FSL小样本学习few-shot learning知识点整理
FSL小样本学习Few-shot learning知识点整理
- 前言
- 小样本训练的一些特殊概念
-
- Zero-Shot One-Shot Few-Shot
- N-Way K-Shot 分类问题
- support sets支持集,query sets 查询集
- episodes
- 用一个例子来理解这些新概念
- Matching networks
- Prototype Networks
- Relation Networks
- Domain-adversarial prototypical network
- Meta learning- learning to learn
- Model-Agnostic Meta-Learning (MAML)
- 参考资料
前言
虽然deeplearning在语音视频和语言处理上有了革命性的进步,数据增强和正则化技术也是的小数据样本的过拟合问题得到了改善,但是距离大数据大模型的差距还是存在的。本文结合《Matching Networks for One Shot Learning》,《Domain-Adaptive Few-Shot Learning》和《Prototypical Networks for Few-shot Learning》,《Learning to Compare: Relation Network for Few-Shot Learning》等论文的内容,梳理一下few shot learning的一些知识点,试图探究一下提高小样本学习的方法。经典的方法可以用预训练模型,固定一定层数,refine一个新模型的方法,还有就是度量学习也能令小样本得到一个不错的高维空间聚类分布。但没有解决域漂移等经典顽疾。所以希望从这几篇论文和众多网文中寻找一些思路。
近年来FSL问题大都基于meta-learning的方法,第一类是基于基础训练+finetune的转移学习思路,这样可以快速的构建源类别和目标类别的桥梁;第二类是基于度量学习方法的演进,具体来说就是将NCA的方法迁移到Fsl问题上来,matching network为support set和query set建立了不同的编码器,prototype network实质上市学习了一个度量空间,这个空间里每个类别都有一个原型表达,通过计算新进类别和这些原型表达的距离实现分类的目标,Relation network通过计算query集合与few samples新类的关系评分,重构了进入类别的样例分布;还有一类是实现一个独特的优化算法代替经典的梯度算法,进而满足FSL的要求,Model-Agnostic Meta-Learning (MAML)就属于这一类。
小样本训练的一些特殊概念
Zero-Shot One-Shot Few-Shot
三个概念其实就是针对于目标集合数为0,1,大于1的场景,本篇的重点是大于1但也没大多少的情况。三类场景也都面临训练资料匮乏,无法利用大数据来驱动模型的问题,所以需要新的数学建模方法,来实现类似人类对于新鲜事物极快的学习接受能力。
N-Way K-Shot 分类问题
所谓N-Way K-Shot 分类问题 就是指用少量样本构建分类任务。主要应用于少样本学习(Few-Shot Learning)领域样本数据不足的情况,后来逐渐延伸到元学习(Meta-Learning)领域。每次在构建分类任务时,从数据集里抽取N-类的数据,每一类数据由K-个样本构成。这样就形成了一个小型分类任务的数据集,实际上就是原始数据集的一次采样。【3】
support sets支持集,query sets 查询集
few shot learning-FSL和元学习中都会用到这两个概念,我起初的理解是训练集(Training Set)对应支持集(Support Set)、测试集对应为查询集(Query Set)。但后来演练代码又觉得不对,因为每个集合里都要划分Support Set/Query Set组合,结合Prototype Networks和triplets的概念,倒是可以将support set理解成anchor(proxy anchor),而Query set是类别对应anchor的分类定标参考。不同的论文对于这两个集合构建的思路有些差异,但都是基于数据量有限的排列组合玩法来设计的。
episodes
在Matching networks论文中对训练周期的定义上提出了episodes的概念,为了区别大数据训练的epochs,在episodes周期里,都是为了服务于few-shot任务的子类别样本训练,这个子类别就是区别于epochs中全类别子样本训练,。很多meta-learning中的任务也喜欢用episodes这个词汇,而对应神经网络中的mini-batch是比较合适的。
用一个例子来理解这些新概念
