ICASSP 2022 | 腾讯AI Lab解读14篇入选论文
感谢阅读腾讯AI Lab微信号第146篇文章。本文介绍腾讯 AI Lab 入选 ICASSP 2022 的 14 篇论文。
ICASSP (International Conference on Acoustics, Speech and Signal Processing) 即国际声学、语音与信号处理会议,是IEEE主办的全世界最大的,也是最全面的信号处理及其应用方面的顶级会议,在国际上享有盛誉并具有广泛的学术影响力。2022 届线上会议于 5 月 7 - 13 日举行。
今年,腾讯 AI Lab 共入选 14 篇论文,包括语音合成、语音转换、声纹识别和说话人日志、语音识别、声学前端、语音分离和增强等方向。以下为论文简述。
语音合成
1. 利用低质量数据进行高表现力语音合成的无参考跨说话人风格迁移
Referee: Towards reference-free cross-speaker style transfer with low-quality data for expressive speech synthesis
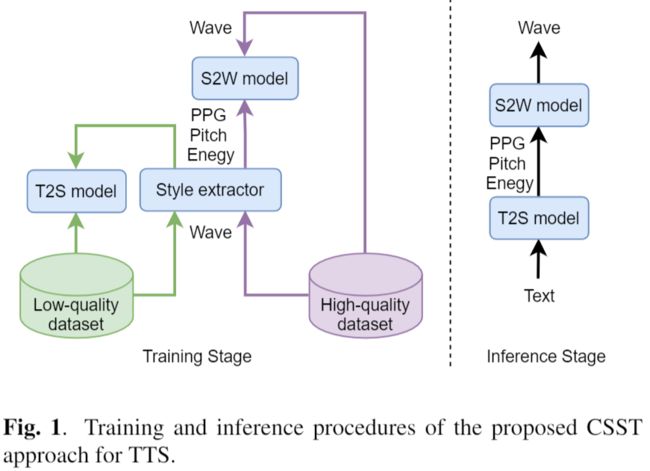
本文由腾讯AI Lab独立完成。文本到语音 (TTS) 合成中的跨说话人风格转移 (CSST) 旨在将说话风格转移到目标说话人的合成语音中。大多数以前的 CSST 方法都依赖于在训练期间携带所需说话风格的昂贵的高质量数据,并且需要参考话语来获得说话风格描述子作为新句子生成的条件。
本文提出了Referee系统,这是一种用于表达性 TTS 的强大的无参考 CSST 方法,可充分利用低质量数据从文本中学习说话风格。裁判是通过将文本到样式 (T2S) 模型与样式到波浪 (S2W) 模型级联构建的。作者将语音后验图(PPG)、音素级音高和能量曲线作为细粒度的说话风格描述子,使用 T2S 模型从文本中预测这些描述子。
本文采用一种新的预训练-细化方法,仅使用易于得到的低质量数据来学习鲁棒的 T2S 模型。S2W 模型使用高质量的目标数据进行训练,用于有效聚合风格描述子并用目标说话人的音色生成高保真语音。实验结果表明,Referee 在 CSST 中优于基于GST的基线方法。


2. 基于语音转换知识迁移的多说话人唇语到语音合成
VCVTS: Multi-speaker Video-to-Speech Synthesis via Cross-modal Knowledge Transfer from Voice Conversion
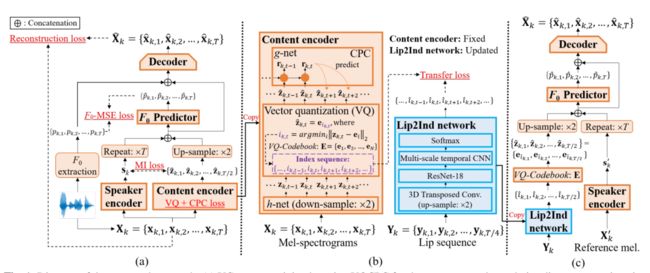
本文由腾讯AI Lab主导,与香港中文大学、博智感知交互研究中心合作完成。尽管说话人相关的唇语到语音合成(Video-to-Speech, VTS)的研究取得了重大的进展,但对于多说话人VTS的研究较少。多说话人VTS旨在将静音视频段映射为语音信号,同时可以在同一个系统中对不同音色进行灵活控制。
