学习日记(三)
目录
PyTorch学习
Sklearn学习
前沿
如何从GitHub下载csv文件
PyTorch学习
《PyTorch深度学习实践》完结合集-刘二大人https://blog.csdn.net/weixin_44410569/article/details/119895038到https://www.bilibili.com/video/BV1Y7411d7Ys?p=7到https://blog.csdn.net/bit452/category_10569531.html
Sklearn学习
到Python 3 天快速入门机器学习项目 - 知乎 (zhihu.com)

数据集网站:
http://archive.ics.uci.edu/ml/index.php
前沿
https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9643008698275409467%22%7D&n_type=1&p_from=4
Hinton最新研究:神经网络的未来是前向-前向算法
https://blog.csdn.net/chunchenbeile/article/details/124540906得代码
https://github.com/echowei/DeepTraffic/tree/master/1.malware_traffic_classification/2.PreprocessedTools(USTC-TK2016)
https://www.doc88.com/p-7048435731957.html原文
论文翻译
《Malware Traffic Classification Using Convolutional Neural Network for Representation Learning》,ICOIN 2017
表征学习?
没有从流量中提取特征,而是将原始的流量数据作为图像,然后使用CNN进行图像分类,这是CNN最常见的任务[7],最终实现了恶意软件流量分类的目标。
dataframe按条件筛选
dataframe 按条件筛选行_data-life的博客-CSDN博客_dataframe筛选满足条件的行
https://blog.csdn.net/sunny_xsc1994/article/details/82969867
有一张图片来源
https://zhuanlan.zhihu.com/p/29201491
深度学习文本分类模型TextCNN--->你可以在github上找到各种不同深度学习框架对于这个模型的实现--->去找
https://github.com/davidsbatista/ConvNets-for-Sentence-Classification/blob/master/Convolutional-Neural-Networks-for-Sentence-Classification.ipynb
https://www.cnblogs.com/zywnnblog/p/15758804.html
Python sklearn 实现过采样和欠采样 - 常给自己加个油 - 博客园 (cnblogs.com)
https://baijiahao.baidu.com/s?id=1717923123351711758
一文读懂Python标准库中argparser模块,详解命令行参数和解析器
我们知道,在windows、linux、macos这样一些操作系统中,除了提供一些傻瓜式的用户界面方便用户操作外,这些系统很大程度上都留给一些系统爱好者(或深度学习的用户)一些命令行接口。

cmd和shell
通过一些简单的系统命令,实现同界面一样的操作效果,甚至可以实现一些用户界面无法实现的功能。
01不同系统的命令行工具
不同系统命令行调用方式存在差异。
【Windows系统】
windows系统
对于windows用户,按下“win” + ‘r’键,在弹出对话框中输入cmd,可以进入这样的交互界面。比如,你想要查看当前windows系统中所有端口占用情况,可以使用下面的命令:
netstat -ano

命令行演示
如果使用图形界面,可能获取到的信息就没这么详细了!
windows中,如果你想要更加高级的界面,在某个文件夹界面中按下“shift”,同时单击鼠标右键,同时按下“s”键(或者点击“在PowerShell中打开”这个选项),即可打开PowerShell窗口,这是一个更加高级的命令行窗口,说它高级,是因为它是一个面向对象的命令行接口。
PowerShell窗口
【linux系统】

linux系统
这里的linux系统指的是大部分linux系统:
Ctrl + Alt + t:打开一个新的终端
Shift +Ctrl + t:在已有终端上打开一个新的tab
Shift +Ctrl + n:在已有终端上打开另一个新的终端(不是tab)
这里就不再截图了,感兴趣的小伙伴自己实验下!
【其它系统】

其他os
此处略去,详情参见系统手册^-^
对于这些命令行工具,本质上来讲,就是调用系统中存在的一些应用程序,将程序运行结果在终端显示出来。而程序运行需要的一些参数,通过命令行的一定格式,传递给命令来执行。
命令行解析
比如,上面的“netstat -ano”这个命令。其中,a、n、o就是netstat运行时需要用户提供的参数,这里也可以分开来写,比如:netstat -a -n -o。当用户将这个命令提交给shell、cmd等终端工具时,shell、cmd就将命令发送给系统底层(可能这里还不是系统底层,暂且这样理解即可)执行,执行后系统将结果会送给shell、cmd等,shell、cmd通过其展示机制,将运行结果展示给用户。

本质来讲是个接口
Python作为一门强大的编程语言,实现这种命令行接口可以说是轻而易举。我们来看下面的内容:
02argparse模块介绍
Python实现类似上面这种命令行接口,有一个简单易用的标准库,不用导入任何第三方库即可轻松实现,这里需要用到argparse模块,它可以让人轻松编写用户友好的命令行接口。
我们先来看一个官网的例子:
import argparse
parser = argparse.ArgumentParser(description='处理一些整数')
parser.add_argument('integers', metavar='N', type=int, nargs='+', help='累加器的整数')
parser.add_argument('-sum',dest='accumulate',action='store_const',const=sum,default=max,help='对整数求和(默认值:查找最大值)')
args = parser.parse_args()
print(args.accumulate(args.integers))
为了便于理解,我们对相关参数说明进行了翻译。
我们将上述代码保存为“test.py”文件,在PyCharm中测试运行,看下结果
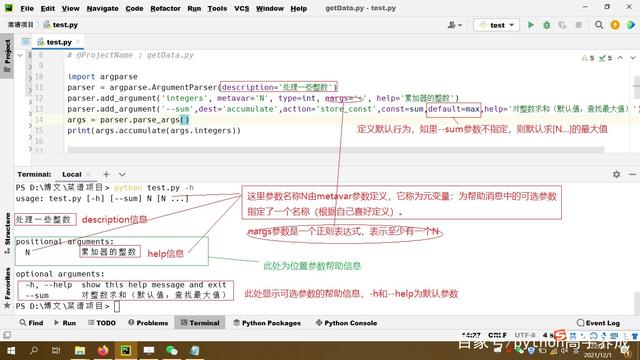
使用默认-h或--help测试结果
然后我们传入参数看下运行结果。
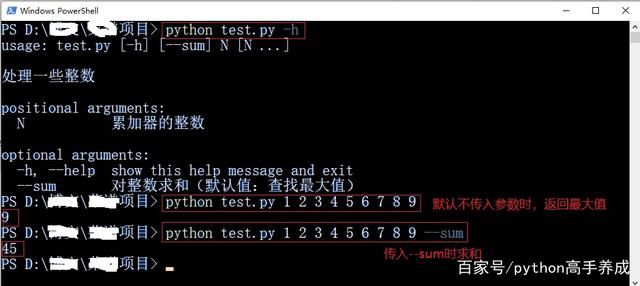
powershell中测试结果
从上面看,类似的程序设计步骤应该是这样的
第一步:导入模块后,定义一个ArgumentParser对象实例
第二步:使用add_argument(*args, **kwargs)方法,向该对象实例中添加参数
第三步:使用parse_args()方法解析该实例对象中的参数。
03分步骤实现命令行接口
上面梳理了一般命令行接口程序的设计步骤,程序首先创建类的实例,然后定义它需要的参数,后argparse将弄清如何从 sys.argv 解析出哪些参数。此外,argparse模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
功能
下面,我们逐个攻破上面涉及到的类的实例和相关方法(下文只是针对步骤对类及方法的参数进行了简要说明,)
【创建解析器对象ArgumentParser】
class argparse.ArgumentParser(prog=None, usage=None, description=None, epilog=None, parents=[], formatter_class=argparse.HelpFormatter, prefix_chars='-', fromfile_prefix_chars=None, argument_default=None, conflict_handler='error', add_help=True, allow_abbrev=True, exit_on_error=True)
创建一个新的 ArgumentParser 对象。所有的参数都应当作为关键字参数传入。每个参数在下面都有它更详细的描述,
【prog】 - 程序的名称(默认值:sys.argv[0])
【usage】 - 描述程序用途的字符串(默认值:从添加到解析器的参数生成)
【description】 - 在参数帮助文档之前显示的文本(默认值:无)
【epilog】 - 在参数帮助文档之后显示的文本(默认值:无)
【parents】 - 一个 ArgumentParser 对象的列表,它们的参数也应包含在内
【formatter_class】 - 用于自定义帮助文档输出格式的类
【prefix_chars】 - 可选参数的前缀字符集合(默认值: '-')
【fromfile_prefix_chars】 - 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合(默认值: None)
【argument_default】 - 参数的全局默认值(默认值: None)
【conflict_handler】 - 解决冲突选项的策略(通常是不必要的)
【add_help】 - 为解析器添加一个 -h/--help 选项(默认值: True)
【allow_abbrev】 - 如果缩写是无歧义的,则允许缩写长选项 (默认值:True),该参数从Python3.5开始才有。在Python3.8之前的版本中,该参数还会禁用短旗标分组,例如 -vv 表示为 -v-v。
【exit_on_error】 - 决定当错误发生时是否让 ArgumentParser 附带错误信息退出。该参数在Python3.9版本中才有 (默认值: True)对于一般需求的应用程序,直接定义描述信息即可。但是,当我们需要自定义一些个性化的功能时,这些参数往往就显得很重要了。如何对这些参数进行个性化定制,每一个参数的含义如何?我们后续专题讲解,这里不再赘述。
类的实例定义好了,如何往实例里面添加参数信息?我们接着往下看!
【使用add_argument添加参数】
import argparse
parser = argparse.ArgumentParser(description="XXXXXXX")
parser.add_argument(**kwargs)
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
定义单个的命令行参数应当如何解析。每个形参都在下面有它自己更多的描述,长话短说有:
【name or flags】 - 一个命名或者一个选项字符串的列表,例如 foo 或 -f, --foo。【action】 - 当参数在命令行中出现时使用的动作基本类型。【nargs】 - 命令行参数应当消耗的数目。【const】 - 被一些 action 和 nargs 选择所需求的常数。【default】 - 当参数未在命令行中出现并且也不存在于命名空间对象时所产生的值。【type】 - 命令行参数应当被转换成的类型。【choices】 - 可用的参数的容器。【required】 - 此命令行选项是否可省略 (仅选项可用)。【help】 - 一个此选项作用的简单描述。【metavar】 - 在使用方法消息中使用的参数值示例。【dest】 - 被添加到 parse_args() 所返回对象上的属性名。对于add_argument方法,我们下文专题介绍,这里不再赘述了。参数添加后,我们需要完成参数的解析,这里我们要用到parse_args方法!【使用parse_args解析参数】
ArgumentParser 通过 parse_args() 方法解析参数。它将检查命令行,把每个参数转换为适当的类型然后调用相应的操作。在大多数情况下,这意味着一个简单的 Namespace 对象将从命令行参数中解析出的属性构建:
【args】 - 要解析的字符串列表。 默认值是从 sys.argv 获取。【namespace】 - 用于获取属性的对象。 默认值是一个新的空 Namespace 对象。上面的例子中,当我们打印解析出来的args参数时,输出是这样的:
Namespace(accumulate=
# 其中,integers列表是我们传递的参数值。一般情况下,程序会自动从sys.argv中解析出参数,该方法不需要传递参数,是不是很方便?
对于parse_args方法,它其实提供了很多容错机制,当用户输入内容不合法时,进行相应的处理。我们下文也会专题进行研究。这里不再赘述。
本文,我们只了解下ArgumentParser对象实例的创建、参数添加、参数解析的步骤,对于这里很重要的几个类和方法,我们下文逐个进行讲解。
下面,针对本文内容,我们利用一个实例加深下印象!
04举个例子
我们知道,默认情况下,如果我们对帮助信息不做任何格式限定,它应该是这样的(以前面官网例子为例):

