Segmentation of Individual Trees From TLS and MLS Data
Abstract
地面激光扫描(TLS)和移动激光扫描(MLS)数据可用于获取丰富而精确的树木边信息。因此,它可以提取树高、树冠大小、树冠基高、胸径等个体参数,为森林研究和管理提供基础数据。本研究提出了一个技术框架,用于从 TLS 和 MLS 数据中分割单个树。该框架包含六个步骤:1) 数据预处理,2) 八叉树构造,3) 空间聚类,4) 茎检测,5) 初始分割,以及 6) 重叠冠层分割。该框架有两个主要贡献:1)自上而下的层次分割方法,包括基于连通性的空间聚类(区域尺度)、基于茎的初始分割(个体树尺度)和重叠树冠的精细分割(树冠尺度),提出降低技术难度,提高工艺效率; 2) 提出了一种改进的针对分割重叠树冠的归一化切割方法的节点相似度计算,即使相邻树木的树冠重叠也能有效分离。所提出的框架在离开地面 LiDAR 数据集和离开移动 LiDAR 数据集上进行了测试。对于地面 LiDAR 数据,我们的框架实现了 92.4% 的完整性、95.4% 的正确性以及 0.94 的 F 分数。对于移动 LiDAR 数据,相应的值为 94.0%、93.7% 和 0.94。
Index Terms——个体树、LiDAR、归一化切割 (Ncut)、八叉树、分割。
I. INTRODUCTION
小型光探测和测距 (LiDAR) 数据的个体树木分割在森林研究中有多种应用 [1]-[5]。树高、树冠大小和树冠基高可以直接从 3-D 点云 [6]-[10] 获取,生物量和碳储量可以使用基于个体树结构的经验方程来估算 [9] –[13]。根据安装扫描仪的平台,小尺寸激光雷达可分为机载激光雷达、地面激光雷达(也称为TLS)和移动激光雷达(也称为MLS)。机载激光雷达的点密度较低(通常每平方米几个到几十个点),单棵树获取的点很少;此外,自上而下的数据获取方式使得获取树干和树枝的点数困难,限制了其在单树尺度上的进一步研究和应用。相比之下,TLS和MLS采用侧视扫描方式,具有高点密度(通常每平方米数百至数千个点);因此,他们可以获得丰富的树侧信息,例如树干、树枝,甚至内部树冠的细节,这对于个体树尺度 [14]、[15] 非常有用。
尽管有这些优点,但到目前为止,很少有研究关注使用 TLS 或 MLS [16] 的个体树分割。此外,此类研究大多针对大间距行道树进行试验,很少考虑冠层重叠度高的情况。 Bienert 等人根据水平切片分析从地面 LiDAR 数据中检测到树木 [17]。 Lin 和 Hyyppa 使用商业 TerraScan 软件交互式地隔离与树相关的点簇以执行树冠重建 [3]。 Wu 等人提出了一种基于体素的标记邻域搜索方法,包括种子选择和区域生长,用于识别行道树并推导其形态参数;这种方法在树木很少相互重叠的测试地点实现了 98% 的树木检测准确率 [18]。 Lin 等人介绍了一种基于冠层表面模型的三级框架和 RD-schematic 算法(类似于旋转门的搜索示意图),用于从移动 LiDAR 数据中分割单个树木;他们达到了 83% 的准确性和 89% 的精确度 [16]。Liang等人提出了一种基于激光点空间分布特性的全自动stem-mapping算法,整体精度达到73%;然而,他们的方法没有处理冠层分割 [19]。
目前的方法不够稳健,无法处理重叠冠层分割中的不同冠层情况。 Zhong等通过分析不确定点到双侧树干的距离与不确定点到双侧树顶的距离的比值关系,对重叠的树冠进行分割;然而,这种方法不适用于处理各种形状的冠层,因为它只考虑距离因素[20]。 Reitberger 等人介绍了归一化切割 (Ncut),这是一种非常有效的二维图像分割技术,用于从机载 LiDAR 数据中分离出单个树木 [21]。 Yu 等人使用 Ncut 将个别树木与附近的灯杆分开 [22]。然而,使用传统的Ncut方法分割具有两棵以上树的点时,不能保证个体树的完整性。
目前针对基于机载LiDAR数据的单个树点分割的研究通常可分为基于栅格的方法和基于点的方法。前者将 LiDAR 点插入到冠层高度模型 (CHM) 或冠层表面模型中,然后使用二维图像处理算法,例如分水岭分割和模板匹配来分割单个树木 [7]、[23]、[24]。后者通过搜索种子点然后基于种子点进行空间聚类或区域生长来生成单个树的树冠 [2],[25]。 Li 等人提出了一种基于树木的相对间距和生长区域的算法来分割混合针叶林中的个体树木,并得出针叶林中的整体 F 分数为 0.9;然而,他们的方法在应用于落叶林时效果较差 [26]。 Lee 等人开发了一种具有最小搜索半径 (sr) 的自适应聚类方法来检测所有可能的种子点,然后合并部分树木检测以获得佛罗里达州中北部管理松林中的个体树木,总体准确率为 95.1%;然而,他们的方法需要使用本地地面实况数据进行训练才能获得最佳结果 [8]。 Jing等提出了一种基于多尺度分析和分割的树冠勾画方法,并在加拿大安大略省的天然林中进行了试验;他们在封闭冠层针叶林、落叶林和混交林中的准确率分别为 69%、65% 和 73% [23]。 Lu 等人开发了一种基于强度和 3-D 结构的自下而上的方法,从 leave-off LiDAR 点云中分割单个落叶树;在宾夕法尼亚州 Shavers Creek Watershed 的森林中进行的一项实验中,他们获得了 0.9 的总体 F 分数 [2]。然而,激光雷达强度信息的需求和树木的离开条件限制了该方法的进一步应用。
