SQL Server2005杂谈(2):公用表表达式(CTE)的递归调用
上图显示了一个表中的数据,这个表有三个字段:id、node_name、parent_id。实际上,这个表中保存了一个树型结构,分三层:省、市、区。其中id表示当前省、市或区的id号、node_name表示名称、parent_id表示节点的父节点的id。
现在有一个需求,要查询出某个省下面的所有市和区(查询结果包含省)。如果只使用SQL语句来实现,需要使用到游标、临时表等技术。但在SQL Server2005中还可以使用CTE来实现。
从这个需求来看属于递归调用,也就是说先查出满足调价的省的记录,在本例子中的要查“辽宁省”的记录,如下:
id node_name parent_id
1 辽宁省 0
然后再查所有parent_id字段值为1的记录,如下:
id node_name parent_id
2 沈阳市 1
3 大连市 1
最后再查parent_id字段值为2或3的记录,如下:
id node_name parent_id
4 大东区 2
5 沈河区 2
6 铁西区 2
将上面三个结果集合并起来就是最终结果集。
上述的查询过程也可以按递归的过程进行理解,即先查指定的省的记录(辽宁省),得到这条记录后,就有了相应的id值,然后就进入了的递归过程,如下图所示。
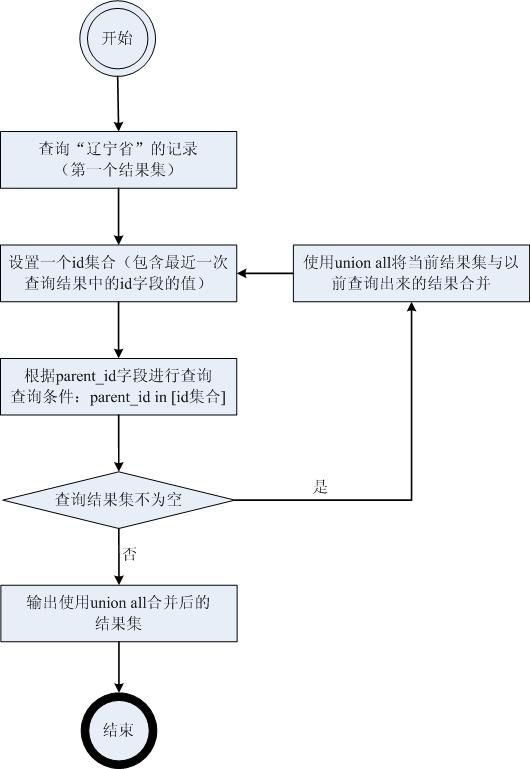
从上面可以看出,递归的过程就是使用union all合并查询结果集的过程,也就是相当于下面的递归公式:
resultset(n) = resultset(n-1) union all current_resultset
其中resultset(n)表示最终的结果集,resultset(n - 1)表示倒数第二个结果集,current_resultset表示当前查出来的结果集,而最开始查询出“辽宁省”的记录集相当于递归的初始条件。而递归的结束条件是current_resultset为空。下面是这个递归过程的伪代码:
{
if (resultset is null )
{
current_resultset = 第一个结果集(包含省的记录集)
将结果集的id保存在集合中
getResultSet(current_resultset)
}
current_resultset = 根据id集合中的id值查出当前结果集
if (current_result is null ) return resultset
将当前结果集的id保存在集合中
return getResultSet(resultset union all current_resultset)
}
// 获得最终结果集
resultset = getResultSet( null )
从上面的过程可以看出,这一递归过程实现起来比较复杂,然而CTE为我们提供了简单的语法来简化这一过程。
实现递归的CTE语法如下:
< common_table_expression > :: =
expression_name [ ( column_name [ ,n ] ) ]
AS (
CTE_query_definition1 -- 定位点成员(也就是初始值或第一个结果集)
union all
CTE_query_definition2 -- 递归成员
)
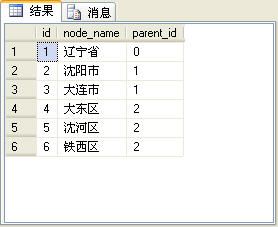
下面是使用递归CTE来获得“辽宁省”及下面所有市、区的信息的SQL语句:
district as
(
-- 获得第一个结果集,并更新最终结果集
select * from t_tree where node_name = N ' 辽宁省 '
union all
-- 下面的select语句首先会根据从上一个查询结果集中获得的id值来查询parent_id