默认帮助信息格式
如果我们需要自己定制一个帮助信息文本,只需要在创建类的实例时,对prog、usage、description、epilog等这样一些参数进行定制即可。
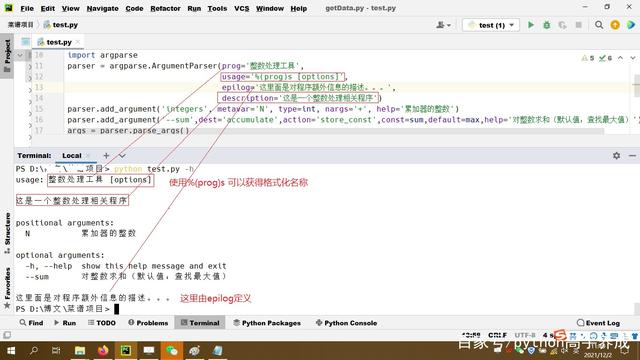
参数定制
我们看到,这里使用参数对帮助信息进行了一些个性化调整。但是,上面内容空行太多,该如何设置去除空行呢?对这个问题,我们下次讨论创建ArgumentParser对象实例时再做介绍。
Python标准库之argparse,详解如何创建一个ArgumentParser对象 (baidu.com)
http://wjhsh.net/liuys635-p-12304118.html
如何从GitHub下载csv文件
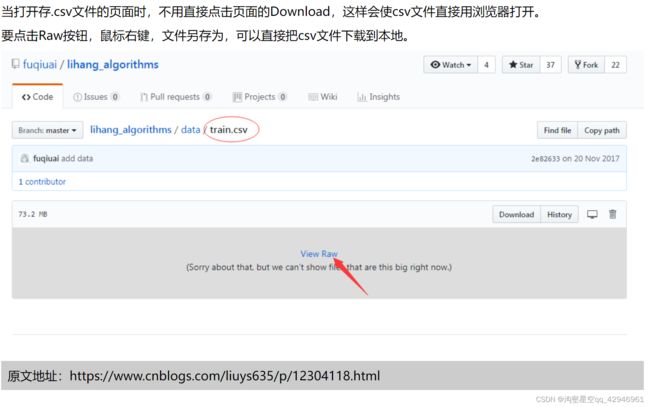
https://blog.csdn.net/weixin_39781209/article/details/110984341
参考https://blog.csdn.net/weixin_39916966/article/details/88049179
在Keras中有两种深度学习的模型:序列模型(Sequential)和通用模型(Model)。差异在于不同的拓扑结构。
序列模型 Sequential
序列模型各层之间是依次顺序的线性关系,模型结构通过一个列表来制定。
或者逐层添加网络结构
通用模型Model
通用模型可以设计非常复杂、任意拓扑结构的神经网络,例如有向无环网络、共享层网络等。相比于序列模型只能依次线性逐层添加,通用模型能够比较灵活地构造网络结构,设定各层级的关系。
from keras.layers import Input, Dense
from keras.models import Model
# 定义输入层,确定输入维度
input = input(shape = (784, ))
# 2个隐含层,每个都有64个神经元,使用relu激活函数,且由上一层作为参数
x = Dense(64, activation='relu')(input)
x = Dense(64, activation='relu')(x)
# 输出层
y = Dense(10, activation='softmax')(x)
# 定义模型,指定输入输出
model = Model(input=input, output=y)
# 编译模型,指定优化器,损失函数,度量
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型拟合,即训练
model.fit(data, labels)
https://www.cnblogs.com/demo-deng/p/10130490.html
word2vec
https://www.iotword.com/4616.html
将npy转化为csv
https://blog.csdn.net/lrt366/article/details/88719207
https://www.jianshu.com/p/a3f3033a7379/
embedding keras