论文笔记:基于外部知识的会话模型Commonsense Knowledge Aware Conversation Generation with Graph Attention
Commonsense Knowledge Aware Conversation Generation with Graph Attention
1 出发点
现有的具有外部知识的模型,大多采用非结构化、开放域知识或者结构化、小规模、特定域的知识,这就导致模型存在依赖高质量的非结构化知识的问题或者在开放域的对话场景下表现不佳的问题。而且,大多数模型通常孤立地利用知识三元组(实体),而不是在知识图中将知识三元组作为一个整体来对待。
2 贡献
提出了两种图注意力机制:(1)、静态图注意力机制,编码被检索出来的知识图用来增强输入句子的语义信息,这样可以更好的理解输入。(2)、动态图注意力机制,读取知识图和其中的知识三元组,然后利用其中的信息生成更好的回答。
3 任务定义
给定对话历史 X = x 1 . . . x n X=x_{1}...x{n} X=x1...xn和知识图的集合 G = { g 1 . . . g N G } G=\{g_{1}...g_{N_{G}}\} G={g1...gNG}的条件下,生成一个目标回答 Y = y 1 . . . y m Y=y_{1}...y_{m} Y=y1...ym。每个知识图由一系列的三元组组成 g i = { τ 1 . . . τ N g i } g_{i}=\{\tau_{1}...\tau_{N_{gi}}\} gi={τ1...τNgi},每个知识三元组 τ = ( h , r , t ) \tau=(h,r,t) τ=(h,r,t),分别代表:头实体、关系和尾实体。note: G G G并不是整个知识库中的所有图的集合,只是其中的一部分,这一部分是以 X X X中的单词为索引检索得到的。
作者在模型中使用TransE[1]来表示实体和关系。并且使用MLP使得模型可以使用实体和关系的TransE表示,如公式1所示, k \pmb{k} kkk为一个知识三元组的表示:
k = ( h , r , t ) = M L P ( T r a n s E ( h , r , t ) ) \pmb{k}=(\pmb{h},\pmb{r},\pmb{t})=MLP(TransE(h,r,t)) kkk=(hhh,rrr,ttt)=MLP(TransE(h,r,t))
4 模型
模型整体结构如图1所示,下面分模块依次介绍模型结构。
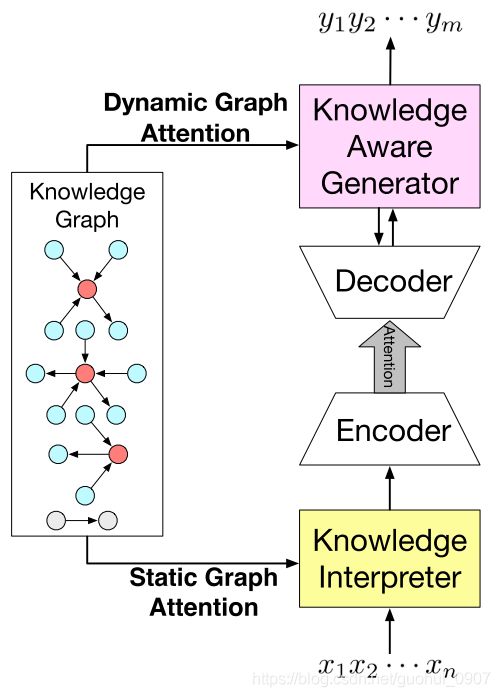
4.1 Knowledge Interpreter
Knowledge Interpreter通过合并单词向量和对应的图向量增强每个单词的语义信息,使得模型更好的理解输入 X X X,如图2:

图2中,单词‘ray’对应于第一个图,其中橙色圆圈代表‘ray’实体,淡蓝色圆圈代表与其有关系的实体,箭头代表关系;单词‘sunlight’对应于第二个图;单词‘of’因为没有对应的实体所以使用一个特殊的图来代表。然后通过静态图注意力机制计算被检索出来的图的向量表示 g i g_{i} gi,并且与单词向量 w ( x t ) w(x_{t}) w(xt)( t t t代表单词的位置)拼接作为单词最终的向量 e ( x t ) = [ w ( x t ) ; g i ] ) e(x_{t})=[w(x_{t});g_{i}]) e(xt)=[w(xt);gi])。下面介绍静态图注意力机制,思想主要来源于[2]。
静态图注意力机制将对应图的所有三元组 K ( g i ) = { k 1 . . . k N g i } K(g_{i})=\{k_{1}...k_{N_{gi}}\} K(gi)={k1...kNgi}作为输入,然后利用注意力机制确定每个三元组的重要性,最后利用加权和得到图向量 g i g_{i} gi,如公式2、3和4:



其中 k n = ( h n , r n , t n ) \pmb{k_{n}}=(\pmb{h_{n}},\pmb{r_{n}},\pmb{t_{n}}) knknkn=(hnhnhn,rnrnrn,tntntn),为每个三元组的向量表达。原文中说明:注意力机制计算的是关系 r n r_{n} rn和实体 h n 、 t n h_{n}、t_{n} hn、tn之间的联系。但是我并没有读懂为什么要这样做,文中也没有具体直观的解释,如果有知道的可以留言,相互学习下。
4.2 Knowledge Aware Generator
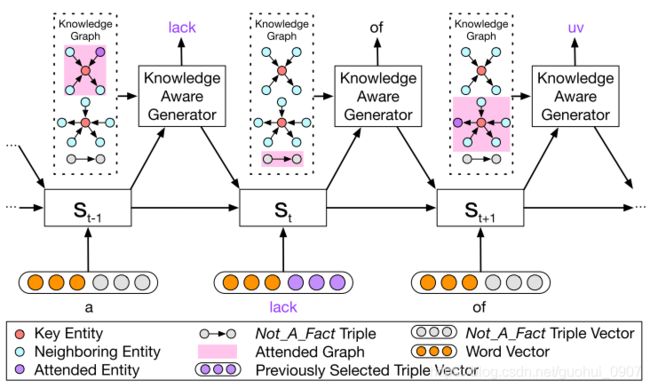
knowledge aware generator通过充分使用被检索出来的知识图中的信息去更好的生成回答,它共有两个作用:(1)、通过每个被检索出来的 g i g_{i} gi生成一个具有图感知的上下文向量用于更新decoder的隐藏状态。(2)、从被检索的图中或者单词表中选择合适的单词生成,如图3:
公式5和6是decoder的隐藏状态的更新操作:
![]()
![]()
这里需要注意下公式6,它与Knowledge Interpreter中的 e ( x t ) = [ w ( x t ) ; g i ] ) e(x_{t})=[w(x_{t});g_{i}]) e(xt)=[w(xt);gi])不同,公式5中的 c t c_{t} ct是对encoder输出的 H = h 1 . . . h n H=h_{1}...h_{n} H=h1...hn的加权和,与常规的具有注意力机制的encoder-decoder结构的做法相一致。 c t g c^{g}_{t} ctg是对图向量 { g 1 . . . g N g } \{g_{1}...g_{N_{g}}\} {g1...gNg}的加权和, c t g c^{g}_{t} ctg是对所有三元组向量 { K ( g 1 . . . K ( g N G ) ) } \{K(g_{1}...K(g_{N_{G}}))\} {K(g1...K(gNG))}的加权和。
动态图注意力机制是一个具有层结构的从上到下的过程。它先利用注意力机制为图向量 g i g_{i} gi做加权和得到 c t g c^{g}_{t} ctg,如公式7、8和9:



其中的注意力机制计算的是decoder的隐藏状态 s t s_{t} st和每个图向量 g i g_{i} gi的关系。
然后利用注意力机制对每个图向量 g i g_{i} gi中的所有 k i k_{i} ki做加权和得到 c t k c^{k}_{t} ctk,如公式10、11和12:

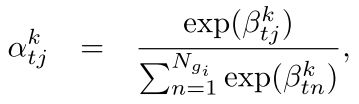

其中注意力机制计算的是decoder的隐藏状态 s t s_{t} st和每个三元组向量 k i k_{i} ki的关系。
最后通过如下规则生成一个单词,如公式13、14、15、16和17:
![]()
![]()
![]()


其中 γ t \gamma_{t} γt是一个标量,用于衡量 P c P_{c} Pc和 P e P_{e} Pe对单词生成的贡献,公式17是将这两个分布拼接,其中每个值我都为下一个要生成的单词概率。note:每个 k i k_{i} ki有三部分构成, k i k_{i} ki所对应的那个实体单词是其中的尾实体,这点可以通过图2可以看出,每次生成的为紫色圆点。
5 相关阅读
[1] Translating embeddings for modeling multirelational data
[2] Graph attention networks