Centos Linux 单机安装 Hive 、使用 Hive
Centos Linux 单机安装 Hive 、使用 Hive
视频教程链接:https://www.bilibili.com/video/BV1Rv4y117NR/
1. Hive 简介

-
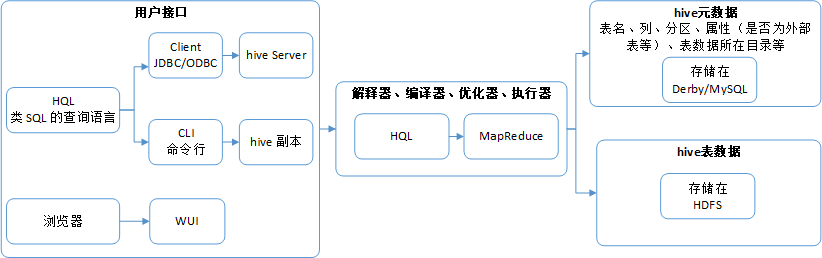
hive 是基于 Hadoop 构建的一套数据仓库分析系统;
-
hive 通过 SQL 查询方式来分析存储在 HDFS 中的数据:可以将结构化的数据文件映射为一张数据库表,并提供完整的类 SQL 查询功能,这套 SQL 名为 Hive SQL,简称 HQL;
-
hive 可以将 HQL 语句转换为 MapReduce 任务运行;
-
hive 的表数据存储与 HDFS;而其元数据存储与其他数据库(如 Derby、MySQL),元数据包括 hive 表的表名、列、分区、属性(是否为外部表等)、表数据所在 HDFS 目录等;
-
hive 支持的存储格式包括 TextFile、SequenceFile、RCFile、Avro Files、ORC Files、Parquet。
-
hive 默认没有开启更新(update)和删除(delete)功能;
-
hive 不适合用于联机(online)事务处理,也不提供实时查询功能;
-
hive 最适合应用在基于大量不可变数据的批处理作业。
2. 准备工作
2.1. 拥有一台 Centos Linux 机器
参考文章:
《VMware 安装 Centos 7 Linux 虚拟机》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/839c494401839c52b7642c9380920001
2.2. Centos Linux 安装好 JDK、配置好环境变量
参考文章:
《Centos Linux 安装 JDK 8、配置环境变量》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/839c494401839e49fa8a2c9380920002
2.3. 在 CentOS Linux 上安装好 Hadoop
参考文章:
《Centos Linux 安装单机 Hadoop(HDFS)》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/839c49440183a41b4a732c9380920003
2.4. 在 CentOS Linux 上安装好 MySQL
参考文章:
《Centos Linux 离线安装 MySQL 5.7、使用MySQL》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/83a48b1901847349507d2c9380920002
2.5. 下载 Hive
hive 官网:
https://hive.apache.org/
hive 安装包官网下载地址(官网,下载速度慢):
https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
hive 安装包国内镜像下载链接(清华大学开源软件镜像站,下载速度快):
https://mirrors.tuna.tsinghua.edu.cn/apache/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
3. 安装、配置 Hive
3.1. 上传 Hive 安装包、解压、放到安装位置
将安装包 apache-hive-3.1.3-bin.tar.gz 上传到 /root/ 目录。
# 进入到root目录
cd /root
# 解压
tar -zxvf apache-hive-3.1.3-bin.tar.gz
# 创建安装目录
mkdir /usr/local/hive
# 将解压后的hive挪到创建的安装目录
mv /root/apache-hive-3.1.3-bin/ /usr/local/hive/
# 进入到安装目录
cd /usr/local/hive/apache-hive-3.1.3-bin/
# 查看
ll
3.2. 配置 hive
-
hive-site.xml
在 hive 安装目录的
conf目录下,创建hive-site.xml配置文件。并将以下内容写入其中。vi /usr/local/hive/apache-hive-3.1.3-bin/conf/hive-site.xml<configuration> <property> <name>javax.jdo.option.ConnectionDriverNamename> <value>com.mysql.cj.jdbc.Drivervalue> property> <property> <name>javax.jdo.option.ConnectionURLname> <value>jdbc:mysql://127.0.0.1:3306/hive_metadata?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=falsevalue> property> <property> <name>javax.jdo.option.ConnectionUserNamename> <value>rootvalue> property> <property> <name>javax.jdo.option.ConnectionPasswordname> <value>123456value> property> <property> <name>hive.metastore.warehouse.dirname> <value>/user/hive/warehouse/internalvalue> property> <property> <name>hive.metastore.warehouse.external.dirname> <value>/user/hive/warehouse/externalvalue> property> <property> <name>hive.server2.enable.doAsname> <value>falsevalue> property> configuration> -
hive-env.sh
将 hive 安装目录的
conf目录下的hive-env.sh.template复制一份改名为hive-env.sh。cp /usr/local/hive/apache-hive-3.1.3-bin/conf/hive-env.sh.template /usr/local/hive/apache-hive-3.1.3-bin/conf/hive-env.sh对
ive-env.sh进行修改,将HADOOP_HOME的注释放开,其值改为本机 Hadoop 的安装目录/usr/local/hadoop/hadoop-3.3.4。即:vi /usr/local/hive/apache-hive-3.1.3-bin/conf/hive-env.shHADOOP_HOME=/usr/local/hadoop/hadoop-3.3.4
3.3. 放置 MySQL jdbc jar包
Maven 中央仓库下载地址:
https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar
将 mysql-connector-java-8.0.30.jar 上传到 /usr/local/hive/apache-hive-3.1.3-bin/lib 下。
3.4. 设置环境变量
vi /etc/profile
在文件末尾添加以下内容:
export HIVE_HOME=/usr/local/hive/apache-hive-3.1.3-bin
export PATH=$HIVE_HOME/bin:$PATH
使环境变量生效:
# 运行配置文件
source /etc/profile
# 检查 PATH 中是否包含 $HIVE_HOME/bin 对应的绝对路径
echo $PATH
3.5. 初始化元数据库
初始化元数据库,指定元数据库类型为 MySQL 。
# 查看MySQL是否启动
service mysqld status
# 如果没有启动,则启动MySQL
service mysqld start
schematool -initSchema -dbType mysql
注:schematool 命令位于 /usr/local/hive/apache-hive-3.1.3-bin/bin/ ,已经配置在环境变量path中,可以直接使用。
3.6. 启动 Hadoop
Hive 是依赖 MySQL 和 Hadoop 的,所以,先启动 MySQL、Hadoop。
# 查看Hadoop是否启动
jps -l |grep hadoop
# 如果没有启动,则启动Hadoop
start-all.sh
3.7. 编写后台启动hive的脚本
前面图中提到过 hive 的三种用户接口。
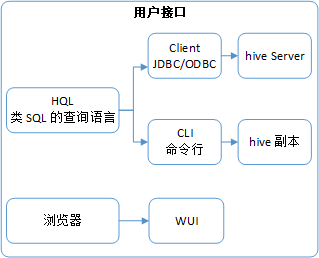
三种用户接口的前台启动方式分别如下:
# Client,JDBC/ODBC + hive Server
hive --service metastore
hive --service hiveserver2
# CLI,命令行 + hive 副本
hive --service cli
# 浏览器,WUI
hive --service hwi
此处选择第一种,同时启动 metastore。编写后台启动脚本:
vi /usr/local/hive/apache-hive-3.1.3-bin/bin/start-hive-metastore-hiveserver2.sh
写入以下内容:
#!/bin/bash
nohup hive --service metastore >> /usr/local/hive/apache-hive-3.1.3-bin/log/metastore.log 2>&1 &
nohup hive --service hiveserver2 >> /usr/local/hive/apache-hive-3.1.3-bin/log/hiveserver2.log 2>&1 &
# 赋予启动脚本执行权限
chmod +x /usr/local/hive/apache-hive-3.1.3-bin/bin/start-hive-metastore-hiveserver2.sh
# 创建日志目录:
mkdir /usr/local/hive/apache-hive-3.1.3-bin/log
3.8. 启动hive
start-hive-metastore-hiveserver2.sh
查看两个日志,无报错即可:
tail -1000f /usr/local/hive/apache-hive-3.1.3-bin/log/metastore.log
tail -1000f /usr/local/hive/apache-hive-3.1.3-bin/log/hiveserver2.log
3.9. 放行端口
# 防火墙放行 8042 tcp 端口,Hadoop http服务端口,可用于在浏览器查看yarn日志
firewall-cmd --zone=public --add-port=8042/tcp --permanent
# 防火墙放行 10000 tcp 端口,hive jdbc连接端口
firewall-cmd --zone=public --add-port=10000/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
3.10. yarn-site.xml 添加 Hadoop 的类路径
查看 Hadoop 的类路径
hadoop classpath
编辑 Hadoop 的 yarn-site.xml 文件
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/yarn-site.xml
添加以下配置项:
<property>
<name>yarn.application.classpathname>
<value>/usr/local/hadoop/hadoop-3.3.4/etc/hadoop:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/common/lib/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/common/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/hdfs:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/hdfs/lib/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/hdfs/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/mapreduce/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/yarn:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/yarn/lib/*:/usr/local/hadoop/hadoop-3.3.4/share/hadoop/yarn/*value>
property>
重启 Hadoop 。
stop-all.sh
start-all.sh
4. 使用 Hive
4.1. 使用 hive 自带的客户端工具 beeline 连接 hive
beeline -u jdbc:hive2://127.0.0.1:10000 -n root
注: -u指的是 hive 的 JDBC URL ;-n 指的是 HDFS 用户名。
查看所有数据库:
show databases;
结果:
+----------------+--+
| database_name |
+----------------+--+
| default |
+----------------+--+
1 row selected (1.591 seconds)
使用数据库 default :
use default;
查看数据库 default 下的所有表:
show tables;
目前没有表。
创建表,表名t_gdp,用于记录每个县区的GDP。
CREATE TABLE t_gdp(
f_year VARCHAR(100),
f_province VARCHAR(100),
f_city VARCHAR(100),
f_county VARCHAR(100),
f_gdp DOUBLE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;
压缩后:
CREATE TABLE t_gdp(f_year VARCHAR(100),f_province VARCHAR(100),f_city VARCHAR(100),f_county VARCHAR(100),f_gdp DOUBLE) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|' LINES TERMINATED BY '\n' STORED AS TEXTFILE;
CRT复制一个连接,创建一个本地文本文件 t_gdp_text.txt :
vi /tmp/t_gdp_text.txt
写入数据:
2021|s_1|ci_1|co_a|0.06|
2021|s_1|ci_2|co_b|0.05|
2021|s_1|ci_3|co_c|0.04|
2021|s_1|ci_4|co_d|0.03|
2021|s_2|ci_5|co_e|0.07|
2021|s_2|ci_6|co_f|0.08|
2021|s_2|ci_7|co_g|0.08|
2021|s_2|ci_8|co_h|0.09|
将文本文件加载到 hive 表:
load data local inpath '/tmp/t_gdp_text.txt' into table t_gdp;
注:local 表示本地文件;除了加载本地文件外,还可以加载 HDFS 上的文件到表中,去掉 local 即可,使用 load data inpath 'HDFS文件路径' into table 表名; 。
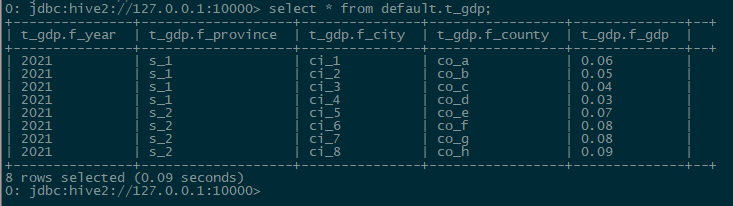
查询所有数据:
select * from default.t_gdp;
查询结果:
统计 2021 年每个省的 GDP:
select f_province,sum(f_gdp) from t_gdp where f_year='2021' group by f_province;
查询结果:

可以在 HDFS 上看到表数据:
hadoop fs -cat /user/hive/warehouse/internal/t_gdp/t_gdp_text.txt
4.2. DBeaver 连接 hive
DBeaver 官网下载页面:
https://dbeaver.io/download/
DBeaver 安装过程:略。
打开驱动管理器:
输入 hive 搜索并编辑hiev驱动:

添加 hive-jdbc 依赖。
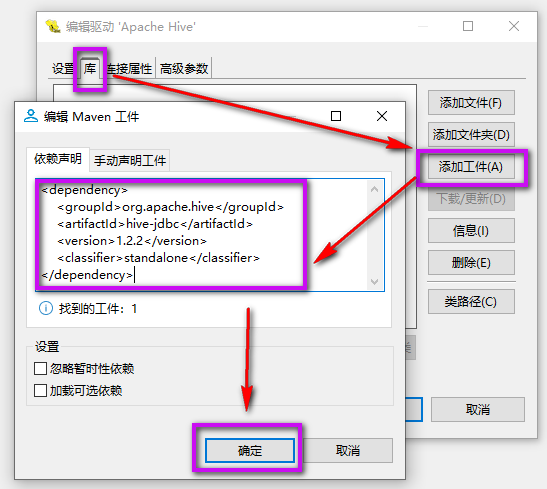
依赖声明填写以下内容:
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.2version>
<classifier>standaloneclassifier>
dependency>
添加 hadoop-core 依赖。
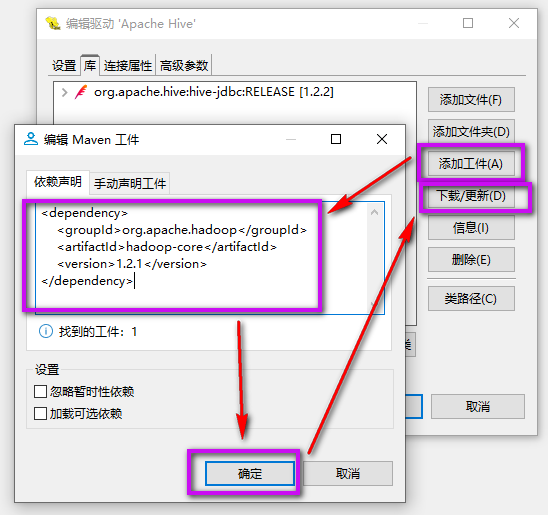
依赖声明填写以下内容:
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-coreartifactId>
<version>1.2.1version>
dependency>
点击 “下载/更新” > “下载”。
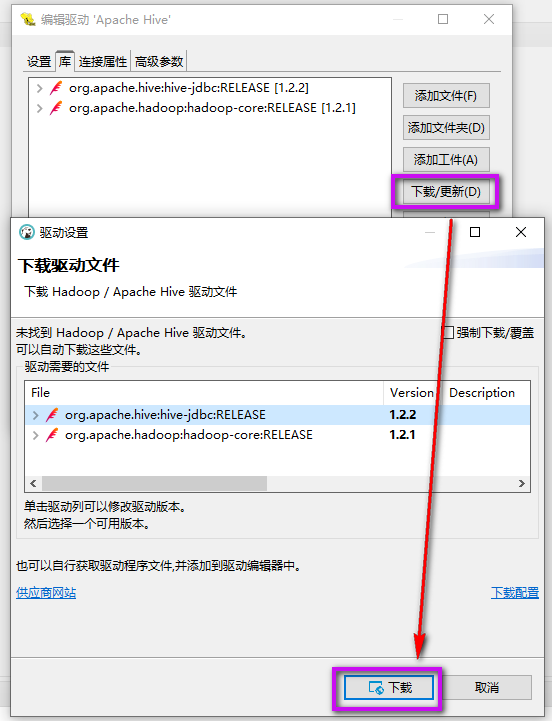
创建连接:
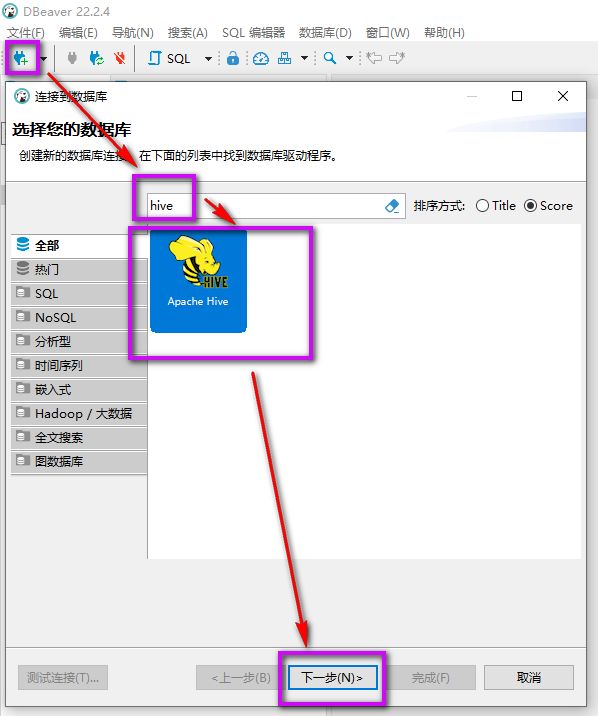
填写连接信息:

查询所有数据:
select * from default.t_gdp;
查询结果:

统计 2021 年每个省的 GDP:
select f_province,sum(f_gdp)
from t_gdp
where f_year='2021'
group by f_province;
查询结果:

可以用 DBeaver 连上 hive 的元数据库(MySQL - hive_metadata)看到元数据。
元数据-表名:

元数据-列名:
