linux内存管理笔记(三十八)----反向映射
用户进程在使用虚拟内存的过程中,从虚拟内存页面映射到物理内存页面时,PTE保留这个记录,page数据结构中的_mapcout记录有多少个用户PTE映射到物理页面。用户PTE是指用户进程地址空间到物理页面的建立映射的PTE,不包括内核地址空间映射到物理页面所产生的PTE,其要面对以下的问题
- 有些页面需要迁移
- 有些页面长时间不适用,需要交换到磁盘
- 在交换之前,必须找到哪个进程适用这个页面,然后解除这些映射的用户PTE
- 一个物理页面可以同时被多个进程的虚拟内存映射,但是一个虚拟页面同时只能映射到一个物理页面
在Linux内核中,为了确保一个页面释放被某个进程映射,必须遍历每个进程的页表,因此工作量相当大,效率很低。为了解决这个问题,内核开发期间,就提出了反向映射的概念。
1. 什么是反向映射
在了解反向映射之前,我们先要了解下什么是正向映射?
正向映射,操作系统开启mmu之后cpu访问到的都是虚拟地址,当cpu访问一个虚拟地址的时候需要通过mmu将虚拟地址转化为物理地址。进程分配了一段VMA之后,并无对应的page(没有分配物理地址),直到程序访问这段VMA之后,产生了缺页异常,由内核为其分配物理页面并建立起各级页表。
也就是说是通过虚拟地址根据页表找到物理内存,通过正向映射,我们可以将虚拟地址空间中的虚拟页面映射到对应的物理页面中。那么反向映射相反,其定义如下:
在已知物理页面(page frame)的情况下,找到映射该物理页面的虚拟地址。
反向映射机制用于快速定位那些引用了某个物理页面的所有页表项,对于linux操作系统为物理页面建立了链表,用于指向引用该物理页面的所有页表项,其大致原理如下:

2. 反向映射的需求
实际上,反向映射的主要应用场景就是内存回收和页面迁移,当页面启动回收机制之后,如果回收的页面时位于内核中的各种cache中,例如slab分配器,那么这些页面起始是可以直接回收,没有相关的页表操作。如果回收的时用户空间的page frame,那么回收之前内核需要进行反向映射。它究竟是为了解决什么样的问题而产生的呢?
-
一个物理页面被多个进程的VMA所映射,系统过程中发生了内存不足,需要回收一些页面,正好发现这个页面是符合我们回收利用的,我们能够直接把这个页面还给伙伴系统吗?
答案肯定是不能的,因为这个页面被多个进程所共享,我们必须做的事情就是断开这个页面的所有映射关系,这也就是反向映射必须要做到事情
-
一些情况,我们需要将一个页面迁移到另外一个页面,我们该如何做呢?是直接迁移就可以了吗?
对于这个问题,此时可能有一些进程已经映射到这个即将要迁移的页面,那么这个时候,同样需要我们知道这个页面被哪些VMA所映射,这页时反向映射必须要做的事情
当系统发生内存回收和页面迁移的时候,对于每一个候选页Linux内核都会判断是否为映射页,如果是,就会调用try_to_unmap来解除页表映射关系。其他的内核子系统会发现,在内存回收,内存碎片整理,CMA, 巨型页,页迁移等各个场景中都能发现反向映射所做的关键性的工作,所有理解反向映射机制在Linux内核中的实现是理解掌握这些子系统的基础和关键性所在,否则你即将不能理解这些技术背后的脊髓所在,所以说理解反向映射这种机制对于理解Linux内核内存管理是至关重要的!!!
