利用决策树学习基金持仓并识别公司风格类型
摘要与声明
1:本文主要利用决策树学习基金持仓并反向推理出一套更受市场认可的风格划分标准,最后借助该模型识别公司所属的风格类型;
2:本文主要为理念的讲解,模型也是笔者自建,文中假设与观点是基于笔者的一孔之见,若有不同见解欢迎随时留言交流;
3:笔者希望搭建出一套交易体系,原则是只做干货的分享。后续将更新更多内容,但工作学习之余的闲暇时间有限,更新速度慢还请谅解;
4:本文主要数据通过Tushare(ID:444829)金融大数据平台接口获取;
5:模型实现基于R 4.1.2;
公司从风格大类上可以划分为成长型,价值型及二者兼而有之的混合型,在实务中,不同风格的划分标准往往通过主观判断,指标计算或市场交易数据拟合风格因子得到。本期笔者利用决策树学习市场上公开交易的风格类基金持仓公司数据,借助算法反向推理出一套更受市场认可的风格划分方式。本文主要内容如下:
目录
1. 为什么要对风格进行识别
2. 风格划分维度
3. 划分标准
3.1 指标评分
3.2 归因分析
3.3 个人判断
4. 算法学习
5. 模型实现
5.1 代码实现
5.2 结果分析
6. 笔者总结
7. 参考文献
1. 为什么要对风格进行识别
相信不少人都在财经媒体上听见“成长股”,“价值股”这两个词,与它们经常一起出现的关键字还有“经济周期”,“景气度”,“轮动”,“大环境”。其实风格更多的是一种大势判断,在不同的环境下选择正确风格的风格能让收益表现更好。相信识别风格对于大多数投资者而言都是一个仁者见仁智者见智的过程,一个人的研究能力所限又不可能熟悉所有行业。四千多家公司,如果依靠人力一家家的判断公司属性是非常麻烦的事情。因此构建一个靠谱的风格识别模型,借助程序去判断不仅为投资者节省大量时间,还可以帮助我们评估持仓风格或者完善风格轮动模型,提高投资组合表现。
2. 风格划分维度
风格其实就算一家公司的特点,特性。对于基本面投资者来说,最广受欢迎的划分方式就是成长型,价值型和二者兼而有之的混合型。同一家公司在发展的不同阶段可以变换多种风格,例如扩张阶段公司规模增长迅速,处于这个阶段的公司大多数是成长型公司;处于行业成熟阶段,市场份额趋于稳定,低市净率高分红的公司则大多是价值型公司;同一个公司也可兼具价值与成长两个特点。当然,还可以增加其它的划分维度。例如晨星(Morningstar)提出的九宫格划分板(Morningstar, 2022a)就是基于风格以及市值两个维度为基础进行划分的,如图一:

图一:风格九宫格划分板
3. 划分标准
既然有了这些维度,难点就在于如何将公司放进对应的格子中。目前市场主流的划分依据有三种类型:指标打分型,归因分析以及主观判断。
3.1 指标评分
例如晨星公司提出的这套九宫格就有一个对应的指标打分系统(Morningstar, 2022b),如下图:

图二:价值打分表及权重设置

图三:成长打分表及权重设置
根据上面的权重设置进行价值和成长分数计算最后加总,分数越接近-100就是价值型,越接近100就是成长型,如图四:

图四:分数加总及风格判定原则
除了晨星公司这套方法,MSCI也有一套打分方法称为Z-Score(MSCI, 2007)。不同点在于MSCI通过每个打分指标转化为变量的分布,然后利用公司各个指标落在分布的位置计算出一个概率。这样做的有点在于该指标不仅可以确定风格类型,还能告诉投资者属于每种类型的概率有多大。这套方法具体计算方式在文末参考文献链接中, 不是本期重点,不展开了。
3.2 归因分析
这个利用的原理其实和之前笔者讲的多因子模型计算折现率是一样的,在多因子计算折现率的FFM和PSM模型中,将个股回报与几个因子回报做回归分析可以通过相关系数β看出该证券属于哪种类型。例如回归出的SML因子敏感系数显著大于0,那么这个公司更倾向于大市值;而SML因子敏感系数如果显著大于0则表名该公司是价值股(原理也不展开了,感兴趣可以看折现率进阶玩法那期内容)。这里确定公司风格类型也是一样的道理,并且这种方式不仅可以分析个股,还可以分析整个投资组合或者一个基金的风格类型,也是重要的因子投资方式和基金经理业绩归因手段。
3.3 个人判断
依靠职业判断(self-identification),指标打分与归因分析其实很大程度上需要依赖历史数据。当一个行业或者公司的未来即将发生重大转折的时候,采用历史数据推测未来很可能得到错误的结果,而这时候专业判断就很重要了。不过这是个仁者见仁智者见智的过程,不同行业和个股在不同人眼里可能产生不一致甚至相冲突的判断结果。
4. 算法学习