我们一般习惯用已有的知识和概念去理解新的事物,那么对于一个已经熟悉了基本神经网络训练过程的人,如何去理解和认识上述几个新概念呢?还是拿个小栗子一目了然。
假设:20-way 5-shot问题:
- 每个episodes提取出来20个类别,而不是所有的类别(传统softmax分类训练要加载所有类别);
- 每个类别是有5个examples可供训练,因为训练中还要分support-sets+query-sets,5-shots场景至少需要5+1个样例,至少一个query example去何support-sets的样例做距离(分类)判断。
- 验证集和训练集的分类方法尽量保持一致。
- 测试集可以变换成5-way 1-shot等等方式来评估模型的泛化能力。
- 最后每个epoch还要设定由多少个episodes来组成,好像大家都喜欢用1000来作为典型值。
Matching networks
这是google的几位专家在Matching Networks for One Shot Learning提出来的概念,这是结合深度神经网络的度量学习方法和外部记忆增强型神经网络(augment neural networks with external memories)的特点,匹配网络试图消除对finetune方法的需求【7】。融入了attention机制的匹配网络,可以被理解成为嵌入空间的权重最邻近分类器。
Prototype Networks
通过训练集确定prototype,其实本质上就是模型利用训练集作为先验知识的过程。这个网络很像DML里的NCA,论文中也提到了这点。针对于小样本集合的识别,往往是利用预训练模型,转移学习小样本的特征,但这样会带来过拟合问题,联想到人类过目不忘的一些生理学特点,原型网络利将小样本集合的原型(特征平均值)来投射到多维空间,避免了个体样本带来的偏差。
本文有一个假设条件:一个分类器应该具有一个简单的归纳偏置(inductive bias),所以原型网络就是简单的将聚类点表达成了向量高维平均值(the mean of the support set)。不能免俗贴张原图:

注释里明确的说到了用softmax而不是距离来实现分类,但仔细想来对于fewshot来说,利用了目标类别的先验知识(support set)得到的空间,而zeroshot只能利用原有训练集的空间,与其他网络的情况没什么本质分别,暂时无法理解如何提升zero-shot能力一说。另外这种原型网络的距离选择,直观上也能理解欧式距离更好一些,如何获取cosine similarity的高维向量均值,还需要从长计议。假设N个标签的支持Support集和 S = { ( x 1 , y 1 ) , . . . , ( x N , y N ) } , x i ∈ R D , y ∈ { 1 , . . . , K } S=\{(x_1,y_1),...,(x_N,y_N)\}, x_i \in\Bbb R^D,y\in\{1,...,K\} S={(x1,y1),...,(xN,yN)},xi∈RD,y∈{1,...,K},那么 S k S_k Sk就是标签为 k k k的子集和样例。定义 f ϕ : R D → R M f_\phi :\Bbb R^D\to\Bbb R^M fϕ:RD→RM是具有可学习参数 ϕ \phi ϕ的嵌入函数,那么原型定义为:
c k = 1 ∣ S k ∣ ∑ ( x i , y i ) ∈ S k f ϕ ( X i ) c_k=\frac{1}{|S_k|}\sum_{(x_i,y_i)\in S_k}f_\phi (X_i) ck=∣Sk∣1(xi,yi)∈Sk∑fϕ(Xi)
查询集的向量来说,原型网络是利用softmax而不是用距离(loss)产生的空间分布,具体的对数似然函数概率公式为:
p ϕ ( y = k ∣ x ) = e − d ( f ϕ ( x ) , c k ) ∑ k ′ e − d ( f ϕ ( x ) , c k ′ ) p_\phi(y=k|x)=\frac{e^{-d(f_\phi(x),c_k)}}{\sum_{k'}e^{-d(f_\phi(x),c_{k'})}} pϕ(y=k∣x)=∑k′e−d(fϕ(x),ck′)e−d(fϕ(x),ck)
损失函数就是取似然函数的负数最小化来做梯度SGD。文中的定义如下:
J ( ϕ ) = − l o g p ϕ ( y = k ∣ x ) J(\phi)=-log\ {p_\phi (y=k|x)} J(ϕ)=−log pϕ(y=k∣x)
这里有一个概念叫做自信息self-information(也叫信息惊诧度), I ( m ) = l o g 1 p ( m ) = − l o g p ( m ) I(m)=log{\frac{1}{p(m)}}=-log\ {p (m)} I(m)=logp(m)1=−log p(m),简单的说就是如果老张家的孩子长得越来越像隔壁老王这样小概率的事情出现了,那么信息惊诧度(自信息)量越大;如果都按部就班的,谁家的孩子长得像谁,信息量的值就越小,所以自信息也可以作为一种loss函数来为SGD服务。
