李沐动手学深度学习v2-目标检测中的锚框和代码实现
一.目标检测中的锚框
前提:
本节锚框代码实现,使用了很多Pytorch内置函数,如果有对应函数看不懂的地方,可以查看前面博客对相应函数的具体解释,如下链接所示:
- Pytorch中torch.meshgrid()函数解析
- Pytorch中torch.stack() 函数解析
- Pytorch中torch.cat()函数解析
- Pytorch中tensor.T(torch.T)解析
- Pytorch中torch.repeat()函数解析
- Pytorch中torch.repeat_interleave()函数解析
- Pytorch中torch.unsqueeze()和torch.squeeze()函数解析
- Pytorch中torch.sort()和torch.argsort()函数解析
- Pytorch中torch.max()函数解析
- Pytorch中[:,None]的用法解析
- Pytorch中torch.argmax()函数解析
- Pytorch中torch.nonzero()函数解析
- Pytorch中torch.full(),torch.ones()和torch.zeros()函数解析
- Pytorch中torch.numel(),torch.shape,torch.size()和torch.reshape()函数解析
- Pytorch中的广播机制(Broadcast)
- Pytorch中的广播机制(Broadcast)
1. 概念
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)。 不同的模型使用的区域采样方法可能不同。 这里介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框,这些边界框被称为锚框(anchor box)。
2. 生成多个不同形状的锚框
2.1 假设输入图像的高度为 h h h,宽度为 w w w,以图像的每个像素为中心生成不同形状的锚框:缩放比为 s ∈ ( 0 , 1 ] s\in (0, 1] s∈(0,1],宽高比为 r > 0 r > 0 r>0。那么锚框的宽度和高度分别是 w s r ws\sqrt{r} wsr和 h s / r hs/\sqrt{r} hs/r。注意当锚框中心位置给定时,已知宽和高的锚框是确定的。
2.2 要生成多个不同形状的锚框,需要设置许多缩放比(scale)取值 s 1 , … , s n s_1,\ldots, s_n s1,…,sn和许多宽高比(aspect ratio)取值 r 1 , … , r m r_1,\ldots, r_m r1,…,rm。当使用这些比例和长宽比的所有组合以每个像素为中心时,输入图像将总共有 w h n m whnm whnm个锚框。尽管这些锚框可能会覆盖所有真实边界框,但计算复杂性很容易过高。在实践中,只考虑包含 s 1 s_1 s1或 r 1 r_1 r1的组合:
( ( s 1 , r 1 ) , ( s 1 , r 2 ) , … , ( s 1 , r m ) , ( s 2 , r 1 ) , ( s 3 , r 1 ) , … , ( s n , r 1 ) . (s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1). (s1,r1),(s1,r2),…,(s1,rm),(s2,r1),(s3,r1),…,(sn,r1).)
也即是以同一像素为中心的锚框的数量是 n + m − 1 n+m-1 n+m−1。对于整个输入图像,我们将共生成 w h ( n + m − 1 ) wh(n+m-1) wh(n+m−1)个锚框。
上述生成锚框的方法在下面的multibox_prior()函数中实现,指定输入图像、尺寸列表和宽高比列表,然后此函数将返回所有像素的锚框。
import torch
import d2l.torch
torch.set_printoptions(2) # 精简输出精度
"""生成以每个像素为中心具有不同形状的锚框"""
def multibox_prior(data,sizes,ratios):
#图片的高和宽
in_height,in_width=data.shape[-2:]
device,num_sizes,num_ratios = data.device,len(sizes),len(ratios)
tensor_sizes,tensor_ratios = torch.tensor(sizes,device=device),torch.tensor(ratios,device=device)
#每个像素点pixel的锚框数
boxes_per_pixel = (num_sizes+num_ratios-1)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的的高为1且宽为1,我们选择偏移我们的中心0.5
offset_w,offset_h = 0.5,0.5
#把图片高和宽归一化(缩放)到1
steps_h,steps_w = 1.0/in_height,1.0/in_width # 在y轴上缩放步长,在x轴上缩放步长
'''生成锚框的所有中心点'''
#生成0.5/in_height到(in_height+0.5)/in_height之间高度的刻度值,代表y轴
center_h = (torch.arange(in_height,device=device)+offset_h) * steps_h
#生成0.5/in_width到(in_width+0.5)/in_width之间宽度的刻度值,代表x轴
center_w = (torch.arange(in_width,device=device)+offset_w) * steps_w
#生成网格,shift_y中行相等,列不等,shift_x中行不等,列相等,行的个数为center_h的元素个数,列的个数为center_w的元素个数
shift_y,shift_x = torch.meshgrid(center_h,center_w,indexing='ij')
#shift_y,shift_x都reshape成一维,维数为:in_height*in_width
shift_y = shift_y.reshape(-1)
shift_x = shift_x.reshape(-1)
'''每个中心点都将有“boxes_per_pixel”个锚框,所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次'''
# 取(shift_x,shift_y,shift_x,shift_y)相应元素组成一行,因此一行有四个元素,然后将这一行直接复制boxes_per_pixel次,表示一个像素点的坐标(4维,因为用于后面计算左上右下的坐标)复制boxes_per_pixel次(因为需要生成boxes_per_pixel)锚框,out_grid.size=(561x728x5,4)
out_grid = torch.stack((shift_x,shift_y,shift_x,shift_y),dim=1).repeat_interleave(boxes_per_pixel,dim=0)
'''生成“boxes_per_pixel”个高和宽,之后用于创建锚框的四角坐标(x_min,y_min,x_max,y_max)'''
#生成锚框的w,有boxes_per_pixel个锚框,因此有boxes_per_pixel个锚框的宽
anchors_w = torch.cat((tensor_sizes*torch.sqrt(tensor_ratios[0]),tensor_sizes[0]*torch.sqrt(tensor_ratios[1:])))*in_height/in_width
#生成锚框的h,有boxes_per_pixel个锚框,因此有boxes_per_pixel个锚框的高
anchors_h = torch.cat((tensor_sizes/torch.sqrt(tensor_ratios[0]),tensor_sizes[0]/torch.sqrt(tensor_ratios[1:])))
#每一行代表一个像素点的锚框的高和宽,因为一个像素点有boxes_per_pixel个锚框,因此每boxes_per_pixel行代表一个像素的所有锚框。因为所有像素点的锚框个数和高宽都是一样的,因此需要复制in_height*in_width次,所以anchor_manipulations.size=(5x561x728,4)
anchor_manipulations = torch.stack((-anchors_w,-anchors_h,anchors_w,anchors_h)).T.repeat(in_height*in_width,1)/2 #除以2来获得半高和半宽
#因此out_grid与anchor_manipulations相加得到一个像素点中一个锚框的左上,右下的坐标,因此每boxes_per_pixel行代表一个像素点的所有锚框的左上,右下坐标值,也相当于生成所有像素点的所有锚框
output = out_grid+anchor_manipulations
#output新增一个维度
return output.unsqueeze(0)
multibox_prior()函数里面一些变量如下图所示,可以用于理解。注意size指的是图像长宽的缩放比例而非图像面积的缩放比例,ratio是指锚框的宽高比,指的是将原图像归一化为正方形后截取的锚框的宽高比,或者说是在原图像的宽高比基础上乘以ratio,才是真正的锚框的宽高比。上面代码中计算anchors_w时为什么需要再乘以(in_height/in_width),原因参考下面链接:
- 计算anchors_w乘以(in_height/in_width)原因
- 计算anchors_w乘以(in_height/in_width)原因

2.3 返回的锚框变量output的形状是(批量大小,锚框的数量,4)。
img = d2l.torch.plt.imread('../images/catdog.jpg')
h,w = img.shape[:2]
data = torch.rand(size=(1,3,h,w))
output = multibox_prior(data,sizes=[0.75,0.5,0.25],ratios=[1,2,0.5])
#返回的锚框变量output的形状是(批量大小,锚框的数量,4)。
print(output.shape)
print(h,w)
输出结果如下:
torch.Size([1, 2042040, 4])
561 728
2.4 将锚框变量Y的形状更改为(图像高度,图像宽度,以同一像素为中心的锚框的数量,4)后,可以获得以指定像素的位置为中心的所有锚框,访问以(250,250,0,:)为中心的第一个锚框 ,它有四个元素:锚框左上角的 (,) 轴坐标和右下角的 (,) 轴坐标,将两个轴的坐标各分别除以图像的宽度和高度后,所得的值介于0和1之间。
boxes = output.reshape(h,w,5,4)
boxes[250,250,0,:]
输出结果如下:
tensor([0.06, 0.07, 0.63, 0.82])
2.5 show_bboxes()函数用来显示以图像中某个像素为中心的所有锚框
def show_bboxes(axes,bboxs,labels=None,colors=None):
def _make_list(obj,default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj,(list,tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors,['b','g','r','m','c'])
for i,bbox in enumerate(bboxs):
color = colors[i % len(colors)]
rect = d2l.torch.bbox_to_rect(bbox.detach().numpy(),color)
axes.add_patch(rect)
if labels and len(labels)>i:
test_color = 'k' if color=='w' else 'w'
axes.text(rect.xy[0],rect.xy[1],labels[i],va='center',ha='center',
fontsize=9,color=test_color,bbox=dict(facecolor=color,lw=0))
2.6 变量boxes中 轴和 轴的坐标值已分别除以图像的宽度和高度,绘制锚框时,需要恢复它们原始的坐标, 因此下面定义了变量bbox_scale,下面代码可以绘制出图像中所有以(250,250)为中心的锚框。
d2l.torch.set_figsize()
bbox_scale = torch.tensor((w,h,w,h))
fig = d2l.torch.plt.imshow(img)
show_bboxes(axes=fig.axes,bboxs=boxes[250,250,:,:]*bbox_scale,labels=['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
's=0.75, r=0.5'])

3.交并比(IoU)
如果已知目标的真实边界框,使用杰卡德系数(Jaccard)衡量锚框和真实边界框之间的相似性。给定集合 A \mathcal{A} A和 B \mathcal{B} B,他们的杰卡德系数是他们交集的大小除以他们并集的大小:
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ . J(\mathcal{A},\mathcal{B}) = \frac{\left|\mathcal{A} \cap \mathcal{B}\right|}{\left| \mathcal{A} \cup \mathcal{B}\right|}. J(A,B)=∣A∪B∣∣A∩B∣.
对于两个边界框,我们通常将它们的杰卡德系数称为交并比(intersection over union,IoU),即两个边界框相交面积与相并面积之比,如下图所示。交并比的取值范围在0和1之间:0表示两个边界框无重合像素,1表示两个边界框完全重合。后面使用交并比来衡量锚框和真实边界框之间、以及不同锚框之间的相似度。
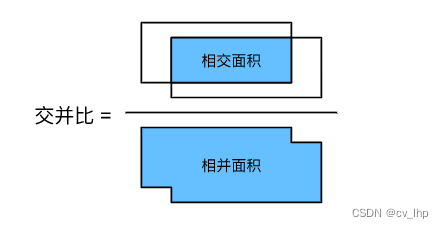
给定两个锚框或边界框的列表,以下boxes_iou函数将在这两个列表中计算它们成对的交并比。
"""计算两个锚框或边界框列表中成对的交并比"""
def boxes_iou(boxes1,boxes2):
box_area = lambda boxes : (boxes[:,2]-boxes[:,0])*(boxes[:,3]-boxes[:,1])
'''
boxes1,boxes2,areas1,areas2的形状:
boxes1:(boxes1的数量,4),
boxes2:(boxes2的数量,4),
areas1:(boxes1的数量,),
areas2:(boxes2的数量,)
'''
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
'''
inter_upperlefts,inter_lowerrights,inters的形状:
(boxes1的数量,boxes2的数量,2)
'''
#计算相交面积中的左上点的坐标
inner_upperlefts = torch.max(boxes1[:,None,:2],boxes2[:,:2])
#计算相交面积中的右下点的坐标
inner_lowrights = torch.min(boxes1[:,None,2:],boxes2[:,2:])
#求出相交面积的宽和高,并且宽和高最小值必须大于0,因此加上clamp(min=0)函数表示将两个锚框不相交的宽和高赋值为0
inners = (inner_lowrights-inner_upperlefts).clamp(min=0)
'''
inter_areas和union_areas的形状:(boxes1的数量,boxes2的数量)
'''
#求出相交部分的面积,不相交面积为0
inner_areas = inners[:,:,0]*inners[:,:,1]
#求出两个锚框面积的并集
union_areas = areas1[:,None]+areas2-inner_areas
#求出面积的交并比
return inner_areas/union_areas
4. 在训练数据中标注锚框
在训练集中,将每个锚框视为一个训练样本。为了训练目标检测模型,需要每个锚框的类别(class)和偏移量(offset)标签,其中前者是与锚框相关的对象的类别,后者是真实边界框相对于锚框的偏移量。
在预测时,为每个图像生成多个锚框,预测所有锚框的类别和偏移量,根据预测的偏移量调整它们的位置以获得预测的边界框,最后只输出符合特定条件的预测边界框。
目标检测训练集是带有“真实边界框”的位置及其包围物体类别的标签。要标记任何生成的锚框,可以参考分配到的最接近此锚框的真实边界框的位置和类别标签。在下面算法中,它能够把最接近的真实边界框分配给锚框。
5.将真实边界框分配给锚框
给定图像,假设锚框是 A 1 , A 2 , … , A n a A_1, A_2, \ldots, A_{n_a} A1,A2,…,Ana,真实边界框是 B 1 , B 2 , … , B n b B_1, B_2, \ldots, B_{n_b} B1,B2,…,Bnb,其中 n a ≥ n b n_a \geq n_b na≥nb。定义一个矩阵 X ∈ R n a × n b \mathbf{X} \in \mathbb{R}^{n_a \times n_b} X∈Rna×nb,其中第 i i i行、第 j j j列的元素 x i j x_{ij} xij是锚框 A i A_i Ai和真实边界框 B j B_j Bj的IoU。该算法包含以下步骤:
- 在矩阵 X \mathbf{X} X中找到最大的元素,并将它的行索引和列索引分别表示为 i 1 i_1 i1和 j 1 j_1 j1。然后将真实边界框 B j 1 B_{j_1} Bj1分配给锚框 A i 1 A_{i_1} Ai1。因为 A i 1 A_{i_1} Ai1和 B j 1 B_{j_1} Bj1是所有锚框和真实边界框配对中最相近的。在第一个分配完成后,丢弃矩阵中 i 1 t h {i_1}^\mathrm{th} i1th行和 j 1 t h {j_1}^\mathrm{th} j1th列中的所有元素。
- 在矩阵 X \mathbf{X} X中找到剩余元素中最大的元素,并将它的行索引和列索引分别表示为 i 2 i_2 i2和 j 2 j_2 j2。将真实边界框 B j 2 B_{j_2} Bj2分配给锚框 A i 2 A_{i_2} Ai2,并丢弃矩阵中 i 2 t h {i_2}^\mathrm{th} i2th行和 j 2 t h {j_2}^\mathrm{th} j2th列中的所有元素。
- 此时,矩阵 X \mathbf{X} X中两行和两列中的元素已被丢弃。继续上面过程,直到丢弃掉矩阵 X \mathbf{X} X中 n b n_b nb列中的所有元素。此时已经为这 n b n_b nb个锚框各自分配了一个真实边界框。
- 只遍历剩下的 n a − n b n_a - n_b na−nb个锚框。例如,给定任何锚框 A i A_i Ai,在矩阵 X \mathbf{X} X的第 i t h i^\mathrm{th} ith行中找到与 A i A_i Ai的IoU最大的真实边界框 B j B_j Bj,只有当此IoU大于预定义的阈值时,才将 B j B_j Bj分配给 A i A_i Ai。
下面用一个具体的例子来说明上述算法。
如下图(左)所示,第一步:假设矩阵 X \mathbf{X} X中的最大值为 x 23 x_{23} x23,将真实边界框 B 3 B_3 B3分配给锚框 A 2 A_2 A2,然后丢弃矩阵第2行和第3列中的所有元素。第二步:在剩余元素(阴影区域)中找到最大的 x 71 x_{71} x71,然后将真实边界框 B 1 B_1 B1分配给锚框 A 7 A_7 A7。第三步:如下图(中)所示,丢弃矩阵第7行和第1列中的所有元素,在剩余元素(阴影区域)中找到最大的 x 54 x_{54} x54,然后将真实边界框 B 4 B_4 B4分配给锚框 A 5 A_5 A5。第四步:如下图(右)所示,丢弃矩阵第5行和第4列中的所有元素,在剩余元素(阴影区域)中找到最大的 x 92 x_{92} x92,然后将真实边界框 B 2 B_2 B2分配给锚框 A 9 A_9 A9。最后:只需要遍历剩余的锚框 A 1 , A 3 , A 4 , A 6 , A 8 A_1, A_3, A_4, A_6, A_8 A1,A3,A4,A6,A8,然后根据阈值确定是否为它们分配真实边界框。
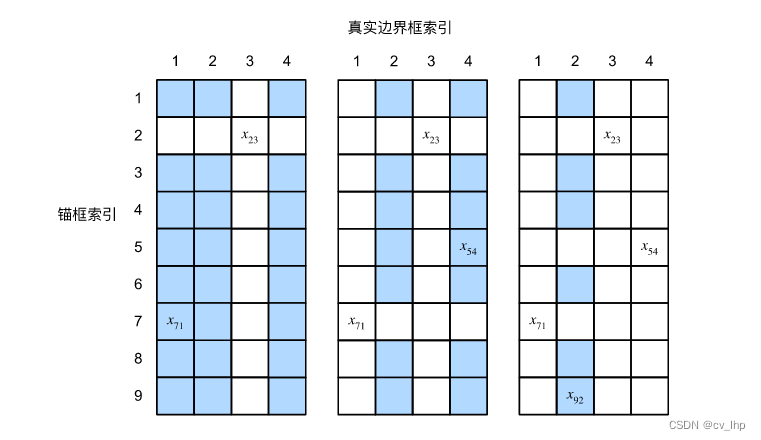
此算法在下面的assign_anchors_to_boxes()函数中实现:
def assign_anchors_to_boxes(anchors,ground_truth,device,iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors,num_gt_boxes = anchors.shape[0],ground_truth.shape[0]
# 对于每个锚框,分配的真实边界框的张量
anchors_bboxes_map = torch.full((num_anchors,),fill_value=-1,device=device,dtype=torch.long)
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = boxes_iou(anchors,ground_truth)
#计算出每行IOU最大值,然后将这个值对应的真实边界框的索引分配给这个当前的锚框
max_iou,indexing = torch.max(jaccard,dim=1)
# 根据阈值,决定是否分配真实边界框
anchors_i = torch.nonzero(max_iou>=iou_threshold).reshape(-1)
box_indices = indexing[max_iou>=iou_threshold]
anchors_bboxes_map[anchors_i] = box_indices
column_discard = torch.full((num_anchors,),fill_value=-1)
row_discard = torch.full((num_gt_boxes,),fill_value=-1)
for _ in range(num_gt_boxes):
#计算矩阵中IOU最大值的元素所在行和列索引,行代表锚框的索引,列代表真实边界框的索引,然后将真实边界框分配给这个锚框
maxiou_index = torch.argmax(jaccard)
maxiou_i = (maxiou_index/num_gt_boxes).long()
maxiou_j = (maxiou_index%num_gt_boxes).long()
anchors_bboxes_map[maxiou_i] = maxiou_j
#将真实边界框分配给锚框后所在的行和列都丢弃,赋值为-1
jaccard[maxiou_i,:] = row_discard
jaccard[:,maxiou_j] = column_discard
return anchors_bboxes_map
6. 标记类别和偏移量
6.1 下面为每个锚框标记类别和偏移量。假设一个锚框 A A A被分配了一个真实边界框 B B B。一方面,锚框 A A A的类别将被标记为与 B B B相同;另一方面,锚框 A A A的偏移量将根据 B B B和 A A A中心坐标的相对位置以及这两个框的相对大小进行标记。鉴于数据集内不同的框的位置和大小不同,我们可以对那些相对位置和大小应用变换,使其获得分布更均匀且易于拟合的偏移量。下面介绍一种常见的变换:
给定框 A A A和 B B B,中心坐标分别为 ( x a , y a ) (x_a, y_a) (xa,ya)和 ( x b , y b ) (x_b, y_b) (xb,yb),宽度分别为 w a w_a wa和 w b w_b wb,高度分别为 h a h_a ha和 h b h_b hb,将 A A A的偏移量标记为:
( x b − x a w a − μ x σ x , y b − y a h a − μ y σ y , log w b w a − μ w σ w , log h b h a − μ h σ h ) , \left( \frac{ \frac{x_b - x_a}{w_a} - \mu_x }{\sigma_x}, \frac{ \frac{y_b - y_a}{h_a} - \mu_y }{\sigma_y}, \frac{ \log \frac{w_b}{w_a} - \mu_w }{\sigma_w}, \frac{ \log \frac{h_b}{h_a} - \mu_h }{\sigma_h}\right), (σxwaxb−xa−μx,σyhayb−ya−μy,σwlogwawb−μw,σhloghahb−μh),
其中常量的默认值为 μ x = μ y = μ w = μ h = 0 , σ x = σ y = 0.1 \mu_x = \mu_y = \mu_w = \mu_h = 0, \sigma_x=\sigma_y=0.1 μx=μy=μw=μh=0,σx=σy=0.1 , σ w = σ h = 0.2 \sigma_w=\sigma_h=0.2 σw=σh=0.2。
这种转换在下面的 offset_boxes()函数中实现。
def offset_boxes(anchors,assign_bboxes,eps = 1e-6):
"""对锚框偏移量的转换,计算分配的真实边界框与对应的锚框的偏移量"""
anchors_center = d2l.torch.box_corner_to_center(anchors)
assign_bboxes_center = d2l.torch.box_corner_to_center(assign_bboxes)
offset_xy = 10*(assign_bboxes_center[:,:2]-anchors_center[:,:2])/anchors_center[:,2:]
offset_wh = 5*torch.log(eps+assign_bboxes_center[:,2:]/anchors_center[:,2:])
offset = torch.cat((offset_xy,offset_wh),dim=1)
print('offset.shape = ',offset.shape)
return offset
6.2 如果一个锚框没有被分配真实边界框,需将该锚框的类别标记为“背景类”。 背景类别的锚框通常被称为“负类”锚框,其余的被称为“正类”锚框。 下面使用真实边界框(labels参数)实现multibox_target()函数,来标记锚框的类别和偏移量(anchors参数),此函数将背景类别的索引设置为零,然后将新类别的整数索引递增一。
def multibox_target(anchors,labels):
batch_size,anchors = labels.shape[0],anchors.squeeze(0)
num_anchors,device = anchors.shape[0],anchors.device
batch_mask,batch_offset,batch_class_labels = [],[],[]
for i in range(batch_size):
label = labels[i,:,:]
anchors_bboxes_map = assign_anchors_to_boxes(anchors,label[:,1:],device)
# 初始化锚框和真实边界框之间偏移量的掩码,因为偏移量每行有四个元素,因此掩码每一行有四个元素,初始化为0或1,0代表这个锚框没有分配给任何一个真实边界框,1代表这个锚框已经分配给了一个真实边界框
anchors_mask = ((anchors_bboxes_map>=0).float().unsqueeze(-1)).repeat(1,4)
# 将类标签和分配的边界框坐标初始化为零
class_label = torch.zeros(num_anchors,device=device,dtype=torch.long)
assign_bb = torch.zeros(size=(num_anchors,4),device=device,dtype=torch.float32)
'''
使用真实边界框来标记锚框的类别。
如果一个锚框没有被分配,我们标记其为背景(值为零)
'''
anchors_idx = torch.nonzero(anchors_bboxes_map>=0).reshape(-1)
bbox_idx = anchors_bboxes_map[anchors_idx]
class_label[anchors_idx] = label[bbox_idx,0].long()+1
assign_bb[anchors_idx] = label[bbox_idx,1:]
# 计算真实边界框和锚框的偏移量,没有分配真实边界框的锚框的偏移量为0
anchors_offset = offset_boxes(anchors,assign_bb)*anchors_mask
batch_mask.append(anchors_mask.reshape(-1))
batch_offset.append(anchors_offset.reshape(-1))
batch_class_labels.append(class_label)
bboxes_mask = torch.stack(batch_mask)
bboxes_class_label = torch.stack(batch_class_labels)
bboxes_offset = torch.stack(batch_offset)
return (bboxes_offset,bboxes_mask,bboxes_class_label)
7. 一个例子来实现对锚框的分类和偏移量标注
7.1 我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的 (,) 轴坐标(范围介于0和1之间),并且构建了五个锚框,用左上角和右下角的坐标进行标记: 0,…,4 (索引从0开始),然后在图像中绘制这些真实边界框和锚框,如下图结果所示。
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
bbox_scale = torch.tensor([w,h,w,h])
fig = d2l.torch.plt.imshow(img)
show_bboxes(axes=fig.axes,bboxs=ground_truth[:,1:]*bbox_scale,labels=['dog','cat'],colors='k')
#因为真实Img图片并没有进行高和宽缩放,因此需要将已经缩放的锚框的高和宽重新进行扩展
show_bboxes(axes=fig.axes,bboxs=anchors*bbox_scale,labels=['0','1','2','3','4'])

7.2 使用上面定义的multibox_target函数,可以根据狗和猫的真实边界框,标注这些锚框的分类和偏移量,在上面例子中,背景、狗和猫的类索引分别为0、1和2。
labels = multibox_target(anchors=anchors.unsqueeze(0),labels=ground_truth.unsqueeze(0))
7.3 返回的结果中有三个元素,第三个元素包含标记的输入锚框的类别。下面根据图像中的锚框和真实边界框的位置来分析下面返回的类别标签。 首先,在所有的锚框和真实边界框配对中,锚框 4 与猫的真实边界框的IoU是最大的。 因此4 的类别被标记为猫,去除包含 4 或猫的真实边界框的配对,在剩下的配对中,锚框 1 和狗的真实边界框有最大的IoU, 因此1 的类别被标记为狗。 接下来,需要遍历剩下的三个未标记的锚框: 0 、 2 和 3 。 对于 0 ,与其拥有最大IoU的真实边界框的类别是狗,但IoU低于预定义的阈值(0.5),因此该类别被标记为背景; 对于 2 ,与其拥有最大IoU的真实边界框的类别是猫,IoU超过阈值,所以类别被标记为猫; 对于 3 ,与其拥有最大IoU的真实边界框的类别是猫,但值低于阈值,因此该类别被标记为背景。
labels[2]
输出结果如下:
tensor([[0, 1, 2, 0, 2]])
7.4 返回的第二个元素是掩码(mask)变量,形状为(批量大小,锚框数的四倍)。 掩码变量中的元素与每个锚框的4个偏移量一一对应。 由于我们不关心对背景的检测,负类的偏移量不应影响目标函数,通过矩阵元素乘法,掩码变量中的零将在计算目标函数之前过滤掉负类偏移量。
labels[1]
输出结果如下:
tensor([[0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 1., 1.,
1., 1.]])
7.5 返回的第一个元素包含了为每个锚框标记的四个偏移值,注意负类锚框的偏移量被标记为零。
labels[0]
输出结果如下:
tensor([[-0.00e+00, -0.00e+00, -0.00e+00, -0.00e+00, 1.40e+00, 1.00e+01,
2.59e+00, 7.18e+00, -1.20e+00, 2.69e-01, 1.68e+00, -1.57e+00,
-0.00e+00, -0.00e+00, -0.00e+00, -0.00e+00, -5.71e-01, -1.00e+00,
4.17e-06, 6.26e-01]])
8. 使用非极大值抑制预测边界框
8.1 在预测时,先为图像生成多个锚框,再为这些锚框一一预测类别和偏移量。 一个“预测好的边界框”则根据其中某个带有预测偏移量的锚框而生成,下面实现了offset_inverse函数,该函数将锚框和偏移量预测作为输入,并应用逆偏移变换来返回预测的边界框坐标。
注意:非极大值抑制是一种贪心算法,它通过移除来抑制预测的边界框。
def offset_inverse(anchors,offset_preds):
"""根据带有预测偏移量的锚框来预测边界框,应用逆偏移变换来返回预测的边界框坐标"""
anchors = d2l.torch.box_corner_to_center(anchors)
predict_bbox_xy = (offset_preds[:,:2]*anchors[:,2:])/10+anchors[:,:2]
predict_bbox_wh = torch.exp(offset_preds[:,2:]/5)*anchors[:,2:]
predict_bbox = torch.cat((predict_bbox_xy,predict_bbox_wh),dim=1)
predict_bbox_corner = d2l.torch.box_center_to_corner(predict_bbox)
return predict_bbox_corner
8.2 当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。为了简化输出,使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。下面是非极大值抑制的工作原理:
对于一个预测边界框 B B B,目标检测模型会计算每个类别的预测概率。假设最大的预测概率为 p p p,则该概率所对应的类别 B B B即为预测的类别。具体来说,我们将 p p p称为预测边界框 B B B的置信度(confidence)。在同一张图像中,所有预测的非背景边界框都按置信度降序排序,以生成列表 L L L。然后通过以下步骤操作排序列表 L L L:
- 从 L L L中选取置信度最高的预测边界框 B 1 B_1 B1作为基准,然后将所有与 B 1 B_1 B1的IoU超过预定阈值 ϵ \epsilon ϵ的非基准预测边界框从 L L L中移除。这时, L L L保留了置信度最高的预测边界框,去除了与其太过相似的其他预测边界框。简而言之,那些具有非极大值置信度的边界框被抑制了。
- 从 L L L中选取置信度第二高的预测边界框 B 2 B_2 B2作为又一个基准,然后将所有与 B 2 B_2 B2的IoU大于 ϵ \epsilon ϵ的非基准预测边界框从 L L L中移除。
- 重复上述过程,直到 L L L中的所有预测边界框都曾被用作基准。此时, L L L中任意一对预测边界框的IoU都小于阈值 ϵ \epsilon ϵ;因此,没有一对边界框过于相似。
- 输出列表 L L L中的所有预测边界框。
下面nms函数按降序对置信度进行排序并返回其索引:
#nms相当于去掉预测真实边界框重复率比较大的一些预测真实边界框
def nms(boxes,scores,iou_threshold):
"""对预测边界框的置信度进行排序"""
#从大到小排序,得到排序后的元素在排序前的索引值
B = torch.argsort(scores,dim=-1,descending=True)
#保存预测真实边界框的索引
keep = []
while B.numel()>0:
i = B[0]
keep.append(i)
if B.numel() == 1 :break
#计算当前预测类别置信度最大的对应的预测真实边界框与剩下所有预测真实边界框进行求IOU,如果超过一定阈值,说明这两个预测真实边界框重合部分比较多,因此去掉这个预测真实边界框,否则保留这个预测真实边界框
box_iou = boxes_iou(boxes1=boxes[i,:].reshape(-1,4),boxes2=boxes[B[1:],:].reshape(-1,4)).reshape(-1)
box_iou_idx = torch.nonzero(box_iou<=iou_threshold).reshape(-1)
B = B[box_iou_idx+1]
return torch.tensor(keep,device=boxes.device)
8.3 下面multibox_detection()函数来将非极大值抑制应用于预测边界框。
"""使用非极大值抑制来预测边界框"""
def multibox_detection(cls_probs,offset_preds,anchors,nms_threshold=0.5,pos_threshold=0.009999999):
device,batch_size = cls_probs.device,cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes,num_anchors = cls_probs.shape[1],cls_probs.shape[2]
#存储批量样本中预测的一些信息
out = []
for i in range(batch_size):
cls_prob = cls_probs[i]
offset_pred = offset_preds[i].reshape(-1,4)
conf,class_id = torch.max(cls_prob[1:],dim=0)
#根据anchors和锚框偏移量得到预测真实边界框的值
predict_bb = offset_inverse(anchors,offset_pred)
#根据nms去除一些重合比较大的预测真实边界框,保留重合率不大的预测真实边界框
keep = nms(predict_bb,conf,nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景-1
anchors_idx = torch.arange(num_anchors,device=device,dtype=torch.long)
idx = torch.cat((keep,anchors_idx))
uniques,counts = idx.unique(return_counts=True)
non_keep = uniques[counts==1]
class_id[non_keep] = -1
anchors_all_id = torch.cat((keep,non_keep))
# pos_threshold是一个用于非背景预测的阈值,将低于pos_threshold阈值的预测真实边界框的类别设置为背景类-1
below_min_idx = (conf<pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1-conf[below_min_idx]
#对class_id,conf,predict_bb按照anchors_all_id索引列表重复排列
class_id = class_id[anchors_all_id]
conf = conf[anchors_all_id]
predict_bb = predict_bb[anchors_all_id]
predict_info = torch.cat((class_id.unsqueeze(1),conf.unsqueeze(1),predict_bb),dim=1)
out.append(predict_info)
return torch.stack(out)
8.4 将上述算法应用到一个带有四个锚框的具体示例中,为简单起见假设预测的偏移量都是零,这意味着预测的边界框即是锚框,对于背景、狗和猫其中的每个类,手动给出了它们的预测概率。
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0]*anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
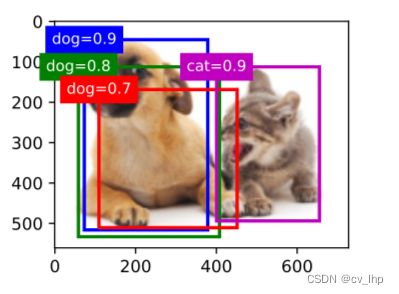
8.5 在图像上绘制这些预测边界框和置信度,如下图结果所示:
fig = d2l.torch.plt.imshow(img)
show_bboxes(fig.axes,anchors*bbox_scale,labels=['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
8.6 调用multibox_detection()函数来使用非极大值抑制,其中阈值设置为0.5,可以看到返回结果的形状是(批量大小,锚框的数量,6)。 最内层维度中的六个元素提供了同一预测边界框的输出信息,第一个元素是预测的类索引,从0开始(0代表狗,1代表猫),值-1表示背景或在非极大值抑制中被移除了;第二个元素是预测的边界框的置信度;其余四个元素分别是预测边界框左上角和右下角的 (,) 轴坐标(范围介于0和1之间)。
out = multibox_detection(cls_probs.unsqueeze(0),offset_preds.unsqueeze(0),anchors.unsqueeze(0),nms_threshold=0.5)
print(out)
输出结果如下所示:
tensor([[[ 0.00, 0.90, 0.10, 0.08, 0.52, 0.92],
[ 1.00, 0.90, 0.55, 0.20, 0.90, 0.88],
[-1.00, 0.80, 0.08, 0.20, 0.56, 0.95],
[-1.00, 0.70, 0.15, 0.30, 0.62, 0.91]]])
8.7 删除-1类别(背景)的预测边界框后,可以输出由非极大值抑制保存的最终预测边界框,如下图结果所示。
fig = d2l.torch.plt.imshow(img)
for i in out[0].detach().numpy():
#当类别是背景类-1时不需要在图片中将预测真实边界框展示出来
if i[0] == -1:
continue
label = ('dog=','cat=')[int(i[0])]+str(i[1])
show_bboxes(fig.axes,[torch.tensor(i[2:])*bbox_scale],label)

实践中,在执行非极大值抑制前,我们甚至可以将置信度较低的预测边界框移除,从而减少此算法中的计算量,或者也可以对非极大值抑制的输出结果进行后处理,例如只保留置信度较高的结果作为最终输出。
9.小结
- 以图像的每个像素为中心生成不同形状的锚框。
- 交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。
- 在训练集中,需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真实相对于边界框的偏移量。
- 在预测期间,使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
- 本节锚框实现过程:以图像的每个像素为中心生成不同形状的锚框–>使用IOU给每个锚框分配真实边界框(物体类别号和真实边界框的左上右下坐标),然后锚框真实相对于边界框的偏移量–>在预测期间,使用非极大值抑制(NMS)来移除类似重合度高的预测边界框–>输出去重后的最终预测边界框。
- 虽然锚框生成过程,预测真实边界框的思想很简单,但是却使用了大量tensor矩阵运算,从而导致实现比较复杂,主要原因是锚框(目标检测)是需要在GPU上面运行,矩阵元素在GPU上面运算效率比较高,因此锚框整个过程使用了大量的矩阵tensor运算。
二.全部代码
import torch
import d2l.torch
torch.set_printoptions(2) # 精简输出精度
"""生成以每个像素为中心具有不同形状的锚框"""
def multibox_prior(data, sizes, ratios):
#图片的高和宽
in_height, in_width = data.shape[-2:]
device, num_sizes, num_ratios = data.device, len(sizes), len(ratios)
tensor_sizes, tensor_ratios = torch.tensor(sizes, device=device), torch.tensor(ratios, device=device)
#每个像素点pixel的锚框数
boxes_per_pixel = (num_sizes + num_ratios - 1)
# 为了将锚点移动到像素的中心,需要设置偏移量。
# 因为一个像素的的高为1且宽为1,我们选择偏移我们的中心0.5
offset_w, offset_h = 0.5, 0.5
#把图片高和宽归一化(缩放)到1
steps_h, steps_w = 1.0 / in_height, 1.0 / in_width # 在y轴上缩放步长,在x轴上缩放步长
'''生成锚框的所有中心点'''
#生成0.5/in_height到(in_height+0.5)/in_height之间高度的刻度值,代表y轴
center_h = (torch.arange(in_height, device=device) + offset_h) * steps_h
#生成0.5/in_width到(in_width+0.5)/in_width之间宽度的刻度值,代表x轴
center_w = (torch.arange(in_width, device=device) + offset_w) * steps_w
#生成网格,shift_y中行相等,列不等,shift_x中行不等,列相等,行的个数为center_h的元素个数,列的个数为center_w的元素个数
shift_y, shift_x = torch.meshgrid(center_h, center_w, indexing='ij')
#shift_y,shift_x都reshape成一维,维数为:in_height*in_width
shift_y = shift_y.reshape(-1)
shift_x = shift_x.reshape(-1)
'''每个中心点都将有“boxes_per_pixel”个锚框,所以生成含所有锚框中心的网格,重复了“boxes_per_pixel”次'''
# 取(shift_x,shift_y,shift_x,shift_y)相应元素组成一行,因此一行有四个元素,然后将这一行直接复制boxes_per_pixel次,表示一个像素点的坐标(4维,因为用于后面计算左上右下的坐标)复制boxes_per_pixel次(因为需要生成boxes_per_pixel)锚框,out_grid.size=(561x728x5,4)
out_grid = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1).repeat_interleave(boxes_per_pixel, dim=0)
'''生成“boxes_per_pixel”个高和宽,之后用于创建锚框的四角坐标(x_min,y_min,x_max,y_max)'''
#生成锚框的w,有boxes_per_pixel个锚框,因此有boxes_per_pixel个锚框的宽
anchors_w = torch.cat((tensor_sizes * torch.sqrt(tensor_ratios[0]),
tensor_sizes[0] * torch.sqrt(tensor_ratios[1:]))) * in_height / in_width
#生成锚框的h,有boxes_per_pixel个锚框,因此有boxes_per_pixel个锚框的高
anchors_h = torch.cat(
(tensor_sizes / torch.sqrt(tensor_ratios[0]), tensor_sizes[0] / torch.sqrt(tensor_ratios[1:])))
#每一行代表一个像素点的锚框的高和宽,因为一个像素点有boxes_per_pixel个锚框,因此每boxes_per_pixel行代表一个像素的所有锚框。因为所有像素点的锚框个数和高宽都是一样的,因此需要复制in_height*in_width次,所以anchor_manipulations.size=(5x561x728,4)
anchor_manipulations = torch.stack((-anchors_w, -anchors_h, anchors_w, anchors_h)).T.repeat(in_height * in_width,
1) / 2 #除以2来获得半高和半宽
#因此out_grid与anchor_manipulations相加得到一个像素点中一个锚框的左上,右下的坐标,因此每boxes_per_pixel行代表一个像素点的所有锚框的左上,右下坐标值,也相当于生成所有像素点的所有锚框
output = out_grid + anchor_manipulations
#output新增一个维度
return output.unsqueeze(0)
img = d2l.torch.plt.imread('../images/catdog.jpg')
h, w = img.shape[:2]
data = torch.rand(size=(1, 3, h, w))
output = multibox_prior(data, sizes=[0.75, 0.5, 0.25], ratios=[1, 2, 0.5])
print(output.shape)
print(h, w)
boxes = output.reshape(h, w, 5, 4)
boxes[250, 250, 0, :]
def show_bboxes(axes, bboxs, labels=None, colors=None):
def _make_list(obj, default_values=None):
if obj is None:
obj = default_values
elif not isinstance(obj, (list, tuple)):
obj = [obj]
return obj
labels = _make_list(labels)
colors = _make_list(colors, ['b', 'g', 'r', 'm', 'c'])
for i, bbox in enumerate(bboxs):
color = colors[i % len(colors)]
rect = d2l.torch.bbox_to_rect(bbox.detach().numpy(), color)
axes.add_patch(rect)
if labels and len(labels) > i:
test_color = 'k' if color == 'w' else 'w'
axes.text(rect.xy[0], rect.xy[1], labels[i], va='center', ha='center',
fontsize=9, color=test_color, bbox=dict(facecolor=color, lw=0))
d2l.torch.set_figsize()
bbox_scale = torch.tensor((w, h, w, h))
fig = d2l.torch.plt.imshow(img)
# show_bboxes(axes=fig.axes, bboxs=boxes[250, 250, :, :] * bbox_scale,
# labels=['s=0.75, r=1', 's=0.5, r=1', 's=0.25, r=1', 's=0.75, r=2',
# 's=0.75, r=0.5'])
"""计算两个锚框或边界框列表中成对的交并比"""
def boxes_iou(boxes1, boxes2):
box_area = lambda boxes: (boxes[:, 2] - boxes[:, 0]) * (boxes[:, 3] - boxes[:, 1])
'''
boxes1,boxes2,areas1,areas2的形状:
boxes1:(boxes1的数量,4),
boxes2:(boxes2的数量,4),
areas1:(boxes1的数量,),
areas2:(boxes2的数量,)
'''
areas1 = box_area(boxes1)
areas2 = box_area(boxes2)
'''
inter_upperlefts,inter_lowerrights,inters的形状:
(boxes1的数量,boxes2的数量,2)
'''
#计算相交面积中的左上点的坐标
inner_upperlefts = torch.max(boxes1[:, None, :2], boxes2[:, :2])
#计算相交面积中的右下点的坐标
inner_lowrights = torch.min(boxes1[:, None, 2:], boxes2[:, 2:])
#求出相交面积的宽和高,并且宽和高最小值必须大于0,因此加上clamp(min=0)函数表示将两个锚框不相交的宽和高赋值为0
inners = (inner_lowrights - inner_upperlefts).clamp(min=0)
'''
inter_areas和union_areas的形状:(boxes1的数量,boxes2的数量)
'''
#求出相交部分的面积,不相交面积为0
inner_areas = inners[:, :, 0] * inners[:, :, 1]
#求出两个锚框面积的并集
union_areas = areas1[:, None] + areas2 - inner_areas
#求出面积的交并比
return inner_areas / union_areas
def assign_anchors_to_boxes(anchors, ground_truth, device, iou_threshold=0.5):
"""将最接近的真实边界框分配给锚框"""
num_anchors, num_gt_boxes = anchors.shape[0], ground_truth.shape[0]
# 对于每个锚框,分配的真实边界框的张量
anchors_bboxes_map = torch.full((num_anchors,), fill_value=-1, device=device, dtype=torch.long)
# 位于第i行和第j列的元素x_ij是锚框i和真实边界框j的IoU
jaccard = boxes_iou(anchors, ground_truth)
#计算出每行IOU最大值,然后将这个值对应的真实边界框的索引分配给这个当前的锚框
max_iou, indexing = torch.max(jaccard, dim=1)
# 根据阈值,决定是否分配真实边界框
anchors_i = torch.nonzero(max_iou >= iou_threshold).reshape(-1)
box_indices = indexing[max_iou >= iou_threshold]
anchors_bboxes_map[anchors_i] = box_indices
column_discard = torch.full((num_anchors,), fill_value=-1)
row_discard = torch.full((num_gt_boxes,), fill_value=-1)
for _ in range(num_gt_boxes):
#计算矩阵中IOU最大值的元素所在行和列索引,行代表锚框的索引,列代表真实边界框的索引,然后将真实边界框分配给这个锚框
maxiou_index = torch.argmax(jaccard)
maxiou_i = (maxiou_index / num_gt_boxes).long()
maxiou_j = (maxiou_index % num_gt_boxes).long()
anchors_bboxes_map[maxiou_i] = maxiou_j
#将真实边界框分配给锚框后所在的行和列都丢弃,赋值为-1
jaccard[maxiou_i, :] = row_discard
jaccard[:, maxiou_j] = column_discard
return anchors_bboxes_map
def offset_boxes(anchors, assign_bboxes, eps=1e-6):
"""对锚框偏移量的转换,计算分配的真实边界框与对应的锚框的偏移量"""
anchors_center = d2l.torch.box_corner_to_center(anchors)
assign_bboxes_center = d2l.torch.box_corner_to_center(assign_bboxes)
offset_xy = 10 * (assign_bboxes_center[:, :2] - anchors_center[:, :2]) / anchors_center[:, 2:]
offset_wh = 5 * torch.log(eps + assign_bboxes_center[:, 2:] / anchors_center[:, 2:])
offset = torch.cat((offset_xy, offset_wh), dim=1)
print('offset.shape = ', offset.shape)
return offset
def multibox_target(anchors, labels):
batch_size, anchors = labels.shape[0], anchors.squeeze(0)
num_anchors, device = anchors.shape[0], anchors.device
batch_mask, batch_offset, batch_class_labels = [], [], []
for i in range(batch_size):
label = labels[i, :, :]
anchors_bboxes_map = assign_anchors_to_boxes(anchors, label[:, 1:], device)
# 初始化锚框和真实边界框之间偏移量的掩码,因为偏移量每行有四个元素,因此掩码每一行有四个元素,初始化为0或1,0代表这个锚框没有分配给任何一个真实边界框,1代表这个锚框已经分配给了一个真实边界框
anchors_mask = ((anchors_bboxes_map >= 0).float().unsqueeze(-1)).repeat(1, 4)
# 将类标签和分配的边界框坐标初始化为零
class_label = torch.zeros(num_anchors, device=device, dtype=torch.long)
assign_bb = torch.zeros(size=(num_anchors, 4), device=device, dtype=torch.float32)
'''
使用真实边界框来标记锚框的类别。
如果一个锚框没有被分配,我们标记其为背景(值为零)
'''
anchors_idx = torch.nonzero(anchors_bboxes_map >= 0).reshape(-1)
bbox_idx = anchors_bboxes_map[anchors_idx]
class_label[anchors_idx] = label[bbox_idx, 0].long() + 1
assign_bb[anchors_idx] = label[bbox_idx, 1:]
# 计算真实边界框和锚框的偏移量,没有分配真实边界框的锚框的偏移量为0
anchors_offset = offset_boxes(anchors, assign_bb) * anchors_mask
batch_mask.append(anchors_mask.reshape(-1))
batch_offset.append(anchors_offset.reshape(-1))
batch_class_labels.append(class_label)
bboxes_mask = torch.stack(batch_mask)
bboxes_class_label = torch.stack(batch_class_labels)
bboxes_offset = torch.stack(batch_offset)
return (bboxes_offset, bboxes_mask, bboxes_class_label)
ground_truth = torch.tensor([[0, 0.1, 0.08, 0.52, 0.92],
[1, 0.55, 0.2, 0.9, 0.88]])
anchors = torch.tensor([[0, 0.1, 0.2, 0.3], [0.15, 0.2, 0.4, 0.4],
[0.63, 0.05, 0.88, 0.98], [0.66, 0.45, 0.8, 0.8],
[0.57, 0.3, 0.92, 0.9]])
bbox_scale = torch.tensor([w, h, w, h])
fig = d2l.torch.plt.imshow(img)
show_bboxes(axes=fig.axes, bboxs=ground_truth[:, 1:] * bbox_scale, labels=['dog', 'cat'], colors='k')
#因为真实Img图片并没有进行高和宽缩放,因此需要将已经缩放的锚框的高和宽重新进行扩展
# show_bboxes(axes=fig.axes, bboxs=anchors * bbox_scale, labels=['0', '1', '2', '3', '4'])
# labels = multibox_target(anchors=anchors.unsqueeze(0), labels=ground_truth.unsqueeze(0))
# labels[2]
# labels[1]
# labels[0]
def offset_inverse(anchors, offset_preds):
"""根据带有预测偏移量的锚框来预测边界框,应用逆偏移变换来返回预测的边界框坐标"""
anchors = d2l.torch.box_corner_to_center(anchors)
predict_bbox_xy = (offset_preds[:, :2] * anchors[:, 2:]) / 10 + anchors[:, :2]
predict_bbox_wh = torch.exp(offset_preds[:, 2:] / 5) * anchors[:, 2:]
predict_bbox = torch.cat((predict_bbox_xy, predict_bbox_wh), dim=1)
predict_bbox_corner = d2l.torch.box_center_to_corner(predict_bbox)
return predict_bbox_corner
#nms相当于去掉预测真实边界框重复率比较大的一些预测真实边界框
def nms(boxes, scores, iou_threshold):
"""对预测边界框的置信度进行排序"""
#从大到小排序,得到排序后的元素在排序前的索引值
B = torch.argsort(scores, dim=-1, descending=True)
#保存预测真实边界框的索引
keep = []
while B.numel() > 0:
i = B[0]
keep.append(i)
if B.numel() == 1: break
#计算当前预测类别置信度最大的对应的预测真实边界框与剩下所有预测真实边界框进行求IOU,如果超过一定阈值,说明这两个预测真实边界框重合部分比较多,因此去掉这个预测真实边界框,否则保留这个预测真实边界框
box_iou = boxes_iou(boxes1=boxes[i, :].reshape(-1, 4), boxes2=boxes[B[1:], :].reshape(-1, 4)).reshape(-1)
box_iou_idx = torch.nonzero(box_iou <= iou_threshold).reshape(-1)
B = B[box_iou_idx + 1]
return torch.tensor(keep, device=boxes.device)
"""使用非极大值抑制来预测边界框"""
def multibox_detection(cls_probs, offset_preds, anchors, nms_threshold=0.5, pos_threshold=0.009999999):
device, batch_size = cls_probs.device, cls_probs.shape[0]
anchors = anchors.squeeze(0)
num_classes, num_anchors = cls_probs.shape[1], cls_probs.shape[2]
#存储批量样本中预测的一些信息
out = []
for i in range(batch_size):
cls_prob = cls_probs[i]
offset_pred = offset_preds[i].reshape(-1, 4)
conf, class_id = torch.max(cls_prob[1:], dim=0)
#根据anchors和锚框偏移量得到预测真实边界框的值
predict_bb = offset_inverse(anchors, offset_pred)
#根据nms去除一些重合比较大的预测真实边界框,保留重合率不大的预测真实边界框
keep = nms(predict_bb, conf, nms_threshold)
# 找到所有的non_keep索引,并将类设置为背景-1
anchors_idx = torch.arange(num_anchors, device=device, dtype=torch.long)
idx = torch.cat((keep, anchors_idx))
uniques, counts = idx.unique(return_counts=True)
non_keep = uniques[counts == 1]
class_id[non_keep] = -1
anchors_all_id = torch.cat((keep, non_keep))
# pos_threshold是一个用于非背景预测的阈值,将低于pos_threshold阈值的预测真实边界框的类别设置为背景类-1
below_min_idx = (conf < pos_threshold)
class_id[below_min_idx] = -1
conf[below_min_idx] = 1 - conf[below_min_idx]
#对class_id,conf,predict_bb按照anchors_all_id索引列表重复排列
class_id = class_id[anchors_all_id]
conf = conf[anchors_all_id]
predict_bb = predict_bb[anchors_all_id]
predict_info = torch.cat((class_id.unsqueeze(1), conf.unsqueeze(1), predict_bb), dim=1)
out.append(predict_info)
return torch.stack(out)
anchors = torch.tensor([[0.1, 0.08, 0.52, 0.92], [0.08, 0.2, 0.56, 0.95],
[0.15, 0.3, 0.62, 0.91], [0.55, 0.2, 0.9, 0.88]])
offset_preds = torch.tensor([0] * anchors.numel())
cls_probs = torch.tensor([[0] * 4, # 背景的预测概率
[0.9, 0.8, 0.7, 0.1], # 狗的预测概率
[0.1, 0.2, 0.3, 0.9]]) # 猫的预测概率
fig = d2l.torch.plt.imshow(img)
#show_bboxes(fig.axes, anchors * bbox_scale, labels=['dog=0.9', 'dog=0.8', 'dog=0.7', 'cat=0.9'])
out = multibox_detection(cls_probs.unsqueeze(0), offset_preds.unsqueeze(0), anchors.unsqueeze(0), nms_threshold=0.5)
out
fig = d2l.torch.plt.imshow(img)
for i in out[0].detach().numpy():
#当类别是背景类-1时不需要在图片中将预测真实边界框展示出来
if i[0] == -1:
continue
label = ('dog=', 'cat=')[int(i[0])] + str(i[1])
show_bboxes(fig.axes, [torch.tensor(i[2:]) * bbox_scale], label)