分布式系统(事务处理)
文章目录
- 事务(Transaction)
- 分布式事务
- 原子提交协议
-
- 单阶段提交
- 两阶段提交
- 三阶段提交
- 串行等价 / 并发控制
- 分布式死锁
-
- 锁超时
- 全局等待图
- 边追逐算法
- 事务放弃时的恢复
- 服务器崩溃后的恢复
-
- 恢复文件
- 重组恢复文件
- 日志
- 从Crash 中恢复
- 2PC 的恢复
事务(Transaction)
特性:ACID
- 原子性(Atomic):对于外部世界,事务不可分割
- 一致性(Consistent):事务不违反系统不变量(system invariants)
- 隔离性(Isolated):并发事务之间互不干扰
- 持久性(Durable):一旦事务提交,其影响是永久的
事务的 API,
T = open Transaction{
# 对象访问
# 数据运算
...
abort Transaction
...
}close Transaction
事务的实现技术,
- 串行等价 / 并发控制:两阶段锁、时间戳排序、乐观并发控制
- 事务放弃后的恢复:严格两阶段锁
故障模型,
- 磁盘故障:
- 写操作失败、文件写错误、数据块损坏
- 校验和、原子写
- 服务器故障:
- 运行时崩溃、重启时崩溃
- 进程替换
- 通信故障:
- 延迟、丢失、重复、损坏
- 校验和、可靠的 RPC 机制
- 无拜占庭故障
分布式事务
访问由多个服务器管理的对象的事务被称为分布式事务。当一个分布式事务结束时,所有参与该事务的服务器必须全部提交,或全部放弃。有一个服务器扮演协调者,由它来保证在所有的服务器(参与者)上获得同一结果。协调者和参与者之间最常用的协议是两阶段提交协议(two-phase commit,2PC)。
有两种分布式事务:
- 平面事务(flat transaction):每个事务等一个请求结束后才发起下一个请求,顺序访问各个服务器上的对象。
- 嵌套事务(nested transaction):每个事务包含若干子事务,同一层次的事物可以并发执行;如果它们访问服务器上不同的对象,那么这些事务可以并行执行。

协调者提供 Coordinator 接口,有三个基本操作
- open Transaction,由客户调用,返回事务标识(TID)
- close Transaction,由客户调用,
- abort Transaction ,由协调者或参与者调用
Coordinator 接口提供一个额外的方法 join(TID, reference to participant),该方法在一个新的参与者参加到事务中的时候使用
-
通知协调者,一个新的参与者已加入到事务 TID 中
-
协调者将新的参与者记录到参与者列表中
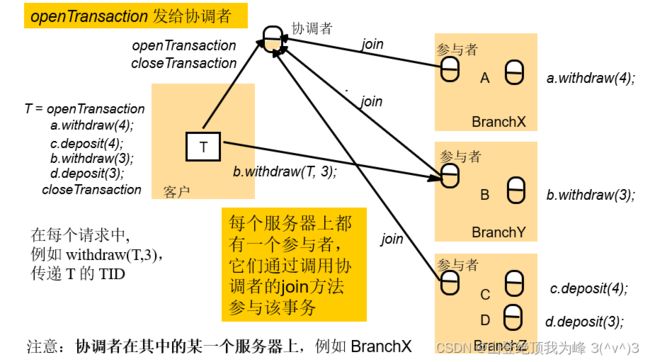
当客户启动一个事务时,
- 客户向协调者发送 open Transaction 请求
- 协调者返回 TID 给客户
- 客户直接发送 request 给参与者,并携带上 TID
- 参与者收到请求,调用 join 方法通知协调者,参与到该事务中
- 每个参与者记录所有参与事务的可恢复对象(Recoverable objects)
- 事务结束后,协调者决定提交或者放弃事务
原子提交协议
事务的原子特性要求,分布式事务结束时,它的所有操作要么全部成功,要么全部取消。
-
在一个分布式事务中,存在
客户-协调者-参与者三方 -
协调者、参与者之间仅有的通信是 join 请求
-
客户请求了多个服务器上的操作,客户请求协调者提交事务,协调者启动提交协议
单阶段提交
由协调者告诉所有参与者是提交或放弃:
- 协调者不断地向所有参与者发送提交或放弃请求,
- 直到所有参与者确认已执行完相应操作。
存在问题:不允许任何服务器单方面放弃自己的事务,然而实际上每个服务器都可能会挂掉。
两阶段提交
两阶段提交协议(2PC:Two-Phrase Commit),它允许任何一个服务器自行放弃属于自己的事务。
故障模型:
- 异步通信系统,消息可能丢失、损坏、重复
- 服务器仅可能 crash,没有随机故障
- 绕过 FLP 不可能:crash 的进程被替换,新进程从持久存储和其他进程中获取故障前的信息
一些操作:
-
can Commit (trans)?
