快速入门Java爬虫、全文搜索引擎Elasticsearch,分析实战项目:仿京东搜索(二)
hi大家好,今天我把上周的内容继续讲完!!
接着上次的部分,今天我们分享的是Elaticsearch全文搜索引擎,Elasticsearch是基于Lucene做了一些封装和增强。
首先我们先介绍一下Elasticsearch,简称es是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储、检索数据;本身它扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的Restful API 来隐藏Luncene的复杂性,从而让全文搜索变得简单。
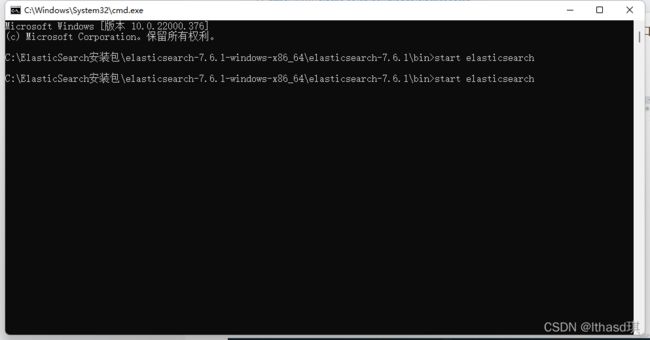
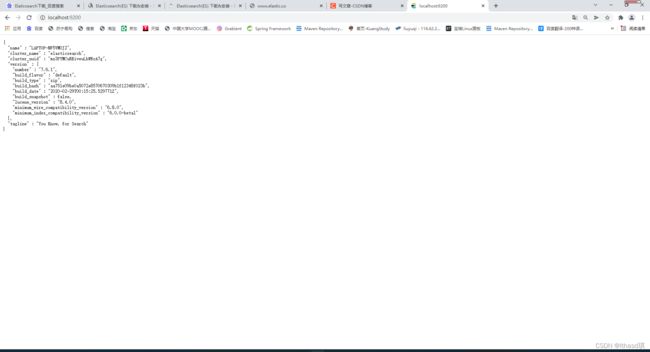
首先大家先去下载好Elaticsearch,访问 Elasticsearch 官网 下载安装包Download Elasticsearch | Elastic https://www.elastic.co/cn/downloads/elasticsearch得到下载的文件后,在bin目录下打开cmd,start elasticsearch,再用浏览器打开9200端口,出现以下界面代表运行成功。
https://www.elastic.co/cn/downloads/elasticsearch得到下载的文件后,在bin目录下打开cmd,start elasticsearch,再用浏览器打开9200端口,出现以下界面代表运行成功。
在这里进行一些小扩展,这里我们可以使用一些扩展插件如head和Kibana,Kibana是一个针对Elasticsearch的开源分析及及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。简单的来说,这些扩展插件是可以用来帮助我们具体学习Elaticsearch的,毕竟是可视化。
如果大家想具体了解Elaticesearch的功能,可以去看官网的开发文档,像里面的·IK分词器、高亮都是需要掌握的。
我今天是展示项目所以不多说,首先我们需要把上篇文章的爬虫包装成一个类,方便我们调用,毕竟我们在使用es前必须保证里面有数据才对。
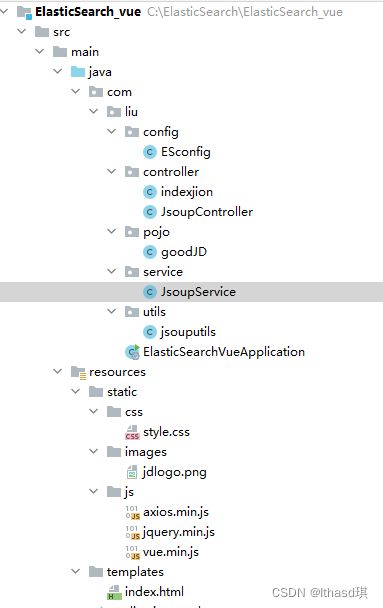
项目的所有文件都如图所示, yaml文件我配置的端口是8081;在用之前得保证你有相关的jsoup和es得maven依赖,上周已经提供。以下是上周的爬虫类utils下的jsoupService
package com.liu.utils;
import com.liu.pojo.goodJD;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.stereotype.Component;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
@Component
public class jsouputils {
// public static void main(String[] args) throws Exception {
https://search.jd.com/Search?keyword=java
// new jsouputils().parsJD("java").forEach(System.out::println);
// }
public List parsJD(String keywords) throws Exception {
String url ="https://search.jd.com/Search?keyword="+keywords;
Document document = Jsoup.parse(new URL(url), 900000000);
Element element = document.getElementById("J_goodsList");
Elements elements = element.getElementsByTag("li");
ArrayList goodJDlist = new ArrayList<>();
for (Element el : elements) {
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
String shopnum = el.getElementsByClass("p-shop").eq(0).text();
goodJD goodJD = new goodJD();
goodJD.setTitle(title);
goodJD.setImg(img);
goodJD.setPrice(price);
goodJD.setShopnum(shopnum);
goodJDlist.add(goodJD);
}
return goodJDlist;
}
}
接下来我们需要在config目录下加一个ESconfig类,目的是为了连接上我们的ES,127.0.0.1:9200代表本地路径加端口。具体代码如下所示:
package com.liu.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ESconfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")));
return client;
}
}
接下来就是最难的service层了,具体代码如下:
package com.liu.service;
import com.alibaba.fastjson.JSON;
import com.liu.pojo.goodJD;
import com.liu.utils.jsouputils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.naming.directory.SearchResult;
import javax.swing.text.Highlighter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.concurrent.TimeUnit;
@Service
public class JsoupService {
@Autowired
private RestHighLevelClient restHighLevelClient;
public Boolean parseContent(String keywords) throws Exception {
