【分类器 Softmax-Classifier softmax数学原理与源码详解 深度学习 Pytorch笔记 B站刘二大人(8/10)】
分类器 Softmax-Classifier softmax数学原理与源码详解 深度学习 Pytorch笔记 B站刘二大人 (8/10)
在进行本章的数学推导前,有必要先粗浅的介绍一下,笔者在广泛查找后发现当前并没有官方定义什么是softmax分类器:
softmax分类器在本质上也是激活函数的一种,可以看作激活函数sigmoid的拓展版,目标是将输出的多个数值转换为多个分类结果的概率。
数学推导
首先回归上一期的多输入模型,通过多个线性层之间的非线性连接,成功完成了通过8个维度的评价数据对样本是否为糖尿病患者进行了01判断:

多输入单输出问题虽然比单输入单输出问题更为普遍,但是现实中最多的是多输入多输出问题。

如果按照多输入单输出模型的思路对数据进行训练,也能得到相关的预测概率,但是会遇到一个非常明显的问题,就是输出的数据将是各个类别的相似概率总和不为1,而每一个概率都在(0,1)之间,显然这与平常的认知是有冲突,我们更希望输出的分类概率总和为1,从而确定最大可能的类别进行判断。
因此该结构理论上可行,但是存在问题,输出结果之间由于相互概率互斥,应该存在相互抑制。在构建中出现输出值为负值或者多个输出概率大于0.7的清楚,不满足分布: y>0 && Σy = 1,希望输出值是一个分布,讲结构进行改进:
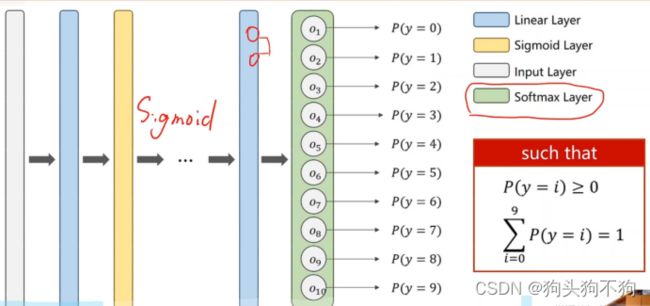
在此就引入Softmax处理层:

可以发现softmax运算的本质是将各个预测结果的单个可能性转换为整体预测中的概率,即输出的分类概率加和为1
在此使用NLLLoss损失函数,通过与独热向量结合得到损失值
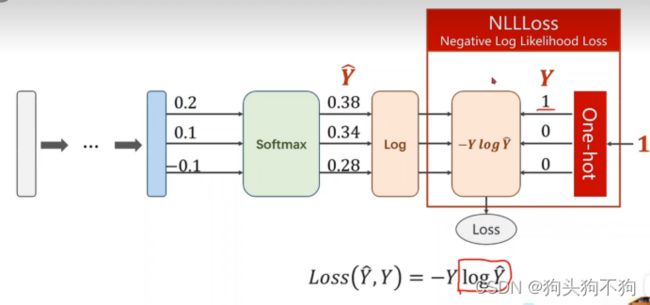
损失函数的代码实现环节:

按照数学原理编程实现softmax
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 07日
"""
import torch
import numpy as np
# 实现 softmax + log 输出 + one_hot向量计算loss=-Yln_Y_
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum() # 将输出值进行softmax处理,是的输出的预测值在0-1之间,输出的各个概率和为1
loss = (-y * np.log(y_pred).sum())
print("Loss1 = ", loss, "\n")
# 使用torch中的CrossEntropyLoss()
y = torch.LongTensor([0]) # longtensor 数据类型的
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss() # 交叉熵模块
loss = criterion(z, y)
print("loss2 = ", loss)
# 通过交叉熵模块进行对比,虽然得到相同的预测结果,但是由于输入的值不同导致损失有不同
criterion = torch.nn.CrossEntropyLoss()
Y = torch.LongTensor([2, 0, 1])
Y_pred1 = torch.Tensor([[0.1, 0.2, 0.9],
[1.1, 0.1, 0.2],
[0.2, 2.1, 0.3]])
Y_pred2 = torch.Tensor([[0.8, 0.2, 0.3],
[0.2, 0.3, 0.5],
[0.2, 0.2, 0.5]])
l1 = criterion(Y_pred1, Y)
l2 = criterion(Y_pred2, Y)
print("Batch Loss1 = ", l1.data, "\nBatch Loss2 = ", l2.data)
代码模块解读与实现
代码关键细节:
1.pytorch 在进行分类的过程中,softmax环节和多分类的loss求解,以及backward梯度解算过程都已经完成了相关封装工作,可以直接调用。
2.在定义y的数据类型时,由于y属于多标签输入,需要定义为LongTensor类型,因为需要通过独热向量进行比对并求取损失

