pytorch用自己数据训练VGG16
一、VGG16的介绍
VGG16是一个很经典的特征提取网络,原来的模型是在1000个类别中的训练出来的,所以一般都直接拿来把最后的分类数量改掉,只训练最后的分类层去适应自己的任务(又叫迁移学习),这种做法为什么有用呢,可能是自然界中的不同数据,分布具有相似性吧。
本文不打算这么干,本文将修改一下vgg的网络自己重新训练。
先看看VGG的原生网络
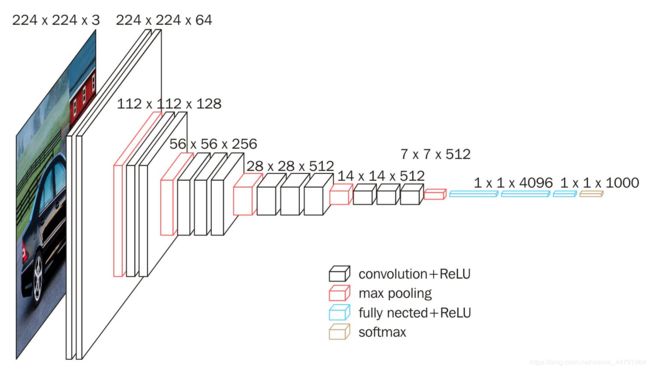
特点:
1.网络结构及其简单清晰,五层卷积+三层全连接+softmax分类,没有其他结构。
2.卷积层全部用3*3的卷积核,三个3*3的卷积核相当于一个7*7的卷积核获得的感受野,这样既获得了较大的感受野,也减少了参数量。
二、模型定义
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
from torchsummary import summary
class VggNet(nn.Module):
def __init__(self, num_classes=1000):
super(VggNet,self).__init__()
self.Conv = torch.nn.Sequential(
# 3*224*224 conv1
torch.nn.Conv2d(3, 64, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(64, 64, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2, stride = 2),
# 64*112*112 conv2
torch.nn.Conv2d(64, 128, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(128, 128, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2, stride = 2),
# 128*56*56 conv3
torch.nn.Conv2d(128, 256, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(256, 256, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2, stride = 2),
# 256*28*28 conv4
torch.nn.Conv2d(256, 512, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size = 2, stride = 2))
# 512*14*14 conv5
# torch.nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1),
# torch.nn.ReLU(),
# torch.nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1),
# torch.nn.ReLU(),
# torch.nn.Conv2d(512, 512, kernel_size = 3, stride = 1, padding = 1),
# torch.nn.ReLU(),
# torch.nn.MaxPool2d(kernel_size = 2, stride = 2))
# 512*7*7
self.Classes = torch.nn.Sequential(
torch.nn.Linear(14*14*512, 1060),
torch.nn.ReLU(),
torch.nn.Dropout(p = 0.5),
torch.nn.Linear(1060, 1060),
torch.nn.ReLU(),
torch.nn.Dropout(p = 0.5),
torch.nn.Linear(1060, num_classes))
def forward(self, inputs):
x = self.Conv(inputs)
x = x.view(-1, 14*14*512)
x = self.Classes(x)
return x
if __name__ == "__main__":
model = VggNet(num_classes=1000)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
summary(model, (3, 224, 224))
这里我们只用四个卷积层就够了,且减少了fc层的神经单元数量,目标是完成十分类。
三、准备数据
本次所用数据为网络上开源数据,来源于和鲸社区https://www.heywhale.com/home/dataset
全部为车的图片,一共分为10个类别,训练集和验证集分开,训练集1410张图片,验证集210张图片。


pytorch里读取数据到内存一般是继承一个dataset类,然后重写三个函数。具体操作过程是根据数据集的形式进行变化的。
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms as T
import matplotlib.pyplot as plt
import os
from PIL import Image
import numpy as np
class Car(Dataset):
def __init__(self, root, transforms=None):
imgs = []
for path in os.listdir(root):
if path == "truck":
label = 0
elif path == "taxi":
label = 1
elif path == "minibus":
label = 2
elif path == "fire engine":
label = 3
elif path == "racing car":
label = 4
elif path == "SUV":
label = 5
elif path == "bus":
label = 6
elif path == "jeep":
label = 7
elif path == "family sedan":
label = 8
elif path == "heavy truck":
label = 9
else:
print("data label error")
childpath = os.path.join(root, path)
for imgpath in os.listdir(childpath):
imgs.append((os.path.join(childpath, imgpath), label))
self.imgs = imgs
if transforms is None:
normalize = T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.transforms = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
normalize
])
else:
self.transforms = transforms
def __getitem__(self, index):
img_path = self.imgs[index][0]
label = self.imgs[index][1]
data = Image.open(img_path)
if data.mode != "RGB":
data = data.convert("RGB")
data = self.transforms(data)
return data,label
def __len__(self):
return len(self.imgs)
if __name__ == "__main__":
root = "/home/elvis/workfile/dataset/car/train"
train_dataset = Car(root)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
for data, label in train_dataset:
print(data.shape)
pass这里注意的是,在给数据label时不能直接进行ont-hot编码,因为在多分类任务中,pytorch后续会自己做这个工作,所以对于多分类,只需要label为单个标签就好了。
四、训练
数据准备好,网络定义好,然后就可以定义超参数去进行训练了。
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
from network import VggNet
from car_data import Car
# 1. prepare data
root = "/home/elvis/workfile/dataset/car/train"
train_dataset = Car(root)
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
root_val = "/home/elvis/workfile/dataset/car/val"
val_dataset = Car(root_val)
val_dataloader = DataLoader(val_dataset, batch_size=32, shuffle=True)
# 2. load model
model = VggNet(num_classes=10)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 3. prepare super parameters
criterion = nn.CrossEntropyLoss()
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 4. train
val_acc_list = []
for epoch in range(300):
model.train()
train_loss = 0.0
for batch_idx, (data, target) in enumerate(train_dataloader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.item()
# val
model.eval()
correct=0
total=0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(val_dataloader):
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, dim=1)
total += target.size(0)
correct += (predicted==target).sum().item()
acc_val = correct / total
val_acc_list.append(acc_val)
# save model
torch.save(model.state_dict(), "last.pt")
if acc_val == max(val_acc_list):
torch.save(model.state_dict(), "best.pt")
print("save epoch {} model".format(epoch))
print("epoch = {}, loss = {}, acc_val = {}".format(epoch, train_loss, acc_val))
在写网络时之所以没有定义softmax,就是因为在nn.CrossEntropyLoss()函数里已经集成了softmax,且进行了one-hot处理。刚开始学习率定义的是1e-3,但训练时loss发散了,改为1e-4后loss就收敛了。
最终的训练结果为:

虽然loss已经下降到比较小了,但验证集的准确率依旧上不去,只有0.615,究其原因,应该是数据量太少(只有1k+),而对于vgg这么大的网络,这么少的数据应该是出现了过拟合。
五、迁移学习进行训练
用vgg16别人训练好的的权重去初始化网络权重。这里直接调用torchvision里封装的vgg16就好了,pretrained=True表示使用预训练模型(别人在更大的数据集上训练好的模型)初始化权重。只需要改变网络的定义文件,其他都不用变,网络定义更改为:
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
from torchsummary import summary
from torchvision import models
class VGGNet_Transfer(nn.Module):
def __init__(self, num_classes=10): #num_classes,此处为 二分类值为2
super(VGGNet_Transfer, self).__init__()
net = models.vgg16(pretrained=True) #从预训练模型加载VGG16网络参数
net.classifier = nn.Sequential() #将分类层置空,下面将改变我们的分类层
self.features = net #保留VGG16的特征层
self.classifier = nn.Sequential( #定义自己的分类层
nn.Linear(512 * 7 * 7, 512), #512 * 7 * 7不能改变 ,由VGG16网络决定的,第二个参数为神经元个数可以微调
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 128),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(128, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
最终的训练结果为:
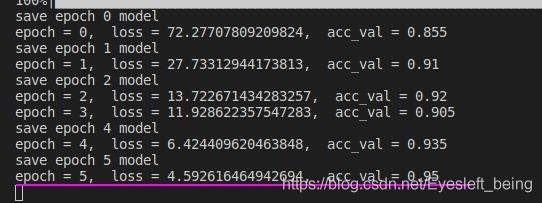
可以看到loss下降的很快,在epoch=5时,验证集准确率就上升到了0.95,效果是很好的。这也再再次验证了我们之前的猜想,如果自己训练,数据很少,过拟合了,验证集表现很差。