【Java架构入门到精通】Redis缓存机制与应用二
可以通过help命令查询相关类型命令说明,比如:
help @string help @list
分享一下我记录的几种数据类型的基本命令
String
#设置值 set key value
#获取值 get key
#获取值类型(set的都是String) type key
#获取值编码类型(raw/int) object encoding key
#获取字节长度(注意1字节等于8位bit) strlen key
#+1计算
#incr key
bitmap(二进制操作)
#设置该值左边第几位为1,bit长度不是8位整数的补成8的整数长度,如 10会补成00000010, 0100000001 会补成0000000100000001 格式:setbit key offset value setbit k1 1 1
#01000000 对应ascii码为‘@’ get k1
#’@’
#将k1值得第7位设置为1 setbit k1 7 1
#01000001 对应ascii码为‘A’ setbit k1 8 1
#0100000110000000
#获取对应位置bit的值(1或0) getbit key offset getbit k1 7
#假如k1值位00000001,第7位返回1 getbit k1 5
#假如k1值位00000001,第5位返回0
#获取对应范围内1的数量(注意范围是字节区间,不是Bit位区间) bitcount key [start end] bitcount k1
#获取bit位为1的数量 相当于bitcount k1 0 -1(假如k1值位00001001,返回2,假如k1值位0000000100001001,返回3) bitcount k1 0 0
#获取第一个字节的8位Bit中有几位为1 (假如k1值位0000000100001001,返回1),注意是从左边开始数每8位为一个字节
#与、或、非、异或操作 bitop opration destkey key [key...]
#opration可选值(and/or/not),destkey为计算完后要保存的新的key bitop and k3 k1 k2
#与运算,假如k1为01000000,k2为00000001,则结果k3为00000000 bitop or k3 k1 k2
#或运算,假如k1为01000000,k2为00000001,则结果k3为01000001 bitop xor k3 k1 k2
#异或运算,假如k1为01000000,k2为01000001,则结果k3为00000001 bitop not k3 k1
#非运算,假如k1为01000000,则结果k3为10111111
list(链表)
#左边插入 格式:lpush key value [value...] lpush k1 1 2 3 4 5 6
#k1值为六项:6 5 4 3 2 1
#右边插入 格式:rpush key value [value...] rpush k1 1 2 3 4 5 6
#k1值为六项:1 2 3 4 5 6
#获取k1范围内的的值 lrange k1 0 -1
#获取第一个数(最左边的数)并删除该值(像栈操作) lpop key
#k1值为六项:1 2 3 4 5 6 那么会返回1,k1值变为2 3 4 5 6
#获取指定下标值 lindex key
#删除范围之外的数值 ltrim key start end ltrim k1 0 3
#k1值为六项:1 2 3 4 5 6,那么k1只留下1 2 3 4
hash(对象)
#设置对象属性值 hset key field value hset user1 name huangtl
#设置user1的name属性为huangtl hset user1 age 18
#设置user1的age属性为18
#单个属性获取 hget user1 age
#18
#所有属性获取 hgetall user1
#返回属性、值、属性、值 :name huangtl age 18
#获取对象所有key hkeys user1
#返回user1的所有属性:name age
#获取对象所有kvalue hvals user1
#返回user1的所有属性得值:huangtl 18
set(无序、去重集合)
#存入集合数据 sadd key member [member...] sadd k1 1 2 3 4 5 6 2
#两个2知会存一个2,集合内数值有1 2 3 4 5 6
#获取集合数据 SMEMBERS k1
#随机获取集合几条数据 SRANDMEMBER k1 [count] SRANDMEMBER k1
#随机获取一条 SRANDMEMBER k1 8
#随机获取8条数据,不会重复的数据,集合不足8条取集合全部数据 SRANDMEMBER k1 -8
#随机取8条,可能会重复的数据,集合不足8条也会取8条数据
#取数值并删除 spop key [count] spop key
#随机取一条并删除 spop key 5
#随机取5条并删除 #多个集合取并集 SUNION key [key...] SUNION k1 k2
#假如k1为1 2 3 4 5 6 ,k2为4 5 6 7 8 9,则返回1 2 3 4 5 6 7 8 9
#多个集合取交集 SINTER key [key...] SINTER k1 k2
#假如k1为1 2 3 4 5 6 ,k2为4 5 6 7 8 9,则返回4 5 6
#多个集合取差集 sdiff key [key...] sdiff k1 k2
#按顺序取k1减掉k2中的值后剩下的值
#假如k1为1 2 3 4 5 6 ,k2为4 5 6 7 8 9,则返回1 2 3 sdiff k2 k1
#按顺序取k2不减掉k1中的值值后剩下的值
#假如k1为1 2 3 4 5 6 ,k2为4 5 6 7 8 9,则返回7 8 9
sorted_set(有序集合)
#新建key并添加元素 zadd key score member [score member...] zadd set1 1 apple 2 orange 3 banana
#返回范围内集合数据,按score分值正序 zrange set1 0 -1
#默认返回 apple orange banana zrange set1 -2 -1
#按正序取最后两名,返回 orange banana ZREVRANGE set1 0 1
#倒序返回前两名,返回 banana orange
#获取元素位置 zrank set1 apple
#返回0,代表apple在第一位
事务
Redis 事务本质:一组命令的集合! 一个事务中的所有命令都会被序列化,在事务执行过程的中,会按照顺序执行!想学习交流HashMap,nginx、dubbo、Spring MVC,分布式、高性能高可用、MySQL,redis、jvm、多线程、netty、kafka、的加尉(同英):1253431195 扩列获取资料学习,无工作经验不要加哦!
Redis单条命令式保存原子性的,但是事务不保证原子性!
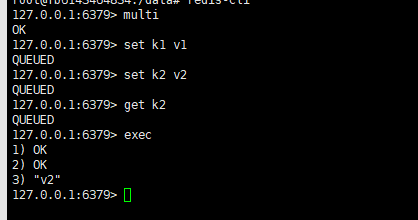
# 开启事务 multi
#命令入队 set k1 v1 set k2 v2 get k2
# 执行事务 exec
Redis持久化
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
redis提供两种持久化机制 RDB(默认) 和 AOF 机制。
1、RDB
RDB是Redis DataBase缩写快照 ,默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb
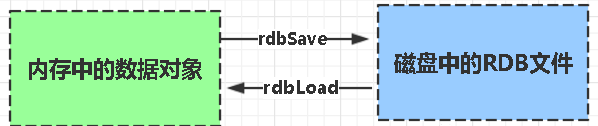
触发机制
(1)save的规则满足的情况下
(2)执行 flushall 命令
(3)退出redis,也会产生 rdb 文件
2、AOF:
持久化,AOF持久化(即Append Only File持久化),则是将Redis执行的每次写命令记录到单独的日志文件中,当重启Redis会重新将持久化的日志中文件恢复数据。

AOF的三种策略(1)always (2)everysec(默认值) (3)no always

在应用时,要根据自己的实际需求,选择RDB或者AOF,其实,如果想要数据足够安全,可以两种方式都开启,但两种持久化方式同时进行IO操作,会严重影响服务器性能,因此有时候不得不做出选择。想学习交流HashMap,nginx、dubbo、Spring MVC,分布式、高性能高可用、MySQL,redis、jvm、多线程、netty、kafka、的加尉(同英):1253431195 扩列获取资料学习,无工作经验不要加哦!
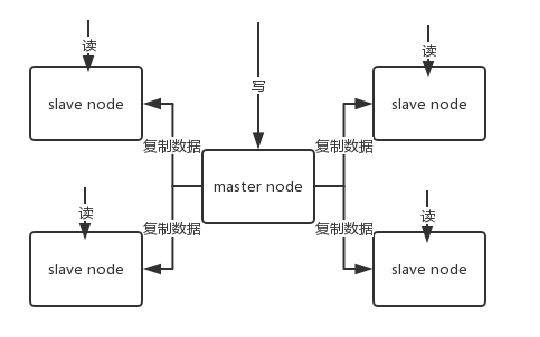
redis主从复制
概念主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower);数据的复制是单向的,只能由主节点到从节点。
优点:(1)读写分离 (2)备份
缺点:主服务器宕机,需要人工启动
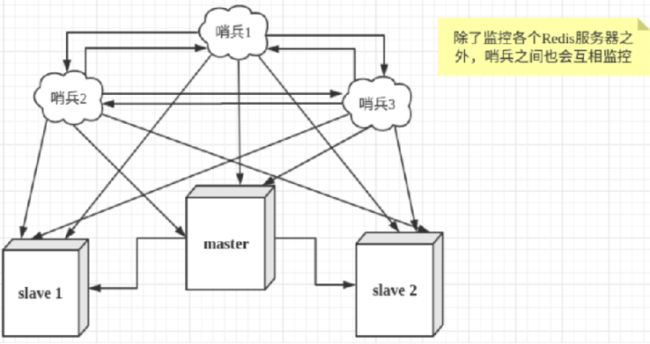
哨兵模式
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例。
使用场景、缓存问题
1、热点数据的缓存
公司项目用户量达到一定数量的时候,这时合理的利用缓存不仅能够提升项目访问速度,还能大大降低数据库的压力。想学习交流HashMap,nginx、dubbo、Spring MVC,分布式、高性能高可用、MySQL,redis、jvm、多线程、netty、kafka、的加尉(同英):1253431195 扩列获取资料学习,无工作经验不要加哦!
