Amazon Neptune学习笔记
Amazon Neptune学习笔记
- Gremlin
-
- Neptune Gremlin 实施的不同之处
-
- Pre-Bound 变量
-
- TinkerPop 枚举
- Java 代码
- 日期和时间
- 脚本执行
- 会话
- 事务
- 顶点和边缘 ID
- 用户提供的 ID
- 顶点属性 ID
- 顶点属性的基数
- 更新顶点属性
- 标签
- 变量
- 超时
- 转义字符
- Groovy 限制
- 序列化
- Lambda 步骤
- 不支持的 Gremlin 方法
- 不支持的 Gremlin 步骤
- 其他功能
- Gremlin 图形支持的功能
- Gremlin控制台
-
- 下载安装
- 修改配置
- 操作
- 演练
- Gremlin常用语法总结
-
- 基本操作
- 核心概念
- Gremlin 查询示例
-
- 查询点
- 查询边
- 查询属性
- 新增点
- 新增边
- 删除点
- 删除边
- Gremlin语法特性
-
- 基础
- 遍历
- 过滤
-
- has
- 路径
- 迭代
- 转换
- 排序
- 逻辑
- 统计
- 分支
- Neptune可视化工具范例.jpg(在这里输入文件名)
Gremlin
Neptune Gremlin 实施的不同之处
Pre-Bound 变量
遍历对象 g 是 Pre-bound。不支持 graph 对象。
TinkerPop 枚举
Neptune 不支持枚举值的完全限定类名称。例如,您在 Groovy 请求中必须使用 single,不能使用 org.apache.tinkerpop.gremlin.structure.VertexProperty.Cardinality.single。
- 枚举类型由参数类型决定。
- 下表显示了允许的枚举值和相关的 TinkerPop 完全限定名称。

Java 代码
**Neptune 不支持调用由支持的 Gremlin API 以外的任意 Java 或 Java 库调用定义的方法。**例如,不允许 java.lang.*、Date() 和 g.V().tryNext().orElseGet()。
日期和时间
Neptune 提供了 datetime 方法,用于为 Gremlin Groovy 变体中发送的查询指定日期和时间。这包括 Gremlin 控制台、使用 HTTP REST API 的文本字符串以及使用 Groovy 的任何其他序列化。日期和时间值必须使用 datetime() 函数进行指定。
- 注意:这仅适用于您将 Gremlin 查询作为文本字符串 发送的方法。如果您使用的是 Gremlin 语言变体 (GLV),则必须使用该语言的本机日期类和函数。
- datetime( ) 函数采用符合 ISO-8601 日期时间的字符串值,最高精度为毫秒。例如:datetime(‘2018-01-01T00:00:00’)
- ISO-8601 日期时间格式的一些示例如下所示:
YYYY-MM-DD
YYYY-MM-DDTHH:mm
YYYY-MM-DDTHH:mm:SS
YYYY-MM-DDTHH:mm:SS.ssss
YYYY-MM-DDTHH:mm:SSZ
脚本执行
所有查询必须以遍历对象 g 开头。
多个遍历可由分号 ( 或换行符 (\n) 分隔发布。最后一个以外的每个语句都必须以要执行的 next() 步骤结尾。仅返回最后遍历数据。
会话
Neptune 属于无会话型。它不支持控制台 session 参数。
事务
Neptune 在每个 Gremlin 遍历开始时打开新的事务,并在遍历成功完成后结束事务。事务会在出现错误时回滚。
用分号 ( 或换行符 (\n) 分隔的多个语句包含在单个事务中。最后一个以外的每个语句都必须以要执行的 next() 步骤结尾。仅返回最后遍历数据。
不支持使用 tx.commit() 和 tx.rollback() 的手动事务逻辑。
顶点和边缘 ID
Neptune Gremlin 顶点和边缘 ID 必须属于 String 类型。如果您在添加顶点或边缘时未提供 ID,则 UUID 会生成并转换为一个字符串;例如,“48af8178-50ce-971a-fc41-8c9a954cea62”。
- 注意:这表示用户提供的 ID 受支持,但它们在正常使用中是可选的。但是,Neptune Load 命令要求所有 ID 使用 ~id 字段采用 Neptune CSV 格式进行指定。
用户提供的 ID
用户提供的 ID 在 Neptune Gremlin 中允许,且具有以下规定。
* 提供的 ID 是可选的。
* 仅支持顶点和边缘。
* 仅支持 String 类型。
要使用自定义 ID 创建新顶点,请将 property 步骤与 id 关键字一起使用:g.addV().property(id, ‘customid’)。
- 注意:请勿为 id 关键字加上引号。
- 所有顶点 ID 必须是唯一的,并且所有边缘 ID 也必须是唯一的。但是,Neptune 允许顶点和边缘具有相同的 ID。
- 如果您尝试使用 g.addV() 创建新顶点并且已存在具有该 ID 的顶点,则此操作将失败。此情况的例外是,如果为顶点指定新标签,该操作将成功,但会将新标签和指定的任何其他属性添加到现有顶点。不会覆盖任何内容。未创建新顶点。顶点 ID 不会更改并会保持唯一。
例如,以下 Gremlin 控制台命令将成功:
gremlin> g.addV('label1').property(id, 'customid')
gremlin> g.addV('label2').property(id, 'customid')
gremlin> g.V('customid').label()
==>label1::label2
顶点属性 ID
顶点属性 ID 会自动生成且可以在查询时显示为正数或负数。
顶点属性的基数
Neptune 支持集基数和单一基数。如果未指定,则集基数处于选中状态。这意味着,如果您设置一个属性值,它会向该属性添加新值,但是仅当它未显示在一组值中时。这是 Set 的 Gremlin 枚举值。
不支持 List。有关属性基数的更多信息,请参阅 Gremlin JavaDoc 中的顶点主题。
更新顶点属性
要更新属性值而无需向一组值添加其他值,请在 property 步骤中指定 single 基数。
g.V('exampleid01').property(single, 'age', 25)
- 注意:这将删除该属性的所有现有值。
标签
Neptune 支持一个顶点的多个标签。创建标签时,您可以指定多个标签,同时使用 :: 分隔它们。例如,g.addV(“Label1::Label2::Label3”) 添加具有三个不同标签的顶点。hasLabel 步骤与具有以下任一三个标签的此顶点相匹配:hasLabel(“Label1”)、hasLabel(“Label2”) 和 hasLabel(“Label3”)。
- 注意::: 分隔符仅用于此用途。您不能在 hasLabel 步骤中指定多个标签。例如,hasLabel(“Label1::Label2”) 与任何内容都不匹配。
变量
Neptune 不支持 Gremlin 变量且不支持 bindings 属性。
超时
Gremlin 控制台命令 :remote config timeout 仅设置本地超时。要为 Neptune 设置远程查询超过,请使用 neptune_query_timeout 参数。
转义字符
Neptune 解析所有转义字符,如 Apache Groovy 语言文档的转义特殊字符部分中所述。
Groovy 限制
Neptune 不支持不以 g 开头的 Groovy 命令。这包括数学(例如:1+1)、系统调用(例如:System.nanoTime())和变量定义(例如:1+1)。
- 注意:Neptune 不支持完全限定类名称。例如,您在 Groovy 请求中必须使用 single,不能使用 org.apache.tinkerpop.gremlin.structure.VertexProperty.Cardinality.single。
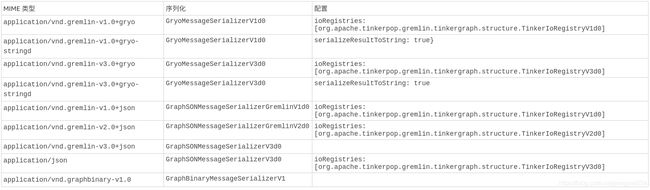
序列化
Neptune 根据请求的 MIME 类型支持以下串行化。
Lambda 步骤
Neptune 不支持 Lambda 步骤。
不支持的 Gremlin 方法
Neptune 不支持以下 Gremlin 方法:
- org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversal.program
(org.apache.tinkerpop.gremlin.process.cmputer.VertexProgram) - org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversal.sideEffect
(java.util.function.Consumer) - org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversal.from
(org.apache.tinkerpop.gremlin.structure.Vertex) - org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversal.to
(org.apache.tinkerpop.gremlin.structure.Vertex)
例如,不允许以下遍历:g.V().addE(‘something’).from(g.V().next()).to(g.V().next())。
不支持的 Gremlin 步骤
Neptune 不支持以下 Gremlin 步骤:
其他功能
Gremlin 的 Neptune 实施不公开 graph 对象。以下部分介绍支持和不支持的 graph 功能。
- Neptune 中不支持 Gremlin io( ) 步骤。例如,g.io(“graph.xml”).read().iterate() 查询不可用于 Neptune。
Gremlin 图形支持的功能
参考:https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/access-graph-gremlin-differences.html?shortFooter=true
Gremlin控制台
- 参考:https://docs.aws.amazon.com/zh_cn/neptune/latest/userguide/access-graph-gremlin-console.html?shortFooter=true
下载安装
wget https://archive.apache.org/dist/tinkerpop/3.3.2/apache-tinkerpop-gremlin-console-3.3.2-bin.zip
unzip apache-tinkerpop-gremlin-console-3.3.2-bin.zip
cd apache-tinkerpop-gremlin-console-3.3.2
修改配置
- 在提取的目录的 conf 子目录中,创建名为 neptune-remote.yaml 的包含以下文本的文件。将 your-neptune-endpoint 替换为您的 Neptune 数据库实例的主机名或 IP 地址。方括号 ([ ]) 是必需的。
hosts: [your-neptune-endpoint]
port: 8182
serializer: { className: org.apache.tinkerpop.gremlin.driver.ser.GryoMessageSerializerV3d0, config: { serializeResultToString: true }}