对比交叉熵的预测运算结果,虽然最后的预测结果相同,但是获得的损失函数值有所不同

显然l1在线性层预测过程中结果更为贴近实际数据标签,因此损失值更小
作业1
课堂作业:阅读文档,解析交叉熵CrossEntropyLoss损失和NLL损失NLLLOSS的差别,了解在什么需求下使用对应的损失函数:
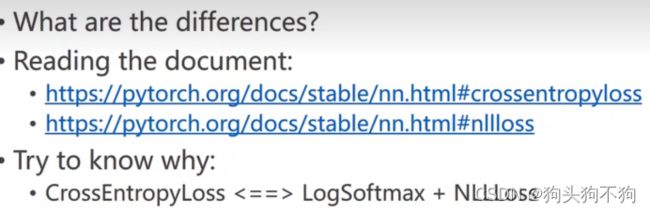
实例
Minist 数据集,预处理:用矩阵表示图像

步骤:1.准备数据2.设计模型计算输出y 3.设计损失和优化函数4.训练循环与测试

代码细节:读取图像,使用pillow进行读取,深度学习希望读取的图像的输入数值较小,在-1 - 1之间

Cv基础:单通道多通道图像相关知识,不再赘述。转换作用:将二维tensor转换为三维tensor,提供通道信息。同时Normalize进行标准化,将像素值转换为对应的零一分布
保证上一层的out与下一层的input数值相同,注意由于使用softmax函数,最后一层不使用激活函数


损失计算与优化器选择,由于模型较大,使用冲量优化momentum设置为0.5

定义训练实例:

整体代码
''' coding:utf-8 '''
"""
作者:shiyi
日期:年 09月 03日
softmax 分类器实现线性层的minist分类
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64 # 设置一次训练的数据集batch大小
# transform 将数据转化为tensor数据类型,并进行标准化处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.137, ), (0.3081, ))
])
# 构建训练集数据
train_dataset = datasets.MNIST(root='../dataset/minist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
# 构建测试集数据
test_dataset = datasets.MNIST(root='../dataset/minist',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(test_dataset,
shuffle=False,
batch_size=batch_size)
# 构建网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__() # 重写类
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不激活
model = Net() # 实例化
criterion = torch.nn.CrossEntropyLoss() # 交叉熵进行计算
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0 # 将之前计算累计loss清零
for batch_idx, data in enumerate(train_loader, 0): # enumerate返回枚举对象,将索引从0开始修改为索引从1开始
inputs, target = data
optimizer.zero_grad()
# forward
outputs = model(inputs)
loss = criterion(outputs, target)
# backward
loss.backward()
# updata
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, 5%d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images) # 输出为一个长度为10的列向量,其中的数值代表0-9识别的可能概率
# 由于输出的是一个列向量,因此通过max函数找到预测的标签,返回值1是最大值,并不需要直接_释放,predicted返回标签
_, predicted = torch.max(outputs.data, dim=1) # 其中dim=1表示对output进行列向量查找,.data运算防止生成计算图
total += labels.size(0) # 通过标签size计算测试集样本个数
correct += (predicted == labels).sum().item() # 计算预测准确的次数
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运算结果:
[9, 5300] loss: 0.039
[9, 5600] loss: 0.041
[9, 5900] loss: 0.046
Accuracy on test set: 97 %
[10, 5300] loss: 0.033
[10, 5600] loss: 0.035
[10, 5900] loss: 0.035
Accuracy on test set: 97 %
作业2
作业:
多分类进行训练
(挖坑+1。。。代填。。。。)