libtorch 异常处理汇总
1. 异常: c10::Error,位于内存位置 0x000000B9DA0FF2E0 处
(1)维度不对,操作范围了。卷积操作和全链接操作直接少了一个展平操作,即将特征图(b,c,h,w)展开成(b, c*h*w);
x = torch::flatten(x, 1); // start_dim = 1. (b, c*7*7)(2) 异常: c10::Error,位于内存位置 0x000000CC4BEFDB70 处。错误原因:在gpu上训练后,在cpu上测试,正确操作:
img_tensor = img_tensor.to(torch::kCUDA)2. CUDA error: invalid device ordinal
CUDA error: invalid device ordinal
Exception raised from exchangeDevice at C:\w\b\windows\pytorch\c10/cuda/impl/CUDAGuardImpl.h:31 (most recent call first):
00007FFAAB5CF84A00007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [ @ ]
00007FFAAB5CF4BA00007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [ @ ]
00007FFAAB5D023100007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [ @ ]
00007FFAAB5CFFC500007FFAAB5CEBE0 c10.dll!c10::detail::LogAPIUsageFakeReturn [ @ ] 原因,使用了错误的显卡序号,1号卡是失效的,改成0号卡即可:
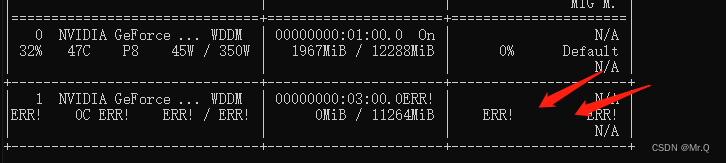
3. cu:108: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
报错的地方: loss.backward().
报错的原因:目标类别数是2,但是标注的类别是1,2,应该是从0开始,即标注类别是0和1,这样就符合t>= && t
4. 引发了异常: 读取访问权限冲突。
this->_Vec._Mypair._Myval2.**_Myfirst** 是 0x111011101110123。
场景:使用libtorch注册机制,register_module("conv1", conv1)
报错原因:注册机制支持release模型,debug模型会报错

编译时,改成release问题解决

5. 报错位置:return impl_->forward(::std::forward(args)...)
部分原因:data放到了cuda中,model子模块没有在cuda中。
mainModel.to(torch::kCUDA). 但是因为mainModel的子模块或者子模块的子模块没有使用register_module()函数注册,导致只有主函数会放置到cuda中,其子模块不会放置cuda中,导致莫名奇妙的错误。
其他原因也会导致此处出错。
异常: c10::Error,位于内存位置 0x0000009F715DA580 处。
6. 报错位置:// Copy `key` here and move it into the index.
报错位置:
// Copy `key` here and move it into the index.
items_.emplace_back(key, std::forward(value));
index_.emplace(std::forward(key), size() - 1); 原因: register_module注册时使用相同的类别名注册了不同的module。
register_module("model1", conv1);
register_module("model1", conv2);
解决办法:不同的模块也写不同的模块名称。
待续。。。