以上的几种方式甚至很多大公司都在使用,但笔者认为缺点是非常明显的。除了前文提到的历史数据不等于未来,上面介绍的晨星和MSCI公司模型都是国外公司开发的模型。首先它们提出已经有一段时间了,MSCI公司的模型甚至是2007年的,其权重设计是否依旧合理?能否符合中国市场状况?都要打个问号。再比如因子回归,首先很多数据并不满足线性模型假设,而且寻找有效的纯因子不是一件容易的事情。最后,那些没有被因子所解释的部分统统扔进了残差项,谁能说得清楚这个残差项所代表的经济意义是什么。
综上所述,笔者在模型这块需要选择一些其它的算法。看了一圈就决策树最适合这个任务,首先决策树的结构使得它具有很强的可解释性和经济意义,其次实现起来难度相比神经网络可简单多了(感兴趣的可以看笔者决策树那期文章:决策树的实现及可视化方法总结)。理论上神经网络的识别能力要远强于决策树,但神经网络很大程度上牺牲了模型的可解释性,况且这本身不是一个很复杂的模型,因此笔者退而求其次选择了决策树。
笔者将学习对象定位市场上的各种风格基金的持仓,优点在于1)市场上有很多风格明确的基金,数据获取也较为容易,方便对数据打标签;2)机构选股更具专业性,也更可靠,机构投资者根据风格选择的个股笔者认为可信度较高;3)机构选股往往具有一定前瞻性,一定程度上改善由于单纯使用历史数据造成的偏差;4)机构偏好往往隐含了当前市场状态(即“机构的审美”),学习算法的自我完善能力更加顺应市场变化。
5. 模型实现
数据方面笔者选择了Tushare金融大数据平台(Tushare数据),花两分钟注册即可以使用自己的API请求很多经常使用的行情数据,避免了写大量爬虫的繁重劳动,非常方便。笔者本期所使用的基金持仓数据需要5000分的积分门槛(需要充值)。基金的报告期和正常上市公司财报披露时间很类似,年报一般截至4月底,半年报8月底。笔者选择获取从2021年7月1日之后到2022年6月30日所有符合条件的基金持仓数据,公司财务数据方面选取2022年年度报告,交易数据方面选取2022年7月1日当天的交易数据。当然,获取过去一年的交易数据取平均也是可以的,看自己选择。
5.1 代码实现
模型方面本次笔者使用R语言实现,相比Python,R语言在决策回归树的实现和可视化上友好很多,具体可参考笔者往期决策回归树的内容。首先导入Tushare数据和决策树模块,定义好Tushare接口,双引号中需要填入自己API的密钥:
library(Tushare)
library(rpart)
library(rpart.plot)
api <- Tushare::pro_api("")下面通过API调取所有场内基金数据,包括已经清盘的基金一共1738家:
df <- api(api_name='fund_basic', market='E')
ts_code name management custodian fund_type found_date due_date list_date issue_date delist_date ... min_amount exp_return benchmark status invest_type type trustee purc_startdate redm_startdate market
0 159682.SZ 创业50ETF 景顺长城基金 中国农业银行 股票型 20221223 None 20230103 20221212 None ... 0.1 None 创业板50指数收益率 I 被动指数型 契约型开放式 None 20230103 20230103 E
1 159681.SZ 创50ETF 鹏华基金 交通银行 股票型 20221221 None 20230103 20221212 None ... 0.1 None 创业板50指数收益率 I 被动指数型 契约型开放式 None 20230103 20230103 E
2 159687.SZ 亚太低碳ETF 南方基金 招商银行 股票型 20221216 None 20221230 20221209 None ... 0.1 None 经估值汇率调整的富时亚太低碳精选指数(FTSE Asia Pacific Low Carbo... I 被动指数型 契约型开放式 None 20221230 20221230 E
3 562010.SH 绿色能源ETF 华宝基金 兴业银行 股票型 20221216 None 20230103 20221125 None ... 0.1 None 中证绿色能源指数收益率 I 被动指数型 契约型开放式 None 20230103 20230103 E
1738 rows × 25 columns基金类型非常之多,我们需要在里面挑出风格最明显的两类:价值和成长。从基金信息和描述中我们其实很难看出它是属于成长风格还是价值风格,笔者打算直接在基金名字中筛选带有价值和成长的基金。因为还在运作的基金清盘日期显示为空值,下面用当前日期代替空值并将2022年1月份之前已经清盘的基金筛选出去:
df <- df[grepl("价值", df$name),]
df$due_date[is.na(df$due_date)] <- format(Sys.Date(), format="%Y%m%d")
df <- df[as.data.frame(lapply(df["due_date"], as.numeric))>20220101, ]
下面获取的几家基金就是符合笔者需要的了,接下来获取它们2022年下半年的持仓数据并将上海和深证交易所交易的证券代码存起来。这里笔者筛掉了持仓低于0.5%的,基金经理短期的战术资产配置可能导致风格发生偏移,过小的仓位很可能是玩的一把短线,选择持仓较大的成分股会更符合基金风格一些。最后,因为不同基金可能持有同一家公司,还需要删除重复值:
codes <- c()
for (fund_code in df$ts_code){
try({
table <- api(api_name='fund_portfolio', ts_code=fund_code, start_date='20210631', end_date='20220701')
table <- table[table$stk_mkv_ratio > 0.5,]
table <- table[grepl(".SH", table$symbol) | grepl(".SZ", table$symbol),]
codes <- c(codes, table$symbol)
})
}
codes <- unique(codes)下面根据这些证券代码获取财报指标以及交易数据,由于财务指标数据每次请求最多返回60条记录,下面笔者写了个循环批量遍历证券代码列表:
code <- paste(codes[1:30], collapse=",")
data_growth <- api(api_name='fina_indicator', ts_code=code, period='20211231')
for (i in c(1:floor(length(codes)/30-1))){
code = paste(codes[(30*i):(30*(i+1))], collapse=",")
data_growth <- rbind(data_growth,api(api_name='fina_indicator', ts_code=code, period='20211231'))
}
code <- paste(codes[(30*(i+1)):length(codes)], collapse=",")
data_growth <- rbind(data_growth,api(api_name='fina_indicator', ts_code=code, period='20211231'))
data_growth <- data_growth[!duplicated(data_growth$ts_code),]
交易数据则比较简单,没有返回数量限制,获取基金22年7月1日的交易数据并与之前的财务数据表进行列合并:
trade_data <- api(api_name='daily_basic', ts_code=paste(codes, collapse=","), trade_date='20220701', fields='ts_code,pe,pb,total_mv,dv_ratio,dv_ttm')
data_growth <- merge(data_growth, trade_data, by="ts_code")
data_growth <- data_growth[, !names(data_growth) == "trade_date"]这里值得注意的是,对于基金数据发布日期和截至日期笔者认为大可不需要考虑是否存在前视偏差。比如基金年报数据是截止到2021年12月,但真正公布出来很可能已经是次年4月底了。正常模型设计需要考虑到数据可得的时间点,但笔者本次的任务主要是依靠决策树的可解释性反向推理出一套风格评价指标,主要目的并非是预测未来,因此笔者完全可以假设在截止日就立马可以拿到数据。但如果该模型的任务变成预测未来,不仅需要考虑数据真正发布的时间点,还需要检验数据平稳性,做时间序列交叉验证,如果缺乏平稳性的数据还有考虑是不是需要重新选取变量,重新设计,考虑加入强化学习等等。这一串下来本文就会显得太过冗长,毕竟不是谈怎么处理数据,与本文主题不符了。
