python学习:使用KNN最邻近分类算法进行iris数据集分析
概述:
工具准备:
KNN最邻近分类算法:
作用:判断一个未知类型的数据属于哪一类。
判断步骤:
1、输入样本数据集。
2、输入要判断类型的数据(X)。
3、找出离X最近的k个样本。
4、根据k个样本数据的特征判断x是什么类型。
举例:(数据是我杜撰的,主要是传意用)
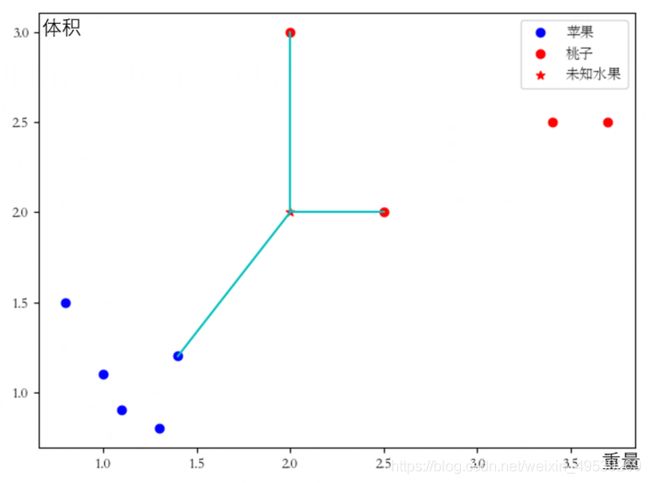
1、输入样本数据集→输入若干个苹果和桃子的体积和重量的数据。
2、输入要判断类型的数据(X)→输入未知种类的水果的重量和体积数据(图中五角星)。
3、找出离X最近的k个样本→找到最近的三个样本(这里k=3,最近的三个样本已用线连出)。
4、根据k个样本数据的特征判断x是什么类型:这里涉及到样本是否加权:
关于邻近样本的加权(K=5):
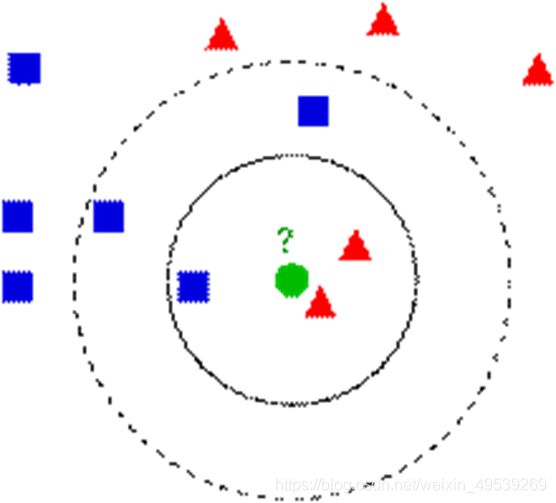
在这张图输出结果时:
使用平均法:一个样本算一分,3>2,判断绿点类型为蓝色方块。
使用加权法:我们设置实线圈内的样本算5分,虚线圈与实线圈之间的算2分,那么蓝色5+2+2<红色5+5,判断绿点类型为红色三角形(具体如何加权可以自由设计)。
KNN最邻近分类算法使用的函数:KNeighborsClassifier
class sklearn.neighbors. KNeighborsClassifier ( n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=1, **kwargs )
把参数一个单独一行拆开来,(主要会用到前两个参数):
class sklearn.neighbors. KNeighborsClassifier
( n_neighbors=5, 寻找邻居的数量,即k值,默认为5。
weights=’uniform’, 使用的加权函数,默认为统一权重;‘distance’:权重点与其距离的倒数,在这种情况下,查询点的近邻比远处的近邻具有更大的影响力。[callable]:用户定义的函数,该函数接受距离数组,并返回包含权重的相同形状的数组。
algorithm=’auto’, 用于计算最近邻居的算法:“ ball_tree”将使用BallTree,“ kd_tree”将使用KDTree,“brute”将使用暴力搜索。“auto”将尝试根据传递给fit方法的值来决定最合适的算法。注意:在稀疏输入上进行拟合将使用蛮力覆盖此参数的设置。
leaf_size=30,叶大小传递给BallTree或KDTree。这会影响构造和查询的速度,以及存储树所需的内存。最佳值取决于问题的性质。默认30。
p=2,Minkowski距离的指标的功率参数。当p=1时,等效于使manhattan_distance(l1)和p=2时使用euclidean_distance(l2)。对于任意p,使用minkowski_distance(l_p)。默认是2。
metric=’minkowski’, 树使用的距离度量。默认度量标准为minkowski,p = 2等于标准欧几里德度量标准。
metric_params=None, 度量函数的其他关键字参数。
n_jobs=1, 并行计算数。
**kwargs )
KNeighborsClassifier 方法:(主要用到前三个)
fit(X, y):使用X作为训练数据和y作为目标值拟合模型(即建立模型,对应前面例子中根据若干个苹果和桃子的体积和重量的数据做出平面直角图这一步骤)。
predict(X):预测提供的数据的类标签。(对应前面例子中输入未知种类的水果的重量和体积数据这一步骤,会基于模型返回预测值,也就是会告诉你未知水果是苹果还是桃子)。
score(X, y[, sample_weight]):返回给定测试数据和标签上的平均准确度。
get_params([deep]): 获取此估计量的参数。
kneighbors([X, n_neighbors, return_distance]) :查找点的K邻居。查找点的K邻居。返回每个点的邻居的索引和与之的距离。
kneighbors_graph([X, n_neighbors, mode]):计算X中点的k邻居的(加权)图。
predict_proba(X):测试数据X的返回概率估计。
set_params(**params):设置此估算器的参数。
在我们使用KNeighborsClassifier时,我们会需要输入用来建立模型的数据和用来测试的数据,而这些数据,来自于我们的另一个工具:train_test_split。
train_test_split:
X_train,X_test, y_train, y_test =cross_validation.train_test_split(X, y, test_size, random_state)
我们先来看看这四个返回值:
X:特征(即x,y轴上的数据,对应前面例子中水果的重量和体积) 。
y: 标签(属于哪一类,对应前面例子中的“苹果”、“桃子”种类)。
train:训练集,用来生成模型中的参数,使模型能够反映现实,进而预测未来或其他未知的信息。
test:测试集,用来测试模型的预测性能。
到这里,我产生了一个疑问:一组数据为什么不全部拿去做模型,而要分成测试集和训练集呢?
答案是:将所有的数据输入到模型拟合过程中,是可以实现的。但是,这可能存在过拟合问题。
什么是过拟合:
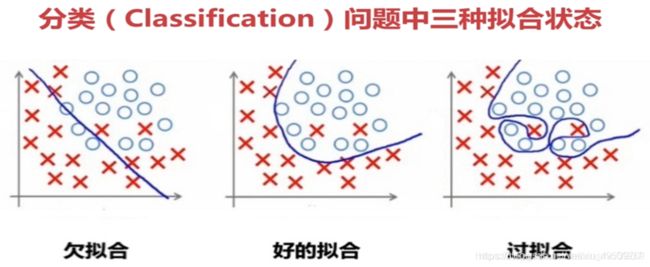
过拟合:就是太过贴近于训练数据的特征了,在训练集上表现非常优秀,近乎完美的预测、区分了所有的数据,但是在新的测试集上却表现平平,不具泛化性,拿到新样本后没有办法去准确的判断。
回过头来看一下参数:
X:待划分的样本特征集合。(即x,y轴上的数据)
y:待划分的样本标签。(即关于样本属于哪一类的数据)
test_size:测试数据占样本数据的比例;如果输入的是整数,则为样本数量。
random_state:随机数种子。
看到random_state,我去了解了一下随机数种子是什么:
随机数种子:
首先,random_state 的作用等于 random seed:保证每次运行得到的随机数是一样的:
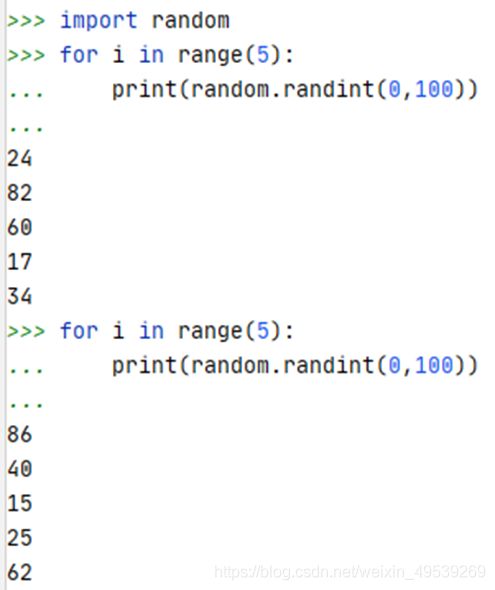

左边没有使用随机数种子,右边使用了随机数种子,可以看到,左边每次生成的随机数是不同的;但是,右边因为用了同样的随机数种子,每次生成5个的随机数是一样的
(随机数种子具体在实际中有什么应用我还没有去了解,这部分到此为止)。
那么使用到的工具部分(KNN最邻近分类算法和train_test_split)就到这里,接下来开始开始讲具体操作步骤:
具体步骤
其实,知道了前面两个工具后,就很简单了(相对)。
1、简化版:
①、给数据划分训练集和测试集:( train_test_split )
②、输入训练集拟合模型:( knn = KNeighborsClassifier()
knn.fit(X_train, Y_train))
③、用一个未知数据测试模型:(prediction= knn.predict(X_new))
④、用测试集测试模型准度:(y_pred=knn.predict(X_test)
np.mean(y_pred==Y_test)
knn.score(X_test,Y_test))
2、完整代码:
import numpy as np #导入np
from sklearn import datasets #导入花卉数据
from sklearn.model_selection import train_test_split #导入训练
from sklearn.neighbors import KNeighborsClassifier #导入KNN最邻近分类算法
#以上都是导入
iris=datasets.load_iris()
X_train,X_test,Y_train,Y_test = train_test_split(iris['data'],iris['target'],random_state=0)#给数据划分训练集和测试集
X_new = np.array([[5,2.9,1,0.2]]) #要我们判断类型的数据
#以上是数据准备
knn = KNeighborsClassifier() #定义一个knn分类器对象
knn.fit(X_train, Y_train) #训练一个模型
prediction= knn.predict(X_new) #测试一个数据
print(prediction) #输出测试结果
print(iris['target_names'][prediction]) #用索引找到结果对应的种类
#这是一次测试,用的是一个数据
y_pred=knn.predict(X_test) #用测试集测试
print('{:.2f}'.format(np.mean(y_pred==Y_test))) #用mean测试平均准确度
#这是一次测试用的是一组自定义数据
print('{:.2f}'.format(knn.score(X_test,Y_test))) #用score测试平均准确度
#这是一次测试,用的是train_test_split生成的测试集输出结果:
PyDev console: starting.
Python 3.8.3 (default, Jul 2 2020, 17:30:36) [MSC v.1916 64 bit (AMD64)] on win32
runfile('D:/pycharm/practise/交换变量.py', wdir='D:/pycharm/practise')
[0]
['setosa']
0.97
0.97