MeanTeacher文章解读+算法流程+核心代码详解
MeanTeacher
本博客仅做算法流程疏导,具体细节请参见原文
原文
原文链接点这里
Github 代码
Github代码点这里
解读
论文解读点这里
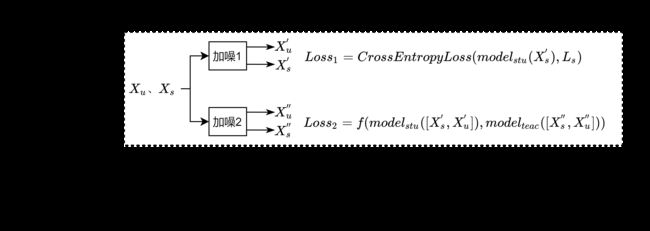
算法流程
代码详解
train_transform = data.TransformTwice(transforms.Compose([
data.RandomTranslateWithReflect(4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))]))
eval_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))
])
这是图像的预处理,TransformTwice可以读两个数据流。
在训练阶段,有:
for i, ((input, ema_input), target) in enumerate(train_loader):
可以看到,通过train_transform出来的batch中,有两个数据流input和ema_input,其数据为同组数据加不同噪声后的形式,即算法流程中的 [ X u ′ , X s ′ ] [X^{'}_u,X^{'}_s] [Xu′,Xs′]和 [ X u ′ ′ , X s ′ ′ ] [X^{''}_u,X^{''}_s] [Xu′′,Xs′′]。每个数据流中包含了一定数量的有标记样本和无标记样本。target是这两个数据流的标签,其中无标记样本的标签为-1.
class_loss = class_criterion(model_out, target_var) / minibatch_size
consistency_weight = get_current_consistency_weight(epoch)
consistency_loss = consistency_weight * consistency_criterion(model_out, ema_logit) / minibatch_size
class_loss正如算法流程中的 L o s s 1 Loss_1 Loss1,是stu模型输出结果和标签的CrossEntropyLoss;consistency_loss如算法流程中的 L o s s 2 Loss_2 Loss2,是两个 [ X u ′ , X s ′ ] [X^{'}_u,X^{'}_s] [Xu′,Xs′]和 [ X u ′ ′ , X s ′ ′ ] [X^{''}_u,X^{''}_s] [Xu′′,Xs′′]的一致性损失,文章中直接选择的MSE损失函数。为了让模型训练更合理, L o s s 2 Loss_2 Loss2有一个渐增系数consistency_weight。
loss.backward() # student 模型的更新
optimizer.step()
global_step += 1
update_ema_variables(model, ema_model, args.ema_decay, global_step) # teacher 模型的更新
student模型更新为 L o s s = L o s s 1 + L o s s 2 Loss=Loss_1+Loss_2 Loss=Loss1+Loss2的反向梯度传播更新权值;teacher模型更新为当前student和上一个epoch的teacher模型的加权,即EMA平滑版本。
主要思想
算法比较简单,主要思想我觉得可以分为两部分:第一部分是原始样本的轻微扰动版本的预测结果应该与原样本属于同一类别;第二部分,希望通过模型的EMA版本作为分类更有可靠性的模型,即teacher来引导当前模型student模型训练,二者合并就是consistency_loss。