-- 字段的值,然后district就会变当前的查询结果集,并继续执行下面的select 语句
-- 如果结果集不为null,则与最终的查询结果合并,同时用合并的结果更新最终的查
-- 询结果;否则停止执行。最后district的结果集就是最终结果集。
select a. * from t_tree a, district b
where a.parent_id = b.id
)
select * from district
查询后的结果如下图所示。
district as
(
select * from t_tree where node_name = N ' 辽宁省 '
union all
select a. * from t_tree a, district b
where a.parent_id = b.id
),
district1 as
(
select a. * from district a where a.id in ( select parent_id from district)
)
select * from district1
查询结果如下图所示。
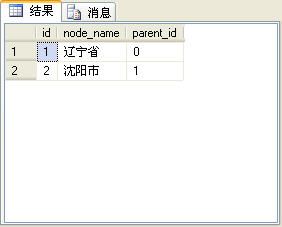
注:只有“辽宁省”和“沈阳市”有下子节点。
在定义和使用递归CTE时应注意如下几点:
1. 递归 CTE 定义至少必须包含两个 CTE 查询定义,一个定位点成员和一个递归成员。可以定义多个定位点成员和递归成员;但必须将所有定位点成员查询定义置于第一个递归成员定义之前。所有 CTE 查询定义都是定位点成员,但它们引用 CTE 本身时除外。
2. 定位点成员必须与以下集合运算符之一结合使用:UNION ALL、UNION、INTERSECT 或 EXCEPT。在最后一个定位点成员和第一个递归成员之间,以及组合多个递归成员时,只能使用 UNION ALL 集合运算符。
3. 定位点成员和递归成员中的列数必须一致。
4. 递归成员中列的数据类型必须与定位点成员中相应列的数据类型一致。
5. 递归成员的 FROM 子句只能引用一次 CTE expression_name。
6. 在递归成员的 CTE_query_definition 中不允许出现下列项:
(1)SELECT DISTINCT
(2)GROUP BY
(3)HAVING
(4)标量聚合
(5)TOP
(6)LEFT、RIGHT、OUTER JOIN(允许出现 INNER JOIN)
(7)子查询
(8)应用于对 CTE_query_definition 中的 CTE 的递归引用的提示。
7. 无论参与的 SELECT 语句返回的列的为空性如何,递归 CTE 返回的全部列都可以为空。
8. 如果递归 CTE 组合不正确,可能会导致无限循环。例如,如果递归成员查询定义对父列和子列返回相同的值,则会造成无限循环。可以使用 MAXRECURSION 提示以及在 INSERT、UPDATE、DELETE 或 SELECT 语句的 OPTION 子句中的一个 0 到 32,767 之间的值,来限制特定语句所允许的递归级数,以防止出现无限循环。这样就能够在解决产生循环的代码问题之前控制语句的执行。服务器范围内的默认值是 100。如果指定 0,则没有限制。每一个语句只能指定一个 MAXRECURSION 值。
9. 不能使用包含递归公用表表达式的视图来更新数据。
10. 可以使用 CTE 在查询上定义游标。递归 CTE 只允许使用快速只进游标和静态(快照)游标。如果在递归 CTE 中指定了其他游标类型,则该类型将转换为静态游标类型。
11. 可以在 CTE 中引用远程服务器中的表。如果在 CTE 的递归成员中引用了远程服务器,那么将为每个远程表创建一个假脱机,这样就可以在本地反复访问这些表。