语义分割中的训练策略和参数设置
下面主要总结一下语义分割和边缘检测中,训练策略和参数的情况:
首先祭出谷歌在训练VGG分类网络时的训练参数,尽管本文专注于分割和边缘检测,但是还是看一下吧
batch size: 256
learning rate: 初始化为0.01, val accuracy不再改进时,减少10倍,一共减了3次;
momentum: 0.9
training time: 74 epochs(370K iterations)

一、FCN
FCN CVPR-Version 的训练参数,VGG是从ImageNet分类网络的VGG初始化开始fine-tune的,
batch size: 20
fixed learning rate: 10−4 , double learning rate for baises.
momentum: 0.9
weight decay: 5−4 or 2−4
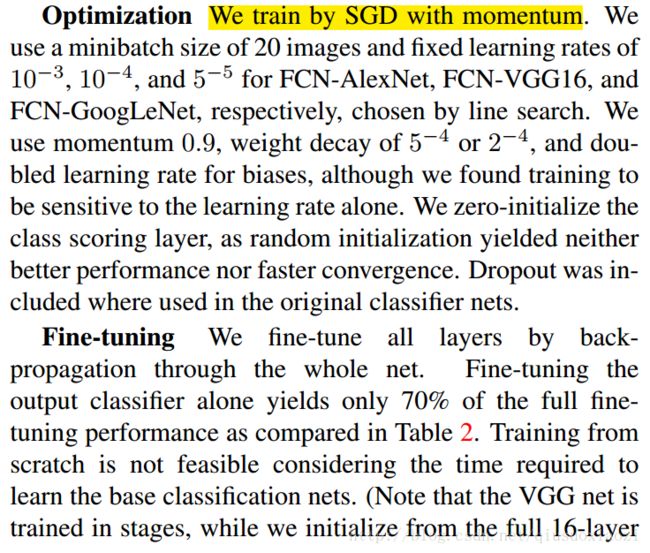

FCN PAMI-Version的训练设定,使用了unnormalized softmax loss(因此base_lr小多了)和heavy online learning(batch_size or iter_size=1, high momentum)。文章提到相比CVPR的训练又快又好,先前不知道还有两个版本的文章有这些差别,邮件咨询Evan Shelhamer后才知道,相关讨论见文末。
train_net: "train.prototxt"
test_net: "val.prototxt"
test_iter: 736
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-14
# high momentum
momentum: 0.99
# no gradient accumulation
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 4000
snapshot_prefix: "snapshot/train"
test_initialization: false二、DeepLab
batch size: 20
lr_policy: poly policy is better than step policy (属于DeepLab-v2做出的三点改进:poly learning policy, ASPP, deeper and multiscale nets之一,效果显著,并且被PSPNet借鉴)
initial learning rate: 0.001(0.01 for the final classifier layer), 每2000个iterations减少10倍
momentum: 0.9
weight decay: 0.0005


poly policy优于step policy. Batch size 和 Iterations的数目同样对于精度有显著影响

三、DeconvNets
learning rate: 0.01, 特别提到了根据val accuracy指数级别低减小learning rate
Two stage的training,先用simple example train,然后是hard example.
momentum: 0.9
weight decay: 0.0005

四、Dilated ConvNets
batch size: 14
learning rate: 10−3 for first 100K iterations and 10−4 for subsequent 40K iterations (first stage trained on VOC12+COCO), 10−5 for 50K iterations(second stage fine-tuned on VOC12)
momentum: 0.9

五、PSPNet
learning_rate: 0.01
lr_policy: poly(power:0.9) 这一点是借鉴的DeepLab-v2,PSPNet在oral presentation的时候也提到了,说明确实有效果
momentum: 0.9
weight decay: 10−4
iterations: 30K iterations in VOC12
average pooling works better than max pooling
后面还提到的larger cropsize和batchsize更好,估计是受了FCN的影响?


