ECCV 2022 Oral | CCPL: 一种通用的关联性保留损失函数实现通用风格迁移
关注公众号,发现CV技术之美
本篇分享论文『CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer』。介绍了一个通用的损失函数CCPL,其能够应用于所有基于训练的风格迁移网络,并能够提升网络在艺术化,照片化,以及视频风格迁移中的表现。结合文中提出的轻量化风格迁移网络SCTNet,论文中的方法分别在艺术化,照片化以及视频风格迁移任务中超越了现有方法。CCPL还被证明在广泛的图到图转换任务中能够提升生成质量。
详细信息如下:

论文链接:https://arxiv.org/abs/2207.04808
项目链接:https://github.com/JarrentWu1031/CCPL
01
前言
1.1 研究背景
艺术化,照片化和视频风格迁移在过去被视作独立的任务,它们对于结果有着不同方面的要求。其中,视频风格迁移除了追求每一帧图像的风格化效果,对生成视频的稳定性也有着很高的要求。过去基于单帧图像训练的视频风格迁移方法尝试通过对视频帧进行全局线性转换来保留源视频的稳定性。
然而这种全局约束往往过强,导致生成效果在变化不明显和不够稳定之间徘徊。本文想要设计一种通用的方法来提升转换视频的稳定性,同时不损害转换后的视频风格化程度。
1.2 主要动机
人在观看视频时是基于每一个局部块而不是全局来判断稳定性的。理论上,如果能够保持视频的局部都稳定,那么整个视频也将是稳定的。另外作者观察到,对于稳定视频,相邻帧或相隔较近的帧与帧之间,局部的变化往往是持续且平滑的。
也就是说,绝大部分前一帧中的局部块能在下一帧的对应位置附近找到相似块。基于这一点,文中尝试保留采样块与邻近块之间的差异性来达到保持源视频稳定性的效果。这样,仅仅通过单图中的约束,便能够达到提升转换后视频稳定性的效果。
1.3 方法简述
首先,通过在不同特征层的随机位置对生成特征进行采样。然后在内容特征的相同位置采样同样数量的向量,对每个采样向量,文中希望建模和保留其与周围向量的关联性。
为了保留这种邻近向量间的关系,作者并未简单将对应的差向量向相同的方向优化,而是使用了对比学习的形式,来增大对应差向量的互信息,同时与不同位置的差向量在隐空间拉远距离。这么做避免了风格变化和维持原状的直接冲突,使得生成的图像及视频的风格化并未减弱,而是更加合理地与内容结构融为一体。
由于更好的保留了内容图中局部之间的关联性,局部随机扰动明显减少,图像生成的质量也大大提升。注意,本文中训练过程没有视频信息参与,训练数据由单图组成。
文章另外还提出了一种轻量化的风格化网络SCTNet来配合完成通用风格迁移的任务。结合CCPL和SCTNet,文中模型在艺术化,照片化和视频风格迁移三个任务上都超越了之前方法的效果。在视频风格迁移任务中性能逼近最先进的利用视频帧训练的方法。文中还展示了CCPL应用于其他风格迁移模型上以及图到图任务中的效果提升,展示了其广泛应用的潜力。
1.4 主要贡献
提出了CCPL来实现通用风格迁移。在多种风格迁移任务上都体现出其有效性。并且CCPL能够被使用到所有基于学习的风格迁移网络上。
提出了一个轻量化且有效的风格化网络SCTNet。在推理速度上超越了以前的方法。
CCPL被验证在其他任务,如图到图转换中有效,提升了生成图像及视频的质量,展示了它的灵活性。
02
方法
2.1 CCPL
CCPL的具体计算流程图如下:
将内容图C和生成图G送入固定参数的编码器E中提取不同层的特征图,其中E为在ImageNet上预训练得到的VGG-19网络,在训练期间固定权重
对G提取到的某一层特征图Gf进行随机采样得到N个中心向量(非边界),并在Cf的相同位置采样N个向量
采样每个中心向量周围的8个邻近向量并与中心向量相减得到8×N个差向量
将这些差向量送入一个2层MLP投影到隐空间并进行l2-标准化后计算infonce loss
对于不同特征层重复1-4操作并加权求和形成最终的CCPL
2.2 SCTNet
SCTNet的结构图如下,其由三个部分组成:1. 于ImageNet上预训练得到的VGG-19网络(固定权重)2. SCT模块 3. 与编码器E对称结构的解码器D。
SCTNet可以视作AdaIN[1]与Linear[2]的结合。一方面,AdaIN[1]在内容向量和风格向量的融合中只考虑了单个对应channel之间的联系,而忽略了通道间的相互联系,这种相互关系在后来的工作中被证实对风格的表达起重要作用;
另一方面,作者实验中发现,Linear[2]虽然考虑了通道间的关系建模,但它为了满足线性变化的条件,其结构存在冗余。由于CCPL已经解决了视频稳定性以及生成图贴合内容结构的问题,作者将Linear[2]简化,并与AdaIN[1]融合,提出了SCT模块。
如图所示,SCT模块主要步骤如下:1. 对内容向量进行均值-方差归一化,对风格向量进行均值归一化 2. 将归一化后的向量通过cnet和snet逐渐降低通道数,降低计算复杂度(512->128->32) 3. 计算输出风格特征的协方差矩阵(通道维度)并与内容特征进行矩阵乘法 4. 最后将融合向量通过一层卷积层还原通道数后加上源风格向量每个通道的均值,得到最终特征

2.3 优化目标
CCPL采用多层Infonce loss和的形式,每层损失计算如下:
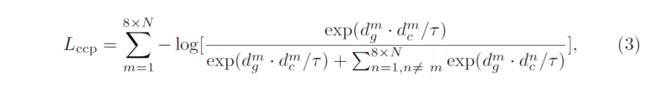
由于文中对每层特征层采样数为N(默认64),最终CCPL的计算复杂度仅为O((8×N)^2),计算代价是较低可承受的,在后面的定性结果中也可以看到,在默认的设定下,CCPL的引入仅在训练时期增加了约30%的时间,其对推理时间没有任何影响。
除了CCPL外,文中采用了常用的风格迁移内容损失和风格损失如下,具体符号及含义请参见原文:
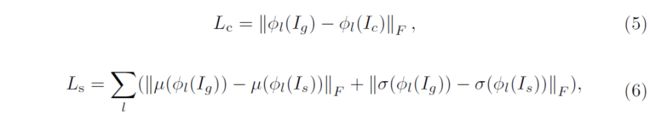
03
实验结果
3.1 视频风格迁移
文中展示了定性及定量的视频风格迁移效果,定性比较包含短期稳定性比较以及长期稳定性(间隔10帧及以上)比较,结果如下。在短期稳定性的比较中可以看出:
1. CCPL的加入大大减少了局部随机噪声的出现,使得最终模型的生成图像(视频)更加贴合源图像(视频)的轮廓。2. 本文提出的完整模型的生成视频在短期稳定性上超越了之前的基于单帧的视频及图像风格化方法,并接近最先进的基于视频帧训练和推理的方法(ReReVST[3])。
在长期稳定性的比较中也可以得出类似的结论,论文的方法超越了最先进的基于单帧的方法(MCCNet[4]),并与ReReVST[3]的结果稳定性相当,并且更好的保留了结构轮廓,风格化程度及颜色也更加贴合风格源。

由下表中的定量比较也可以验证上述结论。其中SIFID用于衡量两张图的风格分布之间的距离,越小越好;LPIPS原用于衡量两张图像的多样性,这里用于比较两张图的patch之间的相似性;由于LPIPS仅仅由生成帧之间计算得到,忽略了源视频帧的参考,文中另外还添加了Temporal Loss作为补充的稳定性衡量指标,其首先计算源视频帧之间的光流,然后将靠前生成帧通过计算得到的光流进行弯曲,再与后续生成帧进行比较。
文章在视频稳定性的比较中同样考虑了长期(间隔10帧)和短期(间隔1帧)的比较。另外,作者还调查了人们对于不同方法生成视频及图像的喜爱程度,在表中表示为Pre.,越高越好。

可以看到,在视频风格化的衡量指标下,文中提出的完整模型在视频稳定性上仅次于基于多帧的方法ReReVST[3],在长期稳定性上甚至超越了它。而在风格化程度及受喜爱程度比较上,论文中的方法则是超越了一种方法。
3.2 艺术化风格迁移
文中与9种最先进的艺术风格迁移方法进行了对比,定性结果如下:
由上图可以看到,1. CCPL的加入减少了生成图像中的局部风格扰动,大大提升了图像质量及风格化效果 2. 文中提出的完整模型在风格化程度,内容结构保留程度以及图像质量的综合效果上超越了之前的方法,这个结论在定量的比较表中也可以看出。另外在推理速度(单位:FPS)上,文中所提方法超越了过去的方法,如下表所示:

3.3 照片化风格迁移
由于CCPL可以很好的保留内容图的结构和语义信息,并能够很大程度上的减少局部随机扰动,文中的方法也非常适合照片化风格迁移的任务。具体的做法是:首先,作者去除了SCTNet编码器Relu3_1后的网络(对称的解码器操作类似);然后,在计算CCPL时,作者选取了所有的3层特征层来对更加小分辨率的特征图也进行约束。
凭借上述改变,文中的模型在照片化风格迁移任务上也表现出了十分不错的性能。相比较于其他的四种最先进的照片风格化方法,文中的完整模型在画面质量,色彩分布合理性,局部扰动等方面超越了之前的照片风格化方法,在定量指标的衡量下也验证了这个结论。另外,过去的照片风格化方法往往推理速度都是较慢的,在这点上文中模型也具有明显的优势(推理速度单位:FPS)。



3.4 消融实验
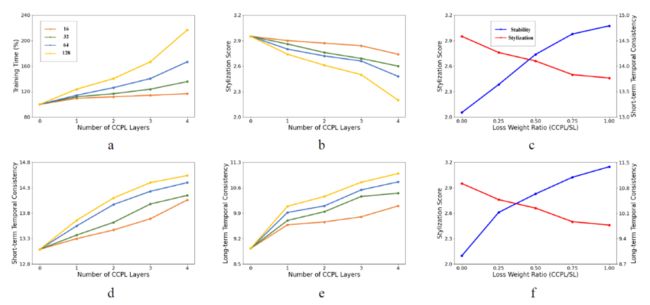
文中展示了CCPL的三种属性(采样中心向量数,计算损失层数,与风格损失的权重比)对于训练时间,风格化程度以及生成视频稳定性程度的影响。可以看到,在文中设定下,训练时间的增长是有限且可控的;在另外一些图中可以看出CCPL对于稳定性和风格化程度的平衡关系,以及和风格损失的制约关系。最终文中选取每层采样64个中心向量,计算后三层特征层以及CCPL和风格损失权重比为0.5作为默认设定。
3.5 应用
文章最后还展示了CCPL的泛化性能,首先作者将CCPL加入了三种经典方法:AdaIN[1],SANet[5], Linear[2]的训练过程中,并将得到的模型与不加CCPL训练的模型进行了比较,效果如下:

可以看到,CCPL对于这些方法同样具有显著的效果提升,其大大减少了图像中的随机风格扰动,并且使得风格化十分贴合内容源的结构和轮廓,提升了生成图像的视觉效果。由于CCPL通用型的设计,它可以被应用于所有基于学习的风格化网络训练中。
文中还展示了CCPL在其他任务(图到图迁移)上的有效性,作者将CCPL加入CUT[6]模型的训练中,在horse2zebra数据集上进行了相同的训练,由下图可以看出,加上CCPL的模型生成的斑马更加合理和逼真,如眼睛等结构也保留的更加完好。同时面对视频输入,CCPL的加入提升了生成视频的稳定性,展示了其广泛的应用潜力。

04
总结
在本文中,作者提出了一种通用的损失函数CCPL应用到通用风格迁移领域。结合论文提出的轻量风格化网络,论文中的方法在多种风格迁移任务中超越了先前的方法。同时本文还展示了CCPL在不同模型,不同任务上的泛化性,展现了其广泛应用的巨大潜力。
相关文献
[1] Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization[C]//Proceedings of the IEEE international conference on computer vision. 2017: 1501-1510.
[2] Li X, Liu S, Kautz J, et al. Learning linear transformations for fast image and video style transfer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 3809-3817.
[3] Wang W, Yang S, Xu J, et al. Consistent video style transfer via relaxation and regularization[J]. IEEE Transactions on Image Processing, 2020, 29: 9125-9139.
[4] Deng Y, Tang F, Dong W, et al. Arbitrary video style transfer via multi-channel correlation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(2): 1210-1217.
[5] Park D Y, Lee K H. Arbitrary style transfer with style-attentional networks[C]//proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 5880-5888.
[6] Park T, Efros A A, Zhang R, et al. Contrastive learning for unpaired image-to-image translation[C]//European conference on computer vision. Springer, Cham, 2020: 319-345.

END
加入「计算机视觉」交流群备注:CV