以上代码是可以整合成函数的,函数里还可以写入日期变量,如果需要做时间序列交叉验证就可以反复调用该模块:
data_mod <- function(style){
df <- api(api_name='fund_basic', market='E')
df$due_date[is.na(df$due_date)] <- format(Sys.Date(), format="%Y%m%d")
df <- df[as.data.frame(lapply(df["due_date"], as.numeric))>20220101, ]
codes <- c()
for (fund_code in df$ts_code){
try({
table <- api(api_name='fund_portfolio', ts_code=fund_code, start_date='20210701', end_date='20220630')
table <- table[table$stk_mkv_ratio > 0.5,]
table <- table[grepl(".SH", table$symbol) | grepl(".SZ", table$symbol),]
codes <- c(codes, table$symbol)
})
}
codes <- unique(codes)
code <- paste(codes[1:30], collapse=",")
data_style <- api(api_name='fina_indicator', ts_code=code, period='20211231')
for (i in c(1:floor(length(codes)/30-1))){
code = paste(codes[(30*i):(30*(i+1))], collapse=",")
data_style <- rbind(data_style,api(api_name='fina_indicator', ts_code=code, period='20211231'))
}
code <- paste(codes[(30*(i+1)):length(codes)], collapse=",")
data_style <- rbind(data_style,api(api_name='fina_indicator', ts_code=code, period='20211231'))
data_style <- data_style[!duplicated(data_style$ts_code),]
trade_data <- api(api_name='daily_basic', ts_code=paste(codes, collapse=","), trade_date='20220701', fields='ts_code,pe,pb,total_mv,dv_ratio,dv_ttm')
data_style <- merge(data_style, trade_data, by="ts_code")
data_style <- data_style[, !names(data_style) == "trade_date"]
return(data_style)
}
data_growth <- data_mod("成长")
data_value <- data_mod("价值")运行得图五,程序目前获取到成长类541家公司,价值类461家公司上百个指标:

图五:运行变量
下面笔者按500亿市值为分水岭,将这些公司划分为4类并打上标签:
data_value_flitter <- !data_value$ts_code %in% data_growth$ts_code # 过滤器
data_growth_flitter <- !data_growth$ts_code %in% data_value$ts_code # 过滤器
data_value <- data_value[data_value_flitter,] # 重复的删除
data_growth <- data_growth[data_growth_flitter,] # 重复的删除
data_value$label[data_value$total_mv>5000000] <- 3 # 大盘价值
data_value$label[data_value$total_mv<=5000000] <- 1 # 中小盘价值
data_growth$label[data_growth$total_mv>5000000] <- 2 # 大盘成长
data_growth$label[data_growth$total_mv<=5000000] <- 0 # 中小盘成长笔者划分这几类就够笔者个人使用了,其次笔者发现划分更多类反而使得模型解释力度下降,有些得不偿失。其实也可以按照晨星九宫格那样划分得更加细致,无非是将市值再划分出一档。另外,这些公司中部分是重复的,说明机构有的认为它是成长,有的认为是价值,因此可以将这些在价值和成长列表中重复的公司作为混合型再创一个标签。也可以直接将重复的数据全部删去,笔者这里认为这些数据更多是噪音,因为选取的部分基金是被动型ETF。
接下来将成长和价值数据合并进一个大数据集,数据集前四列是一些日期、公司代码等无用信息,需要去掉。Tushare将亏损企业的市盈率,不分红的公司和一些没有的财务指标设置为空值,对这些值直接以0填充即可。数据中像收盘价,总股数这类没有意义的数据笔者不希望被决策树学习,因此直接删掉。最后得到的数据集共有近600条:
data_set <- rbind(data_growth, data_value)
data_set <- data_set[!duplicated(data_set$ts_code),]
data_set <- data_set[, 4:ncol(data_set)]
data_set[is.na(data_set)] <- 0
data_set <- data_set[, !names(data_set) == "close"]
data_set <- data_set[, !names(data_set) == "total_share"]
data_set <- data_set[, !names(data_set) == "float_share"]
> nrow(data_set)
[1] 576接下来建立一个随机抽样的测试集,剩下的数据当成训练集,测试集约占总体样本的近20%。设定随机数种子,导入决策树并确定剪枝参数,最后可视化输出就大功告成了:
set.seed(66)
test = sample(1:nrow(data_set), 100)
tree <- rpart(label~., data=data_set[-test, ], method="class")
plotcp(tree)
tree.prune <- prune.rpart(tree, cp=0.05)
rpart.plot(tree.prune, tweak=1.2, type=1) 运行上面代码可得图七,虽然笔者放了上百个变量,但图七决策树所选取的变量仅仅只有四个:
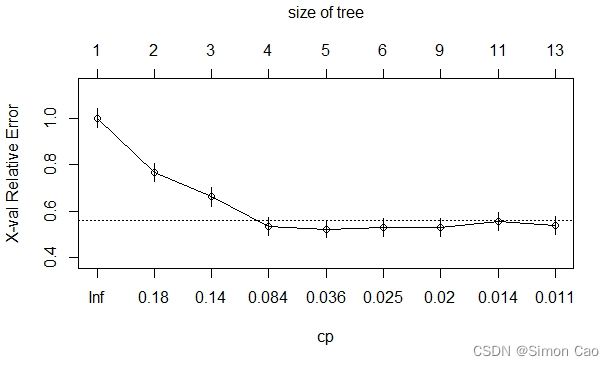
图六:剪枝参数与误差收敛情况

图七:决策树可视化输出
5.2 结果分析
简单分析生成的这颗决策树。根据图七,从决策树的决策依据来看该模型具有不错的经济意义。以右1叶节点为例,该节点的标签为大盘价值风格,对应的公司为总市值大于500亿,股息率大于0.46%,而右2叶节点则是股息率小于0.46%的公司。这与价值股高分红,成长股低分红的常识是一致的,并且模型还在常识的基础上进一步量化地告诉了我们这个分红高低到底是多少算高,多少算低。
从左1节点来看,该节点标签为小盘成长股,对应公司为市值小于500亿,PB大于2.6,这一样可以和成长股低PB的特点对应上。至于左二决策节点op_yoy代表的是营业利润同比增长率(%),一样可以看出成长类公司业务扩张迅速,营业利润同比增长快,而价值类公司增长低的特点。
当然,必要的测试还是需要的,使用测试集进行测试并输出混淆矩阵:
result<- predict(tree.prune,data_set[test,],type="class")
metrics_res <- data.frame(result, data_set$label[test])
table(metrics_res)
> table(metrics_res)
data.label.test.
result 0 1 2 3
0 43 11 0 0
1 7 13 0 0
2 0 0 12 1
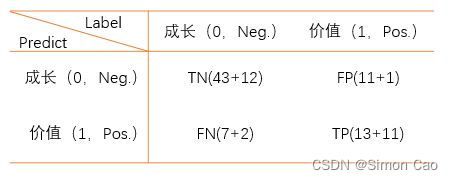
3 0 0 2 11将上面这个矩阵按照成长股为负例,价值股为正例进行划分可以消除掉市值这个维度,即列0与列2相加,列1与列3相加;行0与行2相加,行1与行3相加,最后可得图八的混淆矩阵:
图八:风格维度混淆矩阵
可以计算一下几个关键指标,准确率在79%,该模型对成长股的判别能力较强,但对价值股的判别能力较弱:
> cat("accuracy", (43+12+13+11)/100)
accuracy 0.79
> cat("flase negative rate", (7+2)/(43+12+7+2)) # 成长股被预测为价值股占成长股总数的概率
flase negative rate 0.140625
> cat("False positive rate", (11+1)/(11+1+13+11)) # 价值股被预测为成长股占价值股总数的概率
False positive rate 0.33333336. 笔者总结
上面的模型是设置了随机数种子的,如果不设置那么生成的决策树可能会有些许差异。当然也可以不使用随机数种子,这样每次运行出来的树会有差别,例如下面这颗:

图九:随机生成的一颗决策树可视化输出
在使用该模型时需要注意生成的决策树是否具有经济意义。例如,不删除收盘价,流通股数这些变量,决策树很有可能将这些没有意义的变量判定为统计上显著而当成决策依据。
但该模型也是有局限性的,即假设基金配置是有效的。因此,无效的市场,基金短期内的战术资产配置导致的风格偏移都很容易使得模型打的标签不准确。另外,上面获取的基金中一部分是指数型ETF,笔者认为一些价值指数编制是有水分的,像一些价值ETF追踪的指数是上证50或者上证180这样的大市值公司。不可否认大部分大市值公司价值属性较强,但不能说100%都是价值类公司,这些数据都被一股脑纳入模型进行学习会带来很多噪音。
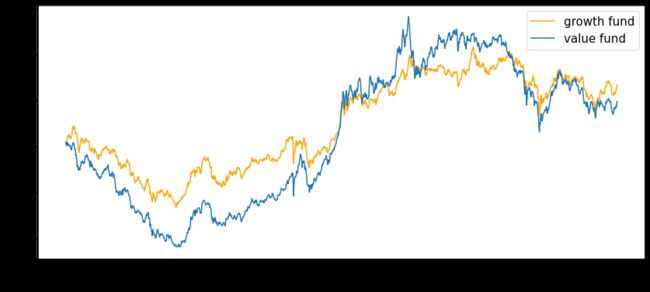
最后稍微补充一点笔者对有效性的看法,笔者认为受到数据显著,有效性是打了折扣的。笔者将18年到现在名字中带有价值和成长两个关键字的基金分别构建两个投资组合,组合净值走势如图十:
图十:全市场价值型和成长型基金投资组合NAV走势(除权)
经笔者计算,两个组合回报率相关系数为78%,NAV走势相关系数高达98%。价值型和成长型公司的走势虽然不能说毫不相干,但走出这样高度一致的走势令人费解。毕竟数据本身如果存在偏差,模型学习到的结果自然要大打折扣。不过笔者仅仅使用了名字中带有成长和价值的基金行情数据,或许还有些符合条件的基金没有被纳入。其次,很多被动基金也被纳入了统计,被动基金的风格可能没有主动配置来得更鲜明。只是笔者就没有继续往下深挖了,感兴趣的读者可以自行研究。
您若不弃,我们风雨共济。
7. 参考文献
Morning star. 2022. 'Morningstar Style Box'. https://www.morningstar.com.au/learn/investing/225142/morningstar-style-box
MSCI. 2007. 'MSCI Global Investable Markets Value and Growth Index Methodology'.https://www.msci.com/eqb/methodology/meth_docs/MSCI_Dec07_GIMIVGMethod.pdf