Layer Stacking: A Novel Algorithm for Individual Forest Tree Segmentation from LiDAR Point Clouds
ABSTRACT
随着光探测和测距 (LiDAR) 技术的进步,以足够高的点密度获取数据集以捕获单棵树木的结构信息已变得很普遍。要处理这些数据,需要一种从 LiDAR 点云中分离单个树木的自动方法。传统的树木分割方法试图从树冠高度模型中分离出突出的树冠。我们在这里介绍一种新颖的分割方法,即层堆叠,它以 1 米的高度间隔对整个森林点云进行切片,并在每一层中隔离树木。合并来自所有层的结果会产生具有代表性的树轮廓。与分水岭划分(一种广泛使用的分割算法)相比,层堆叠在不均匀针叶林中正确识别的树木多了15%,在均匀年龄的针叶林中多识别了7%–17%,在混交林中多识别了 26%,在混合木林中多识别了 26%–在纯落叶林中多出 30%(正确检测到 75% 的树木)。总体而言,层堆叠的佣金误差大多与分水岭划分相似或更好。层堆叠在落叶、落叶条件下表现特别好,即使在树冠不太突出的条件下也是如此。我们得出结论,在测试的森林类型中,与现有算法相比,层堆叠代表了分割方面的改进。
Introduction
当前遥感技术的进步正在通过使用高分辨率 3 维空间数据提高森林资源清查的准确性和范围。 用于检索此类数据的最有效工具之一是光探测和测距 (LiDAR),它使用激光测距来创建代表森林冠层结构的 3 维点云。 用于森林资源清查的航空 LiDAR 应用可分为两类。 首先,基于区域的方法检索一般高度指标,例如平均点高度和点高度分布。这些数据用于通过回归和其他建模技术估计森林体积、生物量和茎密度等(Means 等人 2000 年;Naesset 2002 年;Maltamo 等人 2004 年)。 其次,基于个体树木的方法首先从个体树木中检索详细指标(通常直接测量每棵树的树冠属性),然后将它们聚合起来以表征更大区域的森林属性,或者将它们与基于区域的方法结合使用(Lindberg 2010)).
基于区域的方法比单树方法得到更广泛的应用,部分原因是大多数 LiDAR 数据集的点密度被认为过于稀疏,无法从点云中识别单个树冠,这一过程称为分割。然而,航空 LiDAR 数据收集的密度正在迅速提高,收集的数据通常以每平方米十个或更多脉冲 (pls/m2) 的密度飞行,这使得个体树木分割成为基于区域的方法的可行替代方案。这开启了识别和检索大面积所有冠层树木测量值的可能性。单树方法的一些好处包括使清单更直观(即,与传统的基于田间的森林清单非常相似,但规模更大),更容易对树种进行分类(Vastaranta 等人,2009 年),以及更精确的清单,包括列出每棵树的属性,例如高度和树冠宽度。
以前的分割努力显示出希望,但仍然突出了隔离单个树的挑战。例如,在跨分割方法的比较中,Vauhkonen 等人 (2011) 报告了各种森林类型的个体树木检测率(定义为正确检测到的树木的百分比)在 40% 到 80% 之间。在类似的研究中,Kaartinen 等人(2012) 报道了北方针叶树的范围在 40% 到 90% 之间。由于这种挑战和可变性,很少有研究直接比较基于区域和个体树木的方法。 Yu 等人 (2010) 进行了这样的比较,发现这两种方法产生的平均树木直径、高度和体积相当,但得出的结论是,通过改进分割方法,单树方法可能会产生更好的结果。
目前有几种分割方法,其中最常用的是分水岭及其变体。该方法通过创建树冠表面的模型(称为树冠高度模型,CHM)来进行,该模型被反转以显示描绘相邻个体树冠的局部最大值脊(Soille 2009陈等2006;Kwak等人,2007年)。该方法在具有明显波峰和波谷的单一树冠形状的林分中产生有利的结果,例如纯同龄针叶林;当应用于更复杂或互锁的树冠时,如落叶林的树冠时,它的表现不太好(Koch等人,2006)。虽然标准分水岭分割以及其他基于CHM的分割算法无法检测淹没树木(Koch等人,2014年),但分水岭描绘的几种变化显示了通过检查树冠表面下的点云来检测淹没树木的前景。Reitberger等人(2009年)通过使用一种称为RANSAC的回归方法识别树干,进一步分割淹没的树木,然后通过将分水岭分割为体素并聚集相似的体素,将附近的点放置到适当的树木中。Duncanson等人(2014年)通过对每个隔离流域进行进一步的亚植被流域划分,确定了植被下的底层。
虽然分水岭分割是目前最流行的方法,但有时也会应用其他方法。 局部最大值法识别树冠的峰值并通过以各种方式从这些峰值向外扩展来描绘周围的树冠区域,例如山谷跟随或种子区域生长(Wulder 等人 2000 年,Perrson 等人 2002 年,Popescu 等人 2002 年,Popescu 等人 2004 年)。Rahman 和 Gorte(2009 年)引入的高点密度方法创建了一个基于点密度的模型,类似于分水岭划定中使用的 CHM。 Li 等人 (2012) 开发了一种分割算法,该算法从局部最大值点开始,根据距离阈值迭代分配属于该树的点。 聚类算法也经常应用于分割,其中 k 均值或层次聚类是最常见的(Morsdorf 等人 2003 年;Gupta 等人 2010 年;Lee 等人 2010 年)。 两者都显示出隔离单棵树的希望; 然而,k 均值聚类需要先验知识存在的树的数量,而层次聚类需要用户输入或存在的树的相同知识来决定聚类过程的停止点。 当最密集的点簇(假定代表树的中心)出现在相邻树冠互锁的位置时,会出现进一步的限制。
这里,我们提出了一种称为层堆叠的新型分割算法,它试图克服上述算法所面临的几个挑战。层堆叠包括将森林冠层切割成平行于地面的层,在每个层内聚类点,然后堆叠层以评估层之间出现的聚类位置协议。较一致区域的中心用来代表单个树的中心。该算法基于聚类分割(Gupta等人,2010年)、高点密度扫描(Rahman和Gorte,2009年)和局部极大值检测算法(Popescu,2002年)中实施的概念。我们通过将图层叠加应用于航空激光雷达来测试图层叠加检测树木的能力,我们已经实地测绘并测量了代表一系列树种组成和结构的树木数据。我们还使用这些相同的图,针对商业上可用的分水岭算法和公开可用的局部极大值算法测试了层堆叠。
Methods
Study area
为了评估图层叠加的准确性,需要具有各种林分结构和组成的地点,以及精确的实地测量树高和许多单个树木的地图位置。我们选择的地点位于缅因州和新不伦瑞克的混合木阿卡迪亚森林,这些森林支持在结构上与北纬度的北方森林相似的几乎纯针叶林,在结构上与中大西洋地区的温带森林相似的纯落叶林,以及这两种森林的各种混合物。三个站点用于算法验证。第一个是缅因大学基金会的佩诺布斯科特实验森林(PEF,北纬44.879,西经68.653),被美国林务局北方研究站选择用于均匀和非均匀年龄造林处理。第二个是缅因大学合作林业研究小组的奥斯汀池塘(AP,北纬45.199,西经69.708)研究,选择它的同龄造林。第三个是新不伦瑞克大学的努南研究森林(NRF,位于北纬45.988度,西经66.396度),因其混交林而入选。
用于验证的地块先前已在每个站点建立。 PEF 上的地块是 15.9 m 或 20 m 半径的固定区域地块,空间树木测量使用指南针和 Haglöf Vertex III 测压计进行。 AP 的地块为 30m × 25m,空间测量是使用 Haglöf PosTex 定位仪器进行的。 Noonan 的样地面积为 50 m × 50 m,空间测量是使用网格带三角测量法进行的。 通过 GPS 测量地块中心,然后进行后验移动,使树顶在视觉上与 LiDAR 点云对齐。 此步骤是手动完成的,并且在评估本研究中评估的任何分割算法的准确性之前是必要的。 偏移范围从 0.6 m 到 3 3 。 5m ,偏移量是 GPS 精度的函数。 无法在视觉上与 LiDAR 对齐的图被丢弃。 在 PEF 处胸径大于 11.4 cm(DBH;1.37 m)和在 AP 和 NRF 处胸径大于 10 cm 的树木在空间上绘制,并注明高度和物种。 表 1 列出了每个展位的属性和背景。 物种组成被记录为每个树种在绘制树木中的相对频率,并报告为低至 5%。 每公顷树木超过 400 棵的地块被认为是“密集的”,而树木较少的地块被认为是“稀疏的”。 ” 根据这个名称,AP 站点的树木密度很高; 然而,商业化前的间伐导致的均匀树间距,类似于种植园,导致算法性能与其他密集的均匀年龄地块不同。 出于这个原因,这个地块被放在一个单独的类别中。
LiDAR acquisition
收集了三个 LiDAR 数据集。 第一次 LiDAR 采集发生在 2012 年 6 月,NASA Goddard 的 LiDAR、高光谱和热成像仪(Cook 等人,2013 年)在 PEF 上以平均 15 pls / m2,脉冲率为 300 Khz,平均足迹大小 10 厘米,距离天底的最大扫描角为 28.5 度,海拔高度约为地平面 (AGL) 335 米。第二个 LiDAR 数据集是在 2013 年 10 月的 PEF 和 AP 上获得的,在离叶条件下使用 RIEGL LMS-Q680i 平均为 6 pls/m2,脉冲频率为 150Khz,平均占地面积为 0.17 m,最大扫描角度为 28.5 度,海拔高度约为 600 m A G L 。 这 2 个 PEF 数据集通过对齐容易识别的对象在视觉上组合在一起。 这种排列在整个数据集中似乎都有效,并且树木没有被遮蔽或扭曲。 因此,最终的平均点密度在 PEF 上约为 21 pls/m2,在 AP 上约为 6 pls/m2。 第三个 LiDAR 数据集是在 2011 年 10 月下旬在 NRF 的叶子关闭条件下收集的,使用相同的 RIEGL LMS-Q680i 激光扫描仪,脉冲密度为 ∼ 5 pls / m2。 平均飞行高度为 724 米 AGL,最大扫描角为 28. 5 度。 所有 LiDAR 都是在 1550 nm 波长下收集的。 地面点由供应商分类。
Tree detection
在进行分割之前,我们首先必须检测出所讨论的林分中所有树的中心。原始激光雷达数据首先被归一化,以通过从每个点减去从地面点导出的数字地形模型来测量地面以上的绝对高度。然后,使用预先定义的林分地图将各个林分分开。每个林分都被完整地分割,包括其中的地块。
每个选择用于分割的林分首先以1米的间隔水平分层,从地面以上0.5米开始,一直到最高点(图1a)。然后将聚类算法应用于每一层。为了过滤掉潜在的不需要的低植被,最低的3层首先进行基于密度的扫描(DBScanning),如Ester等人(1996)所述。DBScanning根据用户定义的密度和每个聚类的最小点数将点分类为聚类。因此,聚类中的所有点都被归类为不需要的低植被,并被移除。聚类之外的所有点被假定为狭窄树干上的孤立返回,并被保留。
然后在研究区域建立了一个1米分辨率的冠层高度模型。使用 3 m × 3 m 的单元窗口对此进行平滑处理,并使用 3 m 的固定半径窗口检测局部最大值。 假定这些最大值代表树的顶部。 然后对每一层进行 k 均值聚类(图 1b;Hartigan 和 Wong 1978),将局部最大值用作种子点。 从每个种子点开始,k 均值聚类将点放入属于最近种子点的簇中; 然后计算该簇的质心并将其用作新的种子点。 该算法然后再次将所有最接近每个新种子点的点聚类,迭代地重复该过程,直到种子点的位置不再改变或直到达到指定的迭代次数。
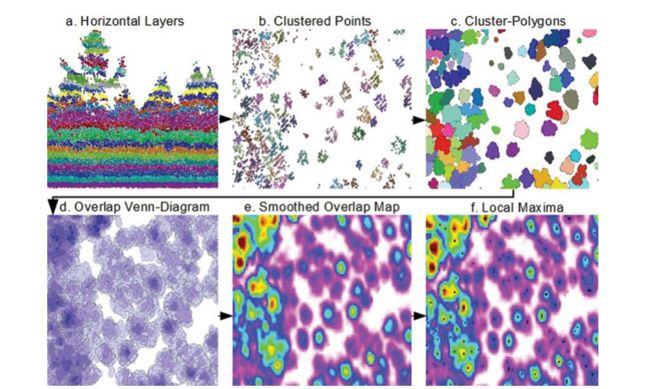
图 1. 层堆叠树检测算法的工作流程。 (a) 森林冠层以1-m 间隔水平分层(侧视图)。 (b) 每一层的点都是聚类的;每个集群都分配了一种随机颜色(10-m 高度的自上而下视图)。 (c ) 半米多边形缓冲区放置在每个集群周围。 (d) 来自所有层的多边形相互堆叠;深蓝色区域代表更多重叠。 (e) 来自不同水平层的多边形之间的重叠区域被栅格化和平滑以产生重叠图。温度升高的区域(黄色和红色)代表更大的重叠。 (f) 从重叠图中检测到局部最大值并显示为黑点;假定这些代表树的中心。
一旦每个层中的点被聚类,一个 0.5m 的多边形缓冲区被放置在每个聚类周围(图 1c)。 此步骤有两个目的:首先,作为另一轮聚类,因为距离主聚类 0.5 m 以外的点(可能被错误地放入该聚类)被有效地彼此分离; 其次,作为连接点和矢量化集群的一种方式。 该缓冲区的大小是在对树冠进行定性视觉评估后通过反复试验确定的,最佳大小可能因脉冲密度和森林类型而略有不同。 当多边形以围绕空心内部形成完整环的方式重叠时,这些“donut holes”就会被填满,因为它们代表激光无法穿透的树冠中心。 然后堆叠每一层的多边形(图 1d),并生成分辨率为0.5 m的重叠多边形数量的栅格化地图。
与维恩图说明 2 个或更多组重合的区域的方式相同,重叠图识别树冠层中的高密度区域,这样多个多边形重叠表明存在单独的树。 在密集的针叶林中,几乎没有穿透到树的中心,重叠图上的额外权重被赋予靠近树冠顶部的簇,因为它们往往代表树尖,因此更接近树的中心 . 前 70 个百分位的集群被赋予双倍权重,前 80 个百分位的集群被赋予三重权重,而前 90 个百分位的集群被赋予四倍权重。 因此,在低激光穿透的情况下,层堆叠仍然可以通过给予高点更多的权重来发挥作用,本质上是将重叠图和树冠高度模型结合起来。 重叠图在概念上类似于 Rahman 和 Gorte (2009) 开发的高点密度图,除了聚类的性质以及应用于上层聚类的权重导致空心中心 填充难以穿透的针叶树,从而确保这些树的中心确实具有最多的重叠(图 2)。
然后用 1.5 m 的窗口对重叠图进行平滑处理。 需要此步骤来移除树中可能代表分支的不同重叠区域,就像在分水岭划定之前平滑 CHM 一样(Koch 等人,2006 年)。 然后用另一个 1.5 米的固定半径窗口检测局部最大值(图 1f)。 然后假设这些局部最大值代表树木的中心,即在整个树冠中具有最多重叠簇的点。 然后必须过滤检测到的局部最大值以排除错误。那些位于几乎没有重叠簇的区域上的那些被移除,因为它们通常代表尺寸小得令人不快的树木。 对于本研究,移除了重叠少于 5 个的树木,因为它们往往代表高度小于 5 m 的树木,并且可能低于现场测量的最小直径阈值。

图 2. 高点密度图显示在左侧,而稀疏针叶林的重叠图显示在右侧。逐渐变暖的区域(黄色和红色)代表更高的值。几棵树被圈了起来。注意在高点密度图中,树形成环,最高点密度的区域在树的外侧。在重叠图上,“环形洞”环被填充,最高的聚类多边形被赋予更大的权重,从而产生最密集的点,通常位于树的中心。
缓冲区被放置在每个局部最大值周围,重叠的缓冲区被溶解,并且它们的质心被作为该树的新的中心点。这一步有助于防止树被错误地分成多个部分,合并彼此过于接近的局部最大值,从而成为单独的树。在对几个半径选项进行定性评估后,我们发现0.6m的缓冲区适用于这些数据和森林类型。
在具有小树的非常密集的林分中,降低该长度阈值可能是有益的。剩余的局部最大值被假定为树的中心,然后用于分割单个树的形状。
Tree segmentation
使用每一层的聚类点来组装树冠。从CHM得到的局部最大值不能检测过度树冠或中等树冠等级的树。因此,需要第二组聚类,这一次使用从重叠图得到的局部最大值。因为每棵树都由许多层组成,所以聚类算法在这些层中的某一层产生错误结果的可能性很高。因此,每层的聚类运行3次,具有3组不同的种子点。
重叠图再次被平滑,这一次使用3米窗口、1.5米窗口和0.75米窗口。使用相同大小的固定半径窗口检测局部最大值。然后,这些被用作3次单独的k-means聚类运行的一系列种子点。如前所述,在每个簇周围放置0.5多边形缓冲液。从3次聚类运行的每一次运行中产生的每一层中的多边形被组合,并且重复的多边形(其中聚类在运行之间没有改变)被移除。

图 3. 层堆叠树分割算法的部分,它遵循图 中所示的树检测步骤,如图所示。 (a) 重叠图中的局部最大值(图 f)用于描绘属于树的聚类多边形。 (b) 每棵树冠形的三维重建。 (c ) 错误过滤消除了错误的簇。请注意,错误过滤无意中删除了一些正确的图层,导致树冠的一小部分被忽略。
遍历每一层,所有与在树检测部分中开发的缓冲局部最大值相交的聚类多边形被隔离为属于该局部最大值的树(图3a)。这导致了多边形的集合,每一个多边形都代表了树的树冠在各自层的形状。
我们的算法包括 3 个检测后错误过滤步骤,以删除未正确表示其各自树形状的聚类多边形。 首先,消除与 2 棵树的核心相交的聚类多边形。 希望这一步骤能够消除覆盖树木上方的树冠层,代价是略微低估了优势树树冠的大小。 其次,集群多边形区域大到被视为异常值(与该集群树中的其他层相比大于 2 个标准差)被忽略,因为这些区域被假定为表示不止一棵树的错误形状。 第三,删除了质心远离局部最大值的聚类多边形,假设正确的多边形应该以树的分数为中心。 再次,使用 2 个标准差阈值来删除质心较远的多边形(图 3c)。
与每棵树相关的其余聚类多边形可以在 3 维方向上挤压回其原始层,以近似每棵树的树冠形状(图 3b)。由缓冲的局部最大值表示的树的核心也被挤压到最高树层的高度,以确保始终捕获代表树干的点,而不是在过滤过程中无意中删除。然后将位于这些树冠重建中的所有点(图 3b)从点云中裁剪出来并分配一个唯一的树标识。与将给定区域内的每个点分配给一棵树的分水岭划分不同,层堆叠留下许多未分类的点,包括地面点、低植被、树苗,有时还有遗漏的树冠。
TIFFS watershed delineation
我们针对 LiDAR 数据过滤和森林研究工具箱 (TIFFS; Chen 2007) 中实施的流行分水岭树分割算法测试了层堆叠的功效。来自每个地块的原始 LiDAR 数据被输入到 TIFFS 中,每个描绘的树冠的形状被用来从点云中剪下树冠的形状。在 TIFFS 中使用默认设置,除了在对几个半径进行定性分析后使用 0.5 米固定半径窗口来平滑表面模型。
FUSION local maxima delineation
层堆叠的功效还针对美国林务局太平洋西北研究站的 FUSION v3.50 (McGaughey 2015) 实施的可变半径局部最大值描绘进行了测试。 FUSION 中实现的算法类似于 Popescu 等人 (2002) 开发的算法。冠层高度模型以 0.25 米的分辨率为密集的林分(PEF23B、PEF-29B、NRF 和 PEF-M2)开发,这是给定 LiDAR 密度的可能的最高分辨率,并导致检测到更小的树。在其他地块上使用 0.5 m 的分辨率,因为这似乎会导致更少的佣金错误。然后将 CanopyMaxima 工具与默认的可变半径方程一起使用,以隔离局部最大值及其周围的最小值并估计树冠宽度。然后将每棵树的估计树冠宽度大小的缓冲区放置在局部最大值周围,并将这些缓冲区内的 LiDAR 点作为单独的树剪掉。
Verification
通过将来自所有 3 种分割算法的分割点云与来自现场测量地块的单独映射树的位置进行比较来进行验证。 代表每个算法描绘的树木的点按树编号分配随机颜色值。 检测率是逐棵人工评估的,现场测量的树木在 3 维空间中绘制为垂直柱,拉伸到树木的现场测量高度,激光雷达点云覆盖。记录了每棵树的检测或遗漏 ,并对每个地块的佣金误差进行了总体统计。如果一个林分中出现多个地块,则通过对每个地块中所有检测到的和未检测到的树木以及佣金误差求和来生成林分级指标。
Conclusions
我们在我们认为非常具有挑战性的森林条件下开发并测试了层堆叠算法:具有垂直复杂树冠结构的混合林分,包括许多被淹没的树木。尽管讨论了需要改进的地方,但我们认为,当应用于这些森林类型时,图层叠加为分水岭和局部极大值描绘提供了合理的替代方案。检测率和树冠形状均有所改善。图层叠加似乎特别适合落叶数据集。我们相信图层叠加有助于在使用航空激光雷达数据时基于单棵树的方法的快速发展,所有这些都有望提高森林调查的准确性和效率。