数据不动模型动-联邦学习的通俗理解与概述
关注公众号,发现CV技术之美
联邦学习是一种机器学习设定,其中许多客户端(例如:移动设备或整个组织)在中央服务器(例如:服务提供商)的协调下共同训练模型,同时保持训练数据的去中心化及分散性。联邦学习的长期目标则是:在不暴露数据的情况下分析和学习多个数据拥有者(客户端或者独立的设备)的数据。
进一步而言,联邦学习可定义为:Federated Learning = Collaborative Machine Learning without Centralized Training Data(没有集中训练数据的协作机器学习)[1],将机器学习的能力与将数据存储在云中的需求进行分离。
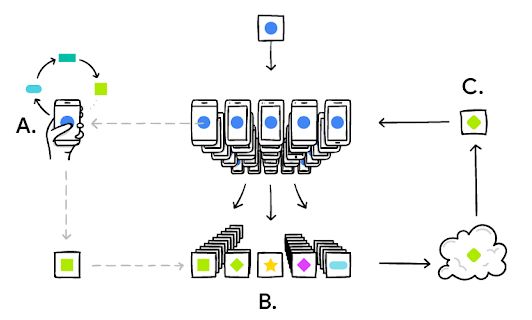
图1:Google联邦学习框架图(链接[1])
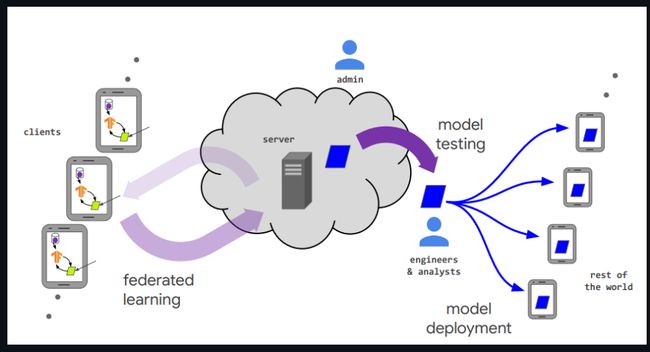
图2:Federated Learning Survey(链接[2])
接下来我们将从联邦学习中的挑战和未来进展剖析联邦学习。
▊ 联邦学习中的挑战
1. Expensive Communication:联邦学习可能由大量设备(例如数百万部智能手机)组成,网络中的通信可能比本地计算慢许多数量级;网络中的通信可能比传统数据中心环境中的通信昂贵得多;为了使模型更适合联邦网络,因此有必要开发出通信高效的方法,在训练过程中迭代发送小消息或模型更新,而不是通过网络发送整个数据集。
通信是在开发联邦网络的方法时需要考虑的一个关键瓶颈:具体而言,可分为以下三种解决方法:
(1)local updating methods本地更新方法;
(2)compression schemes压缩方法;
(3)decentralized training分布式训练。
local updating methods:如下图所示,通过局部小批量更新可以降低通信代价,在每一轮通信中并行地在每台机器上应用可变数量的本地更新,从而使计算量与通信相比更加灵活。
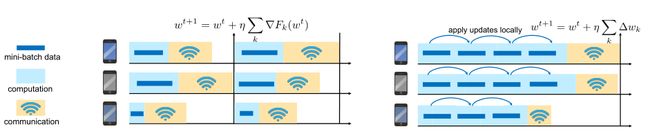
图3:关于多次局部小批次更新示意图(链接[3])
compression schemes:通常而言,稀疏化、子采样和量化等模型压缩方案可以显著减少每一轮通信的消息的大小;但是在联邦学习环境中,设备的低参与度、Non-IID的本地数据和本地更新方案对这些模型压缩方法提出了新的挑战。
然而,一些工作在联邦学习中提供了实用的策略:迫使设备与服务器间更新的模型具有稀疏性和低秩性,并使用使用结构化随机旋转进行量化(Federated learning: strategies for improving communication efficiency)、使用有损压缩和Dropout技术来减少服务器到设备之间的通信(Expanding the reach of federated learning by reducing client resource requirements)。
decentralized training:在数据中心环境中,当在低带宽或者高延迟的网络上运行时,分散训练已被证明比集中训练更快;类似地,在联邦学习中,分散的算法在理论上可以降低设备与中心服务器之间的高通信成本。有研究提出,分层通信模式,以进一步减轻中心服务器的负担,首先利用边缘服务器聚合来自边缘设备的更新,然后依赖云服务器聚合来自边缘服务器的更新。

图4:关于集中式与分散式训练示意图(链接[3])
2. Systems Heterogeneity:由于硬件、网络连接和电源电量的差异,联邦网络中每个设备的存储、计算和通信能力可能会有所不同;此外每个设备上的网络规模和系统相关限制通常会导致只有一小部分设备同时处于活动状态,例如在数百万设备网络中可能只有数百台设备处于活动状态;同时每个设备也可能不可靠,活动设备在给定的迭代中退出的情况并不少见。
基于上述问题,系统异构性层面的解决方法大致可以分为如下所示:
(1)异步通信;
(2)主动设备采样;
(3)容错机制。
Asynchronous Communication:虽然异步参数服务器在分布式数据中心中取得了成功,但经典的有界延迟假设在联邦设置中可能是不现实的,其中延迟可能在数小时到数天或完全无界,因此需要设计出基于异步通信针对设备层面的联邦学习算法。
Active Sampling:在联邦网络中,通常只有一小部分设备参与每轮训练,为了减少系统异构性的影响,我们可以在每一轮中主动选择参与设备。但是,如何扩展这些方法以处理实时的、特定于设备的计算和通信延迟波动仍然是还未解决的。
Fault Tolerance:当在远程设备上学习时,容错机制变得更加关键,因为一些参与设备在给定训练迭代完成之前的某个时间点退出是很常见的。一种实用的策略是简单地忽略此类设备故障,但是可能会引入偏差,经过训练的联邦模型将偏向具有良好网络条件的设备。
3. Statistical Heterogeneity:设备经常以不同的方式在网络中生成和收集数据:例如预测移动电话用户的下一个单词任务中用户在上下文中可能会使用不同的语言。此外跨设备之间的数据数量可能会有很大差异,并且获取设备及其相关分布之间的关系结构或许很难;这种数据生成范式违背常用的独立同分布假设,并可能增加建模、分析和评估方面的复杂性。
当从设备上分布不相同的数据中训练联邦模型时,就会出现统计异构性的挑战,其中比较有效的则是对异构数据进行建模。在机器学习中有大量的文献通过元学习和多任务学习等方法来建模统计异质性,这些想法最近被扩展到联邦设置:
1)通过学习每个设备独立但相关的模型来实现个性化,同时通过多任务学习共享表示(Federated multi-task learning);
2)在一些共享的代理数据上集中训练一个全局模型后,通过运行FedAvg来探索个性化的迁移学习(Federated learning with non-iid data)。
▊ 联邦学习中的未来进展
基于此前提出的挑战,首先在通信方面提出:
1)Extreme communication schemes 极端通信方案:最近,一次性或者少量的启发式通信方案最近被提出作为联邦学习通信方面的设置;
2)Communication reduction 减少通信:在联邦训练中减少通信的几种方法,如本地更新和模型压缩(梯度压缩和量化方法),进一步考虑的是,在相同的通信预算下实现比任何其他方法更大的精度;
其次,在数据层面提出:
1)Self-supervised learning 自监督学习:现实的联邦网络中生成的许多数据可能是未标记的或弱标记的,在联邦网络中解决监督学习之外的问题可能需要解决可伸缩性、异质性和隐私方面的类似挑战;
2)个性化算法:对于单个客户端可用的Non-IID数据分布下的完全分散方案,一项重要任务是设计用于学习个性化模型集合的算法。
▊ 总结
从广义上来说,联邦学习更像是某一类问题或需求的总称:在确保数据隐私的基础下,如何联合多个数据拥有方共同训练出更好的模型;狭义上来说则是指:一类基于客户-服务器的特定算法,通过仅仅暴露出某些中间信息来换取更高效率、模型精度以及安全的隐私保护算法。
就当前来看,主要还是聚焦于联邦学习中Non-IID数据的处理策略(个性化、设计异构算法、基于多任务/元学习、用户选择与聚类)、通信效率优化(剪枝+量化,与知识蒸馏结合的文章也有许多,知识蒸馏/迁移学习+联邦学习是热点)与降低联邦网络训练能耗方向。
个人研究方向是基于Non-IID的联邦学习算法设计,现在就主要就该问题进行一些深入,希望可以给大家带来一些新的idea。Non-IID指的是:变量之间非独立,或者非同分布(由于联邦学习特殊的场景,每个设备不可能完全一样,因此其设备上的数据往往是非同分布的)。每个用户本地的数据分布会随着用户所在地以及用户偏好而变动。
如何降低Non-IID带来的模型精度下降/不稳定/泛化能力差等缺点,即怎么才能减少联邦学习中异构性带来的模型影响?我觉得主要可以从四个方面来看:
1)个性化联邦学习;
2)异构联邦学习;
3)多任务及元学习;
4)用户选择和聚类。
1)个性化联邦学习:由于用户数据的高度Non-IID以及用户对模型性能要求的不一致,单个的Global model很难满足所有参与者的需求,因此需要采用一种个性化的方法使得Global model针对每个用户进行优化。
从本质上来说,个性化联邦学习的方案将Non-IID作为联邦学习的一种优点,因为这些Non-IID数据能够提供用户独特的使用习惯和属性,不同用户能够通过本地数据的差异得到更适合自己的训练模型。
该文章(链接[4])提出了一种用于个性化联邦学习的超网络,在这种方法中,训练一个中央超网络模型,用来给每个客户生成模型,具有生成多样化个性化模型的能力。
另一篇文章(链接[5])主要思想是对于本地模型,在原来传统方法(例如FedAvg算法:链接[6])的基础上加了一个正则项,使其满足全局模型和本地模型间的平衡。
总结下来思路都是一个:全局模型作为基础,再利用每个独立的设备(客户端)上个性化的数据再来微调模型(或者理解为加上客户端自身数据的某些先验知识)。
2)异构联邦学习:在联邦学习中一直以来存在不同参与设备间通信、计算和存储性能的差异(系统异构);数据分布、数据量的差异(统计异构);对不同环境、不同任务间所需建模的差异(模型异构)。异构联邦学习的方案是在模型层面减少因Non-IID数据导致的权重差异对全局收敛的影响,在算法步骤中通过各种方式减少模型间的差异。
近期论文将联邦学习和知识蒸馏进行了结合,例如(链接[7])提出了一种解决异构FL的无数据知识蒸馏方法,其中服务器学习轻量级生成器以无数据的方式集成用户信息,然后将其广播给用户,使用所学知识作为归纳偏差改进模型。异构联邦学习主要是算法层面,可以通过改变模型结构,或者在客户端/服务器端训练过程中添加一些操作来改进模型。
3)多任务及元学习:多任务学习以及元学习在面对Non-IID数据的时候非常有效,其性能甚至可能超过最好的全局共享模型。因为元学习其在数据量较少的情况下也可以发挥出较为稳定精确的性能。
就多任务学习而言,如果我们将每个客户(设备)的本地问题(本地数据集上的学习问题)视为一项单独的任务(而不是单个数据集的一个划分),在多任务学习中,训练过程的结果是每个任务得到一个模型,这样通过对模型进行集成后的精度肯定高于原始模型。
4)用户选择和聚类:用户选择与聚类在联邦学习中也有所研究。通过用户聚类可以将相似数据的用户进行聚合,再通过用户选择抽取具有代表性的用户进行训练。一方面能够减少所有用户参与训练过程中造成的大量通信成本,另一方面也能剔除异常用户,减少被恶意攻击的风险。
具体应用而言,例如该论文(链接[8])则是在用户选择中引入了聚类抽样(选择+抽样,可运用到联邦学习中的设备采样阶段),并证明了聚类抽样能提高用户的代表性,并减少不同客户权重聚合时的差异。
参考文献
[1] https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
[2] Analyzing Federated Learning through an Adversarial Lens.
论文链接:https://arxiv.org/abs/1811.12470
[3] Federated Learning:Challenges, Methods, and Future Directions.
论文链接:https://arxiv.org/abs/1908.07873
[4] Personalized Federated Learning using Hypernetworks.
论文链接:https://arxiv.org/abs/2103.04628
[5] Ditto Fair and Robust Federated Learning Through Personalization.
论文链接:https://arxiv.org/abs/2012.04221
[6] Communication-Efficient Learning of Deep Networks from Decentralized Data.
论文链接:https://arxiv.org/abs/1602.05629
[7] Data-Free Knowledge Distillation for Heterogeneous Federated Learning.
论文链接:https://arxiv.org/abs/2105.10056
[8] Clustered Sampling: Low-Variance and Improved Representativity for Clients Selection in Federated Learning.
论文链接:https://arxiv.org/abs/2105.05883

END
欢迎加入「计算机视觉」交流群备注:CV