操作
- 在终端中,导航到 Gremlin 控制台目录 (apache-tinkerpop-gremlin-console-3.3.2),然后输入以下命令来运行 Gremlin 控制台。
bin/gremlin.sh
- 您应看到以下输出:
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin>
- 在 gremlin> 提示符处,输入以下命令以连接到 Neptune 数据库实例。
:remote connect tinkerpop.server conf/neptune-remote.yaml
- 在 gremlin> 提示符处,输入以下命令以切换到远程模式。这会将所有 Gremlin 查询发送到远程连接。
:remote console
- 输入以下命令以将查询发送到 Gremlin 图形。
g.V().limit(1)
- 完成后,输入以下命令以退出 Gremlin 控制台。
:exit
- 注意:
* 使用分号 (;) 或换行符 (\n) 分隔每个语句。
* 在最后遍历之前的每个遍历必须以要执行的 next() 结尾。仅返回最后遍历中的数据。
演练
- 添加带有标签和属性的顶点
gremlin> g.addV('person').property('name', 'justin')
==>v[30b583c5-acf9-31aa-eee7-99c1644e3367]
// 顶点分配有包含 GUID 的 string ID。Neptune 中的所有顶点 ID 均为字符串。
- 添加具有自定义 ID 的顶点
gremlin> g.addV('person').property(id, '1').property('name', 'martin')
==>v[1]
// id 属性未使用引号引起来。这是顶点 ID 的关键字。顶点 ID 具有一个字符串,其中包含数字 1。
// 普通属性名称必须包含在引号中。
- 更改属性或添加属性(如果属性不存在)
gremlin> g.V('1').property(single, 'name', 'marko')
==>v[1]
// 此处介绍如何更改上一步中顶点的 name 属性。这会从 name 属性删除现有值。
// 如果您未指定 single,则会改为将值附加到 name 属性(如果尚未附加)。
- 添加属性,但在属性已有值时附加属性
gremlin> g.V('1').property('age', 29)
==>v[1]如果 age 属性已有值,此命令将 29 附加到属性。例如,如果 age 属性是 27,则新值将为 [ 27, 29 ]。
// Neptune 使用集基数作为默认操作。
// 此命令添加值为 29 的 age 属性,但不替换任何现有值。
// 如果 age 属性已有值,此命令将 29 附加到属性。例如,如果 age 属性是 27,则新值将为 [ 27, 29 ]。
- 添加多个顶点
gremlin> g.addV('person').property(id, '2').property('name', 'vadas').property('age', 27).next()
==>v[2]
gremlin> g.addV('software').property(id, '3').property('name', 'lop').property('lang', 'java').next()
==>v[3]
gremlin> g.addV('person').property(id, '4').property('name', 'josh').property('age', 32).next()
==>v[4]
gremlin> g.addV('software').property(id, '5').property('name', 'ripple').property('ripple', 'java').next()
==>v[5]
gremlin> g.addV('person').property(id, '6').property('name', 'peter').property('age', 35)
==>v[6]
// 可以同时将多个语句发送到 Neptune。
// 语句可以使用换行符 ('\n')、空格 (' ')、分号 ('; ') 或什么都不使用(例如,g.addV(‘person’).next()g.V() 是有效的)来分隔。
// 注意
// Gremlin 控制台对每个换行符 ('\n') 发送单独的命令,因此在该例中,它们将成为单独的事务处理。此示例的每个命令位于单独一行中,以便阅读。删除换行符 ('\n') 可以将其通过 Gremlin 控制台作为单个命令发送。
// 除了最后一条语句之外的所有语句必须以终止步骤结尾,例如 .next() 或 .iterate(),否则语句不会运行。Gremlin 控制台不需要这些终止步骤。
// 一起发送的所有语句包括在单个事务处理中,并且一起成功或失败。
- 添加边
gremlin> g.V('1').addE('knows').to(g.V('2')).property('weight', 0.5).next()
==>e[fab583cd-5686-b3df-60f8-ab792ca96ba9][1-knows->2]
gremlin> g.addE('knows').from(g.V('1')).to(g.V('4')).property('weight', 1.0)
==>e[60b583cd-74fe-581d-f3b2-637328927188][1-knows->4]
// 这里介绍了两种不同的方法来添加边缘。
- 添加现代图形的其余部分
gremlin> g.V('1').addE('created').to(g.V('3')).property('weight', 0.4).next()
==>e[c4b583cd-06e0-9740-98a0-15f0ed923186][1-created->3]
gremlin> g.V('4').addE('created').to(g.V('5')).property('weight', 1.0).next()
==>e[7eb583cd-0793-821a-2466-78eba1efa94e][4-created->5]
gremlin> g.V('4').addE('knows').to(g.V('3')).property('weight', 0.4).next()
==>e[7ab583cd-083a-1491-a623-f7102b950e85][4-knows->3]
gremlin> g.V('6').addE('created').to(g.V('3')).property('weight', 0.2)
==>e[cab583cd-08e4-f637-944f-810fb09bda56][6-created->3]
- 删除顶点
gremlin> g.V().has('name', 'justin').drop()
gremlin>
// 删除 name 属性等于 justin 的顶点。
// 注意:到这里,您拥有了完整的 Apache TinkerPop 现代图形。TinkerPop 文档的“遍历”部分中的示例使用现代图形。
- 运行遍历
gremlin> g.V().hasLabel('person')
==>v[2]
==>v[6]
==>v[1]
==>v[4]
// 返回所有 person 顶点。
- 使用值运行遍历 (valueMap())
gremlin> g.V().has('name', 'marko').out('knows').valueMap()
==>{name=[vadas], age=[27]}
==>{name=[josh], age=[32]}
// 返回 marko“知道”的所有顶点的键值对。
- 指定多个标签
gremlin> g.addV("Label1::Label2::Label3")
==>v[54b583d3-f0a3-f0ce-2ddb-3e92a968744b]
// Neptune 支持一个顶点的多个标签。创建标签时,您可以指定多个标签,同时使用 :: 分隔它们。
// 此示例添加具有三个不同标签的顶点。
// hasLabel 步骤与具有以下任一三个标签的此顶点相匹配:hasLabel("Label1")、hasLabel("Label2") 和 hasLabel("Label3")。
// :: 分隔符仅用于此用途。
// 您不能在 hasLabel 步骤中指定多个标签。例如,hasLabel("Label1::Label2") 与任何内容都不匹配。
- 指定时间/日期
gremlin> g.V().property(single, 'lastUpdate', datetime('2018-01-01T00:00:00'))
==>v[2]
==>v[6]
==>v[54b583d3-f0a3-f0ce-2ddb-3e92a968744b]
==>v[1]
==>v[3]
==>v[4]
==>v[5]
// Neptune 不支持 Java 日期。改用 datetime() 函数。datetime() 接受符合 ISO8061 的 datetime 字符串。
// 它支持以下格式:YYYY-MM-DD、YYYY-MM-DDTHH:mm、YYYY-MM-DDTHH:mm:SS、YYYY-MM-DDTHH:mm:SSZ
- 删除顶点、属性或边
gremlin> g.V().hasLabel('person').properties('age').drop().iterate()
gremlin> g.V('1').drop().iterate()
gremlin> g.V().outE().hasLabel('created').drop()
gremlin>
// 注意 .next() 步骤不可与 .drop() 一起使用。请改用 .iterate()
完成后,键入以下命令以退出 Gremlin 控制台。
gremlin> :exit
Gremlin常用语法总结
Gremlin是 Apache TinkerPop 框架下的图遍历语言。Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(property graph)的遍历或查询。每个Gremlin遍历由一系列步骤(可能存在嵌套)组成,每一步都在数据流(data stream)上执行一个原子操作。
基本操作
Gremlin 语言包括三个基本的操作:
- map-step:对数据流中的对象进行转换;
- filter-step:对数据流中的对象就行过滤;
- sideEffect-step:对数据流进行计算统计;
核心概念
- Graph: 维护节点&边的集合,提供访问底层数据库功能,如事务功能。
- Element: 维护属性集合,和一个字符串label,表明这个element种类。
- Vertex: 继承自Element,维护了一组入度,出度的边集合。
- Edge: 继承自Element,维护一组入度,出度vertex节点集合。
- Property: kv键值对。
- VertexProperty: 节点的属性,有一组健值对kv,还有额外的properties 集合。同时也继承自element,必须有自己的id, label。
- Cardinality: 【single, list, set】 节点属性对应的value是单值,还是列表,或者set。
Gremlin 查询示例
- 准备:
gremlin> g.addV('person').property(id,'1').property('name','tom')
==>v[1]
gremlin> g.addV('person').property(id,'2').property('name','jack')
==>v[2]
gremlin> g.addV('software').property(id,'3').property('lang','java')
==>v[3]
gremlin> g.addE('uses').from(g.V('1')).to(g.V('3'))
==>e[8ab5866d-4a04-20cf-e4f4-610ec1b45a84][1-uses->3]
gremlin> g.addE('develops').from(g.V('2')).to(g.V('3'))
==>e[96b5866d-74b3-4980-b2b2-93abe93ab990][2-develops->3]
gremlin> g.addE('knows').from(g.V('1')).to(g.V('2'))
==>e[76b5866d-917c-c238-e37d-2ee823b897c2][1-knows->2]

* 顶点:
person
software
* 边:
uses(person -> software)
develops(person -> software)
knows(person -> person)
查询点
// 查询所有点,但限制点的返回数量为100,也可以使用range(x, y)的算子,返回区间内的点数量。
gremlin> g.V().limit(100)
==>v[2]
==>v[1]
==>v[3]
// 查询点的label值为'software'的点。
gremlin> g.V().hasLabel('software')
==>v[3]
// 查询id为‘1’的点。
gremlin> g.V('1')
==>v[1]
查询边
// 查询所有边,不推荐使用,边数过大时,这种查询方式不合理,一般需要添加过滤条件或限制返回数量。
gremlin> g.E()
==>e[96b5866d-74b3-4980-b2b2-93abe93ab990][2-develops->3]
==>e[76b5866d-917c-c238-e37d-2ee823b897c2][1-knows->2]
==>e[8ab5866d-4a04-20cf-e4f4-610ec1b45a84][1-uses->3]
// 查询边id为‘96b5866d-74b3-4980-b2b2-93abe93ab990’的边。
gremlin> g.E('96b5866d-74b3-4980-b2b2-93abe93ab990')
==>e[96b5866d-74b3-4980-b2b2-93abe93ab990][2-develops->3]
// 查询label为‘develops’的边。
gremlin> g.E().hasLabel('develops')
==>e[96b5866d-74b3-4980-b2b2-93abe93ab990][2-develops->3]
// 查询点id为‘2’所有label为‘develops’的边。
gremlin> g.V('2').outE('develops')
==>e[96b5866d-74b3-4980-b2b2-93abe93ab990][2-develops->3]
查询属性
// 查询点的所有属性(可填参数,表示只查询该点, 一个点所有属性一行结果)。
gremlin> g.V().limit(3).valueMap()
==>{name=[jack]}
==>{name=[tom]}
==>{lang=[java]}
// 查询点的label。
gremlin> g.V().limit(1).label()
==>person
// 查询点的name属性(可不填参数,表示查询所有属性, 一个点每个属性一行结果,只有value,没有key)。
gremlin> g.V().limit(10).values('name')
==>jack
==>tom
新增点
//新增点,Label为user,ID为500,age为18-24。
Graph graph = TinkerGraph.open();
graph.addVertex(label,'person',id,'500','age','18-24')
- neptune支持方式:
//新增点,Label为user,ID为500,age为18。
gremlin> g.addV('person').property(id,'500').property('age','18')
==>v[500]
新增边
a = graph.addVertex(label,'person',id,'501','age','18-24')
b = graph.addVertex(label,'software',id,'502','title','love')
// 新增边,边的两个点ID分别为501、502。
a.addEdge('develops', b, 'Year','1994')
- neptune支持方式:neptune暂不支持变量
g.addV('person').property(id,'501').property('age', 24)
g.addV('software').property(id,'502').property('title', 'love')
g.V('501').addE('develops').to(g.V('502')).property('Year', '1994')
删除点
// 删除ID为600的点。
g.V('600').drop()
删除边
// 删除ID为“501-502-0”的边。
g.E('501-502-0').drop()
Gremlin语法特性
- 数据准备:
// 添加顶点
gremlin> g.addV('person').property(id, '1').property('name', 'marko').property('age', 29)
==>v[1]
gremlin> g.addV('person').property(id, '2').property('name', 'vadas').property('age', 27)
==>v[2]
gremlin> g.addV('software').property(id, '3').property('name', 'lop').property('lang', 'java')
==>v[3]
gremlin> g.addV('person').property(id, '4').property('name', 'josh').property('age', 32)
==>v[4]
gremlin> g.addV('software').property(id, '5').property('name', 'ripple').property('lang', 'java')
==>v[5]
gremlin> g.addV('person').property(id, '6').property('name', 'peter').property('age', 35)
==>v[6]
// 添加边
gremlin> g.addE('knows').from(g.V('1')).to(g.V('2')).property(id, '7').property('weight', 0.5)
==>e[7][1-knows->2]
gremlin> g.addE('knows').from(g.V('1')).to(g.V('4')).property(id, '8').property('weight', 1.0)
==>e[8][1-knows->4]
gremlin> g.addE('created').from(g.V('1')).to(g.V('3')).property(id, '9').property('weight', 0.4)
==>e[9][1-created->3]
gremlin> g.addE('created').from(g.V('4')).to(g.V('5')).property(id, '10').property('weight', 1.0)
==>e[10][4-created->5]
gremlin> g.addE('created').from(g.V('4')).to(g.V('3')).property(id, '11').property('weight', 0.4)
==>e[11][4-created->3]
gremlin> g.addE('created').from(g.V('6')).to(g.V('3')).property(id, '12').property('weight', 0.2)
==>e[12][6-created->3]
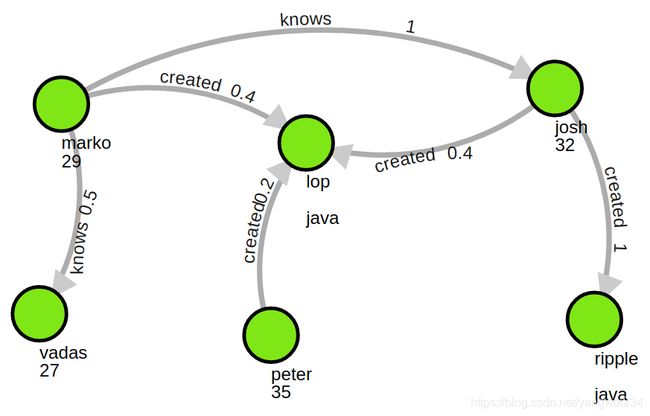
基础
- V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例,g.V(),g.V(‘v_id’),查询所有点和特定点。
- E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多。
- id():获取顶点、边的id。例:g.V().id(),查询所有顶点的id。
- label():获取顶点、边的 label。例:g.V().label(),可查询所有顶点的label。
- key() / value():获取属性的key/value的值。
- properties():获取顶点、边的属性;可以和 key()、value()搭配使用,以获取属性的名称或值。例:g.V().properties(‘name’),查询所有顶点的 name 属性。例如:g.V().properties().key()、g.V().properties().value()
- valueMap():获取顶点、边的属性,以Map的形式体现,和properties()比较像。
- values():获取顶点、边的属性值。例,g.V().values() 等于 g.V().properties().value()。
遍历
顶点为基准:
- out(label):根据指定的 Edge Label 来访问顶点的 OUT 方向邻接点(可以是零个 Edge Label,代表所有类型边;也可以一个或多个 Edge Label,代表任意给定 Edge Label 的边,下同)。
- in(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接点。
- both(label):根据指定的 Edge Label 来访问顶点的双向邻接点。
- outE(label):根据指定的 Edge Label 来访问顶点的 OUT 方向邻接边。
- inE(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接边。
- bothE(label):根据指定的 Edge Label 来访问顶点的双向邻接边。
边为基准的: - outV():访问边的出顶点,出顶点是指边的起始顶点。
- inV():访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点。
- bothV():访问边的双向顶点。
- otherV():访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点。
过滤
在众多Gremlin的语句中,有一大类是filter类型,顾名思义,就是对输入的对象进行条件判断,只有满足过滤条件的对象才可以通过filter进入下一步。
has
has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。常用的有下面几种:
- has(key,value):通过属性的名字和值来过滤顶点或边。
- has(label, key, value):通过label、属性的名字和值过滤顶点和边。
- has(key,predicate):通过对指定属性用条件过滤顶点和边,例:g.V().has(‘age’, gt(20)),可得到年龄大于20的顶点。
- hasLabel(labels…):通过 label 来过滤顶点或边,满足label列表中一个即可通过。
- hasId(ids…):通过 id 来过滤顶点或者边,满足id列表中的一个即可通过。
- hasKey(keys…):通过 properties 中的若干 key 过滤顶点或边。
- hasValue(values…):通过 properties 中的若干 value 过滤顶点或边。
- has(key):properties 中存在 key 这个属性则通过,等价于hasKey(key)。
- hasNot(key): 和 has(key) 相反。
例子:
// lable 等于 person 的所有顶点
g.V().hasLabel('person')
// 所有年龄在20(含)~30(不含)之间的顶点
g.V().has('age',inside(20,30)).values('age')
// 所有年龄不在20(含)~30(不含)之间的顶点
g.V().has('age',outside(20,30)).values('age')
// name 是'josh'或'marko'的顶点的属性
g.V().has('name',within('josh','marko')).valueMap()
// name 不是'josh'或'marko'的顶点的属性
g.V().has('name',without('josh','marko')).valueMap()
// 同上
g.V().has('name',not(within('josh','marko'))).valueMap() g.V().hasNot('age').values('name')
// age 这个属性的所有 value
g.V().properties().hasKey('age').value()
// 不含 age 这个属性的所有 顶点的 name 属性
g.V().hasNot('age').values('name')
路径
- 在使用Gremlin对图进行分析时,关注点有时并不仅仅在最终达到顶点、边或者属性,通过什么样的路径到达最终的顶点、边和属性同样重要。此时可以借助path() 来获取经过的路径信息。
- path() 返回当前遍历过的所有路径。有时需要对路径进行过滤,只选择没有环路的路径或者选择包含环路的路径,Gremlin 针对这种需求提供了两种过滤路径的step:simplePath() 和cyclicPath()。
path():获取当前遍历过的所有路径;
simplePath():过滤掉路径中含有环路的对象,只保留路径中不含有环路的对象;
cyclicPath():过滤掉路径中不含有环路的对象,只保留路径中含有环路的对象。
- 例子
// 寻找4跳以内从 andy 到 jack 的最短路径
g.V("andy").repeat(both().simplePath()).until(hasId("target_v_id").and().loops().is(lte(4))).hasId("jack").path().limit(1)
// “Titan” 顶点到与其有两层关系的顶点的不含环路的路径(只包含顶点)
g.V().hasLabel('software').has('name','Titan').both().both().simplePath().path()
迭代
- repeat():指定要重复执行的语句。
- times(): 指定要重复执行的次数,如执行3次。
- until():指定循环终止的条件,如一直找到某个名字的朋友为止。
- emit():指定循环语句的执行过程中收集数据的条件,每一步的结果只要符合条件则被收集,不指定条件时收集所有结果。
- loops():当前循环的次数,可用于控制最大循环次数等,如最多执行3次。
* repeat() 和 until() 的位置不同,决定了不同的循环效果:
repeat() + until():等同 do-while;
until() + repeat():等同 while-do。
* repeat() 和 emit() 的位置不同,决定了不同的循环效果:
repeat() + emit():先执行后收集;
emit() + repeat():表示先收集再执行。
注意:
emit()与times()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。
emit()与until()搭配使用时,是“或”的关系而不是“与”的关系,满足两者间任意一个即可。
- 例1:根据出边进行遍历,直到抵达叶子节点(无出边的顶点),输出其路径顶点名
g.V('1').repeat(out()).until(outE().count().is('0')).path().by('name')
- 例2:查询顶点’1’的’3’度 OUT 可达点路径
g.V('1').repeat(out()).until(loops().is('3')).path()
转换
- map():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象(一对一),以便进行下一步处理。
- flatMap():可以接受一个遍历器 Step 或 Lamda 表达式,将遍历器中的元素映射(转换)成另一个类型的某个对象流或迭代器(一对多)。
- 例子:
// 创建了 titan 的作者节点的姓名
g.V('titan').in('created').map(values('name'))
// 创建了 titan 的作者节点的所有出边
g.V('titan').in('created').flatMap(outE())
排序
- order()
- order().by()
// 默认升序排列
g.V().values('name').order()
// 按照元素属性age的值升序排列,并只输出姓名
g.V().hasLabel('person').order().by('age', asc).values('name')
逻辑
- is():可以接受一个对象(能判断相等)或一个判断语句(如:P.gt()、P.lt()、P.inside()等),当接受的是对象时,原遍历器中的元素必须与对象相等才会保留;当接受的是判断语句时,原遍历器中的元素满足判断才会保留,其实接受一个对象相当于P.eq()。
- and():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只有在每个新遍历器中都能生成至少一个输出的情况下才会保留,相当于过滤器组合的与条件。
- or():可以接受任意数量的遍历器(traversal),原遍历器中的元素,只要在全部新遍历器中能生成至少一个输出的情况下就会保留,相当于过滤器组合的或条件。
- not():仅能接受一个遍历器(traversal),原遍历器中的元素,在新遍历器中能生成输出时会被移除,不能生成输出时则会保留,相当于过滤器的非条件。
- 例1:
// 筛选出顶点属性“age”等于28的属性值,与`is(P.eq(28))`等效
g.V().values('age').is(28)
// 所有包含出边“supports”和“created”的顶点的名字“name”
g.V().and(outE('supports'), outE('created')).values('name')
// 使用 where语句 实现上面的功能
g.V().where(outE('supports').and().outE('created').values('name')
// 筛选出所有不是“person”的顶点的“label”
g.V().not(hasLabel('person')).label()
- 例2:获取所有最多只有一条“created”边并且年龄不等于28的“person”顶点
gremlin> g.V().hasLabel('person').and(outE('created').count().is(lte(1)), values("age").is(P.not(P.eq(28)))).values('name')
==>vadas
==>peter
==>marko
统计
- sum():将 traversal 中的所有的数字求和。
- max():对 traversal 中的所有的数字求最大值。
- min():对 traversal 中的所有的数字求最小值。
- mean():将 traversal 中的所有的数字求均值。
- count():统计 traversal 中 item 总数。
- 例子:
// 计算所有“person”的“created”出边数的均值
g.V().hasLabel('person').map(outE('created').count()).mean()
分支
- choose():分支选择, 常用使用场景为: choose(predicate, true-traversal, false-traversal),根据 predicate 判断,当前对象满足时,继续 true-traversal,否则继续 false-traversal。
- optional():类似于 by() 无实际意义,搭配 choose() 使用。
- 例1:
if-else
gremlin> g.V().hasLabel('person').choose(values('age').is(lte(30)),__.in(),__.out()).values('name')
==>marko
==>lop
==>lop
==>ripple
// 结果分析:g.V().hasLabel('person').values('age').is(lte(30)) 的结果是27,29
// 所以 true-traversal——【27,29】:__in()求入度,age=27的入度顶点name是marko,age=29的入度顶点没有
// false-traversal——【32,35】:__out()求出度,age=35的出度顶点name为lop,age=32的出度顶点name为lop和ripple
- 例2:
if-elseif-else
// 查找所有的“person”类型的顶点
// 如果“age”属性等于0,输出名字
// 如果“age”属性等于28,输出年龄
// 如果“age”属性等于29,输出他开发的软件的名字
// choose(predicate).option().option()...
gremlin> g.V().hasLabel('person').choose(values('age')).option(0, values('name')).option(28, values('age')).option(29, __.out('created').values('lang'))
==>java
//
gremlin> g.V().hasLabel('person').choose(values('age')).option(0, values('name')).option(28, values('age')).option(29, __.out('created').values('name')).option(none, values('name'))
==>vadas
==>peter
==>lop
==>josh
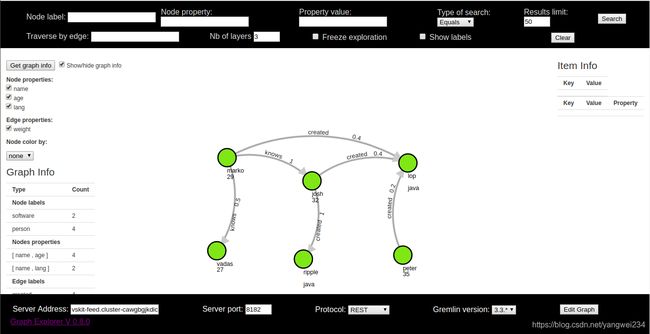
Neptune可视化工具范例.jpg(在这里输入文件名)

基于 github 的一个开源项目 graphexp 实现 Neptune 图数据库可视化。