ElasticSearch快速入门笔记,ElasticSearch基本操作以及爬虫(Java-ES仿京东实战)(狂神说)
文章目录
- ElasticSearch(库、表、记录)笔记
- ElasticSearch概述
- ELasticSearch VS Solr总结
- ElasticSearch安装
-
-
- ELK的下载地址:
-
- 核心概念
- IK分词器插件
- RESTful风格说明
- 关于索引的基本操作
- 关于文档的基本操作(重点)
-
- 复杂操作搜索 query(排序,分页,高亮,模糊查询,精准查询)
-
- match(模糊查询)
- _source(具体查询)
- _sort(排序)
- from..size(分页查询)
- bool(多条件查询)
- 高亮查询(highlight)
- 集成SpringBoot
- 实战
-
- 1、项目的整体架构
- 2、pom依赖
- 3、application.properties配置
- 4、静态资源
- 5、静态资源添加到项目当中
- 6、ES客户端配置类
- 爬虫(Java-ES仿京东实战)
-
- config包
-
- ElasticSearchClientConfig.java
- utils包
-
- HtmlParseUtil.java
- pojo包
-
- Content.java
- controller包
-
- IndexController.java
- ContentController.java
- service包
-
- ContentService.java
- 前后端分离
- 搜索高亮
-
- 构建高亮
- 解析高亮
ElasticSearch(库、表、记录)笔记
版本:ElasticSearch7.6.1
6.x和7.x的区别很大,6.x的API(原生API、RestFul高级!)
我们要讲解什么?
SQL:like%狂神说%,如果是大数据就非常慢!索引!
ElasticSearch:搜索!(百度、github、淘宝电商!)
1、聊一个人
2、货比三家
3、安装
4、生态圈
5、分词器ik
6、RestFul操作ES
7、CRUD
8、SpringBoot集成ElasticSearch(从原理分析!)
9、爬虫爬取数据!京东
10、实战,模拟全文检索!
以后你只要,需要用到搜索,就可以使用ES!
主题
Lucene是一套信息检索工具包!jar包!不包含搜索引擎系统!
包含:索引结构!读写索引的工具!排序,搜索规则。。。工具类!
Lucene和ElasticSearch关系:
ElasticSearch是基于Lucene做一些封装和增强(上手十分简单!)
Lucene简介

ElasticSearch概述
ElasticSearch,简称es,es是一个开源的高拓展的分布式全文搜索引擎它可以近乎实时的存储、检索数据;本身拓展性很好,可以拓展到上百台服务器,处理PB级别的数据。es也是用Java开发并使用Lucene作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ELK技术(elasticsearch+logstash+kibana)
ELasticSearch VS Solr总结
1、es基本是开箱即用(解压就可以用!),非常简单。Solr安装略微复杂一点!
2、Solr利用Zookeeper进行分布式管理,而ElasticSearch自身带有分布式协调管理功能。
3、Solr支持更多格式的数据,比如JSON、XML、CSV,而ElasticSearch仅支持json文件格式。
4、Solr官方提供的功能更多,而ES本身更注重核心功能,高级功能多有第三方插件提供,例如图形化界面需要Kibana友好支持
5、Solr查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用。
- ES建立索引快(即查询慢),即实时性查询快,用于Facebook新浪等搜索。
- SOlr是传统搜索应用的有力解决方案,但ES更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大、更成熟的用户、开发和贡献者社区,而ES相对开发维护者较少,更新太快,学习使用成本较高。
ElasticSearch安装
ELK的下载地址:
JDK1.8,最低要求!ElasticSearch客户端工具,界面工具!
Java开发,ElasticSearch的版本和我们之后对应的Java的核心jar包!JDK环境正常!
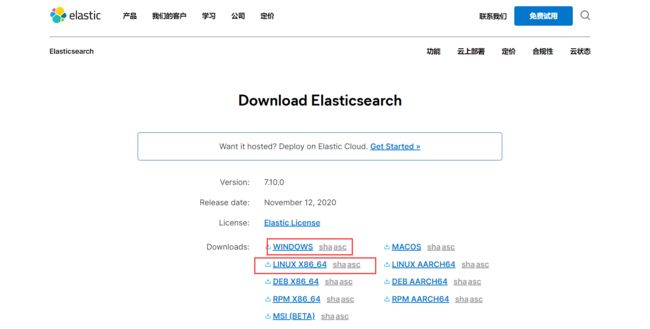
官网下载:https://www.elastic.co/cn/elasticsearch/ 建议复制链接到迅雷下载
镜像下载:
ElasticSearch: https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
logstash: https://mirrors.huaweicloud.com/logstash/?C=N&O=D
可视化界面elasticsearch-head.https://github.com/mobz/elasticsearch-head
kibana: https://mirrors.huaweicloud.com/kibana/?C=N&O=D
ik分词器 https://github.com/medcl/elasticsearch-analysis-ik
Windows使用:
ELK解压即用(Web项目!前端环境!)
Windows安装
1、解压就可以使用了
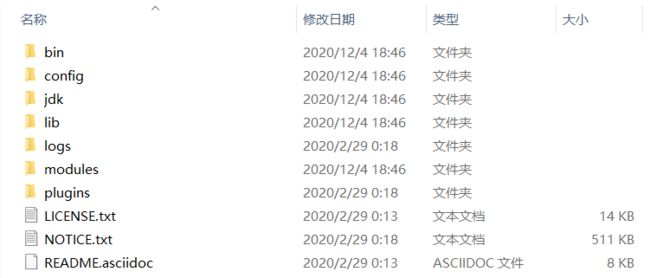
2、目录
bin 启动文件
config 配置文件
log4j2.properties 日志配置文件
jvm.options java虚拟机相关的配置
elasticsearch.yml elasticsearch的配置文件!默认 9200 端口! 跨域!
lib 相关jar包
logs 日志
modules 功能模块
plugins 插件! ik分词器
3、启动elasticsearch.bat,访问9200
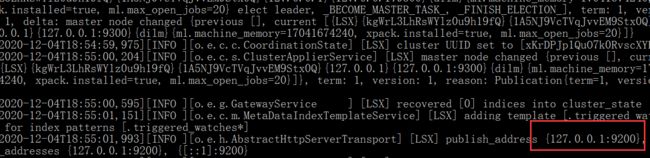
4、访问http://127.0.0.1:9200/测试
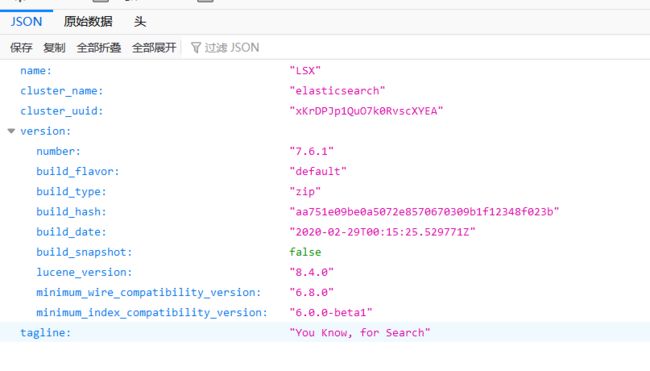
安装可视化插件elasticsearch -head的插件
1、下载地址https://github.com/mobz/elasticsearch-head
2、启动
cnpm install
npm run start
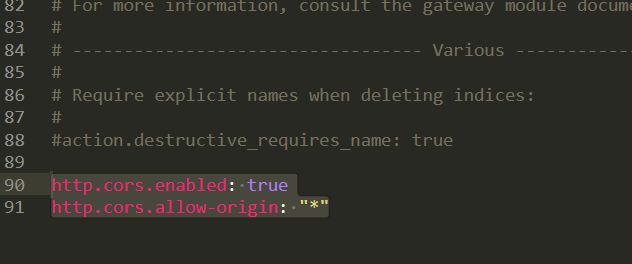
3、连接测试发现,存在跨域问题:配置es.yml文件
http.cors.enabled: true
http.cors.allow-origin: "*"
4、重启es服务器,然后再次连接
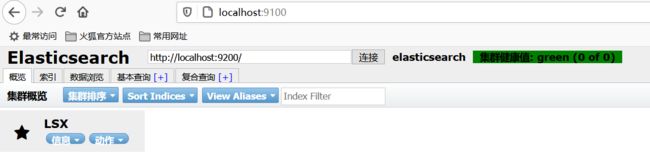
把索引当做一个数据库!(可以建立索引(库),文档(库中的数据!))
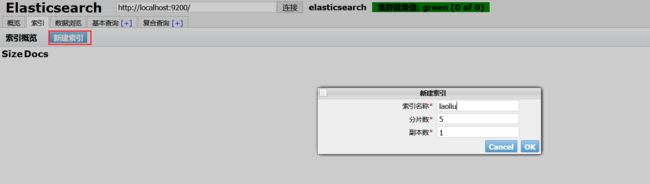
这个head我们就把它当成数据展示工具,我们后面所有的查询,Kibana
了解 ELK
ELK是ElasticSearch、Logstash、Kibana三大开源框架首字母大写的简称。市面上也被称为ElasticStack。其中Elasticsearch是一个基于Lucene、分布式、通过RESTful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。Logstash是ELK的中央数据流引擎,用于从不同目标(文件、数据存储、MQ)手机的不同格式数据,经过过滤后支持输出不同目的地(文件、MQ、redis、Elasticsearch、kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
收集清洗数据–》搜索、存储–》Kibana
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
安装Kibana
Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示ElasticSearch查询动态。设置设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动ElasticSearch索引监测。
官网:https://www.elastic.co/cn/kibana/
Kibana要和ES版本一致
下载完毕后,解压也需要一些时间!是一个标准的工程!
好处:ELK基本上都是拆箱即用!
启动测试:
1、解压后的目录
2、启动
3、访问测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-suT90iIT-1650277602167)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607235646612.png)]
4、开发工具!(Postman、curl、head、谷歌浏览器插件!)
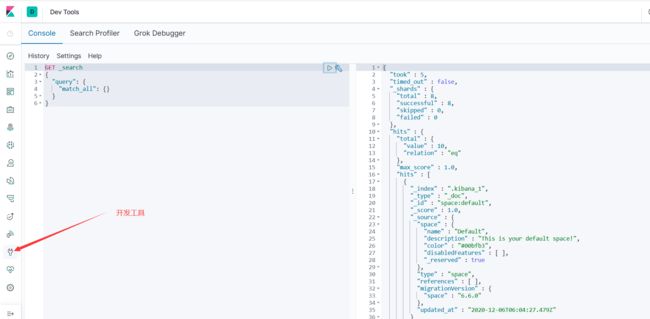
所有的操作都在这进行编写!
5、汉化!(修改yml配置即可,重启)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CP3qMht2-1650277602168)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607236260900.png)]
核心概念
1、索引
2、字段类型(mapping)
3、文档( documents)
4、分片(倒排索引)
概述
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务已经安装启动,那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?
集群,节点,索引,类型,文档,分片,映射是什么?
elasticsearch是面向文档,关系行数据库和elasticsearch客观的对比!一切都是json!
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indeces) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计:
Elasticsearch在后台把每个索引划分成多个片,每份分片可以再集群中的不同服务器间迁移
一个人就是一个集群!默认的集群名称是elasticsearch
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5NjmCl2F-1650277602168)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607237343126.png)]
逻辑设计:
一个文档类型中,包含多个文档,比如说文档1,文档2。当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引->类型->文档ID,通过这个组合我们就能索引到某个具体的文档。注意:ID不必是整数没实际上是个字符串。
文档
就是一条条数据
之前说elasticsearch是面向文档,那么意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要的属性:
- 自我包含,一篇文档同时包含字段和相应的值,也就是同时包含key:value!
- 可以使层次型的,一个文档中包含子文档,复杂的逻辑实体就是这么来的!{ 就是一个json对象!fastjson进行自动转换 }
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为elasticsearch会保存字段和类型之间的映射以及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么elasticsearch中;类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如映射为字符串类型。我们说文档是无模式的,他们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,呢么elasticsearch会认为它是整型。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后在使用。
索引(就是数据库!)
索引时映射类型的容器,elasticsearch中的索引时一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后他们被存储在各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7PUmHh5k-1650277602169)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607238209022.png)]
一个集群至少有一个节点,而一个节点就是一个elasticsearch进程,节点可以有多个索引默认的,如果创建索引,那么索引将会有5个分片(primary shard,又称为主分片)构成的,每个主分片会有一个副本(replica shard,又称为复制分片)
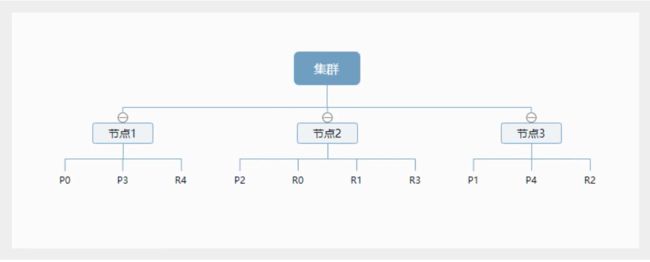
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失,实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含以下内容:
Study every day,good good up to forever # 文档1包含的内容
To forever,study every day,good good up # 文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vSKBLwId-1650277602170)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607238835288.png)]

两个文档都匹配,但是第一个文档比第二个文档匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样一个结构:
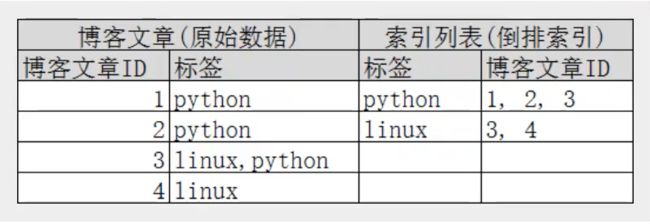
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比:
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中, 索引被分为多个分片,每份分片是一个Lucene索引。所以一个elasticsearch索引是由多个Lucene索引组成的,别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无所指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在Kibana中的Dev Tools下的Console里完成的。基础操作!
IK分词器插件
什么事IK分词器?
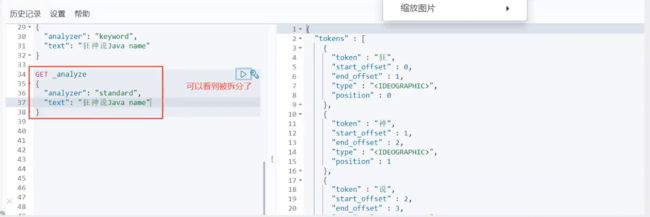
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被分为“我”,“爱”,“狂”,“神”,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分!
安装
1、https://github.com/medcl/elasticsearch-analysis-ik
2、下载完毕之后放入到elasticsearch插件中即可
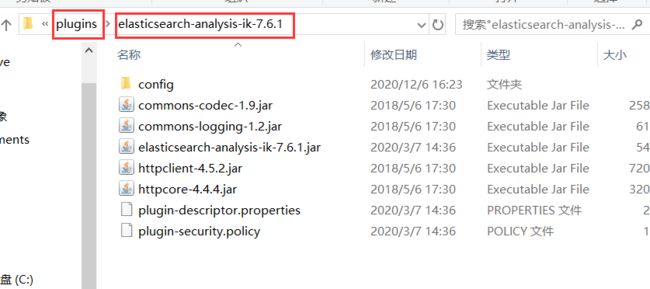
3、重启观察es,可以看到加载了ik分词器插件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y5tzEiDK-1650277602171)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607243130806.png)]
4、可以查看加载的插件

5、启动Kibana测试
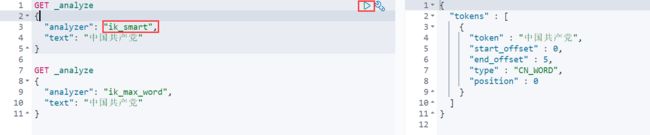
ik_smart为最少切分-----效果
ik_max_word为最细粒度划分-----效果—————–穷尽词库的可能!字典中查
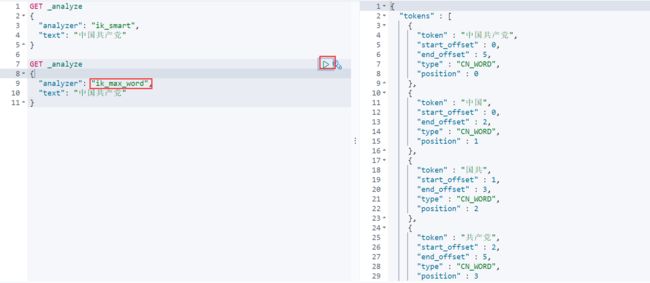
输入超级喜欢狂神说Java
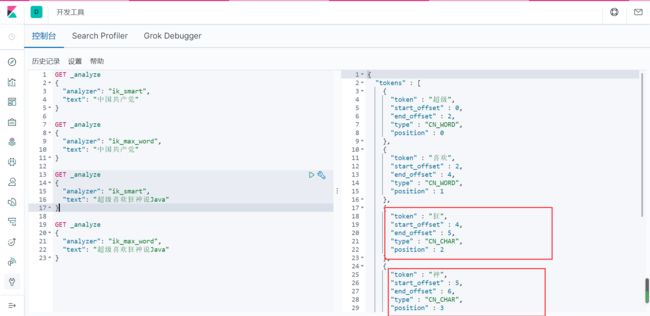
问题:狂神说拆开了
这种自己需要的词,需要加到我们自己的分词器的字典当中!
ik分词器增加自己的配置!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NZJNBoYv-1650277602172)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607244719161.png)]
重启,再次测试一下狂神说!dic文件需要保存为UTF-8格式,否则不生效!
![]()
以后的话,只需要自己配置分词就在自己定义的dic文件中进行配置即可!
RESTful风格说明
一种软件架构风格,而不是标准。更易于实现缓存等机制
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
关于索引的基本操作
基础测试
1、创建一个索引
PUT /索引名/(类型名)/文档id
{请求体}
# 加数据
PUT /test1/type1/1
{
"name":"kuangshen",
"age":3
}
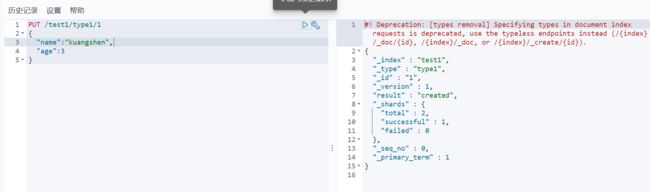
完成了自动增加了索引!数据也成功添加了。
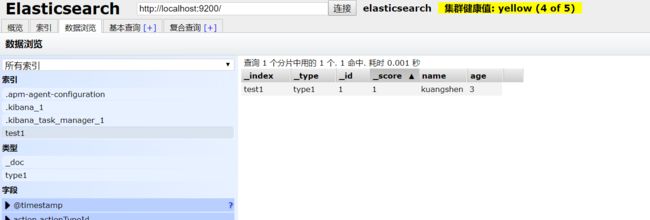
那么name这个字段用不用指定类型呢

指定字段的类型properties 就比如sql创表
获得这个规则!可以通过GET请求获得具体的信息
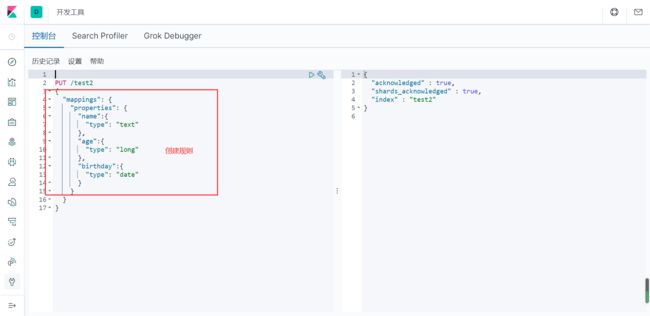
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
获得这个规则!通过GET请求获得具体的信息!
GET test2
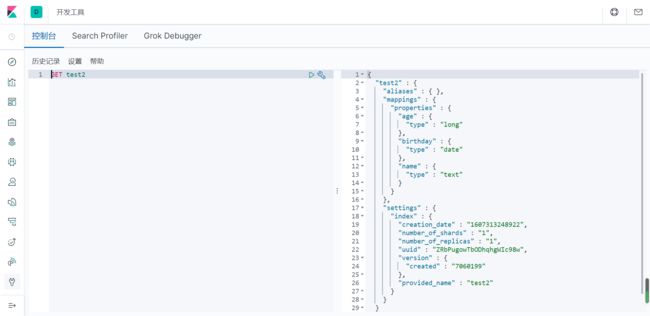
查看默认的信息
如果自己的文档字段没有指定,那么es就会给我默认配置字段类型!
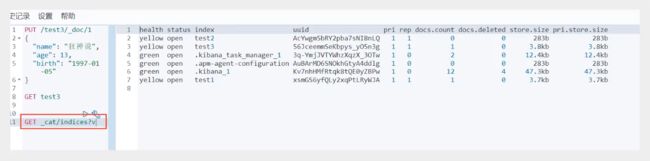
扩展:通过命令elasticsearch索引情况!通过get _cat/ 可以获得es当前的很多信息
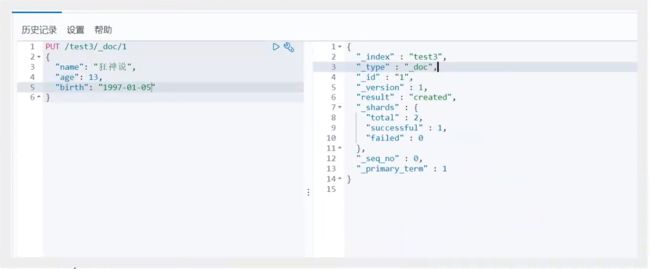
修改 提交还是使用PUT即可!然后覆盖!最新办法!
曾经的办法!
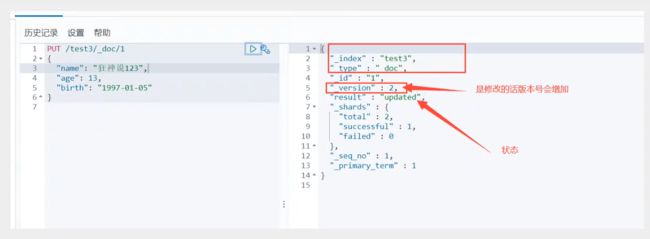
现在的方法!
修改具体的
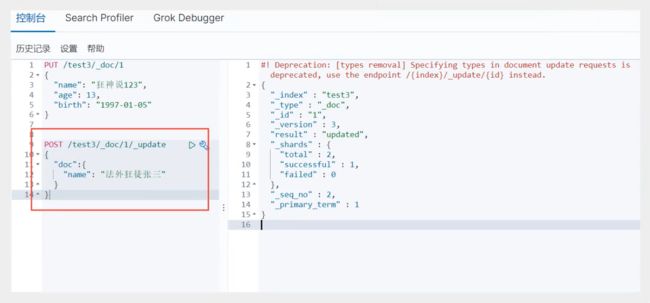
删除索引库!
DELETE test1
通过DELETE命令实现删除、根据你的请求来判断删除索引还是具体的文档记录
使用RESTful风格是我们ES推荐大家使用的
关于文档的基本操作(重点)
基本操作
1、添加数据
PUT /kaungshen/user/3
{
"name": "李四",
"age": 3,
"desc": "无法形容",
"tags":["靓女","旅游","唱歌"]
}
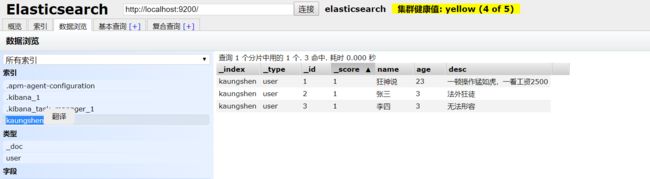
2、获取数据
GET /kuangshen/user/3
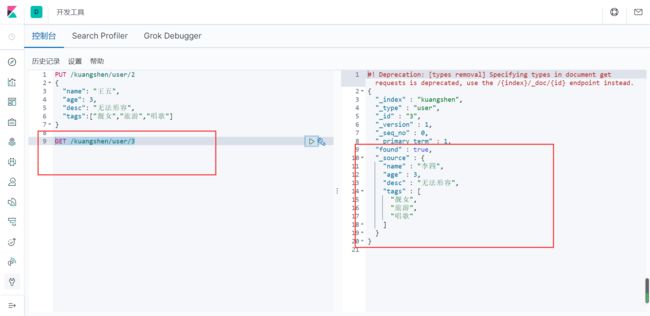
3、更新数据PUT (PUT少了字段会置空)
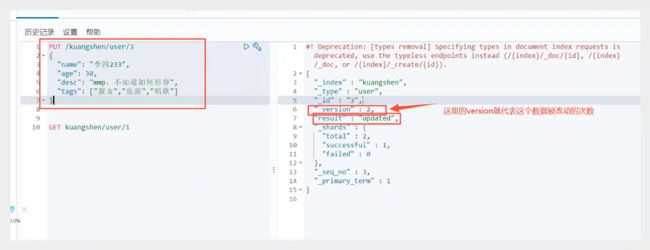
4、更新数据POST _update,推荐使用
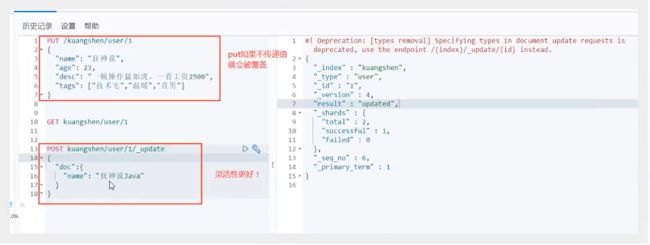
简单的搜索!
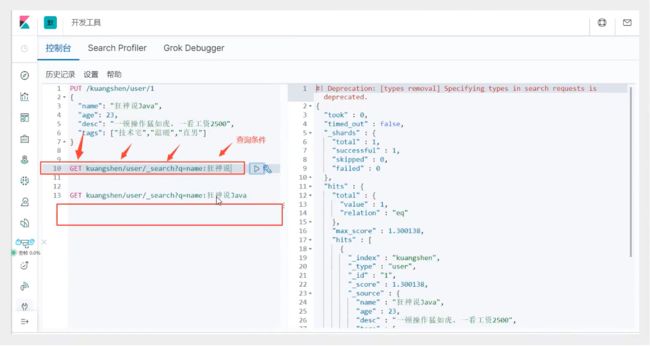
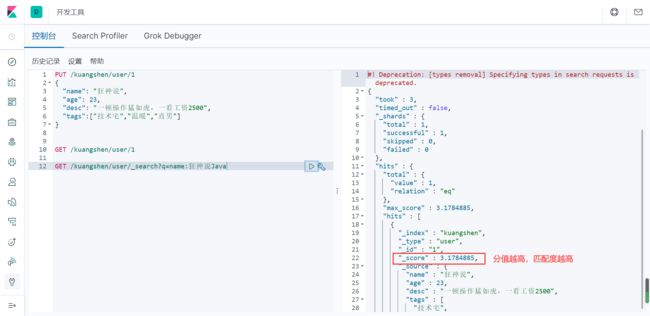
GET /kuangshen/user/1
简单的条件查询,可以根据默认的映射规则,产生基本的查询!
复杂操作搜索 query(排序,分页,高亮,模糊查询,精准查询)
复杂操作搜索 select(排序,分页,高亮,模糊查询,精准查询)
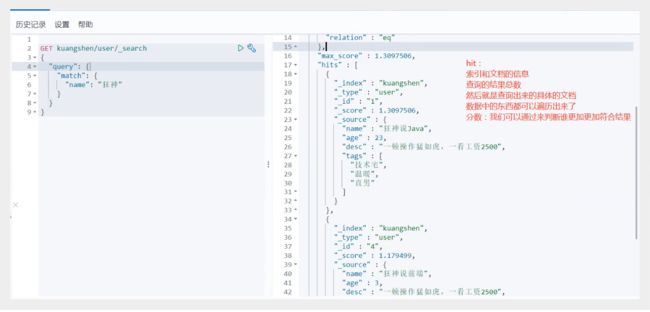
match(模糊查询)
GET /kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神" //查询的参数体使用Json构建
}
}
}
输出具体字段!
_source(具体查询)
具体查询(select name,age)
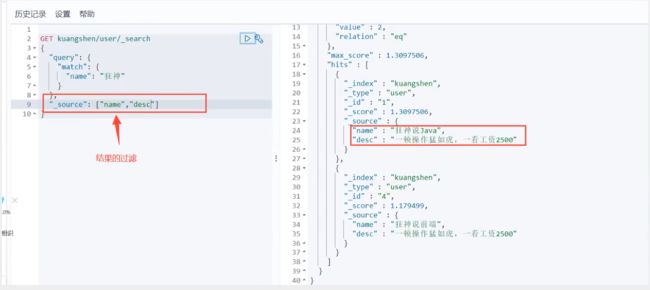
之后使用Java操作es,所有的方法和对象就是这里的key!
_sort(排序)
排序!
通过[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-O7y3gusY-1650277602178)(C:\Users\acer\AppData\Roaming\Typora\typora-user-images\1607332029858.png)]
from…size(分页查询)
分页查询 (limit current,pagesize)
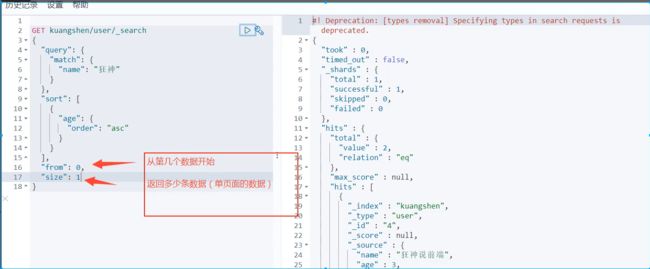
数据下标还是从0开始的,和所有的数据结构是一样的!
/search/{current}/{pagesize}
bool(多条件查询)
布尔值查询
bool+must(and),所有的条件都要符合where id = 1 and xxx
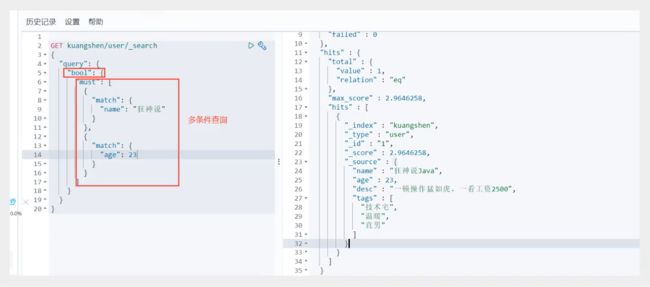
bool+should(or),所有的条件都要符合where id = 1 or xxx
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eom53IuQ-1650277602178)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607333226367.png)]
bool+must_not(not)
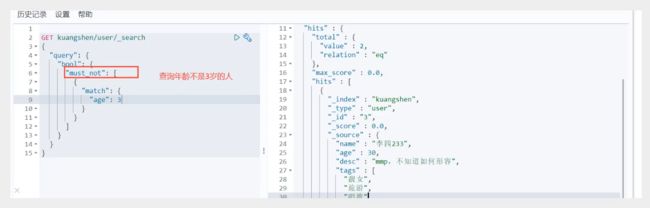
过滤器filter
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ecq34wkK-1650277602179)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607333435721.png)]
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
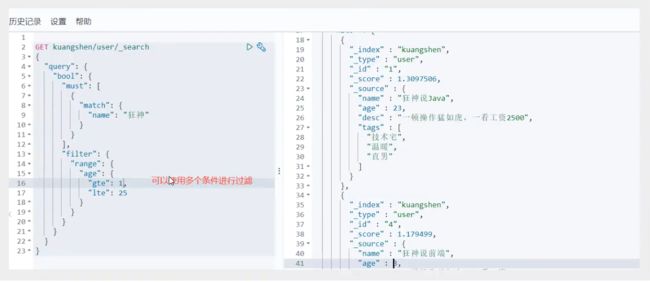
匹配多个条件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0v9I7k7s-1650277602179)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607333722201.png)]
精确查询!
term查询是直接通过倒排索引指定的词条进行精确查找!
关于分词:
-
term,直接查询精确的
-
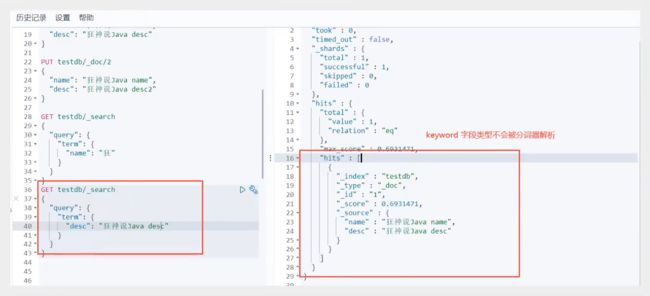
match:会使用分词器解析!(先分析文档,然后再通过分析的文档进行查询!)
两个类型 text keyword
- text会被分词器分析
- keyword不会被分词器分析

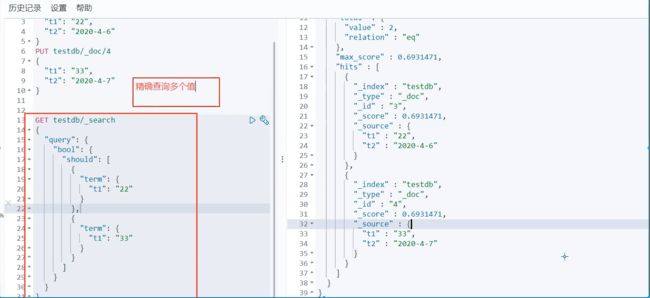
多个值匹配的精确查询
高亮查询(highlight)
高亮查询
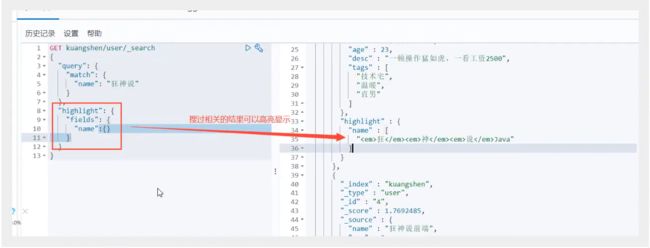
自定义高亮条件
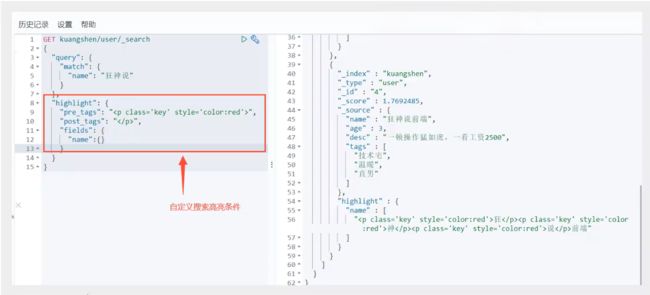
Mysql也能做,MySQL效率比较低
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 支持高亮查询
- 倒排索引
集成SpringBoot
找官方文档! https://www.elastic.co/guide/en/elasticsearch/client

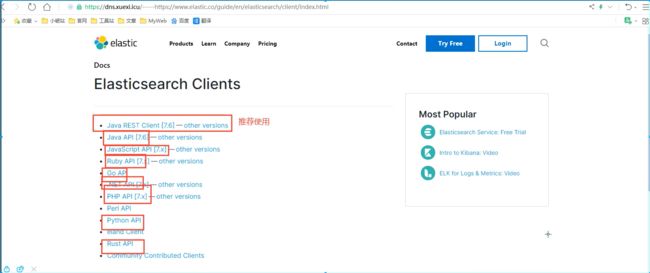
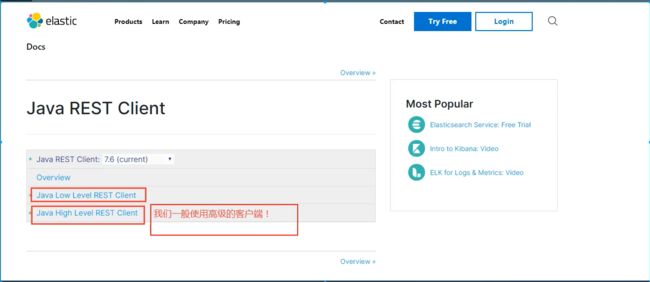
找到原生的依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.1version>
dependency>
配置对应的版本transport
<!--这边配置下自己对应的版本-->
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.6.2</elasticsearch.version>
</properties>
2、找对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9sLUfyCh-1650277602185)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607399409976.png)]
3、分析这个类中的方法即可!
配置基本的项目
**注意:**一定要保证我们导入的依赖transport版本和我们的es的版本一致
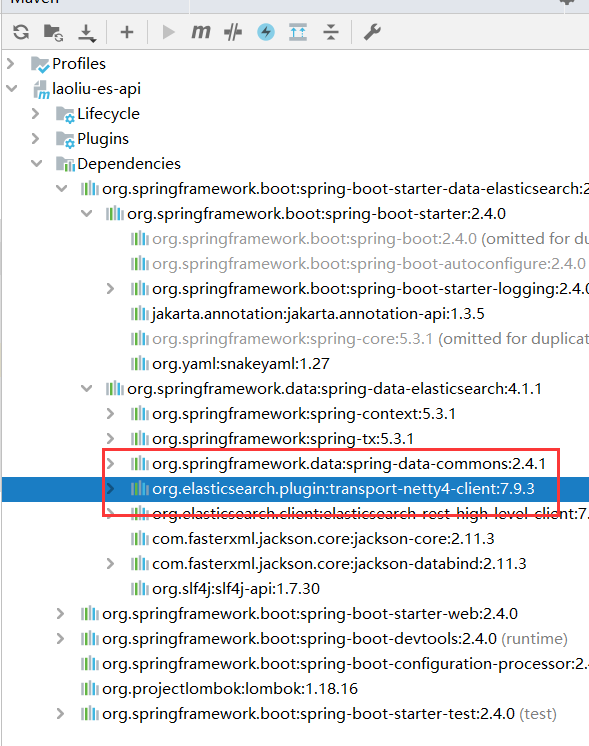
注入RestHighLevelClient客户端
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
核心类ElasticsearchRestClientAutoConfiguration
/*
* Copyright 2012-2020 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.boot.autoconfigure.elasticsearch;
import java.net.URI;
import java.net.URISyntaxException;
import java.time.Duration;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.nio.client.HttpAsyncClientBuilder;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.boot.context.properties.PropertyMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
/**
* {@link EnableAutoConfiguration Auto-configuration} for Elasticsearch REST clients.
*
* @author Brian Clozel
* @author Stephane Nicoll
* @since 2.1.0
*/
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RestHighLevelClient.class)
@ConditionalOnMissingBean(RestClient.class)
@EnableConfigurationProperties(ElasticsearchRestClientProperties.class)
public class ElasticsearchRestClientAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(RestClientBuilder.class)
static class RestClientBuilderConfiguration {
//RestClientBuilderCustomizer
@Bean
RestClientBuilderCustomizer defaultRestClientBuilderCustomizer(ElasticsearchRestClientProperties properties) {
return new DefaultRestClientBuilderCustomizer(properties);
}
//RestClientBuilder
@Bean
RestClientBuilder elasticsearchRestClientBuilder(ElasticsearchRestClientProperties properties,
ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
HttpHost[] hosts = properties.getUris().stream().map(this::createHttpHost).toArray(HttpHost[]::new);
RestClientBuilder builder = RestClient.builder(hosts);
builder.setHttpClientConfigCallback((httpClientBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(httpClientBuilder));
return httpClientBuilder;
});
builder.setRequestConfigCallback((requestConfigBuilder) -> {
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(requestConfigBuilder));
return requestConfigBuilder;
});
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder));
return builder;
}
private HttpHost createHttpHost(String uri) {
try {
return createHttpHost(URI.create(uri));
}
catch (IllegalArgumentException ex) {
return HttpHost.create(uri);
}
}
private HttpHost createHttpHost(URI uri) {
if (!StringUtils.hasLength(uri.getUserInfo())) {
return HttpHost.create(uri.toString());
}
try {
return HttpHost.create(new URI(uri.getScheme(), null, uri.getHost(), uri.getPort(), uri.getPath(),
uri.getQuery(), uri.getFragment()).toString());
}
catch (URISyntaxException ex) {
throw new IllegalStateException(ex);
}
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnMissingBean(RestHighLevelClient.class)
static class RestHighLevelClientConfiguration {
//RestHighLevelClient 高级客户端,后面项目会用到的客户端
@Bean
RestHighLevelClient elasticsearchRestHighLevelClient(RestClientBuilder restClientBuilder) {
return new RestHighLevelClient(restClientBuilder);
}
}
static class DefaultRestClientBuilderCustomizer implements RestClientBuilderCustomizer {
private static final PropertyMapper map = PropertyMapper.get();
private final ElasticsearchRestClientProperties properties;
DefaultRestClientBuilderCustomizer(ElasticsearchRestClientProperties properties) {
this.properties = properties;
}
@Override
public void customize(RestClientBuilder builder) {
}
@Override
public void customize(HttpAsyncClientBuilder builder) {
builder.setDefaultCredentialsProvider(new PropertiesCredentialsProvider(this.properties));
}
@Override
public void customize(RequestConfig.Builder builder) {
map.from(this.properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis)
.to(builder::setConnectTimeout);
map.from(this.properties::getReadTimeout).whenNonNull().asInt(Duration::toMillis)
.to(builder::setSocketTimeout);
}
}
private static class PropertiesCredentialsProvider extends BasicCredentialsProvider {
PropertiesCredentialsProvider(ElasticsearchRestClientProperties properties) {
if (StringUtils.hasText(properties.getUsername())) {
Credentials credentials = new UsernamePasswordCredentials(properties.getUsername(),
properties.getPassword());
setCredentials(AuthScope.ANY, credentials);
}
properties.getUris().stream().map(this::toUri).filter(this::hasUserInfo)
.forEach(this::addUserInfoCredentials);
}
private URI toUri(String uri) {
try {
return URI.create(uri);
}
catch (IllegalArgumentException ex) {
return null;
}
}
private boolean hasUserInfo(URI uri) {
return uri != null && StringUtils.hasLength(uri.getUserInfo());
}
private void addUserInfoCredentials(URI uri) {
AuthScope authScope = new AuthScope(uri.getHost(), uri.getPort());
Credentials credentials = createUserInfoCredentials(uri.getUserInfo());
setCredentials(authScope, credentials);
}
private Credentials createUserInfoCredentials(String userInfo) {
int delimiter = userInfo.indexOf(":");
if (delimiter == -1) {
return new UsernamePasswordCredentials(userInfo, null);
}
String username = userInfo.substring(0, delimiter);
String password = userInfo.substring(delimiter + 1);
return new UsernamePasswordCredentials(username, password);
}
}
}
具体的API测试
1、创建索引
2、判断索引是否存在
3、删除索引
4、创建文档
5、操作CRUD文档
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.serializer.SerializeFilter;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.IndicesClient;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchAllQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.core.GenericTypeResolver;
import top.laoliu.pojo.User;
import top.laoliu.utils.ESconst;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* ES 7.6.x 高级客户端的 API测试
*/
@SpringBootTest
class LaoliuEsApiApplicationTests {
//面向对象来操作
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
//测试索引的创建 Request
@Test
void testCreateIndex() throws IOException {
//1、创建索引请求
CreateIndexRequest request = new CreateIndexRequest("laoliu_index");
//2、客户端执行创建请求,获得请求后的响应
CreateIndexResponse createIndexResponse =
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
//测试获取索引,判断其是否存在
@Test
void testExistIndex() throws IOException {
//1、创建索引请求
GetIndexRequest request = new GetIndexRequest("laoliu_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
//1、创建索引请求
DeleteIndexRequest request = new DeleteIndexRequest("laoliu_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
//是否删除成功
System.out.println(delete.isAcknowledged());
}
//测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("狂神说", 3);
//创建请求
IndexRequest request = new IndexRequest("laoliu_index");
//规则 put /laoliu_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse =
client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString()); //
System.out.println(indexResponse.status()); //对应我们命令返回的状态 CREATED
}
//获取文档,判断是否存在
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("laoliu_index", "1");
//不获取返回的_source的上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists =
client.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获取文档信息
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("laoliu_index", "1");
GetResponse getResponse =
client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse); //返回的全部内容和命令行一样的
System.out.println(getResponse.getSourceAsString()); //打印文档的内容
System.out.println(getResponse.getSource());
Map<String, Object> sourceMap = getResponse.getSource();
sourceMap.forEach((s, o) -> {
System.out.println(s + "\t" + o);
});
}
//更新文档信息
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("laoliu_index", "1");
//操作
updateRequest.timeout("1s");
User user = new User("狂神说Java", 18);
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse =
client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
//删除文档信息
@Test
void testDeleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("laoliu_index", "1");
DeleteResponse deleteResponse =
client.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
//特殊。批量查询,真的项目一般都会批量插入数据!
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("laoliu1", 3));
userList.add(new User("laoliu2", 3));
userList.add(new User("laoliu3", 3));
userList.add(new User("lsx1", 3));
userList.add(new User("lsx1", 3));
userList.add(new User("lsx1", 3));
//批处理请求
for (int i = 0; i < userList.size(); i++) {
//批量更新和批量删除,就在这里修改对应的请求就可以了!
bulkRequest.add(
new IndexRequest("laoliu_index")
.id("" + (i + 1)) //不添加生成随机id
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON)
);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures()); //是否失败,返回false代表成功!
}
// 复杂查询
// SearchRequest 搜索请求
// SearchSourceBuilder 条件构造
// HighlightBuilder 高亮构造
// TermQueryBuilder 精确查询
// MatchAllQueryBuilder match模糊查询
// xxxQueryBuilder 对应命令
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我们可以使用QueryBuilders 工具类来实现
//QueryBuilders.termQuery 精确匹配
//QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "lsx1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
// sourceBuilder.from();
// sourceBuilder.size();
// sourceBuilder.highlighter();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//将查询条件 放到 请求
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
System.out.println(JSON.toJSONString(hits));
System.out.println("==================================");
for (SearchHit hit : hits.getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
}
实战
最终效果
1、项目的整体架构
2、pom依赖
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.1elasticsearch.version>
properties>
<dependencies>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.13.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.75version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-thymeleafartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
3、application.properties配置
server.port=9090
#关闭thymeleaf的缓存
spring.thymeleaf.cache=false
4、静态资源
- 链接:https://pan.baidu.com/s/1PT3jLvCksOhq7kgAKzQm7g
- 提取码:s824
5、静态资源添加到项目当中
6、ES客户端配置类
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
爬虫(Java-ES仿京东实战)
数据问题?数据库获取,消息队列中获取,都可以成为数据源,爬虫!
爬取数据:(获取请求返回的页面信息,筛选出我们想要的数据就可以了!)
jsoup包需要导入的依赖
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.13.1version>
dependency>
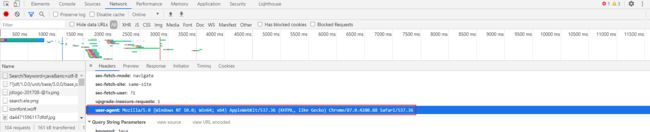
在请求头添加这个内容 user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36解决需要登录的问题
public class HtmlParseUtil {
public static void main(String[] args) throws IOException {
//获取请求 https://search.jd.com/Search?keyword=java
//前提,需要联网,不能获取到ajax!
String url = "https://search.jd.com/Search?keyword=java&enc=utf-8&wq=ja&pvid=ab735d276e254f70b86366f8ce34de34";
// String url = "https://list.tmall.com/search_product.htm?q=java&type=p&vmarket=&spm=875.7931836%2FB.a2227oh.d100&from=mallfp..pc_1_searchbutton";
//解析网页。(Jsoup返回Document就是浏览器Document对象)
// Document document = Jsoup.parse(new URL(url), 30000);
Connection connect = Jsoup.connect(url);
connect.header("user-agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36");
Document document = connect.get();
System.out.println(document);
//所有你在js中使用的方法,这里都可以使用!
Element element = document.getElementById("J_goodsList");
System.out.println(element);
}
}
F:\vue>npm install vue
F:\vue>npm install axios
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FYPfsWI0-1650277602189)(https://gitee.com/liu_shaoxiong/pictures/raw/master/img/1607505763646.png)]
config包
ElasticSearchClientConfig.java
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("127.0.0.1",9200,"http"))
);
return client;
}
}
utils包
HtmlParseUtil.java
@Component
public class HtmlParseUtil {
// public static void main(String[] args) throws IOException {
// new HtmlParseUtil().parseJD("java").forEach(System.out::println);
// }
public ArrayList<Content> parseJD(String keywords) throws IOException {
//获取请求 https://search.jd.com/Search?keyword=java
//前提,需要联网,不能获取到ajax!
String url = "https://search.jd.com/Search?keyword=" + keywords + "&enc=utf-8";
//解析网页。(Jsoup返回Document就是浏览器Document对象)
// Document document = Jsoup.parse(new URL(url), 30000);
Connection connect = Jsoup.connect(url);
connect.header("user-agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36");
Document document = connect.get();
//所有你在js中使用的方法,这里都可以使用!
Element element = document.getElementById("J_goodsList");
//获取所有的li元素
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
//获取元素中的内容,el就是每个li标签
for (Element el : elements) {
// 关于这种图片,特别多的网站,所有的图片都是延迟加载的!
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
goodsList.add(new Content(title, img, price));
}
return goodsList;
}
}
pojo包
Content.java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Content {
private String title;
private String img;
private String price;
}
controller包
IndexController.java
@Controller
public class IndexController {
@GetMapping({"/", "/index"})
public String index() {
return "index";
}
}
ContentController.java
//请求编写
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keywords}")
public Boolean parse(@PathVariable("keywords") String keywords) throws Exception {
Boolean aBoolean = contentService.parseContent(keywords);
return aBoolean;
}
// @GetMapping("/searchPage/{keyword}/{pageNo}/{pageSize}")
// public List> searchPage(@PathVariable String keyword,
// @PathVariable int pageNo,
// @PathVariable int pageSize) throws IOException {
// List> list = contentService.searchPage(keyword, pageNo, pageSize);
// System.out.println(list);
// return list;
// }
@GetMapping("/searchPage/{keyword}/{pageNo}/{pageSize}")
public List<Map<String, Object>> searchPage(@PathVariable String keyword,
@PathVariable int pageNo,
@PathVariable int pageSize) throws IOException {
List<Map<String, Object>> list = contentService.searchPageHighLightBuilder(keyword, pageNo, pageSize);
System.out.println(list);
return list;
}
}
service包
ContentService.java
//业务编写
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//1、===================================解析数据放入es索引中============================
public Boolean parseContent(String keywords) throws Exception {
ArrayList<Content> contents = new HtmlParseUtil().parseJD(keywords);
//把查询的数据放入es中
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < contents.size(); i++) {
bulkRequest.add(new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
//2、=========================================获取这些数据实现搜索功能======================================
public List<Map<String, Object>> searchPage(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
//构建条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//分页
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
//模糊查询
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", keyword);
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//条件放进请求
searchRequest.source(searchSourceBuilder);
//客户端发送请求,执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
//解析结果
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : hits.getHits()) {
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
list.add(sourceAsMap);
}
return list;
}
//3、==============================================实现搜索高亮功能==============================================
public List<Map<String, Object>> searchPageHighLightBuilder(String keyword, int pageNo, int pageSize) throws IOException {
if (pageNo <= 1) {
pageNo = 1;
}
//条件搜索
SearchRequest searchRequest = new SearchRequest("jd_goods");
//构建条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//分页
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
//模糊查询
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", keyword);
searchSourceBuilder.query(matchQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//构建高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false); //多个高亮显示关闭
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
//条件放进请求
searchRequest.source(searchSourceBuilder);
//客户端发送请求,执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
//解析结果
List<Map<String, Object>> list = new ArrayList<>();
for (SearchHit hit : hits.getHits()) {
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
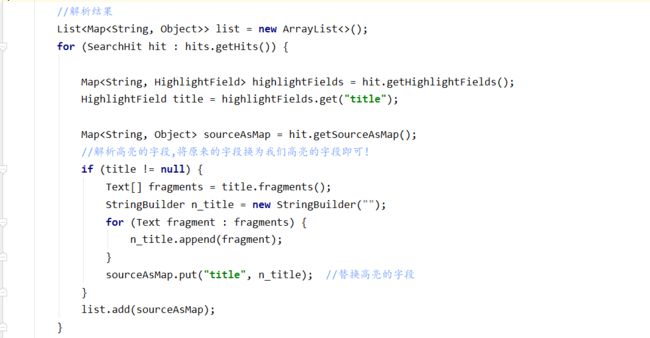
//解析高亮的字段,将原来的字段换为我们高亮的字段即可!
if (title != null) {
Text[] fragments = title.fragments();
StringBuilder n_title = new StringBuilder("");
for (Text fragment : fragments) {
n_title.append(fragment);
}
sourceAsMap.put("title", n_title); //替换高亮的字段
}
list.add(sourceAsMap);
}
return list;
}
}
测试将数据放入到es中 访问 http://localhost:9090/parse/vue
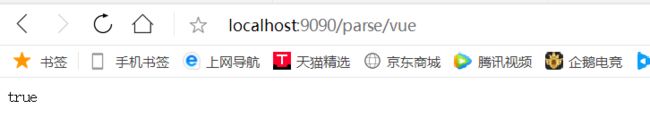
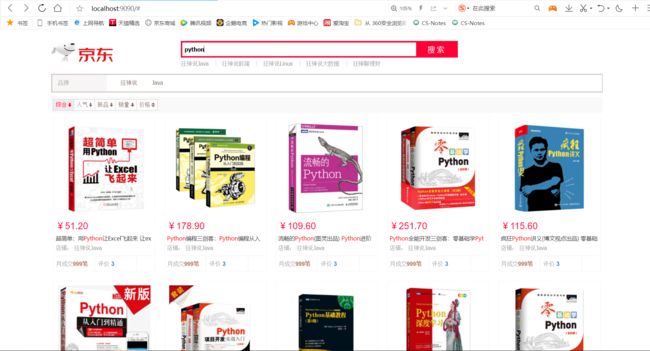
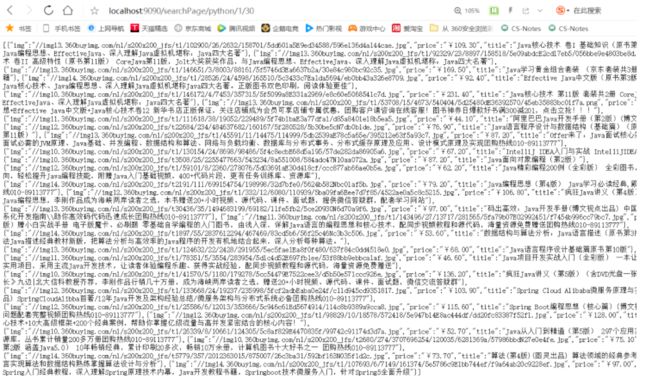
测试分页 访问 http://localhost:9090/searchPage/python/1/30
前后端分离
前端修改的部分


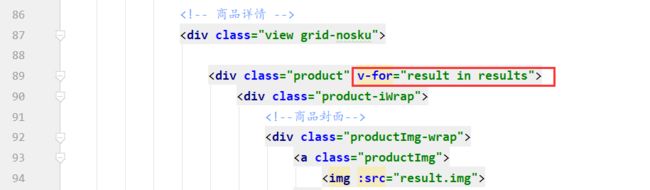
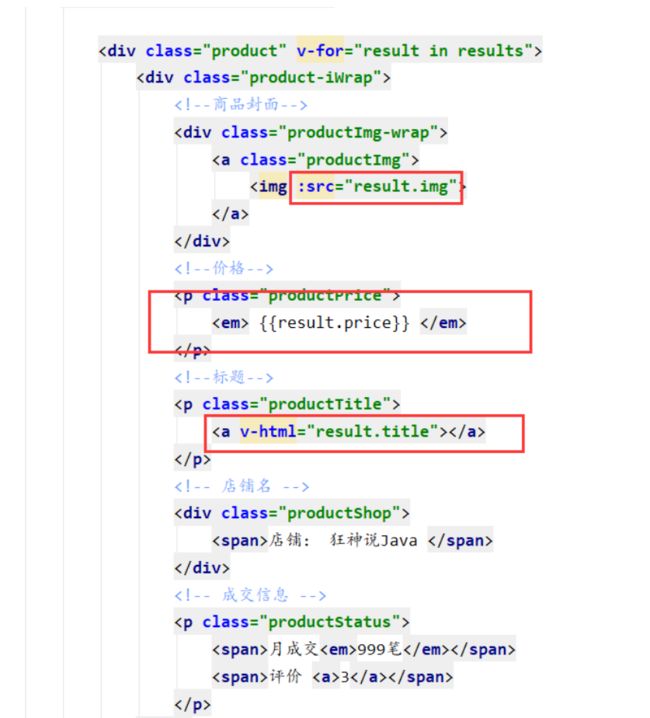

搜索高亮
构建高亮

解析高亮
解析高亮的字段,将原来的字段换为我们高亮的字段即可!