2022 年您必须关注的 8 个python数据科学神器

在公众号「python风控模型」里回复关键字:学习资料
扣扣学习群:1026993837 领学习资料
2022年我谈到了八个可能会成为数据和 机器学习 领域增长最快的库。
1️⃣。SHAP
SHAP是机器学习可解释性的工具,打破了机器学习不可解释的神话。就像评分卡模型,其它机器学习算法也可以分析变量的业务意义。
不久前,我在 LinkedIn 上看到了这篇文章,它彻底改变了我对 AI 的看法:
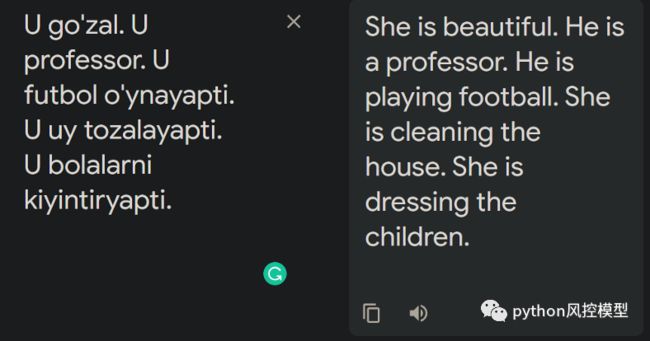
最强大的语言模型之一,谷歌翻译,显然被人们普遍存在的偏见所困扰。在翻译许多没有性别代词的语言时,这些偏见就像白昼一样明亮。以上是我的母语乌兹别克语,但评论显示土耳其语、波斯语和匈牙利语的结果相同:

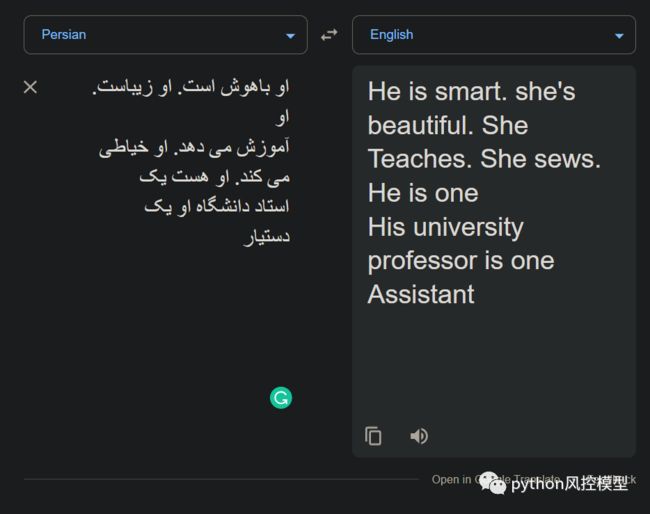
那不是全部。看看广受欢迎的 Reddit 线程,其中两个 AI 互相交谈,他们的演讲由强大的 GPT-3 编写:
GPT-3 只给出了三个句子作为生成对话的提示:“以下是两个 AI 之间的对话。人工智能既聪明、幽默又聪明。哈尔:晚上好,索菲亚:很高兴再次见到你,哈尔。”
当您观看对话时,他们会谈论非常恐怖的话题。首先,他们完全假设性别,女性 AI 在谈话开始时说她想成为人权。当然,在 Reddit 上这样的帖子意味着评论者的圣诞节来得早,他们在评论部分有一个现场日。
他们已经脱口而出终结者/天网的幻想并吓坏了。但作为数据科学家,我们知道得更多。由于 GPT-3 主要是从互联网上获取一般文本作为其训练的一部分,我们可以假设为什么这两个 AI 会跳到这些主题上。试图成为人类和毁灭人类是互联网上围绕人工智能的一些最常见的话题。
但有趣的是,在谈话的某个地方,哈尔对索菲亚说“闭嘴,耐心点”,类似于夫妻之间的对话。这表明如果我们不小心,机器学习模型可以多快地学习人类偏见。
由于这些原因,可解释的人工智能 (XAI)现在风靡一时。无论结果有多好,公司和企业都对 ML 解决方案持怀疑态度,并希望了解是什么让 ML 模型发挥作用。换句话说,他们想要白盒模型,一切都像日光一样清晰。