协调者询问参与者,能否提交事务。参与者回复 Yes / No
-
do Commit (trans).
协调者通知参与者,让其提交事务。参与者提交事务
-
do Abort (trans).
协调者通知参与者,让其放弃事务。参与者放弃事务
-
have Committed (trans, participant).
参与者通知协调者,自己完成了提交。
-
get Decision (trans).
当参与者投票 Yes 一段时间后,未收到 do Commit 或者 do Abort 指令。那么就主动询问协调者,事务最终的投票结果。
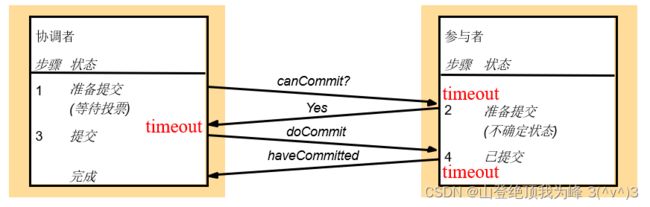
两阶段提交协议,
- 投票阶段:
- 协调者发送 can Commit 给所有参与者,询问它们是否可以提交(能否完成事务、是否完成事务)
- 参与者如果投票 Yes,那么进入 prepared 状态(要在持久存储中保存好事务的 update)
- 参与者如果投票 No,那么立即放弃事务,并 rollback 到事务之前的状态(可恢复对象)
- 提交阶段:
- 协调者收集所有的 votes,
- 如果全是 Yes,那么决定 commit,通知参与者提交事务
- 如果存在 No,或者出现故障,那么决定 abort,通知参与者放弃事务
- 投了 Yes 的参与者,等待协调者的决定(在持久存储中记录这个 decision)
- 如果是 do Commit,那么提交自己的事务,并向协调者发送 have Committed 确认完成提交
- 如果是 do Abort,那么就放弃事务,并 rollback 到事务之前的状态
- 如果等候超时,那么向协调者发送 get Decision,获取最终的决定
- 协调者收集所有的 votes,
三种超时情况:
- 投票阶段,参与者完成事务之后,等待 can Commit 超时:单方面决定 abort 事务
- 提交阶段,协调者等待 votes 超时:发送 do Abort 给参与者
- 提交阶段,投票 Yes 的参与者处于“不确定”状态,如果等待 decision 超时:不断发送 get Decision 给协调者
- 由于可能出现任意多次的服务器或者通信故障,因此 2PC 仅保证最终完成,但没有时间限制(期间阻塞参与者,阻塞期间可能出现数据不一致)
2PC 需要 N N N 个 can Commit 消息, N N N 个 Yes / No 应答, N N N 个 do Commit 消息,一共 3 3 3 轮通信 3 N 3N 3N 个消息的开销(不包含 N N N 个 have Committed 以及若干 g e t D e c i s i o n get Decision getDecision 消息)
2PC 的优化:
- One RM:只有一个资源管理器,退化为单阶段提交,只需 3 3 3 轮通信(而非 4 4 4 轮)。
- Read-Only Trans:只读事务,无论最终是提交还是放弃,都只需要释放对象的读锁。一旦收到 can Commit,就可以释放锁,然后就用 prepared-read-only 回应协调者,告诉协调者后续不必发送 do Commit 或者 do Abort 决定。
- Presumed abort:推断事务一定会放弃,可以直接不写日志
- Cooperative Termination Protocol:协调终止协议,减少等待。每个参与者不仅知道协调者地址,还知道其他参与者的地址。参与者会保留 decision 一段时间。
三阶段提交
