轻量级卷积网络DenseNet:密集连接卷积网络
原文地址:CVPR 2017
《Densely Connected Convolutional Networks》
卷积神经网络如何提高效果:
网络做得更深:ResNet,解决了网络深时的梯度消失问题;
网络做得更宽:即增加每一层的输入输出通道数,例如GoogleNet的Inception;
还有什么方法可以提高网络的效果呢?
作者的想法则是从feature map入手,通过对feature的极致利用达到更好的效果和更少的参数,希望网络可以支持百层以上的深度,以减少更多的参数和计算量来实现更高的性能。
亮点:
- 减轻了网络深度带来的梯度消失现象;
- 加强了feature map传递,更有效地利用了浅层的feature map;
- 一定程度上减少了网络的参数量;
- 通过特征在channel上的连接来实现特征重用(feature reuse)。
1. 来源:
ResNet模型的核心是通过建立前面层与后面层之间的“短路连接”(shortcuts,skip connection),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络。残差网络能够应用在特别深的网络中的一个重要原因是,shortcut连接无论正向计算精度还是反向计算梯度,信息都能毫无损失的从一层传到另一层。如果我们的目的是保证信息毫无阻碍的传播,那么残差网络的残差块的设计便不是信息流通最合适的结构。作者延续这个思路,建立前面所有层与后面层的密集连接(dense connection),即在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来,为了能够保证前馈的特性,每一层将之前所有层的输入进行拼接,之后将输出的特征图传递给之后的所有层。
2. Dense block:
对于每一层,将所有先前层的特征图用作输入,并将其自己的特征图用作所有后续层的输入。
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。
如下图:x0是input,H1的输入是x0(input),H2的输入是x0和x1(x1是H1的输出)。。。依此类推。
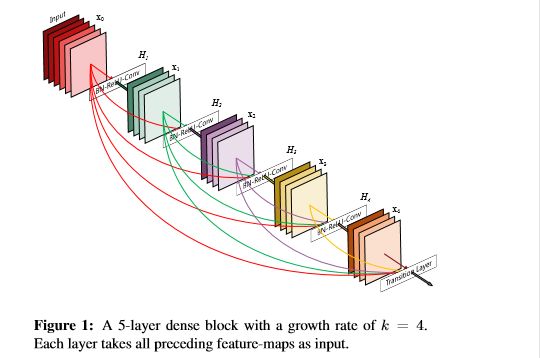
1. 这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。每一层都可以直接利用损失函数的梯度以及最开始的输入信息,相当于是一种隐形的深度监督(implicit deep supervision),这有助于训练更深的网络,密集连接方式相当于每一层都直接连接输入和损失,因此可以减轻梯度消失现象;
2. 稠密连接模块(dense block)的一个优点是它比传统的卷积网络有更少的参数,因为它不需要再重新学习多余的特征图。传统的前馈结构可以被看成一种层与层之间状态传递的算法。每一层接收前一层的状态,然后将新的状态传递给下一层。它改变了状态,但也传递了需要保留的信息。DenseNet结构中,增加到网络中的信息与保留的信息有着明显的不同。DenseNet的dense block中每个卷积层都很窄(例如每一层有12个滤波器),仅仅增加小数量的特征图到网络的“集体知识”(collective knowledge),并且保持这些特征图不变——最后的分类器基于网络中的所有特征图进行预测。另外作者这种密集连接有正则化的效果,因此对于过拟合有一定的抑制作用,因为参数减少了,所以过拟合现象减轻;
3. 特征重用(feature reuse),每层的输出特征图都是先前所有层的输入,加强了特征的传递,更有效地利用了特征;
4. 计算:假设一张图片x0在卷积网络中传播。网络共有L层,每一层都有一个非线性转换函数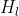 (定义为三种操作的组合函数,分别是:BN、ReLU和卷积),其中l表示第几层。用
(定义为三种操作的组合函数,分别是:BN、ReLU和卷积),其中l表示第几层。用 表示第l层的输出。
表示第l层的输出。
传统的前馈网络是将l-1层的输出作为l层的输入,得到l层的输出,可用以下方程来表示:
![]()
ResNets增加了一个跨层连接,将自身与非线性转换的结果相加:
![]()
DenseNets为了更好的改善层与层之间信息的传递,提出一种不同的连接模式:将该层与之后的所有层进行连接:
![]()
DenseNet与传统cnn权重参数量对比 :

5. 合成函数:位于Dense Block的每一个节点中,其输入是拼接在一起的Feature Map, 输出则是这些特征经过BN->ReLU->3*3卷积的三步得到的结果,其中卷积的Feature Map的数量是成长率(Growth Rate),DenseNet用concat在channel上进行维度拼接。
3. 网络结构:
在这个结构图中包含了3个dense block。作者将DenseNet分成多个dense block,原因是希望各个dense block内的feature map的size统一,这样在做concatenation就不会有size的问题。
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。如图所示,DenseNet的网络结构主要由DenseBlock和Transition组成

1. 增长速率k(growth rate):Dense block中,如果每个层函数 都产生k个特征图,那么第l层就有 ![]() 个特征图作为输入,其中k0表示输入层的通道数。DenseNet和现存网络结构的一个很重要的不同是,DenseNet的网络很窄,如k=12 。超参数k称为网络的增长速率。一个很小的增长速率在测试的数据集上就可以获得不错的效果,因为每一层都可以和它所在的block中之前的所有特征图进行连接,使得网络具有了“集体知识”(collective knowledge)。可以将特征图看作是网络的全局状态,每一层相当于是对当前状态增加 k 个特征图。增长速率控制着每一层有多少信息对全局状态有效。全局状态一旦被写定,就可以在网络中的任何地方被调用,而不用像传统的网络结构那样层与层之间的不断重复;
个特征图作为输入,其中k0表示输入层的通道数。DenseNet和现存网络结构的一个很重要的不同是,DenseNet的网络很窄,如k=12 。超参数k称为网络的增长速率。一个很小的增长速率在测试的数据集上就可以获得不错的效果,因为每一层都可以和它所在的block中之前的所有特征图进行连接,使得网络具有了“集体知识”(collective knowledge)。可以将特征图看作是网络的全局状态,每一层相当于是对当前状态增加 k 个特征图。增长速率控制着每一层有多少信息对全局状态有效。全局状态一旦被写定,就可以在网络中的任何地方被调用,而不用像传统的网络结构那样层与层之间的不断重复;
2. Bottleneck层:尽管每一层只产生 k 个输出特征图,但是后面几层可以得到前面所有层的输入,因此拼接后的输入通道数还是比较大的。又每个dense block的中3x3的卷积之前加入1x1的卷积可以减少输入的特征图数量,减小计算量,同时能融合各个通道的特征。将具有bottleneck层,即 BN-ReLU-Conv(1x1)-BN-ReLU-Conv(3x3) 的结构称为DenseNet-B。DenseNet先使用了1*1卷积将输入数据channel降维到4k,再使用3*3卷积提取特征;
关于Block,有以下4个细节:
1、每一个Bottleneck输出的特征通道数是相同的,例如这里的32。同时可以看到,经过Concatnate操作后的通道数是按32的增长量增加的,因此这个32也被称为GrowthRate;
2、1×1卷积的作用是固定输出通道数,达到降维的作用。当几十个Bottleneck相连接时,Concatnate后的通道数会增加到上千,如果不增加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。1×1卷积的通道数通常是GrowthRate的4倍;
3、特征传递方式是直接将前面所有层的特征Concatnate后传到下一层,而不是前面层都要有一个箭头指向后面的所有层;
4、Block采用了激活函数在前、卷积层在后的顺序。
3. Transition layer:每两个dense block之间的层称为Transition layer,完成卷积和池化的操作,目的是减小特征图的数量。过渡层由BN层、1x1卷积层和2x2平均池化层组成:1×1卷积的作用是降维,起到压缩模型的作用,而平均池化则是降低特征图的尺寸,使feature maps的尺寸减半。 如果一个dense block有m个特征图,我们让之后的过渡层生成![]() 个输出特征图,其中
个输出特征图,其中 表示压缩(compression)系数。定义
表示压缩(compression)系数。定义![]() 的 DenseNet 为 DenseNet-C,实验中
的 DenseNet 为 DenseNet-C,实验中![]() 。如果bottleneck和过渡层都有
。如果bottleneck和过渡层都有![]() ,我们称该模型为DenseNet-BC。
,我们称该模型为DenseNet-BC。
4. 实现: 在进入第一个dense block之前,输入图像先经过了16个(DenseNet-BC中是两倍的增长速率)卷积。对于3x3的卷积层,使用一个像素的零填充来保证特征图尺寸不变。在两个dense block之间的过渡层中,我们在2x2的平均池化层之后增加了1x1的卷积。在最后一个dense block之后,使用全局平均池化和softmax分类器。三个dense block的特征图的尺寸分别是32x32,16x16,8x8。

实现细节:
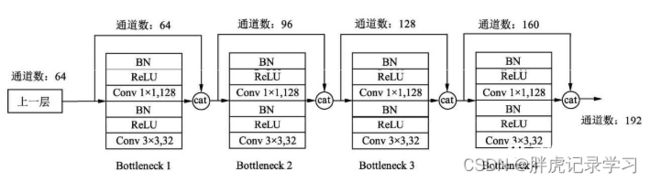 以DenseNet-121为例,看下其网络构成:
以DenseNet-121为例,看下其网络构成:
1、DenseNet-121由121层权重层组成(其中4个Dense block,共计2×(6+12+24+16) = 116层权重,加上初始输入的1卷积层+3过渡层+最后输出的全连接层,共计121层);
2、训练时采用了DenseNet-BC结构,压缩因子0.5,增长率k = 32;
3、初始卷积层有2k个filter,经过7×7卷积将224×224的输入图片缩减至112×112;Denseblock块由layer堆叠而成,layer的尺寸都相同:1×1+3×3的两层conv(每层conv = BN+ReLU+Conv);Denseblock间由过渡层构成,过渡层通过2×2pool stride2使特征图尺寸缩小一半。最后经过全局平均池化 + 全连接层的1000路softmax得到输出。
4. 总结:
DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Translation layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了;
DenseNet的不足在于由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术,应用起来没有ResNet广泛。
参考:
DenseNet:比ResNet更优的CNN模型
DenseNet算法详解
仅为学习记录,侵删!