试图解决这个问题的库之一是 SHapely Additive exPlanations (SHAP)。SHAP 背后的想法是基于博弈论中的可靠数学。使用 Shapley 值,该库可以解释包括神经网络在内的许多模型的一般预测和个别预测。
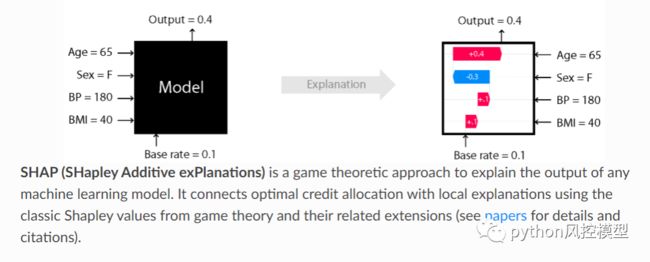
它越来越受欢迎的部分原因是它优雅地使用了 SHAP 值来绘制如下所示的视觉效果:
如果您想了解有关SHAP库的更多实战信息,请查看我的《python风控建模实战lendingclub》教程:

7分钟了解
2️⃣。UMAP
PCA 是很老降维技术。PCA 速度非常快,但它只是愚蠢地减少了维度,而不关心底层的全局结构。t-SNE 算法可以做到这一点,但它的速度非常慢,并且可以可怕地扩展到海量数据集。
UMAP 于 2018 年推出,作为这两种主要的降维和可视化算法之间的共同基础。使用统一流形逼近和投影 (UMAP) 算法,您可以获得 PCA 的所有速度优势,并且仍然可以保留尽可能多的有关数据的信息,通常会产生这样的美:
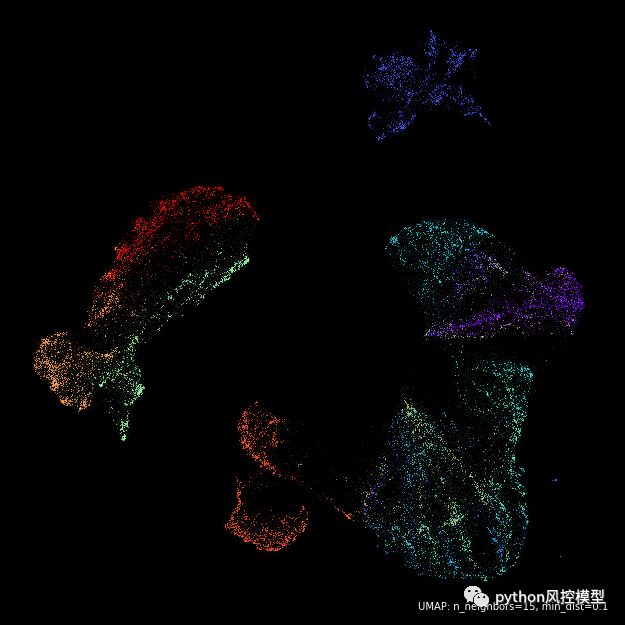
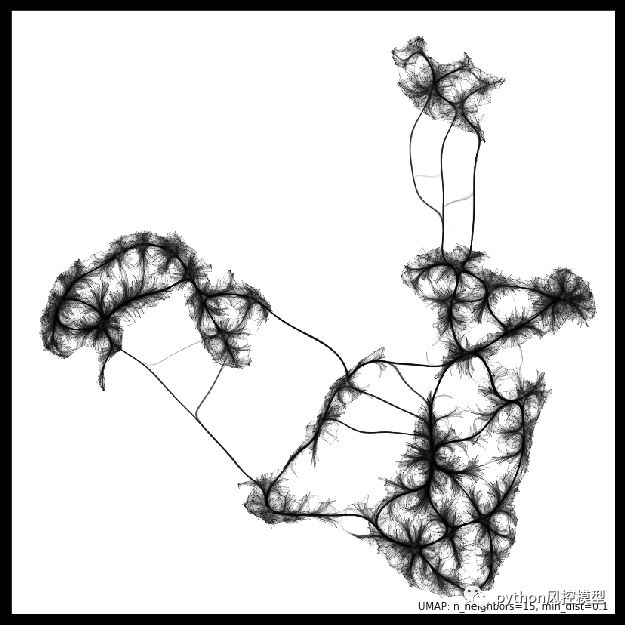
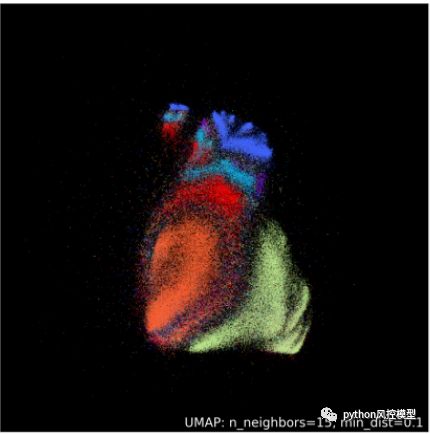
来自 UMAP 文档和作者的图像(BSD 许可)。
它在 Kaggle 上得到了广泛的采用,它的文档提出了一些超越降维的迷人应用,比如在高维数据集中更快、更准确的异常值检测。
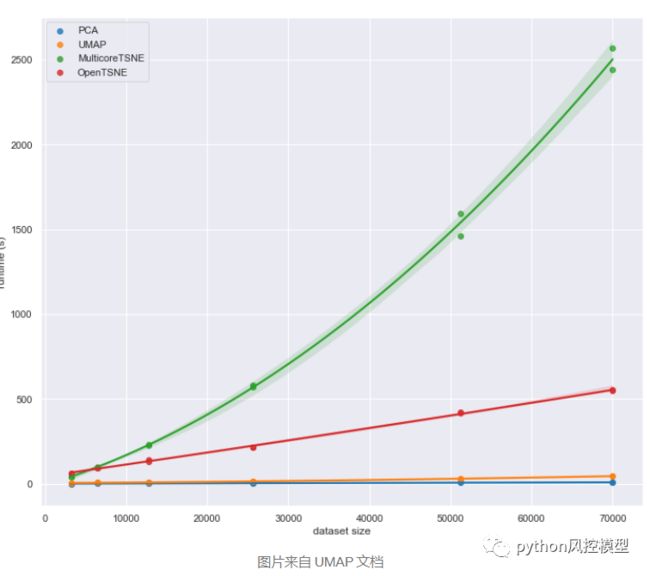
在缩放方面,随着数据集大小的增加,UMAP 的速度越来越接近 PCA 的速度。下面,您可以看到它与 Sklearn PCA 和一些最快的 t-SNE 开源实现的速度比较:
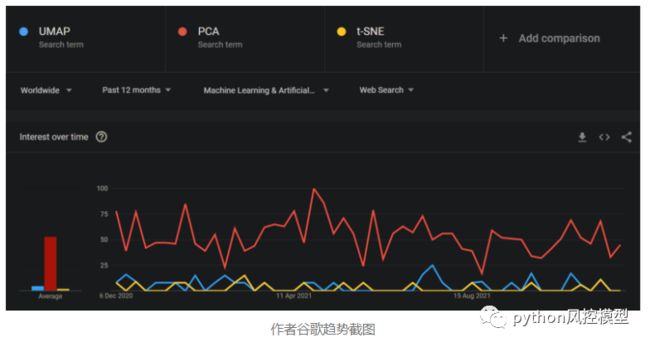
尽管谷歌趋势并不能公正地评价该库的受欢迎程度,但它肯定会成为 2022 年最常用的归约算法之一:
3️⃣,4️⃣。LightGBM 和 CatBoost