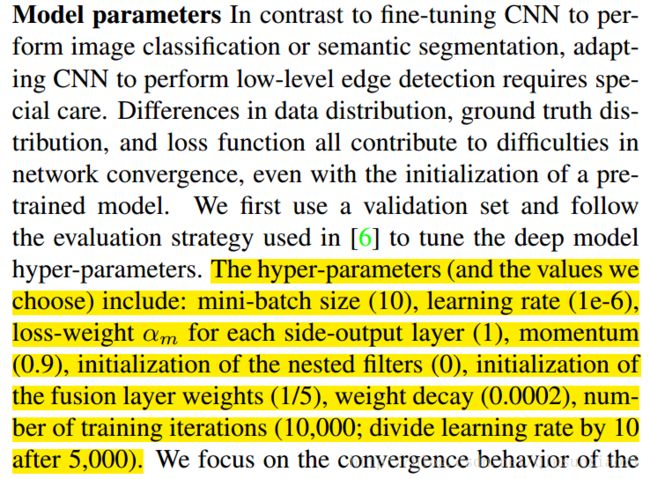
六、 HED
batch size: 10
learning rate: 10−6 , divide learning rate by 10 after 5000
loss weight αm for each side-output layer
momentum: 0.9 (好像常常都设成了0.9)
initializaton weight of fusion layer: 0.5
weight decay: 0.0002
iterations: 10000
以上大致介绍了一些经典方法中的训练策略和参数,接下来要针对性地看看他们prototxt中的网络结构和参数。
今天解决两个问题,一个是借鉴HED的class weight的做法,再就是借鉴其他论文进行网络参数的微调。
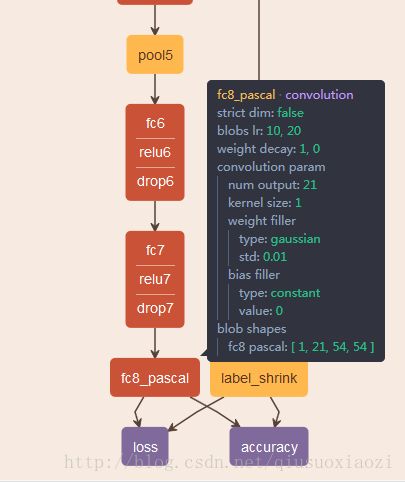
一、 FCN
卷积层(除了deconvolution layer没有learning)都是1-1-2-0的格式

二、 DeepLab
DeepLab-v2,截止到最后一层conv layer,前边的lr_mult, decay_mult全是1-1-2-0的格式
值得注意的是,DeepLab-v2在ASPP中使用了dropout,而PSPNet中则没有用。

base_lr是 10−3 ,然后最后一层conv layer的学习率扩大10倍( 10−2 ),并且使用高斯kernel初始化

回看DeepLab-v1(DeepLab-v1没有使用ASPP)亦如是

最后一层conv layer
三、DeconvNets
lr_mult, decay_mult又是1-1-2-0的格式。看来这真不是巧合了,估计已经是默认的“行业规范”了。
至于base_lr是 10−2 ,使用了two stage的训练方法,先用simple sample train,然后是hard sample.
值得注意的是,DeconvNets中,VGG16的conv block和deconv block都加了BN,而且作者在文章中说,他们观察到使用和不使用BN的差别很大,使用BN能更好地optimize network

自己的一些体会: 从上面三篇工作来看,base_lr的选择不尽相同,但是初始都不太小,差不多都是 10−4 到 10−2 (有一点没搞明白的是FCN里面文章中说的是 10−4 但是代码中用的是 10−14 ,正在等待Evan Shelhamer的回复),然后逐步减小; 从FCN论文中提到double bias learning rate之后,其后的文章差不多都沿用了这个设定。
四、Dilated ConvNets
1-1-2-0 again, 然后base_lr是 10−5 .
五、PSPNet
PSPNet使用的ResNet,详细的参数设置与前面介绍的VGG-based network没有可比性,如果要使用resnet的话可以参考PSPNet。
base_lr是0.01,然后学习了DeepLab使用了poly training policy.
===============================================================================
SPECIAL SECTION for FCN
Evan Shelhamer在回复的邮件中提到他们后来的PAMI论文中针对先前CVPR中的FCN的优化问题做了进一步的研究,并且提出了更加快而好的训练方法(heavy online learning)。
After the CVPR paper we figured out improved optimization settings that give better accuracy and faster training. The reference implementation follows the improved settings, without normalizing the loss and setting the learning rate much lower accordingly.
回复的文字来看,大致是不再normalize loss(没太搞懂啥意思??)并且设置更小的leanring rate。这也是现在released code中采用的训练策略。
在具体的实现上,从solver.prototxt中可以发现
# NOTE: following optimization settings correspond to FCN PAMI-version, heavy online learning(iter_size=1)
train_net: "train.prototxt"
test_net: "val.prototxt"
test_iter: 736
# make test net, but don't invoke it from the solver itself
test_interval: 999999999
display: 20
average_loss: 20
lr_policy: "fixed"
# lr for unnormalized softmax
base_lr: 1e-14
# high momentum
momentum: 0.99
# no gradient accumulation, heavy online learning indicated in FCN PAMI-version
iter_size: 1
max_iter: 100000
weight_decay: 0.0005
snapshot: 4000
snapshot_prefix: "snapshot/train"
test_initialization: false作者设置了iter_size:1(相当于batch_size为1),然后momentum:0.99(high momentum),因此形成了heavy learning,具体原因请见原文。这里还要特地解释一下iter_size和batch_size的区别:
而在caffe.proto中,对于iter_size的定义是
// accumulate gradients over
iter_sizexbatch_sizeinstances
optional int32 iter_size = 36 [default = 1];
而在FCN PAMI-Version中,作者说到
In the first, gradients are accumulated over 20 images. Accumulation reduces the memory required and respects the different dimensions of each input by reshaping the network.
言下之意,iter_size可以减小对GPU memory的需求。因此当GPU momory不够时,使用iter_size配合batch_size是一个不错的选择(在Fisher Yu的dilated convnets中也是这么做的)!所以可以理解成,iter_size是一个偏“外层”的参数,可以在batch_size作用的基础上进行gradients accumulate。 看solver.cpp也可以发现,iter_size是在ForwardBackward()外面起作用的,而batch_size是在函数里面:
// accumulate the loss and gradient
Dtype loss = 0;
for (int i = 0; i < param_.iter_size(); ++i) {
loss += net_->ForwardBackward();
}
loss /= param_.iter_size();有了这个功能,iter_size就可以有另外一个batch_size所完成不了的功能。
在caffe-users mailing list中有一个问题:有人提问有没有一种方法可以实现进行batch training时,让batch内的image shape不一样。对此,Evan Shelhamer就推荐了使用iter_size的做法(这也是他在FCN中使用的iter_size:1,mementum:0.99(high)进行heavy online learning的方法)。具体的帖子见:
https://groups.google.com/forum/#!searchin/caffe-users/iter_size|sort:relevance/caffe-users/oTsYVAHzJQA/6tSNwVIPAQAJ
还有一个帖子,关于actual behavior of iter_size,也很不错
https://groups.google.com/forum/#!searchin/caffe-users/iter_size|sort:relevance/caffe-users/PMbycfbpKcY/FTBiMKunEQAJ
其中提到了关于为什么iter_size可以节省GPU memory的原因:
Each time, it loads ‘batch_size’ examples, computes loss&gradients and then discards the examples, resulting in less memory than using a larger ‘batch_size’.
看完Evan Shelhamer的回答之后,意识到是否进行loss的normalization对于base_lr的数量级是有很大的影响的。而根据caffe.proto的相关定义
enum NormalizationMode {
// Divide by the number of examples in the batch times spatial dimensions.
// Outputs that receive the ignore label will NOT be ignored in computing
// the normalization factor.
FULL = 0;
// Divide by the total number of output locations that do not take the
// ignore_label. If ignore_label is not set, this behaves like FULL.
VALID = 1;
// Divide by the batch size.
BATCH_SIZE = 2;
// Do not normalize the loss.
NONE = 3;
}
// For historical reasons, the default normalization for
// SigmoidCrossEntropyLoss is BATCH_SIZE and *not* VALID.
optional NormalizationMode normalization = 3 [default = VALID];
// Deprecated. Ignored if normalization is specified. If normalization
// is not specified, then setting this to false will be equivalent to
// normalization = BATCH_SIZE to be consistent with previous behavior.
optional bool normalize = 2;可以知道,对于SoftmaxWithLossLayer,如果normalize未设置或为True,则默认是VALID Normalization,见softmax_loss_layer.cpp的片段
if (!this->layer_param_.loss_param().has_normalization() &&
this->layer_param_.loss_param().has_normalize()) {
normalization_ = this->layer_param_.loss_param().normalize() ?
LossParameter_NormalizationMode_VALID :
LossParameter_NormalizationMode_BATCH_SIZE;
} else {
normalization_ = this->layer_param_.loss_param().normalization();
}而对于SigmoidCrossEntropyLossLayer,caffe.proto也交代了,因为历史原因略有不同,默认是BATCH_SIZE Normalization:
if (this->layer_param_.loss_param().has_normalization()) {
normalization_ = this->layer_param_.loss_param().normalization();
} else if (this->layer_param_.loss_param().has_normalize()) {
normalization_ = this->layer_param_.loss_param().normalize() ?
LossParameter_NormalizationMode_VALID :
LossParameter_NormalizationMode_BATCH_SIZE;
} else {
normalization_ = LossParameter_NormalizationMode_BATCH_SIZE;
}因此要特别注意!
比如,在以上所有提到的语义分割论文(除了“奇葩”的FCN PAMI-Version)中,最后的softmax loss layer压根就没考虑normalize的事,所以都是默认进行Valid normalization;而HED和程明明的Richer Convolutional Features for Edge Detection一文中,也没有考虑normalize的事,则是默认的batch_size normalization.
===============================================================================