3D目标检测——CLOCs论文学习笔记
CLOCs:Camera-LiDAR Object Candidates Fusion for 3D Object Detection
文章链接:https://www.researchgate.net/publication/344067087_CLOCs_Camera-LiDAR_Object_Candidates_Fusion_for_3D_Object_Detection
github:https://github.com/pangsu0613/CLOCs
文章是当前在后融合方面做到SOTA,为现有检测结果带来了涨点的思路,博主也是趁着调研的机会把论文和代码进行了阅读,算是把论文用自己的话翻译了一下,也希望可以在讨论中不断进步。
介绍
长距离的目标检测由于点云点稀疏等,无法保证很好的效果
因此MV3D的工作使人们看到了三种融合的未来前景,选择通过前、中、后三种融合方式进行信息的补充
前、中融合虽然能在理论上获得更好的综合信息,但是他们在数据的匹配中有难度,而且融合的结构会十分的复杂
这篇文章使用的后融合,能够在NMS之前,对图像检测和点云检测两个分支进行融合,降低冗余(FP)
优点:
- 普适性强,能够适用于任何一种预先训练的2D和3D检测网络;
- CLOCs is fast, leveraging sparse tensors with low memory footprint, which only adds less than 3ms latency for processing each frame of data on a desktop-level GPU
A.几何&语义信息
FP极大概率没有明确的bbox范围,
几何层面:微小的位姿变化有可能导致IoU减少
语义层面:避免在这个步骤使用阈值进行筛选,或者使用极小的阈值去筛选正负样本
B.网络结构

将2D和3D的detection candidates转换成稀疏的tensor,即图中蓝色框。
之后对这些稀疏的tensor中的非空元素进行2D卷积操作;(以什么为非空的界定呢)
最终,这个被操作之后的tensor通过最大值池化映射到 被学习对象——一个可能值图像当中。
1)输入的稀疏tensor表示
这一步将所有的2D&3D detection candidates转变成可以送入融合网络的表示:
2D转变成:

3D转变成:

最后一维是置信分数
很多正确的检测结果因为单传感器的局限性而被nms覆盖,舍去
因此本文重新对所有 detection candidates进行评估,从两个传感器的视角分别评估。
所以构建了一个kn4的tensor,其中k,n是2D和3D condidates 的数量,4是:
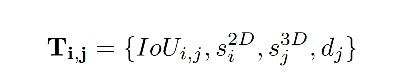
- 通道1: 2D和3D检测框的IoU;
- 通道2&3: 2D和3D检测框的置信度;
- 通道4: 在xy平面上,3D框和雷达的距离
当通道1 IoU为0时,整个tensor不计入考虑范围内:(但是这个有解决的tricks
c.网络细节:
融合网络是一系列 1*1 的2D卷积网络;
- Conv2D(4,18,(1,1),1) 输入通道,输出通道,kernel size,stride
- Conv2D(18,36,(1,1),1)
- Conv2D(36,36,(1,1),1)
- Conv2D(36,1,(1,1),1)
class fusion(nn.Module):
def __init__(self):
super(fusion, self).__init__()
self.name = 'fusion_layer'
self.corner_points_feature = Sequential(
nn.Conv2d(24,48,1),
nn.ReLU(),
nn.Conv2d(48,96,1),
nn.ReLU(),
nn.Conv2d(96,96,1),
nn.ReLU(),
nn.Conv2d(96,4,1),
)
self.fuse_2d_3d = Sequential(
nn.Conv2d(4,18,1),
nn.ReLU(),
nn.Conv2d(18,36,1),
nn.ReLU(),
nn.Conv2d(36,36,1),
nn.ReLU(),
nn.Conv2d(36,1,1),
)
self.maxpool = Sequential(
nn.MaxPool2d([200,1],1),
)
生成一个1 * p * 1的tensor,p是指稀疏tensor中为空的元素elements(每一层之后通过ReLU进行筛选,将<=0的值过滤掉)
之后可以构建一个k* n *1的输出tensor,将上面输出的p个tensor基于索引(i,j)第几个2D框与第几个3D框进行匹配
可以在其他地方随意的放置一系列 负无穷值 作为填充
最后,将这个tensor映射到一个目标:一个在第一个通道进行最大值池化的分数图像
大部分主要的代码都集成在了train.py中,相较于second来讲可读性提高了很多
D.loss:
交叉熵损失函数:
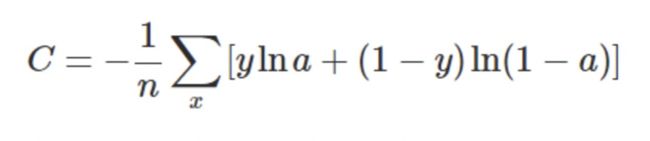
使用focal loss,调整参数以平衡差别很大的前后景;
E.training:
使用SGD进行融合网络的训练,
use the Adam optimizer with an initial learning rate of 3 * 10−3 and decay the learning rate by a factor of 0.8 for 15 epochs
结论:使用log类似的输出,更为简单有效
IoU十分重要,失去它2D3D之间的联系就消失了。for us,the IoU could be 100% or little less
3D 也十分重要,是重建置信度的重要依据。
d也很重要,更近的目标有更好的检测效果,