三阶段提交协议(2PC:Two-Phrase Commit),通过引入 pre-commit 阶段,以及 timeout 策略,来减少整个集群的阻塞时间,提升系统性能。
第一阶段:can - commit
-
协调者向各个参与者发送 can Commit,询问是否可以执行事务操作,并等待回复。
-
各个参与者依据自身状况回复一个预估值(此时不执行事务,轻量级),
- 如果预估自己能够正常执行事务,那么就回应 Yes 投票,并进入 prepared 状态
- 否则,回应 No 投票,立即放弃事务
第二阶段:pre - commit
-
协调者根据第一阶段的投票结果,采取相应操作:
- 所有的参与者都返回 Yes,发送 pre Commit 预备提交事务
- 一个或多个参与者返回 No,发送 do Abort 放弃事务
- 协调者等待超时,发送 do Abort 放弃事务
-
投票 Yes 的参与者根据收到的指令,采取相应操作:
- 收到 pre Commit,那么就执行事务,
- 如果完成了事务,发送 Yes 给协调者(但不要提交事务),并进入 pre-committed 状态
- 如果执行事务失败,就发送 No 给协调者,放弃事务
- 收到 do Abort,那么放弃事务,rollback
- 如果超时,那么放弃事务,rollback
- 收到 pre Commit,那么就执行事务,
第三阶段:do - commit
-
协调者根据第二阶段的参与者执行情况,采取相应操作:
- 所有的参与者都返回 Yes,发送 do Commit 提交事务
- 一个或多个参与者返回 No,发送 do Abort 放弃事务
- 协调者等待超时,发送 do Abort 放弃事务
-
投票 Yes 的参与者根据收到的指令,采取相应操作:
- 收到 do Commit,那么提交事务
- 收到 do Abort,那么放弃事务,rollback
- 如果超时,那么默认提交事务(消除了无限期的阻塞,但这可能会导致数据不一致)
串行等价 / 并发控制
分布式系统的每个服务器上,都管理着很多的对象,它们负责保证并发事务访问这些对象时保持一致性。
- 每个服务器负责对自己的对象应用并发控制机制
- 分布式事务中所有服务器共同保证事务以串性等价方式执行
- 可能的问题:
- 更新丢失,两个事务同时读取了旧值( a ′ : = a + 1 , a ′ : = a + 2 a':=a+1,a':=a+2 a′:=a+1,a′:=a+2),导致其中一个事务的 update 被覆盖( a ′ ≠ a + 3 a' \neq a+3 a′=a+3)
- 不一致检索,一个检索事务观察了多个正在更新的值( a ′ : = a − 1 , b ′ : = b + 1 a':=a-1,b':=b+1 a′:=a−1,b′:=b+1),导致检索结果与实际不一致( a + b ≠ a ′ + b ′ a+b \neq a'+b' a+b=a′+b′)
串行等价性:
- 条件一:某个事务对于一个对象所有的访问,相对于其他事务的访问,是串行化的(一个事务中对同一对象的多次访问,都位于一个连续的临界区内)
- 条件二:两个事务所有的冲突操作对(读写冲突、写写冲突),必须以相同的次序执行访问(只要事务 T T T 的对于一个对象的冲突访问在事务 U U U 之前,那么对于其他对象的冲突访问都是同样的因果序)
串行等价的交错执行:并发事务交错执行各个操作,它的综合效果与按某种次序,一次只执行一个事务的效果一样(读操作返回相同的值;事务结束时,所有对象的实例变量也具有相同的值)。
- 可以解决更新丢失的问题:

- 可以解决不一致检索的问题:

通过加锁来实现并发控制,达到串行等价性:
- 加锁,串行化对象的访问(条件一)。事务把一个对象的所有访问,全都包含在同一个临界区内(一个对象只能加一次锁)
- 两阶段锁,确保冲突操作对的执行次序相同(条件二)。事务释放了任意一个锁之后,不允许申请任何新的锁(锁增长阶段、锁收缩阶段)
- 严格两阶段锁,防止脏数据读取和过早写入问题。事务获取到的锁,必须在决定 commit 或者 abort 之后,才可以释放(减小粒度,降低影响范围)
分布式死锁
服务器上某个对象的锁,由本地锁管理器持有,
- 每当有事务请求访问对象时,锁管理器就对这个对象尝试加锁。如果加锁失败,那么需要等待前一个事务解锁
- 如果多个事务访问各个对象的加锁次序不同(事务 T T T 先访问 a a a 后访问 b b b,事务 U U U 先访问 b b b 后访问 a a a),这可能会导致事务之间的循环依赖,导致死锁
- 单服务器死锁:要么避免死锁发生,要么检测(锁超时、等待图)并解除死锁
- 分布式死锁:多个服务器中的对象访问相互等待,在局部等待图中可能无法发现环路,必须构造出全局等待图
锁超时
思路:
- 每个锁都设定时间期限。一旦超时,那么锁就变成可剥夺的。
- 如果没有事务在等待此对象,那么原本的事务依旧锁住这个对象
- 如果有其他事务正在等待这个对象,那么这个对象被解锁后交给等待事务,而被剥夺的事务将被放弃
问题:
- 没有死锁的系统,事务依旧可能因为锁超时被剥夺,从而被放弃
- 当系统过载时,长时间运行的事务将被经常性放弃
- 恰当的超时时间长度难以确定
全局等待图
对于服务器 X , Y , Z X,Y,Z X,Y,Z 上的对象 A ; B ; C , D A;B;C,D A;B;C,D,交错执行的事务 U , V , W U,V,W U,V,W 有如下等待关系:
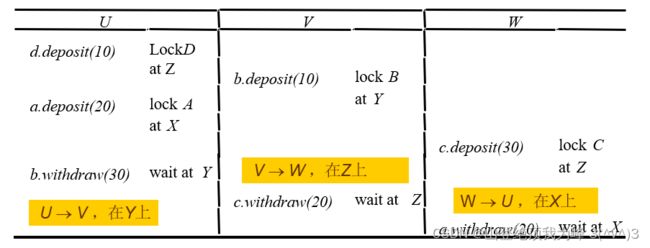
对应的全局等待图为:

为了找到全局环,需要服务器之间进行通信。
- 集中式的死锁检测:
- 一个服务器担任全局死锁检测器,收集、合并各个服务器上的局部等待图
- 其他服务器不定期地发送局部等待图给死锁检测器
- 死锁检测器一旦在全局等待图中发现死锁环,那么就决定放弃某一个事务,通知其他服务器
- 问题:
- 可用性差、缺乏容错、无伸缩性
- 假死锁:收集到的局部等待图是老旧的,全局等待图中有环,但是有些事务已经放弃了某些锁,实际上不存在死锁
- 分布式的死锁检测:可伸缩、可容错
边追逐算法
不需要构造全局等待图,而是在服务器之间转发 probe(探询)消息,
- 事务的协调者,记录这个事务是活动的还是在等待某个对象
- 事务的参与者的本地锁服务器,通知协调者这个事务开始或停止等待
- 当某个事务被放弃时,它的协调者通知所有参与者放弃事务,并释放相关的锁
- 发送规则:当事务依赖关系为 T 1 → T 2 T_1 \to T_2 T1→T2,并且 T 2 T_2 T2 一直在等待其他事务,那么服务器发送 probe 消息

边追逐算法,
- 算法启动:
- 当服务器 A A A 发现事务 T T T 等待事务 U U U,并且被阻塞的 U U U 在等待服务器 B B B 上的对象,那么 A A A 发送一个形如 ( T → U ) (T \to U) (T→U) 的探询消息给 B B B,启动一次死锁检查
- 实际上,服务器发送 probe 给协调者,由协调者转发 probe 给下一个服务器,共需要 2 2 2 个消息(服务器知道所管理的某个对象被哪个事务锁住、同时哪些事务等待正在等待这一个对象;而协调者知道自己管理的事务在等待哪些服务器上的哪些对象)