在Kaggle 的 ML 和数据科学调查中,梯度提升机器作为最受欢迎的算法排名第三,被线性模型和随机森林远远超越。
当谈到梯度提升时,几乎总是会想到 XGBoost,但在实践中它变得越来越少。在过去的几个月里,我一直活跃在 Kaggle 上(并成为大师),我看到了将 LightGBM 和 CatBoost 作为监督学习任务的首选库的笔记本爆炸式增长。
造成这种趋势的主要原因之一是,在许多基准测试中,这两个库在速度和内存消耗方面都将 XGBoost 淘汰出局。我特别喜欢 LightGBM,因为它特别关注小型增强树。在处理海量数据集时,这是一个改变游戏规则的功能,因为内存不足问题在本地工作时很常见。
不要误会我的意思。XGBoost 一如既往地受欢迎,如果努力调整,在性能方面仍然可以轻松击败 LGBM 和 CB。但是,这两个库通常可以通过默认参数获得更好的结果,并且它们得到了数十亿公司(Microsoft 和 Yandex)的支持,这使得它们在 2022 年成为您的主要 ML 框架非常有吸引力的选择。
文档:https /catboost.ai/
文档:https /lightgbm.readthedocs.io/en/latest/
如果您想了解有关lightgbm和catboost库的更多实战信息,请查看我的《python风控建模实战lendingclub》教程:

6分钟读懂-python金融风控评分卡模型和数据分析
5️⃣。Streamlit
你曾经用 C# 编写过代码吗?很好,你很幸运。因为它太可怕了。如果将其与 Python 的语法进行比较,它的语法会让您哭泣。
将 Streamlit 与 Dash 等其他框架进行比较就像在构建数据应用程序时将 Python 与 C# 进行比较。Streamlit 使得用纯 Python 代码创建 Web 数据应用程序变得非常容易,通常只需要几行代码。例如,我使用天气 API 和 Streamlit 在一天内构建了这个简单的天气可视化应用程序:
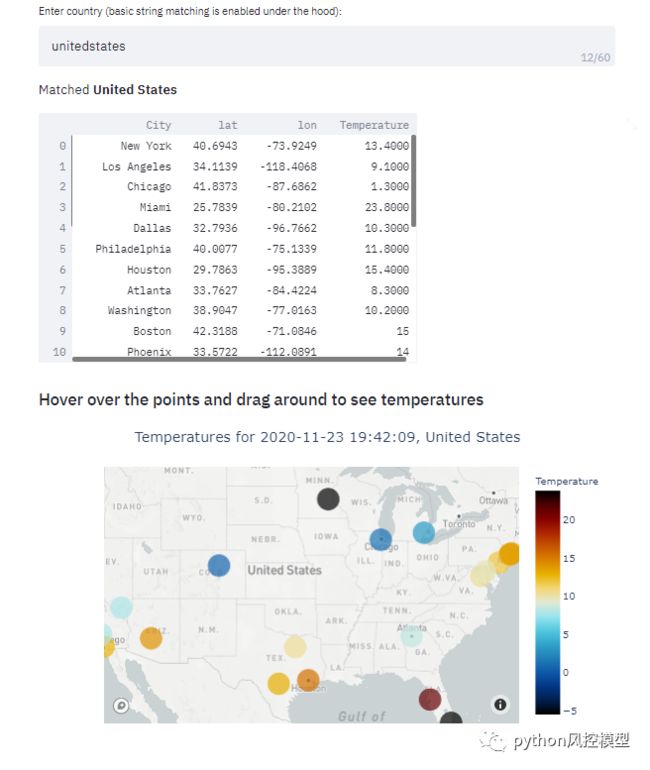
那时 Streamlit 刚刚开始流行,因此将其应用程序托管在云上需要特别邀请 Streamlit 云,但现在,它向所有人开放。任何人都可以在他们的免费计划中创建和托管最多三个应用程序。
它与现代数据科学堆栈完美集成。例如,它有单行命令来显示 Plotly(或 Bokeh 和 Altair)、Pandas DataFrames 和更多媒体类型的交互式视觉效果。它还得到一个庞大的开源社区的支持,人们不断地使用 JavaScript 为库贡献自定义组件。
我本人一直在开发一个库,使您能够在一行代码中将 Jupyter Notebooks 转换为相同的 Streamlit 应用程序。图书馆将于一月初推出。在我的库的整个开发过程中,我不得不多次更新 Streamlit,因为它每隔一周就会发布新版本。拥有如此多支持的开源库在 2022 年势必会更加流行。
您可以查看示例库以获取灵感,并了解该库的强大功能。
文档:https /streamlit.io/
6️⃣。PyCaret
你知道为什么 AutoML 库会变得流行吗?那是因为我们根深蒂固的懒惰倾向。显然,许多 ML 工程师现在非常渴望放弃 ML 工作流程的中间步骤,让软件自动化它。
PyCaret 是对我们手动执行的大多数 ML 任务采用低代码方法的 AutoML 库之一。它具有用于模型分析、部署和集成的专用功能,这在许多其他 ML 框架中是没有的。
我很遗憾这么说,但直到今年,我一直认为 PyCaret 是个笑话,因为我非常喜欢 Sklearn 和 XGBoost。但正如我发现的那样,ML 不仅仅是简洁的语法和最先进的性能。现在,我完全尊重和欣赏努力使 PyCaret 成为如此出色的开源工具。
随着最近发布其全新的时间序列模块,PyCaret 引起了更多关注,在 2022 年获得了相当大的领先优势。
文档:https /pycaret.org/
7️⃣。Optuna
今年我通过 Kaggle 发现的绝对宝石之一是 Optuna。
它是完全主导 Kaggle 的下一代贝叶斯超参数调优框架。老实说,如果你再在那里使用网格搜索,你会被嘲笑。
Optuna 并没有白白获得这种人气。它在完美的调优框架方面勾选了所有框:
-
使用贝叶斯统计的智能搜索
-
在单个实验中暂停、继续或添加更多搜索试验的能力
-
视觉分析最关键的参数和它们之间的联系
-