3. 反向映射的发展过程
在早期的Linux内核版本中,是没有反向映射的,那个时候为了找到一个物理页面对应的页表项就需要遍历系统中所有mm组成的链表,然后对每一个mm再遍历每一个VMA,然后查找这个VMA是否映射了这个页面,这个过程极其漫长且低效,有时候不得不遍历完所有的mm才能找到映射到这个页面的所有PTE。

系统中的所有进程地址空间被串联成一个链表,链表头是init_mm,系统中所有的进程地址空间都挂在这个链表中。
- 首先沿着init_mm,对每一个进程地址空间进行扫面
- 在扫面一个进程地址空间的时候,对属于该进程地址空间中的每一个VMA进行扫面,如果命中了进程1的PTE,由于该page知识被进程1使用,那么可以直接unmap并回收该page
- 对于共享页面,就不能进行这么简单处理了,当扫面到进程1的时候,如果符合条件,那么我们就会unmap该page,解除它和进程A的关系。当然,这个时候不能回收该pgae,因为进程X还在使用该page,直到扫面到进程x,并完成unmap操作,该物理页面才能真正的回收
对于这种方式,存在很多问题,例如到底要扫面多少进程才能停止呢?对效率和性能都会是一个很大的影响。后来发现这个问题,只需要在物理页面的Page结构体重增加一个指针的方式解决,通过这个指针来找到一个描述映射这个页的所有PTE结构,这对于反向映射查找所有的PTE易如反掌,但是却带来了内存浪费问题。
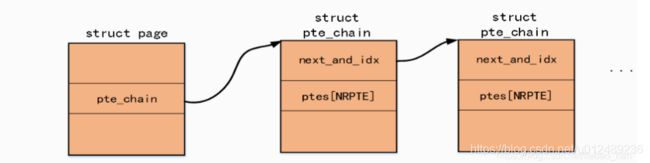
接着在2.6的内核中,内核的大神们想到服用page结构体中的mapping字段,然后通过红黑树的方式来组织所有映射这个页的VMA,形成匿名页和文件页的反向映射。
匿名页面反向映射图解

文件页反向映射图解

但是后来匿名页的反向映射遇到了效率和锁竞争激烈问题,就促使了目前使用的通过avc的方式联系各层级反向映射结构然后将锁的粒度降低的这种方式。可以看到反向映射的发展是伴随着Linux内核的发展而发展,是一个不断进行优化演进的过程。
4. 主要的数据结构
反向映射的目的是从屋里页面的page数据结构中找到有哪些映射的用户PTE,这样页面回收模块就可以很快速和高效地把这个物理页面映射的所有用户PTE都解除并回收这个页面。
page 结构中与基于对象的反向映射相关的关键字段有两个:_mapcount 和 mapping。
struct page {
atomic_t _mapcount;
union {
……
struct {
……
struct address_space *mapping;
};
……
};
- 字段 _mapcount 表明共享该物理页面的页表项的数目。该计数器可用于快速检查该页面除所有者之外有多少个使用者在使用,初始值是 -1,每增加一个使用者,该计数器加 1。
- 字段 mapping 用于区分匿名页面和基于文件映射的页面,如果该字段的最低位被置位了,那么该字段包含的是指向 anon_vma 结构(用于匿名页面)的指针;否则,该字段包含指向 address_space 结构的指针(用于基于文件映射的页面)
为了达到这个目的,内核在页面创建需要建立反向映射的钩子,即建立相关的数据结构。有两个重要的数据结构
- anon_vma,简称AV
- anon_vma_chain,简称AVC
4.1 anon_vma数据结构
anon_vma数据结构主要是用于连接物理页面的page数据结构和VMA的vm_are_struct数据结构,VMA的数据结构中有指向anon_vma数据结构
struct vm_area_struct {
...
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
...
}
由上图中可以得知,page数据结构中的mapping成员指向匿名页面的anon_vma数据结构,anon_vma其数据结构定义如下:
struct anon_vma {
struct anon_vma *root; /* Root of this anon_vma tree */
struct rw_semaphore rwsem; /* W: modification, R: walking the list */
atomic_t refcount;
unsigned degree;
struct anon_vma *parent; /* Parent of this anon_vma */
struct rb_root rb_root; /* Interval tree of private "related" vmas */
}
| 成员 | 类型 | 描述 |
|---|---|---|
| root | struct anon_vma * | 指向anon_vma数据结构中的根节点 |
| rwsem | struct rw_semaphore | 保护anon_vma数据结构中链表的读写信号量 |
| refcount | atomic_t | 引用计数 |
| degree | unsigned | 无 |
| parent | struct anon_vma * | 指向父aon_vma数据结构 |
| rb_root | struct rb_root | 红黑树根节点,anon_vma内部有一颗红黑树 |
4.2 anon_vma_chain数据结构
anon_vma_chain数据结构起枢纽作用,比如连接父子进程间struct anon_vma数据结构,其数据结构如下所示
struct anon_vma_chain {
struct vm_area_struct *vma;
struct anon_vma *anon_vma;
struct list_head same_vma; /* locked by mmap_sem & page_table_lock */
struct rb_node rb; /* locked by anon_vma->rwsem */
unsigned long rb_subtree_last;
#ifdef CONFIG_DEBUG_VM_RB
unsigned long cached_vma_start, cached_vma_last;
#endif
};
| 成员 | 类型 | 描述 |
|---|---|---|
| vma | struct vm_area_struct * | 指向VMA,可以指向父进程的VMA,也可以指向子进程的VMA |
| anon_vma | struct anon_vma * | 指向anon_vma数据结构,可以指向父进程或者子进程的 |
| same_vma | struct list_head | 链表节点,通常把anon_vma_chain添加到vma->anon_vma_chain链表中 |
| rb_node | struct rb_node | 红黑树节点,通常把anon_vma_chain添加到anon_vma->rb_root的红黑树 |
三个重要的数据结构之间的组合如下
- anon_vma_chain链接了anon_vma和vma
- vma则会有指针指向自己的anon_vma
5. 建立反向映射
在创建反向映射的时,分为两种页:匿名页和基于文件映射的页,
5.1 匿名页反向映射
父进程为自己的进程空间VMA分配物理页面的时,会产生匿名页面。例如,缺页中断处理中do_anonymous_page会产生匿名页面,下面以do_anonymous_page为例
static int do_anonymous_page(struct fault_env *fe)
{
struct vm_area_struct *vma = fe->vma;
if (unlikely(anon_vma_prepare(vma)))
goto oom;
...
page_add_new_anon_rmap(page, vma, fe->address, false);
...
}
产生匿名页面的时候,调用RMAP系统的两个接口来完成初始化工作
- anon_vma_prepare
- page_add_new_anon_rmap
对于anon_vma_prepare函数,主要是以下工作
- 通过anon_vma_chain_alloc(GFP_KERNEL)分配了一个struct anon_vma_chain *avc数据结构
- 通过find_mergeable_anon_vma函数检查是否可以和前后vma合并,如果相邻的VMA无法复用,就调用anon_vma_alloc重新分配一个anon_vma数据结构,并对收据结构进行必要的初始化
- 将vma->anon_vma指向刚才分配的anon_vma,anon_vma_chain_link函数会把刚才分配的anon_vma_chain的vma指向该进程的vma,将anon_vma指向刚才分配的anon_vma,并将添加到anon_vma_chain的链表中,另外把avc也添加到anon_vma->rb_root红黑树中。
而page_add_new_anon_rmap的实现工作如下:
void page_add_new_anon_rmap(struct page *page,
struct vm_area_struct *vma, unsigned long address, bool compound)
{
int nr = compound ? hpage_nr_pages(page) : 1;
VM_BUG_ON_VMA(address < vma->vm_start || address >= vma->vm_end, vma);
__SetPageSwapBacked(page);
if (compound) {
VM_BUG_ON_PAGE(!PageTransHuge(page), page);
/* increment count (starts at -1) */
atomic_set(compound_mapcount_ptr(page), 0);
__inc_node_page_state(page, NR_ANON_THPS);
} else {
/* Anon THP always mapped first with PMD */
VM_BUG_ON_PAGE(PageTransCompound(page), page);
/* increment count (starts at -1) */
atomic_set(&page->_mapcount, 0);
}
__mod_node_page_state(page_pgdat(page), NR_ANON_MAPPED, nr);
__page_set_anon_rmap(page, vma, address, 1);
}
- __SetPageSwapBacked设置page的标志位,表示这个页面可以交换到磁盘
- 设置_map_count和通过__mod_node_page_state增加匿名页面计数,匿名页面的类型为NR_ANON_MAPPED
- __page_set_anon_rmap设置这个页面为匿名映射
tatic void __page_set_anon_rmap(struct page *page,
struct vm_area_struct *vma, unsigned long address, int exclusive)
{
struct anon_vma *anon_vma = vma->anon_vma;
BUG_ON(!anon_vma);
if (PageAnon(page))
return;
/*
* If the page isn't exclusively mapped into this vma,
* we must use the _oldest_ possible anon_vma for the
* page mapping!