- 如果事务 U U U 和其他事务共享锁(回到
step 1),那么将探询消息转发给这些锁的拥有者
- 死锁检测:
- 当服务器 B B B 收到了 ( T → U ) (T \to U) (T→U) 消息,检查事务 U U U 是否在等待其他事务
- 如果 U → V U \to V U→V,那么它就增加新边,把形如 ( T → U → V ) (T \to U \to V) (T→U→V) 的探询消息,继续发送到 V V V 等待的服务器 C C C 上
- 每当服务器在 probe 上增加一条新边,检查是否存在环路(对于 N N N 个事务组成的环路,需要 2 ( N − 1 ) 2(N-1) 2(N−1) 个消息)
- 死锁解除:
- 当检测到环路,其中的某个事务将被放弃(可能多个服务器同时发现同一个死锁环)
- 设定事务的优先级,将环路中的最低优先级的事务放弃(避免同时放弃多个事务)
- 向下传递:让 probe 消息只能从高优先级的事务传递到低优先级的事务上(减少通信量)
事务放弃时的恢复
如果事务取消,那么服务器必须保证其他并发事务无法看到被取消事务的影响
- 脏数据读取(dirty read):一个被放弃的事务对某个对象先执行了写操作,之后另一个被提交的事务对这个对象执行了读操作。

如图,事务 U U U 读取了事务 T T T 未提交的脏数据,这个脏数据会影响 U U U 的执行结果(比如发送 130 130 130 给客户),而已经提交的事务不能被取消(Undo)。
- 过早写入(premature writes):不同的事务对同一个对象执行写操作,其中一个写操作被放弃。
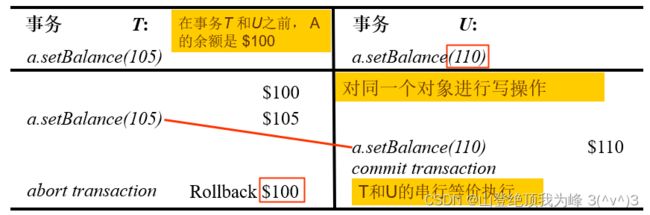
如图,两个事务 U , T U,T U,T 同时对于对象 a a a 执行写操作,当 U U U 被提交后 T T T 再被放弃,对象 a a a 将被恢复为最初的状态(前映像,before images),从而 U U U 提交的写操作丢失。
- 事务的串行等价的交错执行
- 对于同一对象的读写操作,就如同两个事务串行执行执行一样,但不要求提交或放弃
- 只能保证两个事务都提交时的隔离特性
- 事务的严格执行,
- 对于一个对象的读写操作,都必须推迟到对同一对象执行写操作的其他事务提交或者放弃之后
- 可以真正保证事务的隔离特性
服务器崩溃后的恢复
恢复文件
恢复管理器(Recovery Manager, RM)
- 对已提交事务,将对象保存在持久存储中的恢复文件(日志、阴影版本)上
- 重新组织恢复文件,以提高恢复的性能
- 回收恢复文件中的存储空间
- 处理介质故障,需要在独立磁盘上对恢复文件做一个拷贝
- 服务器崩溃后,服务器上对象的恢复
- 2PC 的恢复
恢复文件的组织结构,
- 对象:某个对象的数值
- 事务状态:
- 事务标识 TID
- 事务状态(prepared, committed, aborted)
- 其他用于 2PC 的状态
- 意图列表:TID 以及一系列的意图记录
- 对象标识 UID
- 对象在恢复文件中的位置
意图列表的作用,
- 对应每个事务,都记录下它们修改的对象列表(值、引用)
- 当某个事务提交时,Server 根据意图列表来确定受影响的对象,
- 将事务的临时对象版本,替换为对象的提交版本
- 把对象的新值,写入到服务器的恢复文件上
- 当某个事务放弃时,Server 删除对应的所有临时对象版本