2、业务上的统计,排行榜
为了保证数据实时效,比如项目的访问量,每次浏览都得给+1,并发量高时如果每次都请求数据库操作无疑是种挑战和压力
3、限时业务的运用
每日签到、限制登录功能等业务场景
4、消息队列
提供基本的发布订阅功能,但不像消息队列那种专业级别
缓存雪崩
原因:大量redis key在同一时间失效,导致大量请求访问数据库,数据库服务器宕机,线上服务大面积报错。
解决办法:
(1)redis高可用
(2)加锁排队,限流降级
(3)缓存失效时间均匀分布
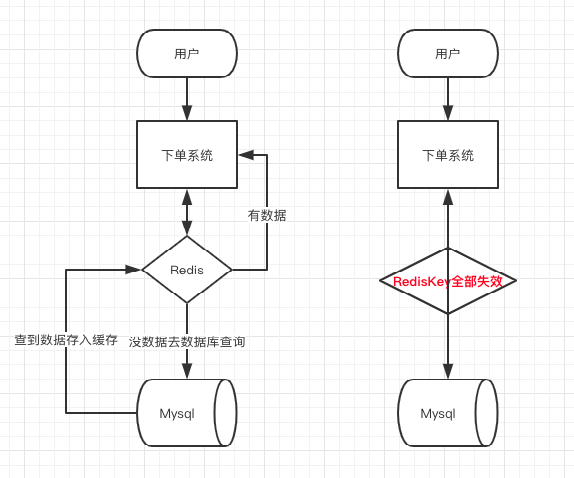
缓存穿透
原因:指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决办法: (1)接口层增加校验 (2)采用布隆过滤器
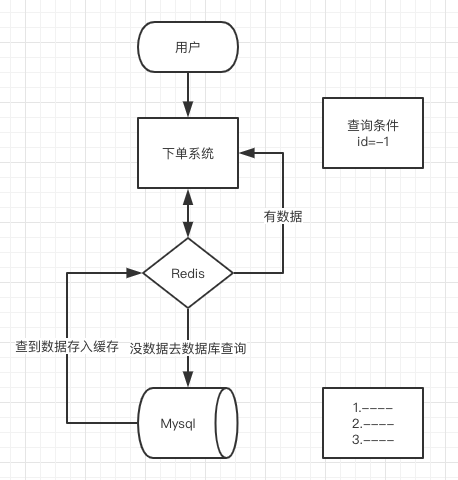
缓存击穿
原因:指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。比如微博热搜。想学习交流HashMap,nginx、dubbo、Spring MVC,分布式、高性能高可用、MySQL,redis、jvm、多线程、netty、kafka、的加尉(同英):1253431195 扩列获取资料学习,无工作经验不要加哦!
解决办法:
(1)设置热点数据缓存没有过期时间
(2)加互斥锁
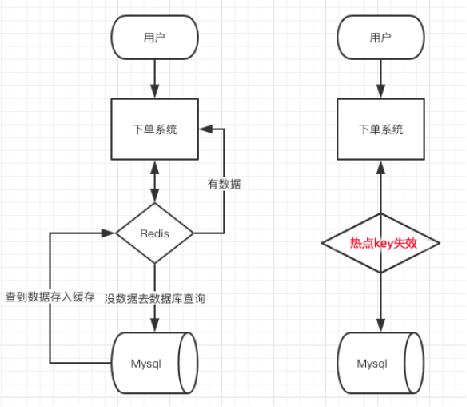
好了就介绍到这了,可以自己动手尝试吧。