本文提出了一个新颖的基于跨模态语音转换的知识迁移的多说话人VTS系统,其中矢量量化与对比预测编码用于语音转换的内容编码器来提取离散的类音素的声学单元,该声学单元随后迁移到一个嘴唇到索引(Lip2Ind)网络的学习来预测声学单元的索引序列。Lip2Ind网络能替换语音转换系统的内容编码器来构成一个多说话人VTS系统,用于将静音视频片段转换成声学单元来重构准确的说话内容。VTS系统同时还继承了语音转换的优点,通过采用一个说话人编码器来提取说话人表示用于有效地控制生成语音的音色。
大量的实验验证了所提方法的有效性,所提VTS系统可以用于有限词汇量和开放词汇量的场景,在语音自然度,可懂度和说话人相似度上取得了最优的效果。
语音转换
3. 基于鲁棒的解耦变分语音表征学习的zero-shot语音转换
Robust Disentangled Variational Speech Representation Learning for Zero-shot Voice Conversion
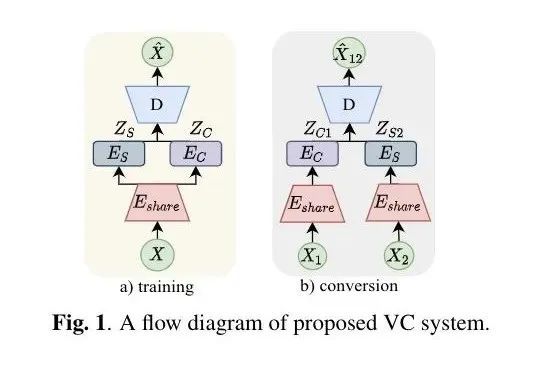
本文由腾讯AI Lab主导,与加州大学伯克利分校合作完成。传统的语音转换研究已经在平行语料和已知说话人的情况下取得了很大的进展。好的语音转换质量通过研究更好地对齐模块和更有表达能力的映射函数得到。
本研究基于一个自监督解耦表征学习的角度研究zero-shot的语音转换。具体地来说,作者通过在一个句式的变分自编码器来平衡全局说话人表征和时变语音内容的表征之间的信息流,从而达到解耦的目的。zero-shot语音转化就简单地通过给定任意一个说话人的表征和任意的语音内容表征输入到训练好的VAE的解码器来完成。除此之外,本研究用一个在线的数据增强模块,来进一步促使学出来的表征能够做到抗噪声干扰。
在TIMIT和VCTK数据集上,本研究取得了最好的客观指标性能(声纹)和语音转换主观指标性能(语音的自然度和相似度),同时当目标说话人或者源语音存在噪声干扰时,依然保持了很好的效果。
声纹识别和说话人日志
4. 基于简单注意力模块及迭代噪声标签检测的说话人确认
Simple Attention Module Based Speaker Verification with Iterative Noisy Label Detection
本文由腾讯AI Lab主导,与武汉大学合作完成。最近,注意力机制,例如基于squeeze-and-excitation (SE)及卷积模块的注意力机制在深度学习说话人确认系统中取得了很大成功。
本论文将一种简单注意力机制(SimAM)引入说话人确认任务。SimAM是一个即装即用的模块而且不会增加额外参数量。而且,考虑到在大规模数据集标注中,人工标注或者自动标注都会含有噪声样本,本文提出了一种噪声标签检测方法来迭代去除训练集中的噪声样本。噪声样本可能造成模型的过参数化问题,从而导致系统性能变差。
在VoxCeleb数据集上的实验表明,采用了SimAM模块的模型在VoxCeleb1原始测试集上的EER达到0.675%。采用了噪声标签检测算法后EER进一步降至0.643%。
5. ICASSP 2022多通道多方会议转录挑战(M2Met)亚军方案:CUHK-TENCENT 说话人日志系统
The CUHK-Tencent Speaker Diarization System for the ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
本文由腾讯AI Lab与香港中文大学合作完成。本文介绍一个说话人日记系统方案,它在ICASSP 2022多通道多方会议转录(M2Met)挑战中取得第二名。
该挑战记录了多通道的中文会议录音用于说话人日志任务和语音识别(ASR)任务,在这些会议场景中,不确定数量的说话人和高语音重叠率都给说话人任务带来了很大的挑战。
基于声学特征、空间相关特征和说话人相关特征之间互补性假设,团队提出了一种多级特征融合的目标-说话人语音活动检测(FFM-TS- VAD)系统,以提高传统TS-VAD系统的性能。此外,团队在训练过程中提出了一种数据增强方法来增强当说话人角度差较小时系统的鲁棒性。
6. 基于通用神经网络说话人聚类的端到端说话人日志系统研究
Towards End-to-End Speaker Diarization with Generalized Neural Speaker Clustering
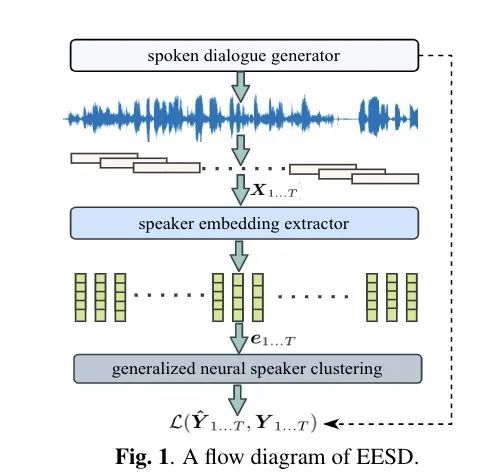
本文由腾讯AI Lab独立完成。传统说话人日志系统由很多的部分组成,包括前端处理,端点检测,混叠语音检测和说话人分割聚类等部分。一般来说,这些模块都是独立开发和优化的。因此,得出来的说话人日志系统通常都比较复杂,且泛化性能一般。
本文以通用神经网络说话人聚类为主体,提出了一个新颖的说话人日志系统。整个说话人日志系统因此可以简化为两个主要的成分,一个是说话人embedding的提取部分,另外一个是说话人聚类部分。在训练时,作者使用一个在线的语音对话的生成模块来给系统提供模拟的对话,和相对应的监督标签(包含了非语音标签,混叠标签和说话人标签)。本研究用段式的推理和基于声纹的追踪模块来处理复杂的说话人不确定问题。
该项研究展示了说话人日志系统确实可以通过一个网络结构端到端地整合端点检测,混叠语音检测和说话人分割聚类,并且在VoxConverse20这个benchmark上得到了非常有竞争力的结果。
7. 会议场景下的基于空间特征的多通道说话人日志系统
Multi-Channel Speaker Diarization Using Spatial Features for Meetings
本文由腾讯AI Lab主导,与香港中文大学合作完成。重叠语音对会议场景下的说话人识别以及说话人日记任务提出了很大的挑战。为了克服这一挑战,一些说话人日志系统集成了不同的基于深度学习的方法来处理重叠语音。
本文提出了两种多通道的说话人日记系统,它们通过学习空间特征来发现重叠语音以及识别不同说话人。一种是在不给定说话人方向(DOA)的情况下采用multi-look策略对网络进行训练,另一种是根据已有的标注信息估计目标说话人的到达方向来进行训练。这两种系统都旨在估计不同方向上说话人的声音活动来处理重叠的语音。
在AMI语料库上的实验结果表明,与采用了BeamformIt前端的重叠感知单通道系统相比,这两种系统的日志化错误率(DER)相对提升了9.4%和18.1%。
语音识别
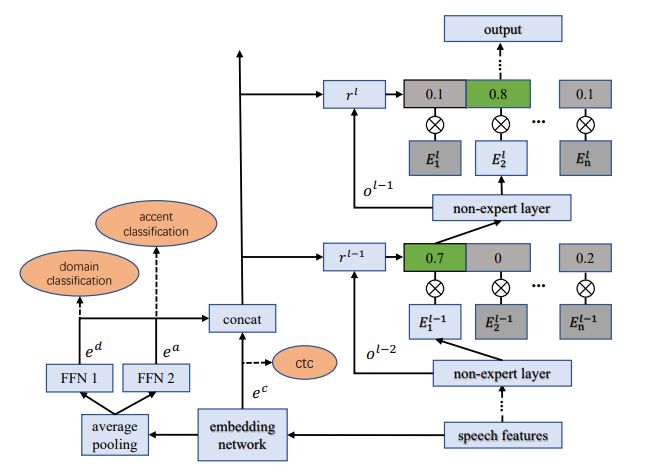
8. SpeechMoE2:改进路由的混合专家神经网络
SpeechMoE2: Mixture-of-Experts with Improved Routing
本文由腾讯AI Lab独立完成。基于混合神经网络的声学模型采用动态路由的机制已经证明在ASR中能获得可观的收益。路由结构的设计的准则对于大模型的容纳能力和高的计算效率非常重要。
在团队之前的工作中,语音动态神经网络仅采用局部的embedding来帮助路由做出路由决策。为了进一步提高针对不同域和口音的语音识别性能,本文提出了一种新的路由器架构,该架构将额外的全局域和口音嵌入到路由器输入中以提高适应性。
实验结果表明,与SpeechMoE相比,SpeechMoE2在多领域和多口音任务中都能获得更低的字符错误率(CER),且参数具有可比性。基本上,建议的方法在多领域任务中可获得1.6%到4.8%的相对提升。在多域任务中可获得相对1.9%到17.7%的相对提升。此外,增加专家数量还可以实现性能的持续改进,并保持计算成本不变。
9. 适用于端到端语言识别的一致性LF-MMI训练和解码
Consistent Training and Decoding for End-to-End Speech Recognition Using Lattice-Free MMI
本文由腾讯AI Lab主导,与北京大学合作完成。近年来,端到端语音识别系统在多项语音识别任务上取得长足进展。然而,广泛应用于Hybrid语音识别系统的LF-MMI训练准则极少被应用于端到端语音识别系统中。
本文提出一种新的方法,将LF-MMI准则应用于端到端语音识别系统的训练和解码中。该方法的有效性在两种常见的端到端语音识别系统(Attention-based Encoder-Decoder和Neural Transducer)上均得到验证。
实验表明,在端到端语音识别系统中引入LF-MMI准则能为两种端到端语音识别系统带来一致性性能提升。该方法最佳模型在Aishell-1的dev/test集上实现了4.1%/4.4%的字错误率(CER),在其他数据集Aishell-2和Librispeech上也实现了显著提升。
相关代码已经开源:https://github.com/jctian98/e2e_lfmmi
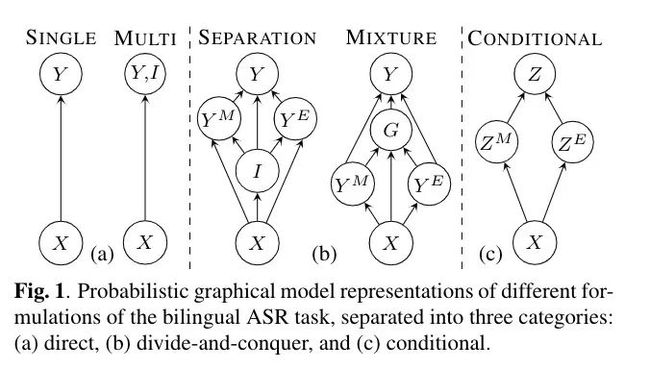
10. 基于条件分解的混杂和单语言语音识别系统的联合建模
Joint Modeling of Code-Switched and Monolingual ASR via Conditional Factorization
本文由腾讯AI Lab主导,与卡内基梅隆大学合作完成。对话性质的双语语音一般有三种形式:两个纯单语种形式和一种句子内部的语种混杂形式。本文提出一种一般性的框架,来联合建模组成双语语音识别的单语和混杂语音子任务的概率模型。通过对单语任务标签到语音帧同步的定义,该联合建模的框架能够被条件性的分解,使最后双语的语音识别输出通过单语的信息来给定,不管输入的语音是否是有混杂语音。
本文研究表明,这种基于条件分解的联合框架能够用一个端到端的网络来建模。作者在中英双语和中英混杂的语音识别任务上验证了该方法的有效性。
声学前端、语音分离和增强
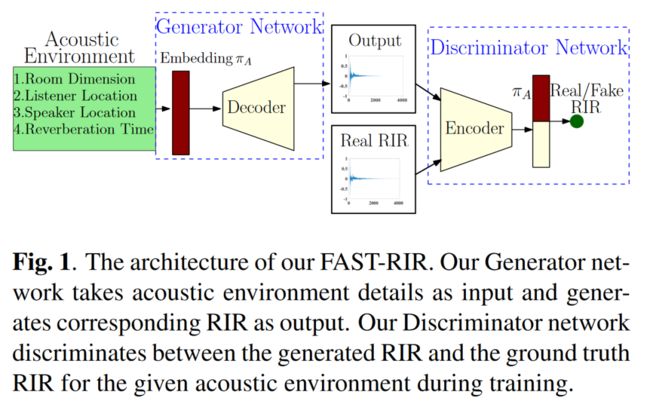
11. FAST-RIR:基于神经网络的快速高精度RIR生成器
FAST-RIR: Fast Neural Diffuse Room Impulse Response Generator
本文由腾讯AI Lab主导,与马里兰大学合作完成。提出了一种基于神经网络的快速漫反射房间脉冲响应发生器 (FAST-RIR),用于为给定的声学环境生成房间脉冲响应 (RIR)。
该 FAST-RIR 将矩形房间尺寸、听者和扬声器位置以及混响时间 (T_60) 作为输入,并为给定的声学环境生成镜面反射和漫反射。它能够为给定的输入 T_60 生成 RIR,平均误差为 0.02 秒。作者使用 Google Speech API、Microsoft Speech API 和 Kaldi 工具在自动语音识别 (ASR) 应用程序中评估该方法生成的 RIR。
实验表明,本文提出的FAST-RIR有以下领先性:1)批量大小为 1 的 FAST-RIR 比 CPU 上最先进的扩散声学模拟器 (DAS) 快 400 倍,并且在 ASR 实验中提供与 DAS 相似的性能;2)比现有的基于 GPU 的 RIR 生成器 (gpuRIR) 快 12 倍;3)在 AMI 远场 ASR 基准测试中,比 gpuRIR 高出 2.5%。
12. 适用于语音分离与识别的混精度模型量化压缩方法
Mixed Precision DNN Quantization for Overlapped Speech Separation and Recognition