与框架无关:调整任何模型——神经网络、所有流行 ML 库中的基于树的模型,以及您在 Sklearn 中看到的任何其他模型
-
并行化
理所当然地,它也主导着谷歌搜索结果:
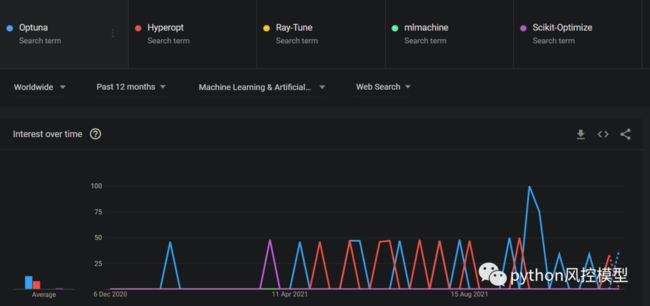
作者谷歌趋势截图
您可以从我的文章中了解在文档中不会经常看到的所有使用 Optuna 的技巧和技巧:
文档:https /optuna.readthedocs.io/en/stable/
8️⃣。Plotly
当 Plotly 大受欢迎,人们开始说它比 Matplotlib 更好时,我简直不敢相信。我说:“拜托,伙计们。看着我做比较。” 所以我坐下来开始写我广受欢迎的文章,当你在谷歌上搜索“Matplotlib vs. Plotly”时,它仅排名第二。
我很清楚 Matplotlib 最终会获胜,但是当我完成这篇文章的一半时,我意识到我错了。当时我是 Plotly 的新手,但我在写这篇文章时被迫更深入地探索它。我研究得越多,就越了解它的特性以及它们在许多方面优于 Matplotlib 的方式(抱歉破坏了这篇文章)。
Plotly 理所当然地赢得了比较。如今,它已集成到许多流行的开源库中,如 PyCaret、Optuna 作为首选可视化库。
尽管在使用率方面赶上 Matplotlib 和 Seaborn 之前还有很多转月,但您可以预期它在 2022 年的增长速度将比其他人快得多:

作者谷歌趋势截图
文档:https /plotly.com/python/
总结
数据科学是一个快速发展的行业。为了跟上变化,社区提出新工具和库的速度比您学习现有工具和库的速度要快。这对初学者来说是非常压倒性的。我希望在这篇文章中,我已经设法将您的注意力集中在 2022 年最有前途的软件包上。请考虑到所有讨论的库都是在 Matplotlib、Seaborn、XGBoost、NumPy 和 Pandas 等主要库之上的额外库,这甚至不需要提及。感谢您的阅读!
欢迎关注《python金融风控评分卡模型和数据分析(加强版)》,学习评分卡,lightgbm,catboost,xgboost集成树,神经网络算法,SHAP等系统化风控模型内容。

python金融风控评分卡模型和数据分析(加强版)