List goodJDS = new jsouputils().parsJD(keywords);
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0; i < goodJDS.size(); i++) {
bulkRequest.add((new IndexRequest("jd_good")
.source(JSON.toJSONString(goodJDS.get(i)), XContentType.JSON)
));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
public List> seachPage(String keywords,
int pageNo,
int pageSize) throws IOException {
if(pageNo<=1){
pageNo=1;
}
SearchRequest searchRequest = new SearchRequest("jd_good");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keywords);
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ArrayList>list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits()) {
list.add(documentFields.getSourceAsMap());
}
return list;
}
public List> seachPagehighlighter(String keywords,
int pageNo,
int pageSize) throws IOException {
if(pageNo<=1){
pageNo=1;
}
SearchRequest searchRequest = new SearchRequest("jd_good");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNo);
searchSourceBuilder.size(pageSize);
TermQueryBuilder termQueryBuilder =
QueryBuilders.termQuery("title", keywords);
searchSourceBuilder.query(termQueryBuilder);
searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse =
restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ArrayList>list = new ArrayList<>();
for (SearchHit documentFields : searchResponse.getHits()) {
Map highlightFields =
documentFields.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map sourceAsMap = documentFields.getSourceAsMap();
if(title!=null){
Text[] fragments = title.fragments();
String ntitle="";
for (Text text : fragments) {
ntitle +=text;
}
sourceAsMap.put("title",ntitle);
}
list.add(sourceAsMap);
}
return list;
}
}
对应service层我来进行一下简单的分析,
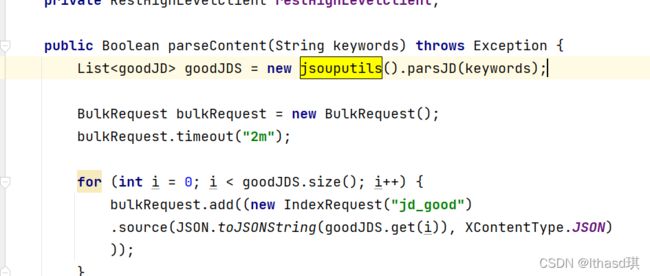
BulkRequest是插入多个数据时候使用,连接2分钟
高亮操作:

接着是controllerr层
JsoupController类:
package com.liu.controller;
import com.liu.service.JsoupService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
import java.util.List;
import java.util.Map;
@RestController
public class JsoupController {
@Autowired
private JsoupService jsoupService;
@CrossOrigin
@GetMapping("/parse/{keywords}")
public Boolean parse(@PathVariable String keywords) throws Exception {
return jsoupService.parseContent(keywords);
}
@CrossOrigin
@GetMapping("/search/{keywords}/{pageNo}/{pageSize}")
public List> search(
@PathVariable String keywords,
@PathVariable int pageNo,
@PathVariable int pageSize) throws IOException {
return jsoupService.seachPagehighlighter(keywords,pageNo,pageSize);
}
}
indexjion类:
package com.liu.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
@Controller
public class indexjion {
@GetMapping({"/", "/index"})
public String toindex(){
return "index";
}
}
前端界面
index.html:
Java-ES仿京东实战
最终实现结果:
首页: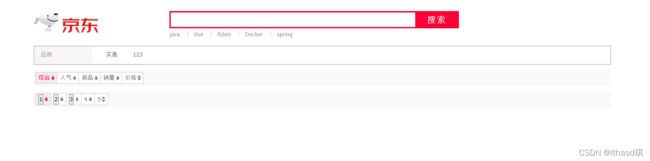
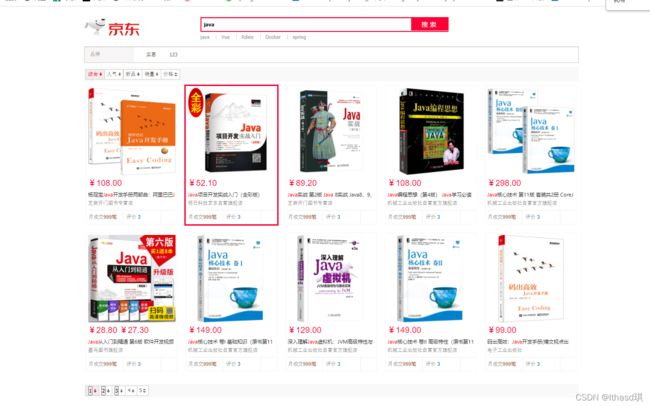
输入java之后:(爬虫爬的java数据!!!)
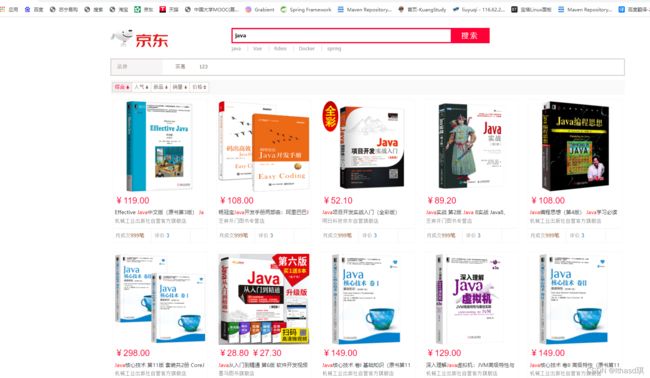
可以按下一页调节: