文本生成系列之transformer结构扩展(三)
每天给你送来NLP技术干货!
来自:NLP日志
作者:zelong
提纲
1 简介
2 Multi-Input Transformer
3 Multi-view BART
4 TSLF
5 VECO
6 BASS
7 总结
参考文献
1 简介
在前面两章中我们主要介绍了如何在embedding层中添加额外的embedding来适配特定任务以及如何降低attention中的平方复杂度,这两章内容都是针对常见的单个文本输入,但是如果遇到多个源输入的话,transformer又应该做哪些相应的调整呢?例如在多轮对话场景中,我们有历史对话,知识库内容,以及用户个性化设定,如果简单的把这几种源输入拼接在一起输入到transformer(常规做法),那就是把他们合并成单个文本输入了。但是我们知道这几部分源输入明显不同,应当有不同的方式处理,简单的拼接到一起后虽然能直接应用传统的单输入模型,但是效果上却会大打折扣,远不及经过改造后的支持多个输入的transformer模型。而且如果简单的把多个输入拼接到一起很容易就导致最终的输入超过模型的最大输入长度,这又是一个很难搞的问题。

图1:单输入模型跟多输入模型的区别
至于如何扩展transformer,使得它具备处理多种源输入的能力,就是本章节的主要内容了。我们会从几个不同场景去介绍如何扩展transformer,使它能够兼容多个输入,提高模型效果,缓解模型支持的最大长度问题。
2 Multi-Input Transformer
对于一个纯文本的开放域对话场景而言,它的输入可能包括几个部分
a) 来自于知识库的相关事实。
b) 历史对话
c) 用户个性化设定
我们知道支持单个输入的预训练transformer语言模型在诸多生成任务中表现亮眼,那么如何将单输入的transformer改造成支持多个输入的预训练模型以适配当下场景?基于此,支持多个输入的Multi-input transformer方法被提出, Multi-input transformers沿用的是GPT的结构,这里的Multi-input transformer用的是encoder-decoder结构就是将将GPT的结构复制后得到的,encoder跟decoder共享权重。这里的multi-input包括历史对话,用户的个性化设定和当前时刻已经生成的文本内容三个部分。这里的输入除了传统的分隔符还新增了空间分隔符,用于区分说话人的信息,与之对应地还在segment embedding的基础上引入更多相应的向量类型。历史对话跟个性化信息依次输入Encoder获得相应的表征作为decoder部分的输入,在decoder的时候计算attention会分别针对历史对话,个性化信息,当前状态计算三次,将三者的结果加起来求平均。这里多个输入都是分开处理的,极大的缓解模型支持输入长度限制的问题,另外encoder跟decoder的权重共享也减少了模型的参数量和兼顾多任务学习。
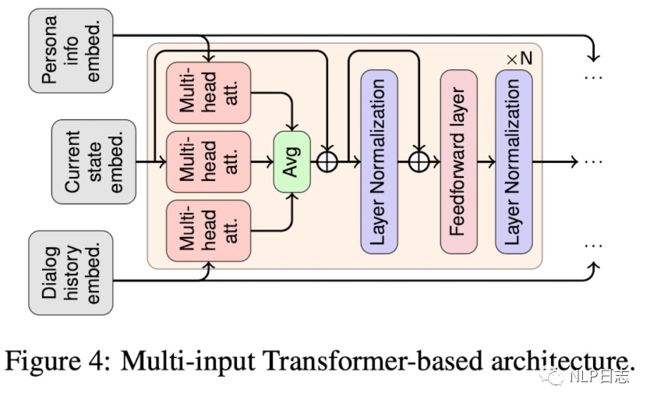
图2: Multi-Input Transformer的框架
跟单输入的transformer模型对比,Multi-input transformers在效果上有明显优势。(单输入的transformer使用的是GPT的结构,虽然参数量跟Multi-input transformers一样,但是层数少了一半,所以这样对比是不是不太公平?)Multi-input transformers这种方法主要的优化就是在decoder的部分计算attention会分别针对历史对话,个性化信息,当前状态计算三次,将三者的结果加起来求平均,这样就可以更加全面的考虑到这三部分的内容,生成更加合理的结果。
3 Multi-view BART
在文本摘要任务中,当对话历史愈发冗长的时候,在开始新对话之前去回顾之前的内容会变得非常挑战和耗时,所以怎么将之前的内容转变为简洁并且结构化的文本就显示格外重要。Multi-view BART首先根据不同视角将日常对话进行分块,不同的块聚焦于对话的不同方面,然后再利用一个多视角的decoder联合不同视角的内容去生成摘要。
我们从多个视角去解读对话并且每个视角都会驱使模型聚焦于对话的某个部分,所以可以根据不同视角将对话分块。例如图中的topic view,对话通常是可以根据一定主题组织起来的,实际使用中可以将对话里每句话都通过sentence BERT获得相应的表征,然后利用C99算法将这些句子按照topic分类。或者是stage view,为了让那个对话有意义并且可读,可以某种顺序去组织对话,实际使用中可以将对话里的每句话通过sentence BERT获得相应的表征,然后利用HMM的办法对这些话进行分类。最终分块的方式可以根据独立的某个view,也可以是多个view的组合方式。

图3: 对话里的多视角类型
通过上面的方式,原始的对话可以被分成多个块,然后以块为基本单位依次输入BART的encoder可以得到每一个token的表征,将每一块开始位置的表征作为块的表征,将得到的块的表征按顺序输入LSTM得到当前块的隐状态。Decoder的部分不同于之前的方式,这里引进了一个multi-head attention,这里会先决定每一个块的重要性,进而影响最终的attention结果。(这里我理解是原本的attention是计算当前时刻里encoder部分各个token的得分,这里在这个基础上还要考虑这个token所处的块的得分,也就是要综合考虑块跟token的得分)。这种多视角的方式可以给模型提供不同类型的对话内容去学习和决定哪个块的内容值得更多的关注从而生成更好的摘要。
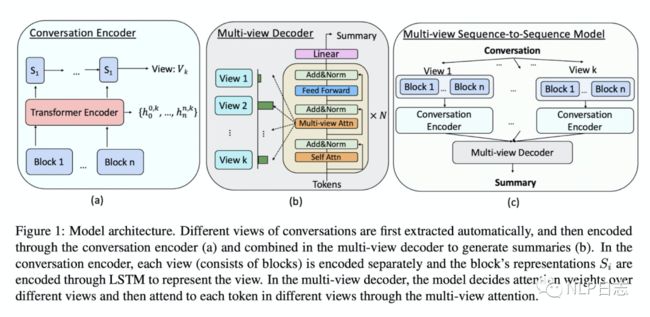
图4: Multi-view BART的框架
总结下这种方法,就是先将对话分块,然后在decoder的部分要考虑每个块的重要性,进而让模型关注更重要的内容,生成更好的摘要。
4 TSLF
在对话场景中引入外部知识库来生成通顺并且更具信息的回复目前看起来是一个有前景的方向,但现存的方法当迁移到一个训练数据有限的新领域都不仅费力而且表现糟糕。基于此,TSLF作为一种受益于大规模无监督数据和非结构化知识库的弱监督学习框架被提出来。
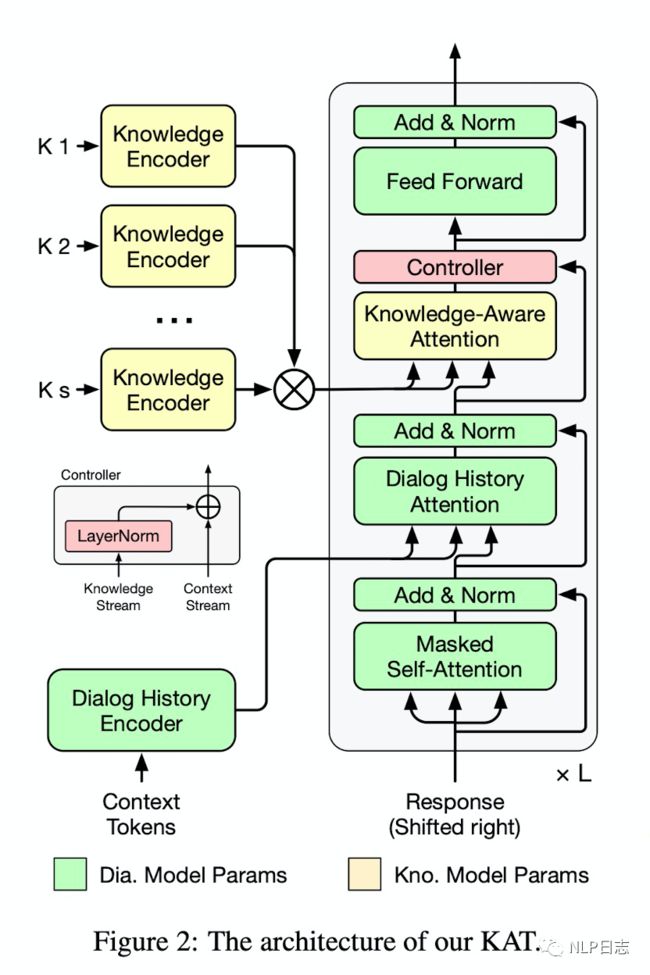
图五:TSLF的框架
TSLF沿用的是BART的encoder-decoder结构,encoder有两个,第一个负责对对话历史进行编码,生成相应的对话历史表征,第二个encoder负责对外部知识库里的文档进行编码,生成相应的表征。在decoder的部分,新增了一个Knowledge-Aware Attention和Controller,Knowledge-Aware Attention这里的query是上一个模块的输出(decoder部分中cross-attention的输出),key跟value都是第二个encoder生成的外部知识库的相关表征,通过这个模块,可以引入外部知识库的信息,让模型去选择合适的外部知识库的内容。而Controller类似于一个残差网络,就是汇总了Knowledge-Aware Attention模块的输入跟输出,防止有信息在这个地方损失了。
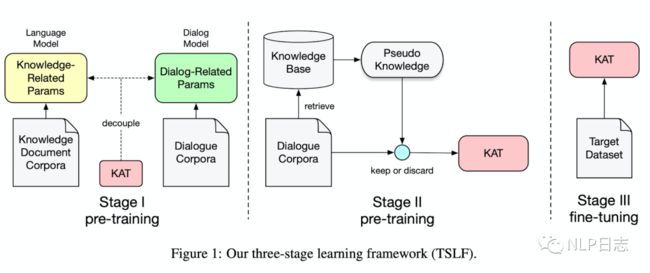
图6: TSLF训练过程
训练过程分为3个阶段。第一阶段是利用自回归任务去预训练第一个encoder跟decoder(除了新增的两个模块),同时利用一个MLM任务去预训练第二个decoder,第二阶段是利用弱监督学习在大规模数据上微调整个模型(这里的弱监督值得的训练数据是计算相似度得分构造的),第三个阶段是在低资源数据上对整个模型进行微调。
LSTF主要的优化是在decoder的部分新增一个用于attention模块,在这里引入了外部知识库的信息,从而迫使模式去利用外部知识库的信息去生成更加具有信息量的内容。
5 VECO
VECO的提出是为了在跨语言任务中搭建一个统一的框架,同时满足NLU跟NLG任务训练跟微调的任务需求。当前的NLU跟NLG预训练框架彼此分离,NLU任务通常使用transformer的encoder,而NLG通常使用transformer的encoder-decoder,没有考虑到这两种任务跟框架的关联。所以VECO通过一个选择性的cross attention模块(只在NLG任务时加进来),实现NLU跟NLG在同一个模型架构里完成训练,将这两种任务结合起来。
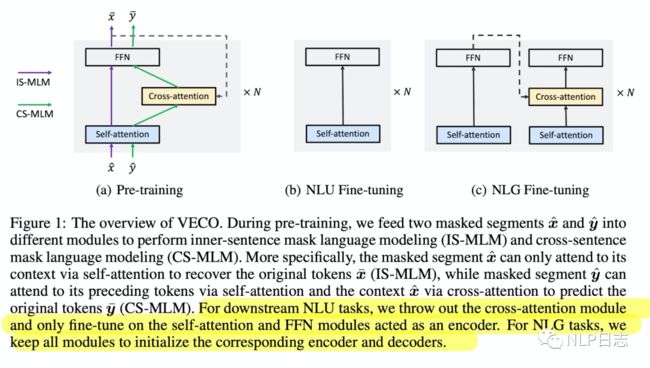
图7: VECO的框架
整个VECO是有多个同样的结构堆叠行程的,每一个基础单元包括三个模块self-attention, cross-attention跟FFN。预训练的语料分都是两种不同语言构成的pair对,所以预先训练的目标包括四个部分,两种语言独立的MLM任务,利用第一种语言来生成第二种语言的自回归任务和利用第二种语言来生成第一种语言的自回归任务。训练过程中单语种的MLM任务不会用到cross attention,只有多语言中的生成任务会用到cross attention,通过这种方式,可以将NLU跟NLG任务关联起来,联合训练。
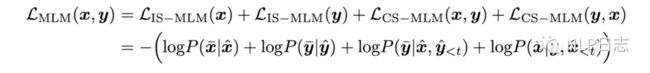
图8:VECO的目标函数
后续如果在NLU任务下微调,就只需要相应的self attention跟FFN模块,如果是在NLG任务下微调,就需要全部结构。最终在下游的NLU跟NLG任务上,VECO都取得优异的效果。
VECO引入一个可选择的cross attention模块,使得这个统一的框架可以同时支持NLU跟NLP任务,把这两个任务关联起来,得到更加强大的模型。
6 BASS
Seq2seq方法由于不擅长捕捉长距离的关系而在长文本摘要任务面临着挑战,为此,一种利用图来增强全局信息的transformer方法,BASS被提出。

图9:BASS的框架
利用图的方法首先需要构建图,这里构建图的过程需要用到现成的工具,比如CoreNLP,通过这些现成的工具,可以获得输入文本的依存句法树以及相应的指代消解信息,根据这些指代消解信息可以将不同的位置的短语合并到一起,得到相应的一个图。完成图的构建后就BASS就可以使用了,BASS首先利用一个文本encoder(得到输入文本的表征)这里用的是Roberta,扩展了模型的最大输入长度,同时这里的self-attention计算只能用到旁边token的信息,也就是local attention)。而后通过将这些token的表征作为图encoder的一个初始化(这里要注意,图的节点是有短语组成的,可能包含多个token,那就是用多个token的表征求平均作为它的初始表示),在这个过程中还会引入一个全局节点,用于学习全局表示,另外在更新节点表示时会根据two hop建立新的边,(可以简单理解,对于一个主谓宾结构,利用句法分析得到的图,主语跟谓语,谓语跟宾语之间都存在边,但是在这里利用two hop可以建立主语跟宾语之间的边)。通过encoder阶段,可以得到token的表征和对应的图的节点的表征。然后在decoder阶段,因为token表针更利于捕捉局部特征,而图的节点的表征更利于捕捉全局表征,所以这里的cross attention包括两部分,分别用token的表征和图节点的表征去计算,然后在融合两部分的结果,再去预测下一个token。
BASS通过引入图的方法来增强全局的表示,同时跟token的表征所蕴含的局部表示相结合,在decoder阶段能够利用到更加全面的信息,进而生成更加合理的内容。
7 总结
本章节的模型都是encoder-decoder结构,扩展后的模型都可以接受多个输入。encoder过程没太多变化(除了可能需要新增encoder对其他输入进行编码),但是decoder部分变得更加复杂多样,基本都是在cross attention分别计算多个输入的表征,去选择关注那个输入的内容,然后融合多个cross attention的结果,从而去生成更加合理且丰富的文本。
参考文献
1. (2022, Multi-Input Transformer) Large-Scale Transfer Learning for Natural Language Generation
https://aclanthology.org/P19-1608.pdf
2. (2020, Multi-view BART) Multi-View Sequence-to-Sequence Models with Conversational Structure for Abstractive Dialogue Summarization
https://arxiv.org/pdf/2010.01672v1.pdf
3. (2021, TSLF) A Three-Stage Learning Framework for Low-Resource Knowledge-Grounded Dialogue Generation
https://arxiv.org/pdf/2109.04096.pdf
4. (2020, VECO) VECO: Variable and Flexible Cross-lingual Pre-training for Language Understanding and Generation
https://arxiv.org/pdf/2010.16046v1.pdf
5. (2021, BASS) BASS: Boosting Abstractive Summarization with Unified Semantic Graph
https://arxiv.org/pdf/2105.12041v1.pdf
最近技术文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!