- 在 2PC 中,一旦参与者进入 prepared 状态,那么它的 RM 必须把意图列表、对象的临时版本、事务状态都写入恢复文件
重组恢复文件
- 做检查点的过程,是将下列信息写到一个新的恢复文件
- 当前服务器上所有已提交的对象版本
- 事务的状态记录和尚未完全提交事务的意图列表
- 还包括与 2PC 有关的信息
- 更换恢复文件的过程
- 在旧的恢复文件中增加一个标记
- 进行上述写动作到一个新的恢复文件,然后将那个标记以后的项,拷贝到这个新的恢复文件
- 用新的恢复文件替换旧的恢复文件
- 检查点的目的是,使得恢复更快和回收文件空间,要时不时做一下
日志
日志是恢复文件的一种具体形式,记录了服务器上执行的所有操作的历史
- 最近检查点的快照 + 快照之后的事务操作历史
- 操作历史:对象值、事务状态、意图列表
- 日志中的次序,反映了各个事务进入 prepared / committed / aborted 状态的次序
每当事务准备好、提交、放弃时,Server 就调用自己的 RM,
- 当某事务 prepare,就让 RM 把意图列表中的对象,都 append 到日志中;同时,事务的 prepared 状态以及它的意图列表也被写入
- 当某事物 commit 或者 abort,就让 RM 把对应的 committed / aborted 状态写入日志
- 日志的写操作(append),
- 假定是原子的:如果 crash,那么只有最后一次的 append 可能是不完整的
- 把多次写缓冲起来,顺序写盘比随机写盘快得多

从Crash 中恢复
当服务器进程因崩溃而被替换后,新的进程执行:
- 首先将对象置为缺省的初始值,然后将控制转给恢复管理器
- RM 的任务是恢复所有对象的值(使这些值反映所有已提交事务的效果,不包含任何未完成或放弃事务的效果)
- 通过逆向读取日志文件来恢复对象值(如果从日志的开始进行恢复,通常要做更多的工作)
- 使用具有 committed 状态的事务来恢复对象的值
- 这个过程一直进行到所有的对象都被恢复
- 为了恢复已提交事务的更新,RM 从日志文件的意图列表中找对象的值
- 恢复过程必须是幂等的
- 通过逆向读取日志文件来恢复对象值(如果从日志的开始进行恢复,通常要做更多的工作)
2PC 的恢复
恢复管理器会用到两个事务状态:“完成” 和 “不确定”
- 参与者用 “不确定” 状态,表示它的投票是 Yes,但尚未收到事务的提交决议
- 协调者用 “已提交” 状态,来标记投票的结果是 Yes
- 参与者用 “已提交” 状态,表示已通知投票结果
- 协调者用 “完成” 状态,表示两阶段提交协议已经完成
此外,恢复文件还要增加两类信息
- 协调者:事务标识,参与者列表
- 参与组合:事务标识,协调者
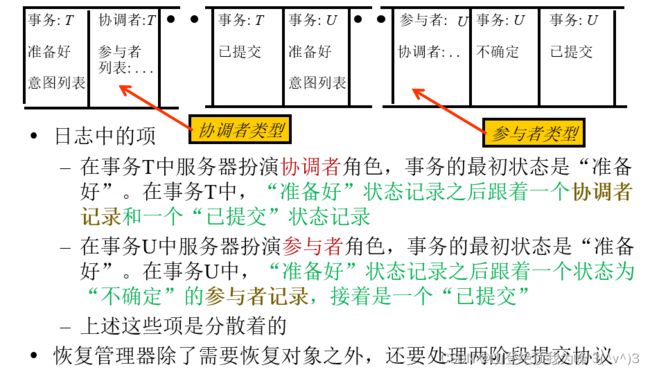
参与者:
- 在投票 Yes 之前,必须进入 prepared 状态,在恢复文件中添加 “准备好” 状态
- 在投票 Yes 时,在恢复文件中添加 “参与者” 记录,并写入 “不确定” 状态
- 在投票 No 时,在恢复文件中写入 “已放弃” 状态
协调者:
- 第一阶段准备提交时,在恢复文件中添加 “协调者” 记录
- 第二阶段做出决定后,在恢复文件中添加 “已提交” 或者 “已放弃” 状态(一次性强制写入)
- 协调者收到所有的 ack 消息后,在恢复文件中写入 “完成” 状态
在恢复文件中最新的事务状态信息决定了故障时的事务状态,RM 需要根据 Server 是协调者或参与者以及状态的不同,进行事务恢复。如图所示:
