R语言dplyr包
R语言之dplyr包
-
- 1.使用filter()筛选行
- 2.使用arrange()排列行
- 3.使用select()选择列
- 4.使用mutate()添加新变量
本文将介绍如何使用tidyverse中的另一个核心R包——dplyr包, 加载tidyverse时,仔细查看输出的冲突信息,它会告诉你dplyr覆盖了基础R包中的哪些函数。如果想要在加载dplyr后使用这些函数的基础版本,那么你应该使用它们的完整名称:stats::filter()和stats::lag()。
library(tidyverse)
install.packages("nycflights13")
library(nycflights13)
flights
为了介绍dplyr中的基本数据操作,我们需要使用nycflights13::flights。这个数据框包含了2013年从纽约市出发的所有336 776次航班的信息。该数据来自于美国交通统计局,可以使用?flights查看其说明文档

我们将在本章中学习5个dplyr核心函数,它们可以帮助你解决数据处理中的绝大多数难题。
• 按值筛选观测(filter())。
• 对行进行重新排序(arrange())。
• 按名称选取变量(select())。
• 使用现有变量的函数创建新变量(mutate())。
• 将多个值总结为一个摘要统计量(summarize())。
1.使用filter()筛选行
为了有效地进行筛选,你必须知道如何使用比较运算符来选择观测。R提供了一套标准的比较运算符:>、>=、<、<=、!=(不等于)和==(等于)。
filter()函数可以基于观测的值筛选出一个观测子集。第一个参数是数据框名称,第二个参数以及随后的参数是用来筛选数据框的表达式。例如,我们可以使用以下代码筛选出1月1日的所有航班:
filter(flights,month==1,day==1)


以下代码可以找出11月或12月出发的所有航班:
filter(flights,month==11|month==12)
# 注意|键在F12下面两个,需要和shift一起按
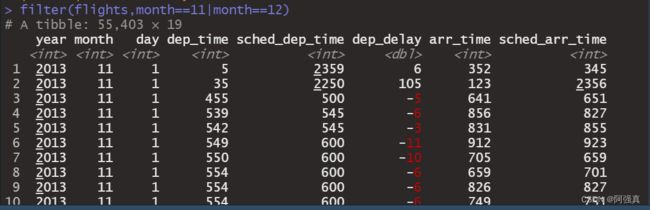
表达式中的运算顺序和语言中的是不一样的。你不能写成
filter(flights, month == 11 | 12)这种形式。这种形式的文字翻译确实是“找出11月或12月出发的所有航班”,但在代码中则不是这个意思,代码中的含义是找出所有出发月份为11 | 12的航班。11 | 12这个逻辑表达式的值为TRUE,在数字语境中(如本例),TRUE就是1,所以这段代码找出的不是11月或12月出发的航班,而是1月出发的所有航班。真是够绕的!
这种问题有一个有用的简写形式:x %in% y。这会选取出x是y中的一个值时的所有行。我们可以使用这种形式重写上面的代码:
filter(flights, month %in% c(11, 12))
2.使用arrange()排列行
arrange()函数的工作方式与filter()函数非常相似,但前者不是选择行,而是改变行的顺序。它接受一个数据框和一组作为排序依据的列名(或者更复杂的表达式)作为参数。如果列名不只一个,那么就使用后面的列在前面排序的基础上继续排序:
arrange(flights, year, month, day)
使用desc()可以对某一列列进行降序排序:
arrange(flights, desc(dep_delay))

3.使用select()选择列
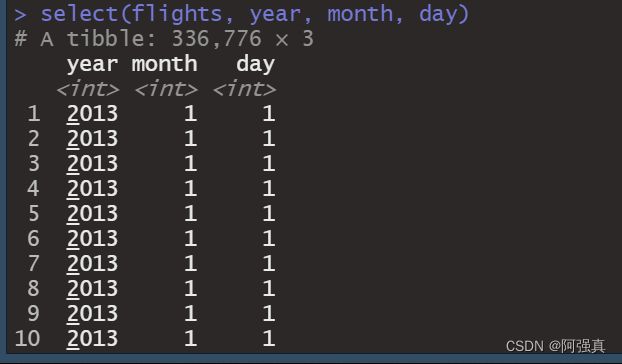
如今,数据集有几百甚至几千个变量已经司空见惯。这种情况下,如何找出真正感兴趣的那些变量经常是我们面临的第一个挑战。通过基于变量名的操作,select()函数可以让你快速生成一个有用的变量子集。select()函数对于航班数据不是特别有用,因为其中只有19个变量,但你还是可以通过这个数据集了解一下select()函数的大致用法:
select(flights, year, month, day) #等于下面这个代码
flights[,c(1,2,3)]
选择不在“year”和“day”之间的所有列(不包括“year”和“day”)
select(flights, -(year:day)) #等于
flights[,-c(1,3)]

将select()函数和everything()辅助函数结合起来使用。当想要将几个变量移到数据框开头时,这种用法非常奏效:
select(flights, time_hour, air_time, everything())

4.使用mutate()添加新变量
除了选择现有的列,我们还经常需要添加新列,新列是现有列的函数。这就是mutate()函数的作用。mutate()总是将新列添加在数据集的最后,因此我们需要先创建一个更狭窄的数据集,以便能够看到新变量。
flights_sml <- select(flights, year:day, ends_with("delay"), distance, air_time ) ;flights_sml
#end_with("delay")是指变量名后缀是delay的项,这里有dep_delay 和arr_delay

mutate(flights_sml, gain = arr_delay - dep_delay,
speed = distance / air_time * 60 )
这样就添加了两列新的变量,gain和speed

R数据科学