*/
if (!exclusive)
anon_vma = anon_vma->root;
anon_vma = (void *) anon_vma + PAGE_MAPPING_ANON;
page->mapping = (struct address_space *) anon_vma;
page->index = linear_page_index(vma, address);
}
- 首先判断该页面释放为匿名页面,mapping成员的低2位用于判断是否指向匿名映射或KSM页面的地址空间,如果mapping成员的第0位不为0,那么mapping成员执行匿名页面的地址空间数据结构
- 然后将anon_vma指针的值加上PAGE_MAPPING_ANON赋值给page->mapping
5.2. 文件页反向映射
此类型的页相对来说比较简单,是通过page_add_file_rmap来完成
void page_add_file_rmap(struct page *page, bool compound)
{
int i, nr = 1;
VM_BUG_ON_PAGE(compound && !PageTransHuge(page), page);
lock_page_memcg(page);
if (compound && PageTransHuge(page)) {
for (i = 0, nr = 0; i < HPAGE_PMD_NR; i++) {
if (atomic_inc_and_test(&page[i]._mapcount))
nr++;
}
if (!atomic_inc_and_test(compound_mapcount_ptr(page)))
goto out;
VM_BUG_ON_PAGE(!PageSwapBacked(page), page);
__inc_node_page_state(page, NR_SHMEM_PMDMAPPED);
} else {
if (PageTransCompound(page) && page_mapping(page)) {
VM_WARN_ON_ONCE(!PageLocked(page));
SetPageDoubleMap(compound_head(page));
if (PageMlocked(page))
clear_page_mlock(compound_head(page));
}
if (!atomic_inc_and_test(&page->_mapcount))
goto out;
}
__mod_node_page_state(page_pgdat(page), NR_FILE_MAPPED, nr);
mem_cgroup_update_page_stat(page, MEM_CGROUP_STAT_FILE_MAPPED, nr);
out:
unlock_page_memcg(page);
}
基本上,所需要的只是对_mapcount变量加1(原子操作)并更新各个内存域的统计量。
6. 使用反向映射
内核中通过struct page找到所有映射到这个页面的VMA典型场景有
- **页面回收:**kswapd内核线程回收页面需要断开所有映射了该匿名页面的用户PTE页表项
- **页面迁移:**页面迁移时,需要断开所有映射到匿名页面的用户PTE页表项
try_to_unmap()是反向映射的核心函数,内核中其他模块会调用此函数来断开一个页面的所有映射
int try_to_unmap(struct page *page, enum ttu_flags flags)
{
int ret;
struct rmap_private rp = {
.flags = flags,
.lazyfreed = 0,
};
struct rmap_walk_control rwc = {
.rmap_one = try_to_unmap_one,
.arg = &rp,
.done = page_mapcount_is_zero,
.anon_lock = page_lock_anon_vma_read,
};
/*
* During exec, a temporary VMA is setup and later moved.
* The VMA is moved under the anon_vma lock but not the
* page tables leading to a race where migration cannot
* find the migration ptes. Rather than increasing the
* locking requirements of exec(), migration skips
* temporary VMAs until after exec() completes.
*/
if ((flags & TTU_MIGRATION) && !PageKsm(page) && PageAnon(page))
rwc.invalid_vma = invalid_migration_vma;
if (flags & TTU_RMAP_LOCKED)
ret = rmap_walk_locked(page, &rwc);
else
ret = rmap_walk(page, &rwc);
if (ret != SWAP_MLOCK && !page_mapcount(page)) {
ret = SWAP_SUCCESS;
if (rp.lazyfreed && !PageDirty(page))
ret = SWAP_LZFREE;
}
return ret;
}
try_to_unmap函数内部主要调用rmap_walk函数,它返回时判断page的_mapcount,如果_mapcount为-1,说明所有的映射到这个物理页面的用户PTE都已经解除完毕了,因此它返回true;反之,则返回false。
int rmap_walk(struct page *page, struct rmap_walk_control *rwc)
{
if (unlikely(PageKsm(page)))
return rmap_walk_ksm(page, rwc);
else if (PageAnon(page))
return rmap_walk_anon(page, rwc, false);
else
return rmap_walk_file(page, rwc, false);
}
内核中有3中页面需要做unmap操作,他们分别是KSM页面,匿名页面和文件映射页面,因此它定义了一个struct rmap_walk_control来统一管理umap操作。
struct rmap_walk_control {
void *arg;
int (*rmap_one)(struct page *page, struct vm_area_struct *vma,
unsigned long addr, void *arg);
int (*done)(struct page *page);
struct anon_vma *(*anon_lock)(struct page *page);
bool (*invalid_vma)(struct vm_area_struct *vma, void *arg);
};
rmap_walk_control数据结构定义了如下函数指针
- rmap_one表示具体断开某个VMA上映射的PTE
- done表示判断一个页面是否断开成功
- anon_lock实现一个锁机制
- invalid_vma表示跳过无效的VMA
对于匿名页面的反向映射,会调用rmap_walk_anon进行,其代码为:
static int rmap_walk_anon(struct page *page, struct rmap_walk_control *rwc,
bool locked)
{
struct anon_vma *anon_vma;
pgoff_t pgoff;
struct anon_vma_chain *avc;
int ret = SWAP_AGAIN;
if (locked) {
anon_vma = page_anon_vma(page);
/* anon_vma disappear under us? */
VM_BUG_ON_PAGE(!anon_vma, page);
} else {
anon_vma = rmap_walk_anon_lock(page, rwc);
}
if (!anon_vma)
return ret;
pgoff = page_to_pgoff(page);
anon_vma_interval_tree_foreach(avc, &anon_vma->rb_root, pgoff, pgoff) {
struct vm_area_struct *vma = avc->vma;
unsigned long address = vma_address(page, vma);
cond_resched();
if (rwc->invalid_vma && rwc->invalid_vma(vma, rwc->arg))
continue;
ret = rwc->rmap_one(page, vma, address, rwc->arg);
if (ret != SWAP_AGAIN)
break;
if (rwc->done && rwc->done(page))
break;
}
if (!locked)
anon_vma_unlock_read(anon_vma);
return ret;
}
rmap_walk_anon函数一共有3个参数,如下所示
- page:表示需要解除映射的物理页面的page数据结构
- rwc:表示rmap_walk_control数据结构
- locked:表示是否已经加锁
其代码流程下图所示

最终会调用到try_to_unmap_one() 函数中,更新引用特定物理页面的所有页表项的操作都是在这个函数中实现的。该函数实现的关键功能如下图所示:

对于给定的物理页面来说,会首先计算出线性地址,并找到对应的页表项地址,更新新页表项。对于匿名页面来说,换出的位置必须保持,以便于该页面下次被访问的时候被换进去。
同时并非所有的页面都是可以被回收的,比如被mlock() 函数设置过的内存页,或者最近刚被访问过的页面,等等,都是不可以被回收的。一旦遇上这样的页面,该函数会直接跳出执行并返回错误代码。如果涉及到页缓存中的数据,需要设置页缓存中的数据无效,必要的时候还要置位页面标识符以进行数据回写。该函数还会更新相应的一些页面使用计数器,比如前边提到的 _mapcount 字段,还会相应地更新进程拥有的物理页面数目等。
其上面的整个流程也符合之前的反向映射的框图

7 总结

对于反向映射,分别通过page所对应的的vma, address_space, stable_node结构来查找vma,地址空间VMA可以通过页表完成虚拟地址到物理地址的映射;页框与page结构对应,page结构中的mapping字段指向anon_vma,从而可以通过RMAP机制去找到与之关联的VMA。对于反向映射各个数据结构建立的过程错综复杂,各个知识点散落在内存管理的各个环节中,还有很多问题也一时无法弄明白,期待后续。
8 参考文档
深入剖析Linux内核反向映射机制