训练episodes通过随机采集训练集合的子类,提取子类中的每一类子集作为support set,剩余的子集作为query set,实现meta-learning的小样本学习,论文也给出了算法的具体伪码:

文中其他部分还讲了很多,但初次接触上面的已经交代很清楚了,剩下的就是找代码来分析了。
Relation Networks
这也是被介绍比较多的网络之一
Domain-adversarial prototypical network
《Domain-Adaptive Few-Shot Learning》这篇文章将Domain-shift和Few-shot两个比较难的话题合二为一,提出了DAPN网络,训练方法也是基于N-Way K-Shot设计的,网络结构是在ResNet特征提取之后引入了一个带有attention机制的自编码器作为对抗网络,采用 Prototype Networks的metric方法。文中用下图重点强调了什么是DA-FSL,进而阐述两个问题统一考虑的必要性。
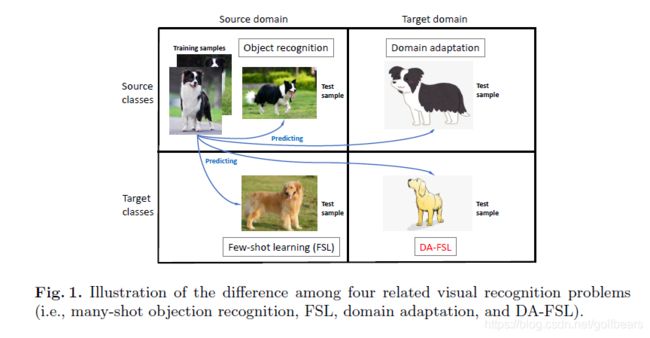
DA问题是zero shot领域的最头疼的事情,上图的标签看上去是一致的,只是域从照片变成了卡通图片(域漂移),而下面阿黄(不懂这狗的品种)训练数据又少了,那么第四象限的识别就更加困难了。FSL一直以来被转移学习范式所研究,但目标类除了样例少,目标域的分布也很难和训练集合对等。语音领域举例来说不同手机在不同屋子里录到的声音就有自己的混音、噪声以及直流bias等特点,那么在实验室做录取的声音如何能自适应到各种环境复杂下的声音识别问题,是语音识别的巨大挑战,这个挑战比基于图像的更加难以应对。本篇提出的DA-FSL确实是需要努力的方向。相对于原始的将两个概念简单结合(据说论文之前的算法假设目标和源的标签空间是相同的),对于全局和具体单类分布完全不一样的情景无法覆盖,而DA-FSL通过loss函数的调制,很好的解决了这个看似矛盾的问题。
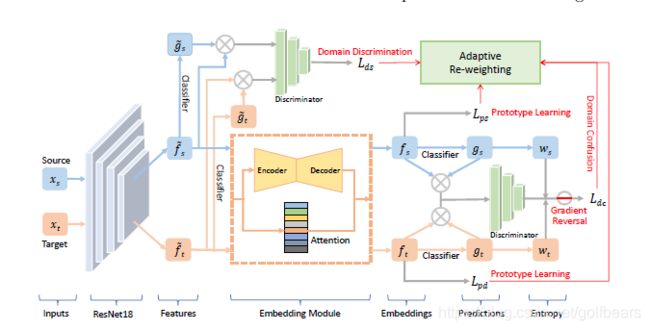 上图就是所谓的DAPN,域对抗原型网络,顾名思义这个网络增加了一个对抗学习方法,去解决few-shot 域自适应问题。unsupervised domain adaptation问题最后往往都依赖于对抗学习,利用discriminator鉴别器来减小源和目标类之间的特征距离。
上图就是所谓的DAPN,域对抗原型网络,顾名思义这个网络增加了一个对抗学习方法,去解决few-shot 域自适应问题。unsupervised domain adaptation问题最后往往都依赖于对抗学习,利用discriminator鉴别器来减小源和目标类之间的特征距离。
网络图有re-weighting模块,即将四个loss值做自适应的评估,这是个典型的多任务学习问题,从图上看这个模型是集大成者(大杂烩),比之前的几个都复杂,虽然作者评估下来是牛的一塌糊涂,但最终是有时间的沉淀才能证明其价值。当然对于ai老白来说,确实是个不错的模型,虽然很多地方都懵懂了。
Meta learning- learning to learn
小样本FSL总是和META-LEARNING混在一起,以至于很难分清楚,也可以把这理解成解决训练资料不多的机器学习的两个方面,源是FSL,方法是meta-learning。meta-learning和multi-task learning又有很深渊源,这块是最近几年非常火的主题。
Model-Agnostic Meta-Learning (MAML)
这个有点复杂,mark一下后面啃。
参考资料
【1】斯坦福《深度多任务学习与元学习》课程(2019) by Chelsea Finn
【2】当小样本遇上机器学习 fewshot learning
【3】关于N-Way K-Shot 分类问题的理解
【4】AutoML: Methods, Systems, Challenges (new book)
【5】最前沿:百家争鸣的Meta Learning/Learning to learn
【6】TEMPORAL CONVOLUTIONAL NETWORKS
【7】《Domain-Adaptive Few-Shot Learning》, An Zhao, Beijing Key Laboratory of Big Data Management and Analysis Method
Gaoling School of Artificial Intelligence, Renmin University of China
【8】《Prototypical Networks for Few-shot Learning》Jake Snell,University of Toronto