本文由腾讯AI Lab与香港中文大学合作完成。迄今为止,识别重叠语音一直是一项极具挑战性的任务。最先进的多通道语音分离系统在实际应用中变得越来越复杂和昂贵。为此,低位神经网络量化提供了一种强大的解决方案,可以显着减小其模型大小。然而,当前的量化方法基于统一的精度,无法考虑不同模型组件对量化误差的不同性能敏感性。
本文通过将局部可变位宽应用于基于 TF 掩码的多通道语音分离系统的各个 TCN 组件,提出了新颖的混合精度 DNN 量化方法。使用三种技术自动学习最佳局部精度设置。前两种方法利用基于均方误差 (MSE) 损失函数曲率或在全精度和量化分离模型之间测量的 KL 散度的量化灵敏度度量。第三种方法是基于混合精度的神经架构搜索。
在 LRS3-TED 语料库模拟重叠语音数据上进行的实验表明,所提出的混合精度量化技术在 SI-SNR 和 PESQ 分数以及单词错误率方面始终优于具有可比位宽的统一精度基线语音分离系统(WER) 减少高达 2.88\% 绝对值(8\% 相对值)。
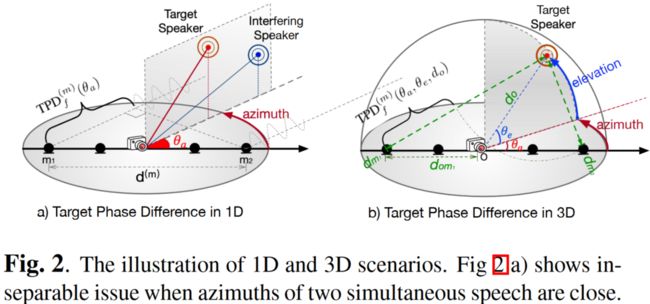
13. 基于3D空间特征的多通道多说话人语音识别
Multi-Channel Multi-Speaker ASR Using 3D Spatial Feature
本文由腾讯AI Lab主导,与约翰霍普金斯大学合作完成。多说话人重叠语音的自动语音识别 (ASR) 仍然是语音界最具挑战性的任务之一。本文首次利用目标说话人在 3D 空间中的位置信息,来解决这一问题。
本文提出了两种范式:1) 多通道语音分离模块,和单通道 ASR 模块 的级联系统;2)“All-In-One”模型,其中 3D 空间特征直接用作 ASR 系统的输入,无需显式分离模块。它们都是完全可导的,并且可以端到端反向传播。
在仿真数据和真实录音上的测试表明:1)提出的 ALL-In-One 模型实现了与级联系统相当的错误率,同时将推理时间减少了一半;2)提出的 3D 空间特征明显优于(31% CERR) 之前基于1D方向信息的所有工作。

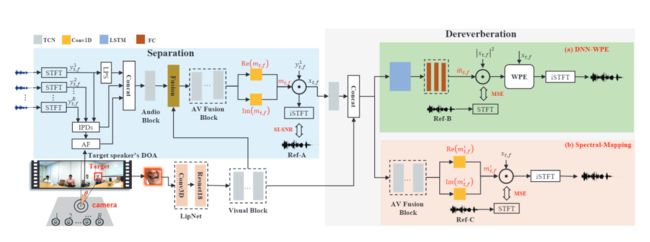
14. 音视频多通道语音分离去混响及识别
Audio-Visual Multi-Channel Speech Separation, Dereverberation and Recognition
本文由腾讯AI Lab与香港中文大学合作完成。尽管语音识别技术在过去几年取得了快速的发展,在包含混叠说话人,背景噪声和房间混响的鸡尾酒会场景下的语音识别依旧很有挑战。由于视觉模态不受声学噪声的干扰,基于音视频的语音增强和语音识别技术开始逐渐出现。
本文提出了一种将视觉模态同时应用于语音分离,语音去混响和语音识别的一体化系统。并提出使用最大化互信息的训练准则来联合调试系统中的分离,去混响和识别模块。
在 LRS2数据上的实验表明本提出的音视频分离-去混响-识别框架能够相较音视频分离-识别系统降低2.06%的绝对词错误率。

* 欢迎转载,请注明来自腾讯AI Lab微信(tencent_ailab)