虽然机载 LiDAR 数据中个体树木的分割已有相对成熟的方法,但由于观察几何和信息内容的差异,针对机载 LiDAR 数据设计的算法和方法无法直接转化为 TLS 和 MLS 数据 [16], [18]。然而,为 TLS 和 MLS 数据开发的现有方法无法适当地处理高度重叠的树冠。本研究提出了一个技术框架,用于从 TLS 和 MLS 数据中分割单个树点。
本文的其余部分安排如下。第二节详细描述了所提出框架的工作流程和技术。第三节介绍了使用两个不同的 LiDAR 数据集对所提出的框架进行的实验和评估。第四节讨论了框架的几个关键参数和某些缺点。最后,第五节介绍了本研究的结论。
II. METHODOLOGY
图 1 显示了所提出的个体树点分割技术框架的流程图。它包含六个主要步骤:1)数据预处理,2 八叉树构造,3)空间聚类,4)树干检测,5)初始分割,6)精细分割。
对原始激光雷达点云数据预处理,去除地面点和建筑立面点。然后构建用于点空间索引的八叉树结构,并将预处理后的点根据它们的连通性聚类到局部块(点集)中。对于每个聚类点集,再次构建八叉树结构,通过分析八叉树节点的水平直方图来检测点集中的所有树干。然后根据树干位置进行初始树分割,生成树核心区域和重叠区域。最后,采用改进节点相似度计算的 Ncut 方法对重叠冠层进行分割并导出单个树点。
地面点和建筑物立面点倾向于将来自不同树的点桥接成一个点集;如果不删除它们,它们可能会影响空间聚类过程。此外,如果一棵树离建筑物立面点太近,建筑物立面点将显着影响树干检测结果。对于移除地面点,lastools 中的 lasground 工具表现出良好的性能,可以直接用于此目的。为了检测和消除建筑物立面点,投影点密度方法[27]、[28]因其计算速度快和鲁棒性而被选中。
A. Octree Construction
八叉树构造的目标是提供具有高位置精度的有效空间索引。与机载激光雷达相比,TLS数据和MLS数据的点密度要高很多;因此,他们可以更详细地描述树结构。然而,如果直接处理原始激光雷达点,则高点密度(每平方米数十至数千个点)需要大量计算机资源进行空间搜索。因此,有必要为原始 TLS 和 MLS 数据建立空间索引,以实现更好的点云管理。
八叉树是一种高效的空间索引结构。 LiDAR 点的空间索引通常可以分为两类:基于对象的空间索引和基于空间的空间索引。前者根据空间对象的分布来组织数据集,如R-tree [29]、[30],后者根据底层空间的细分来细分数据集,如四叉树[31]和它的 3-D 扩展,八叉树 [32]–[34]。其中,八叉树可以直接应用于点几何,而不是 R 树所依赖的仅边界框。另外,R-tree中的叶子节点经常相互重叠,而octree中不存在这个缺点。因此,八叉树相对于 R 树 [32] 在空间索引方面具有明显的优势。要为 LiDAR 点构建八叉树结构,首先导出最小边界体素作为根节点。如果根节点不满足分裂停止规则,它将被分裂成八个等容子节点。对每个子节点(认为是最小边界体素)重复上述判断和划分,直到满足停止规则。
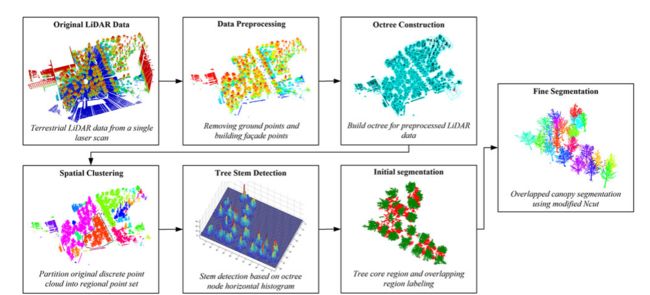
图 1. 拟议框架的流程图。
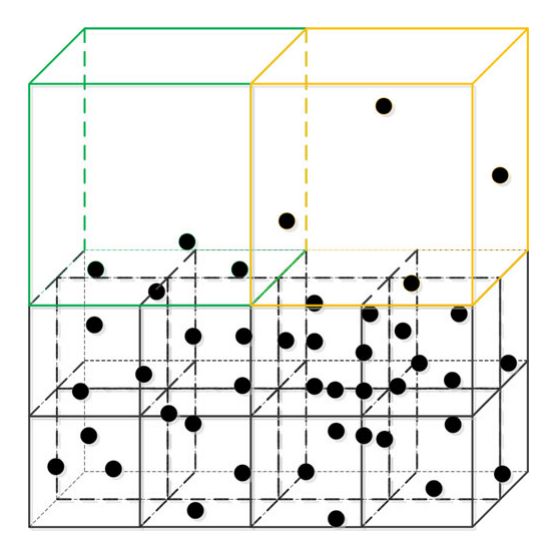
图 2. 边界型(绿色)和稀疏型(橙色)假脂肪节点示例。
最常用的八叉树包含许多位置精度低的叶节点,本文称为假胖(fake-fat)节点。该空间索引以最小节点大小(mns,也称为粒度)和最小点数(mnp)作为拆分规则[34],即,如果派生子节点小于 mns 或点数小于mnp,它将被视为叶节点。然而,仅考虑 mnp 和 mns 作为分裂停止规则,尺寸大但内部 LiDAR 点很少的叶节点更有可能出现在点密度低的区域,例如对象的边界。假脂肪节点可以是分为边界型和稀疏型,如图2所示。边界型节点通常出现在物体边界周围,其中LiDAR点强烈分布在节点的一侧或特定角落。 另一方面,稀疏型节点通常出现在点密度低的区域,内部点被认为具有随机分布。与普通叶节点相比,边界型假肥节点存在以下几个缺点:1)节点位置不能代表内部点的平均位置,因为所有点占据的节点空间不到一半; 2)由于假肥节点体积大,在邻域搜索中很容易找到伪邻居节点和激光雷达点,并且更容易与其他节点形成邻域关系,距离较远的点很可能成为伪节点的邻居桥接。
为了减少假胖节点,本研究在构建八叉树时修改了节点分裂规则。除了最常用的 mns 和 mnp [34] 之外,我们还为新的八叉树结构添加了点分布模式 (pds)。在构建八叉树时,如果当前节点的大小大于mns,且其内部点数小于mnp,则触发pds判断检查点分布。如果所有点占用的节点空间都小于一半,则分裂继续;否则,该节点的分裂过程将停止,并将其标记为叶节点。通过附加规则,可以在派生的八叉树结构中避免边界类型的假胖节点,因此,即使在对象的边界区域中,节点的平均位置精度也会提高。
在这项研究中,八叉树节点被定义为拥有一个结构,包括节点位置(节点几何中心的 x、y 和 z 坐标)、节点大小(边的长度)、LiDAR 点、父亲节点和子节点的指针,以及显示分类结果的标志。为了表达方便,将停止规则中的最小节点大小设置为mns,最小激光雷达点数设置为mnp;八叉树由以下步骤构建(见图3所示的流程图)。
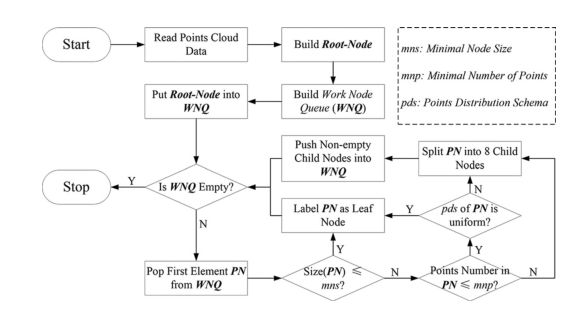
图 3. 构建八叉树的流程图。
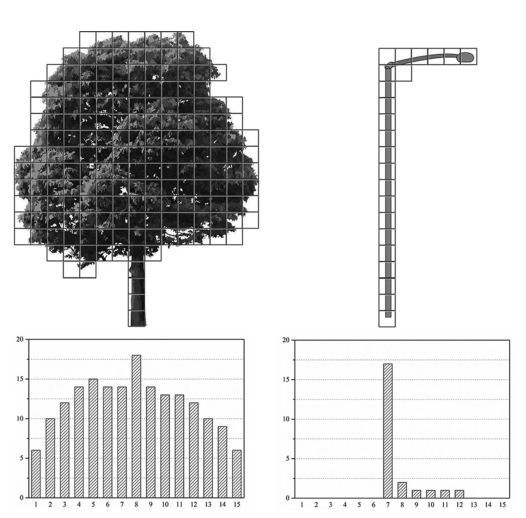
图 4. 树和灯杆的水平直方图剖面示例。
第一步:输入给定的激光雷达点云,得到三个方向的范围 ( Max X , Min X , Max Y , Min Y , Max Z , Min Z ) (\operatorname{Max} X, \operatorname{Min} X, \operatorname{Max} Y, \operatorname{Min} Y, \operatorname{Max} Z, \operatorname{Min} Z) (MaxX,MinX,MaxY,MinY,MaxZ,MinZ)。
第二步:根据点的范围建立根节点。根节点左下角以 ( Min X , Min Y , Min Z ) (\operatorname{Min} X, \operatorname{Min} Y, \operatorname{Min} Z) (MinX,MinY,MinZ)开头,为计算方便,大小为2的整数次幂,如(1)所示。然后应将所有 LiDAR 点添加到根节点
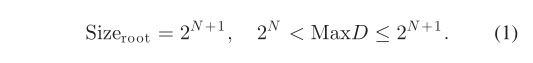
这里, Max D = Max ( ( Max X − Min X ) , ( Max Y − Min Y ) \operatorname{Max} D=\operatorname{Max}((\operatorname{Max} X-\operatorname{Min} X),(\operatorname{Max} Y-\operatorname{Min} Y) MaxD=Max((MaxX−MinX),(MaxY−MinY), ( Max Z − Min Z ) ) (\operatorname{Max} Z-\operatorname{Min} Z)) (MaxZ−MinZ))。
第三步:构建工作节点队列(WNQ),将根节点推入WNQ。
第四步:如果WNQ为空,则八叉树构建成功,流程结束。否则,从 WNQ 弹出第一个元素 PN。
第五步:如果PN的大小不大于mns,则将其标记为叶节点,跳转到第四步,否则进入下一步。
第六步:如果PN 中的点数大于mnp,则跳至步骤8。否则,进行下一步。
第七步:分析点在 PN 中的分布模式。如果这些点强烈分布在 PN 的一侧或特定角落,请转到下一步。否则,跳到步骤 4。为了判断 PN 的点分布模式,我们首先对 PN 应用八叉树分区,将 PN 分成八个等容子节点,然后搜索所有空子节点。如果存在四个共面的空子节点(PN 的任意面),则 PN 的点被认为是强分布的(在另一侧)。否则,它们被认为具有随机分布。
第八步:对节点PN应用八叉树划分,更新每个子节点中的LiDAR点,清除PN中的所有点以释放计算机资源。将非空子节点压入 WNQ,然后跳转到第 4 步。
B. Spatial Clustering Using Octree Node Connectivity
数据预处理后,去除地面点和建筑立面点,对剩余点进行空间聚类;然而,属于特定对象的点在点云中仍然是离散和无组织的,在树提取或分割之前需要通过一定的策略对其进行组织。
空间聚类的基本目的是将来自同一对象(被认为在空间上相邻)的点分组,并根据点云中存在的间隙与其他组进行区分,从而可以直接导出单个树点。然而,点云中的间隙不仅存在于不同的树之间,而且存在于单个树内部(由遮挡引起)。此外,在许多情况下,树冠经常相互重叠;这减少了树之间的间隙并增加了从不同树中隔离点的难度。因此,在本研究中,实际应用空间聚类将整个点云划分为局部点集块,因为在直接单树推导中难以实现正确性和完整性的双赢解决方案。
大多数现有研究采用欧几里得距离进行点空间聚类[8],[22],如果点之间的欧几里得距离小于给定阈值,则将点标记为同一类。这种方法的缺点是对于复杂的环境,指定一个合适的阈值是非常具有挑战性的[8]。在这项研究中,我们使用八叉树节点邻接点对点进行聚类,将空间相邻节点和内部 LiDAR 点标记为同一类。
为了判断节点是否在空间上相邻,搜索26个邻域,即节点i和j是否满足以下公式:
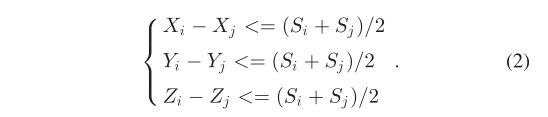
然后,节点 i i i和 j j j被认为是空间相邻的。请注意, ( X i , Y i , Z i ) \left(X_i, Y_i, Z_i\right) (Xi,Yi,Zi)和 ( X j , Y j , Z j ) \left(X_j, Y_j, Z_j\right) (Xj,Yj,Zj)表示几何形状, S i S_i Si 和 S j S_j Sj分别表示节点 i i i和 j j j的节点大小。
C. Tree Stem Detection
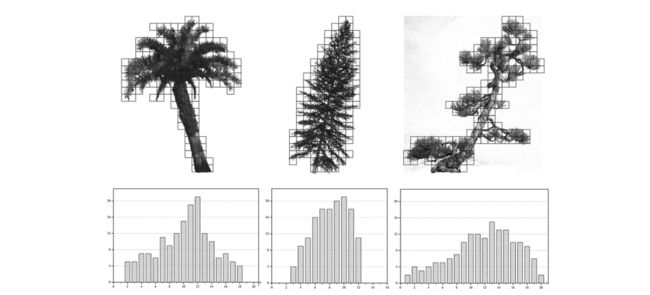
图 5. 典型斜干树的示例及其水平直方图轮廓。八叉树节点直方图的局部最大值揭示了最大绿色体积所在的位置,这比树根更适合表示树的位置。
每个聚类点集可能包含几棵树。要获得单个树点,首先需要检测树干。大多数现有研究使用局部最大值方法来检测来自 LiDAR 数据的茎。他们假设树顶位于局部景观的最高部分,并通过从 LiDAR 点、CHM 或 3-D 体素结构中搜索局部最大值来提取树干位置 [21]、[35]、[36] ].然而,局部最大值包含许多非树对象,例如灯孔、建筑物顶部,甚至行人;这些会降低词干检测结果。此外,在许多情况下,树干的水平位置与其树冠峰顶并不重合;这会降低使用此方法检测到的茎的位置精度。
在这项研究中,我们在八叉树节点的水平直方图中搜索局部最大值以检测潜在的词干(候选词),并分析每个候选词的形状特征以进行可靠性检查,以从候选词中去除假词干。 TLS 和 MLS 可以产生丰富的树木剖面信息,甚至是机载激光扫描无法到达的树干和一些内部树枝。通常,对于直立的树干树,垂直方向上八叉树节点的最大数量出现在树干位置(见图 4)。对于斜杆情况(见图5),虽然直方图的局部最大值不在树根上,但它揭示了某棵树范围内绿色体积(单位面积所有茎叶的总体积)的局部最大值, 比树根更适合表示树的位置。
基于此属性,我们首先为每个聚类点集构建一个八叉树结构,并生成节点的水平直方图。然后搜索直方图中的局部最大值以检测干候选,并移除浮动候选(那些未链接到地面的)。为了从主干候选中去除灯杆和行人,分析了局部直方图的形状特征(波峰的 leptokurtic 或 platykurtic)。大多数树冠以树干为轴对称,具有一定的覆盖率;结果,直方图中的频率从最大值(主干所在的位置)向各个方向的邻域缓慢减小,使得直方图的波峰相对平坦。对于灯杆和行人,频率急剧下降,并且只在几个方向上,使直方图峰呈尖峰状,如图 4 所示。
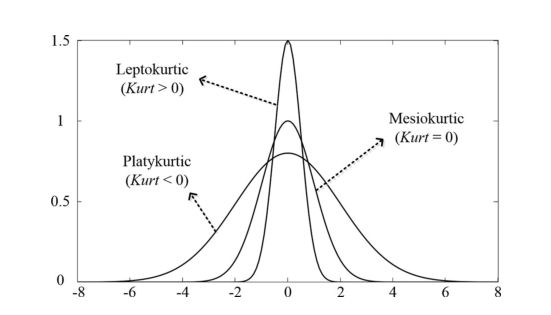
图 6. 具有不同峰度的曲线的 Leptokurtic(或 platykurtic)度数差异。
本文使用峰态来定量衡量直方图是尖峰态还是扁平峰态。峰态定义如 (3) 中。如果给定的数据集具有标准正态分布、尖峰分布和平峰分布,则峰度分别为 0、大于 0 和小于 0,如图 6 所示。
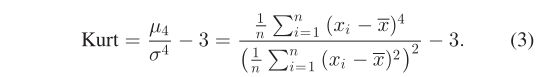
对于每个候选者,我们首先计算某个邻域内直方图中四个剖面(水平、垂直、前对角线、次对角线)的峰度,并将它们的平均值作为候选者的峰度。然后应用阈值分割来去除错误检测的词干,以确保高词干检测精度。
D. Initial Segmentation Based on Tree Stem
对于初始分割,基于派生的词干构建 Voronoi 图,其中每条边分隔两个词干。为每条边创建一定大小的缓冲区。缓冲区标记为树重叠区域,其余部分标记为树核心区域,如图 7 所示。
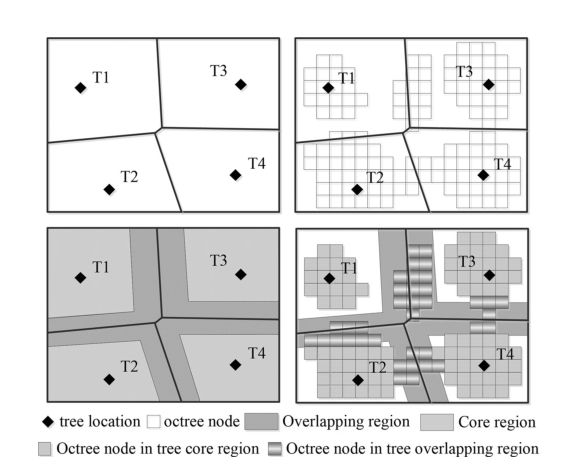
图 7 树木核心区和重叠区示意图。
树重叠区域中的节点根据与两侧树核心区域的连通性有三种情况。如果节点仅与一侧相连,则将它们标记为相连核心区域的类别。例如,在图 6 中,T1 和 T2 之间重叠区域的节点与 T2 相连,与 T1 断开,因此,它们被标记为 T1。如果节点与两侧断开连接,如 T1 和 T3 之间的情况,则计算这些节点的平均水平位置到两侧茎的距离,并将节点分配到较近的茎类。如果节点连接到两侧,如 T2 和 T4 之间的情况,则假设存在重叠的冠层,并采用下一节中描述的分割方法。
E. Fine Segmentation of Overlapped Canopy Using Ncut
为了分割相邻树木之间重叠的树冠,然后采用 Ncut 分割。 Ncut 分割工作在加权连通图上,通过使用动态规划的概念将图切割成两个子图的成本最小化来分割给定的对象。 Shi 和 Malik 首先提出将 Ncut 应用于二维图像分割,其中通过基于图像像素构建加权图并删除图中总成本最小的一组边,将图像分为两部分 [ 37]。 Reitberger 等人将 Ncut 扩展到 3-D 空间,并将其应用于使用 3-D 体素作为图节点的机载 LiDAR 数据分割;这种方法在分离相邻树木方面显示出良好的性能 [21]。 Yu等人使用Ncut进行移动LiDAR数据分割;他们的方法有效地将灯杆与附近的树木隔离开来 [22]。为了更好地理解 Ncut 的工作原理,下一节将简要介绍 Reitberger 的 Ncut 方法。
首先,构建输入聚类点集的 3-D 体素结构。然后,创建一个加权图 G = { V , E } G=\{V, E\} G={V,E},其中 V V V表示由具有内部点的体素表示的图节点集, E E E表示连接节点的图边集。边 E i j E_{\mathrm{ij}} Eij的权重为通过节点 i 和 j 的相似性
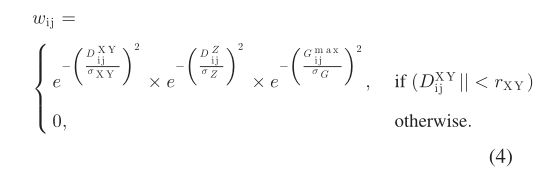
请注意, D i j X Y D_{\mathrm{ij}}^{\mathrm{XY}} \quad DijXY和 D i j Z D_{\mathrm{ij}}^Z DijZ分别表示节点 i i i和节点 j j j之间的水平距离和垂直距离。 G i j max = max ( D min X Y ( i G_{\mathrm{ij}}^{\max }=\max \left(D_{\min }^{\mathrm{XY}}(i\right. Gijmax=max(DminXY(i, Stems ) , D min X Y ( j ), D_{\min }^{\mathrm{XY}}(j ),DminXY(j, Stems ) ) \left.)\right) )),其中 D min X Y ( i D_{\min }^{\mathrm{XY}}(i DminXY(i, Stems ) ) )表示节点i与最近的茎之间的水平距离。 σ X Y , σ Z \sigma_{\mathrm{XY}}, \sigma_Z σXY,σZ, 和 σ G \sigma_G σG分别表示 D i j X Y , D i j Z D_{\mathrm{ij}}^{\mathrm{XY}}, D_{\mathrm{ij}}^Z DijXY,DijZ, and G i j max G_{\mathrm{ij}}^{\max } Gijmax的标准差。 r X Y r_{\mathrm{XY}} rXY表示相似度的水平影响半径;如果节点的水平距离超出 r X Y r_{\mathrm{XY}} rXY,则节点没有相似性。
Ncut的目标是通过最大化线段成员的相似度和最小化线段A和B之间的相似度,将图G切割成两个不相交的节点线段A和B。将G线段分割成A和B的成本可以描述如下:
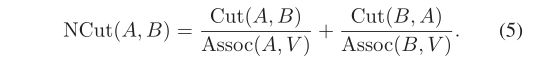
在 (5) 中, Cut ( A , B ) = ∑ i ∈ A , j ∈ B w i j \operatorname{Cut}(A, B)=\sum_{i \in A, j \in B} w_{\mathrm{ij}} Cut(A,B)=∑i∈A,j∈Bwij表示 A A A与 B B B的权值总和, Assoc ( A , V ) = ∑ i ∈ A , j ∈ V w i j \operatorname{Assoc}(A, V)=\sum_{i \in A, j \in V} w_{\mathrm{ij}} Assoc(A,V)=∑i∈A,j∈Vwij表示结束于 A A A段的所有边的权值之和。为了最小化 NCut ( A , B ) \operatorname{NCut}(A, B) NCut(A,B),Shi等人进行了一系列的数学计算和归约,将动态规划问题转化为以下广义特征值问题:
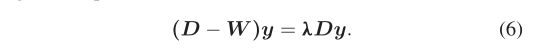
请注意, W \boldsymbol{W} W是一个 n × n n \times n n×n权重矩阵,其元素由图 G G G中节点的相似性 w i j w_{\mathrm{ij}} wij表示。 D D D是一个 n × n n \times n n×n对角矩阵,其元素 D ( i , i ) = d i = ∑ j w i j \boldsymbol{D}(i, i)=d_i=\sum_j w_{\mathrm{ij}} D(i,i)=di=∑jwij表示节点$i#的总成本。 λ \lambda λ是特征值, y y y表示广义特征值问题的特征向量。
(6) 的最小解 y 1 y_1 y1对应于第二小的特征值 [37]。通过对该特征值应用阈值分割,可以将点集分割成两部分。 Reitberger 指出,如果点集中存在多于两棵树,则可以通过迭代应用 Ncut 分割来隔离单个树点,直到每次迭代的 Ncut ( A , B ) \operatorname{Ncut}(A, B) Ncut(A,B)小于适当给定的阈值。

图 8. 本研究中使用的测试站点和数据集。
现有的用于个体树分割的 Ncut 方法有两个缺点。首先,对于多树点集情况,不能保证单个树的完整性。 Ncut 可以将给定的点集以最低的成本分割成两部分;然而,成本是全球性的。如果点集包含两棵以上的树,则全局乐观主义可能会将一棵树上的点强行切割成两部分;因此,破坏了单棵树的完整性。其次,在现有研究中,节点相似度仅考虑了距离因素;因此,增加了重叠树冠的树枝尖端的分割错误。当 Ncut 首次被提出作为图像分割方法时,灰度值和像素位置被考虑用于节点相似性。当 Reitberger 等人将其扩展到 3-D 空间时,考虑了水平距离、垂直距离和到最近的茎干的距离。另一方面,当 Yu 等人使用 Ncut 将灯杆与附近的树木分开时,到最近树干的距离被移除。节点相似度只取距离因子的过程很可能会产生来自同一分支的点,尤其是尖端上的点被分割为不同类的结果。
为了克服上述缺点,我们对基于八叉树节点的 Ncut 分割方法进行了一些修改。对于多树情况,我们仅根据初始分割结果对重叠的树冠进行 Ncut 分割。这种处理方案提供了独特的优势。一方面,可以确保单个树冠的完整性,因为不再存在任何全球乐观情绪。另一方面,所需的计算量可以大大减少。此外,还可以避免为大面积设置非常难以设置的最低成本阈值。对于节点相似度,我们制作八叉树节点图节点,并通过考虑水平距离、垂直距离和节点连通性来修改相似度计算
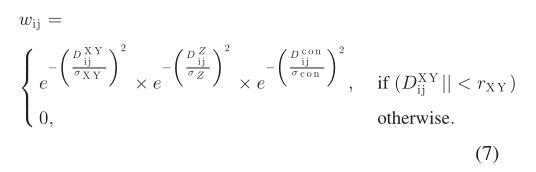
请注意, D i j X Y D_{\mathrm{ij}}^{\mathrm{XY}} DijXY和 D i j Z D_{\mathrm{ij}}^Z DijZ分别表示节点 i i i和 j j j之间的水平距离和垂直距离。 D i j c o n D_{\mathrm{ij}}^{\mathrm{con}} Dijcon是图中节点 i i i 和 j j j之间的最短路径的距离。如果节点 i i i和 j j j相连,则 D i j c o n = 1 m n s ∑ k S k m p D_{\mathrm{ij}}^{\mathrm{con}}=\frac{1}{\mathrm{mns}} \sum_k S_k^{\mathrm{mp}} Dijcon=mns1∑kSkmp,其中 S k m p S_k^{\mathrm{mp}} Skmp表示从 i i i到j的最短路径经过的节点大小,mns表示八叉树节点的粒度,最短路径可以使用Floyd算法计算。如果节点 i i i和 j j j断开连接,则 D i j con D_{\mathrm{ij}}^{\text {con }} Dijcon 设置为 32767。
III. EXPERIMENTS AND ANALYSIS
A. Test Site and Dataset
1)NJU试验场——落叶地面LiDAR:该试验场位于南京大学仙林校区,面积为100m×80m,如图8所示。试验场以银杏树为主,少量灌木像山茶花和桤木。总体冠层重叠度较低。 LiDAR 数据集于 2015 年 1 月 15 日获取,使用 Leica ScanStation 2,共计 12 645 200 个 LiDAR 点,点密度为 2821/m2,见表 1。
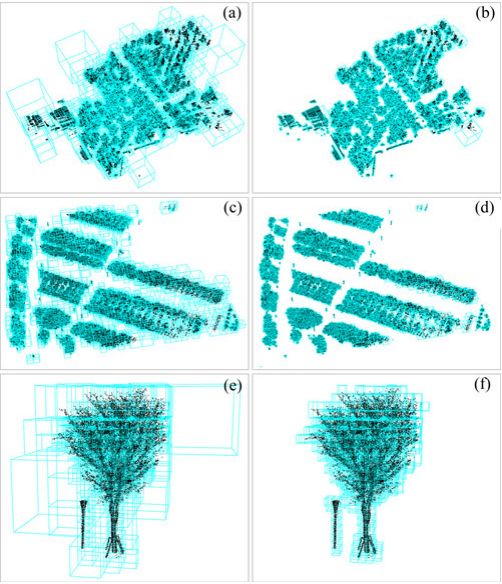
图 9. mns = 0.5 m 时 OT 和 ON 中的叶节点,其中 (a) 和 (b) 显示 NJU 测试站点 LiDAR 的 OT 和 ON 节点,© 和 (d) 显示 NJOC 的 OT 和 ON 节点测试站点 LiDAR,以及 (e) 和 (f) 显示特定树的 OT 和 ON 节点。
2)NJOC试验场——Leaves-On Mobile LiDAR:该试验场位于南京奥林匹克中心东南方,面积为150 m×160 m,见图8。试验场主要种植樟树和梧桐树。 LiDAR数据集采集于2011年6月,共4 937 602个LiDAR点,点密度为222/m2,采用中国科学院自主研发的SSW移动激光建模测绘系统测绘的数据见表一。这个数据集是由从不同车辆路线扫描的几个数据集镶嵌而成的,因此,一些树木具有从不同视点收集的点云。
B. Octree Construction
去除地面点和建筑立面点后,采用新提出的分裂规则(考虑mns、mnp、pds,构建的八叉树简称ON)为各试验点点云构建八叉树结构.同时构建了一个使用传统分裂规则的八叉树结构(只考虑mns和mnp,构造的八叉树简称OT)进行比较。结果如图9所示,从图中可以看出,在点密度较低的区域,如OT结构中的对象边界,存在大量的边界型和稀疏型假脂肪节点。然而,边界型假肥节点在ON结构中很少存在,因为ON会使用额外的停止规则进一步分裂它们;因此,所有节点都可以拟合 LiDAR 点的分布。对于ON中的稀疏型fake-fat节点,虽然只包含少数激光雷达点,但在这些点服从随机分布的假设下,这些节点的位置在一定程度上也可以代表点云的位置。
为了定量估计八叉树节点与点云之间的位置偏差,计算了两个指标:1)每个LiDAR点与包含它的八叉树节点之间的距离,本文称为P-N距离,表示为DP-N[见(8) )], 2) 每个八叉树节点与其所有内部点的平均位置之间的距离,在本文中称为 N-P 距离,表示为 DN−P [见 (9)]。这两个距离是在OT和ON结构中计算出来的,用于比较
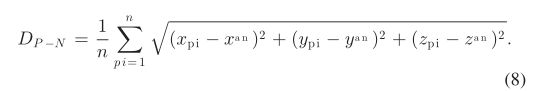
其中,(xpi, ypi, zpi)表示点pi的位置坐标,(xan, yan, zan)表示包含pi的八叉树节点的位置坐标,n为激光雷达点数。
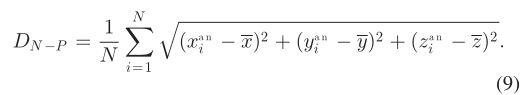
这里,(xani , yani , zani ) 表示八叉树节点 i 的位置坐标,(¯x, ¯y, ¯z) 表示节点 i 内所有 LiDAR 点的平均位置坐标,N 是八叉树节点的数量。
表 II 显示了八叉树节点位置精度的结果。在相同的 mns 下,两个数据集的 ON 结构中的 P-N 距离和 N-P 距离均低于 OT 结构,这表明位置精度更高。此外, mns明显影响定位精度:随着mns增大,节点最小体积增大,节点几何中心与内部激光雷达点平均位置的距离变大,导致P-N和N-P距离均增大。
C. LiDAR Spatial Clustering
许多树在选定的测试地点相互重叠,因此无法仅使用空间聚类来隔离单个树点。因此,空间聚类的目标是将整个点云分割成区域块进行单独处理,这对于处理大面积的海量点云数据非常有用。
表 1 激光雷达数据采集的详细参数

表 2 八叉树节点的位置精度
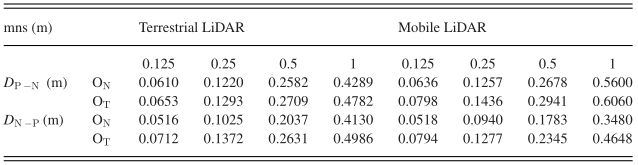

图 10. 基于八叉树节点连通性的空间聚类结果。其中相同颜色的点被标记为同一类,黑色虚线区域的点被选择用于后期分割演示的示意图数据。
尽管使用八叉树节点连通性的空间聚类不需要距离阈值,但 mns 仍然会影响结果。具体来说,如果设置八叉树节点粒度等于mns,则最小间隙小于mns的两个点集将通过节点桥接效应聚为一个类;但是,如果它们的最小间隙大于 2 mns,它们将被标记为不同的类。为保证单个树点的完整性,聚类时八叉树结构的mns应大于遮挡造成的树点内部间隙。考虑到本研究中所选测试地点不同树木之间和单棵树木内部的差距,我们将地面和移动 LiDAR 数据集的 mns 分别设置为 0.5 m 和 1 m。图 10 显示了空间聚类结果。
D. Individual Tree Points Segmentation
图 11 显示了从聚类点集中分割单个树点的一般工作流程。首先,为每个聚类点集建立八叉树结构,然后生成八叉树节点的水平直方图,其中搜索局部最大值作为候选干。接下来,计算每个候选者在四个剖面(水平、垂直、对角线和第二对角线)中的峰度和平均峰度作为形状特征。根据平均峰度和与地面的连通性,去除伪树干。然后根据树干位置进行初始树分割,并根据检测到的树干构建 Voronoi 图。对于图中的每条边,都创建了一个缓冲区,其大小等于双边树干之间距离的三分之一,以生成树核心区域和重叠区域。最后,使用第 II-D 和 II-E 节中描述的方法对重叠区域中的八叉树节点及其内部 LiDAR 点进行分割,并导出单个树点。
在词干检测过程中,使用峰态阈值来约束候选词干的形状,以消除伪词干。峰态阈值包括最大峰态和最小峰态,分别用于控制尖峰和平峰直方图。设置合适的阈值对词干检测结果影响很大。图 12 显示了试验场典型树木和灯杆的 LiDAR 点数、八叉树节点的直方图和各自的峰态。从中可以看出,峰度是由局部极大值与相邻统计单元的频率差决定的,与冠层大小和树高的比例没有直接关系。由于冠层在很多情况下确实有一定的水平覆盖,高频可以在局部最大值附近的相邻统计单元中找到,并且频率会随着它们与局部最大值的距离的增加而缓慢降低,使得直方图看起来像标准正态分布。但对于灯杆而言,由于杆状树桩较高,同时缺乏树冠的过渡效果,直方图多为尖峰态,导致峰度高于树木。为了区分树木与灯杆和其他物体,最小峰度阈值设置为 -1.5,而最大值设置为 1.5。
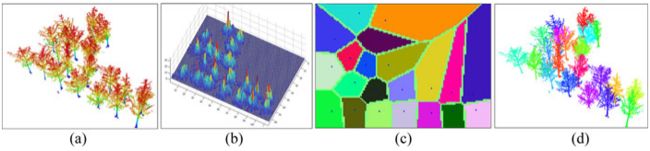
图 11. 从点集分割单个树点的工作流程。 (a) 聚类点集(图 10 中的黑色虚线框),(b) 八叉树节点的水平直方图,(c ) 树位置的 Voronoi 图,以及 (d) 单个树点的分割结果。
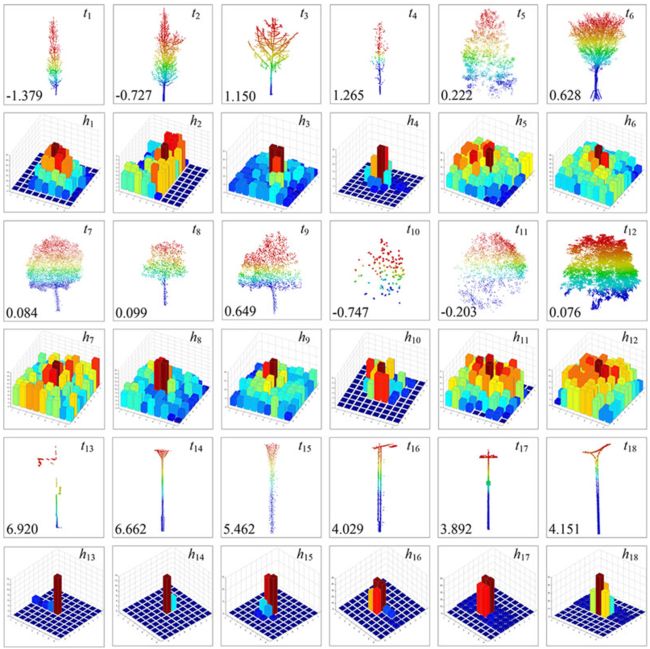
图 12. 典型的树点云、相应的八叉树节点水平直方图和峰度。其中水平直方图来自 0.25 米的八叉树结构,峰态是基于距离局部最大值小于 1 米的直方图像素计算的。树木倾向于拥有峰度相对较低的标准正态分布直方图,而灯杆倾向于拥有峰度相对较高的尖峰直方图。
单个树点的分割结果如图13所示,从中可以看出,在冠层重叠度较低的区域,可以观察到良好的分割结果。在冠层重叠度高、垂直结构简单的地区也能得到较好的实验结果。但对于冠层重叠度高、垂直结构复杂的情况,结果不太理想。造成这种现象的原因是对于复杂的垂直冠层结构,如乔灌草结构的森林或一棵大树的冠层下有几棵树的情况,在茎检测过程中只能提取最高的树干,而林下无法有效识别植物,导致分割错误。
图 14 显示了不同的参数设置策略,特别是局部最大值的 sr 和地面连接性,如何影响分割结果。斑点中同时包含高密度树(小树间隔)和低密度树(大树间隔)。图 14(a) 显示了 sr = 2 m 时没有地面连通性判断的结果,从中我们可以看到低密度区域的树木被正确分离。

图 13. NJU 测试点和 NJOC 测试点的个体树分割结果。对于(c)和(f)所示的冠层重叠度较低的情况,可以观察到良好的分割结果。对于冠层重叠度高但垂直结构简单的情况,也可以得到很好的分割结果,如图(a)和(d)所示。对于冠层重叠度高和垂直结构复杂的情况,结果不太令人满意,如(b)和(e)所示。

图 14. 不同词干检测策略的分割结果。 (a) sr = 2 m,不做地面连通性判断,适用于低密度树木(最后一行)区域; (b) sr = 1 m,不做地面连通性判断,适用于高密度树木(第一行)区域; © 本文采用的策略,sr = 1 m,带有地面连通性判断,适用于高密度和低密度树木。
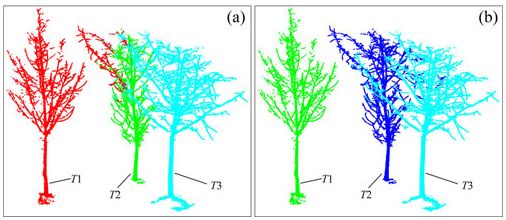
图 15. Ncut 相似度计算中节点连通性对分割结果的影响。 (a) 仅考虑距离因素的分割结果和 (b) 考虑距离因素和节点连通性的分割结果。
表 3. 地面激光雷达和移动激光雷达的分割精度
然而,在高密度区域存在遗漏,因为在 sr 范围内只能检测到一个候选茎。因此,sr 不宜过大。图 14(b)为 sr = 1 m 时未进行地面连通性判断的结果,从图中可以看出,高密度区域的树木被有效分割,而低密度区域的树木被过度分割。图 14© 显示了当 sr = 1 m 时地面连通性判断的结果,它正确地隔离了高密度和低密度区域的树点。因此,在茎检测过程中,我们建议在满足高密度区域的情况下选择较小的搜索半径,并结合地面连通性和峰度阈值判断,以获得更可靠的结果。
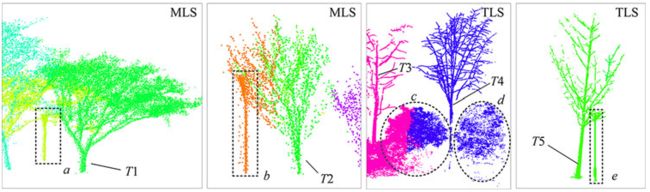
图 16. 典型的分割错误。其中(a)、(b)和(e)表示FP,而(c)和(d)表示FN。 (a) 和 (b) 是现实世界中的灯杆,在分割过程中被视为独特的茎。 (e) 也是一根灯杆,但被标记为附近树 T5 的一部分。 © 和 (d) 是两种独特的灌木,但是,由于它们离附近的高大树木 T3 和 T4 太近,它们应该被标记为候选茎而不是灌木本身,导致灌木 d 被完全归类为T4 和灌木 c 的部分被归类为 T4 的一个组成部分,而其他部分被归类为 T3 的一个组成部分。
图 15 显示了 Ncut 中节点的连通性对分割结果的影响。图 15(a) 使用 Reitberger 的相似度计算,仅考虑距离因素,其中来自 T2 和 T3 的部分分支被错误地分割到 T1,因为它们更接近 T1。图 15(b)显示了修改后的相似度计算,它同时考虑了距离因素和节点的连通性;图 15(a) 中错误分割的分支在连通性约束下被正确分类。
E. Accuracy Analysis
实验中的分割结果分为三类: 1) True positive (TP) 表示个体树被正确分割,提取了超过 70% 的点; 2)假阴性(FN)表示一棵树上超过30%的点被标记为附近的其他物体或树木;见图16中的(c)和(d)和3)假阳性(FP)表示非树对象的点集被分割为树见图16中的(a),(b)和(e) . 根据三种分割结果,可以计算出三类指标来评价分割精度:recall(r)、precision(p)和F-score [2],[38],如下式所示:
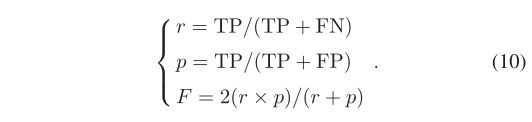
请注意,r 表示分割完整性,p 表示正确性。 F 分数表示整体准确性,它同时考虑了委托和遗漏错误。
表 III 显示了两个测试站点的分割精度。地面 LiDAR 的正确性和完整性分别为 92.4% 和 95.4%,移动 LiDAR 的相应准确度分别为 94.0% 和 93.7%。两个数据集的总体 F 分数均达到 0.94,表明所提出的框架具有良好的性能.
IV . DISCUSSION
拟议的框架包括五个步骤,涉及一些参数和假设。参数设置和特殊测试环境会对分割结果产生多种影响。文中已经描述了一些参数,下面讨论八叉树节点粒度、Voronoi 边缓冲区大小和冠层垂直复杂度。
A. Octree Node Granularity
在面向对象的分割研究中,尺度是影响结果的重要参数,无论是图像分割[39]还是激光雷达分割[23]。在这项研究中,规模由八叉树节点粒度控制。
八叉树在提议的框架中分两步使用。第一步,即Spatial Clustering Using Octree Node Connectivity(见Section II-B),文中已经介绍了八叉树节点粒度的参数设置。在第二步,即 Stem Detection(见第 II-C 节)中,八叉树节点粒度的确定直接影响点云的初始分割和重叠树冠的分割。在这两个分割过程中,八叉树节点用于分析空间形态,而不是激光点,因此它们需要获得更高的位置精度,以贴近原始激光雷达数据。此外,最终分割结果的细节由八叉树节点粒度决定,因为八叉树节点中的激光点不会被进一步划分为更多类别。因此,设置较小的八叉树节点粒度(例如 0.125 或 0.25 m)来检测树干。
B. Buffer Size of Voronoi Edge
Voronoi边的缓冲区大小决定了初始分割过程中重叠区域的产生,直接影响重叠冠层的分割结果。由于Ncut方法通过寻找LiDAR点的最佳分割面来分割重叠冠层,如果最佳表面不在重叠区域,则无论如何都无法实现最佳分割。因此,Voronoi 边的缓冲区大小不能设置得太小。相反,过大的缓冲区大小会显着降低算法的效率。 Ncut算法的时间和空间复杂度都很高。如果八叉树节点的数量为n,则需要创建多个实数n×n矩阵来计算八叉树节点的相似度,计算广义特征值和特征向量的时间复杂度为O(n3)[37]。因此,Voronoi 边的缓冲区大小不应设置得很大。在本研究中,缓冲区大小设置为 Voronoi 边两侧树木之间距离的三分之一。
C. Canopy Vertical Complexity
冠层垂直复杂度是指不同树冠在垂直方向上的相互叠加。如果有一棵大树的树冠盖住了一棵小树的树冠,则通常无法使用所提出的方法检测到小树,从而导致分割结果的准确性较低。因此,所提出的框架不适合从具有复杂垂直结构的森林中分割单个树木。
V. CONCLUSION
本研究提出了一种新的框架,用于从地面 LiDAR 和移动 LiDAR 数据中分割单个树木。实验结果表明,在长叶和落叶条件下,单棵树都被有效且高效地分割,表明可以实现令人满意的性能。整体分割准确度的 F 分数为 0.94。拟议框架的主要贡献总结如下。
1)本研究开发了一个自上而下的层次分割框架。在区域尺度上,大面积的点云通过空间聚类被分组成局部点集。在单个树尺度上,执行初始分割以生成树核心区域和重叠区域。在树冠尺度上,进行了分离重叠树冠的精细分割,以获得完整的个体树点。
2) 本研究提出了一种新的构造八叉树结构的分裂规则。与旧分裂规则构建的八叉树相比,新规则构建的八叉树节点位置精度更高。
3) 提出了一种基于八叉树节点直方图的树干检测方法。通过将峰度阈值和地面连通性作为约束条件,该方法可以区分树干与灯杆、行人和其他物体。
4) 针对重叠冠层分割提出了一种改进的Ncut方法的节点相似度计算,其中除了距离因素外还增加了节点的连通性。与只考虑距离因素的Ncut方法相比,改进相似度的方法减少了局部分割误差,尤其是在分支的末端。