如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation
知乎同名账号同步发布。
目录
- 0,参考文献和前置知识和阅读注意
- 1,[ECCV20]Contrastive Learning for Unpaired Image-to-Image Translation
-
- 1.1,创新点和架构
- 1.2,multi-layer、patchwise的对比学习
- 1.3,完整的loss
- 1.4,实验结果
- 1.5,小结
- 2,[CVPR22]Unpaired Deep Image Deraining Using Dual Contrastive Learning
-
- 2.1,方法介绍
- 2.2,复杂的loss
- 3,小结
0,参考文献和前置知识和阅读注意
- 参考文献
本文通过两篇paper,简述一下如何利用对比学习做无监督。
(ECCV20)Contrastive Learning for Unpaired Image-to-Image Translation
(CVPR22)Unpaired Deep Image Deraining Using Dual Contrastive Learning
一个是Image translation,一个是去雨,后者是很新的工作,依次介绍两篇paper。
- 前置知识
第一篇paper需要了解CycleGAN,建议看b站李宏毅的CycleGAN课程,只需要20分钟。当然忽略本文和CycleGAN相关的内容也问题不大。
博主会默认你对对比学习有一定了解。
- 阅读注意
⚠️不要将本文当做对比学习入门文章,如果要入门对比学习,建议b站搜moco,看李沐(朱毅)的课。
⚠️这两篇建议自行阅读的是:(ECCV20)Contrastive Learning for Unpaired Image-to-Image Translation
1,[ECCV20]Contrastive Learning for Unpaired Image-to-Image Translation
1.1,创新点和架构
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第1张图片](http://img.e-com-net.com/image/info8/da29d03d42884b9b8079173cbf2c533b.jpg)
直接看模型架构,做的事情是将马变成斑马。如果不用对比学习,也不用无监督,那么上图会做的事情就是:1,将马通过generator生成斑马;2,使用label做一个loss;3,使用生成的斑马和label做一个对抗损失。
然而众所周知,获取大量有label的数据往往是昂贵的事情,所以无监督得以大火。那么再看上图,如果用无监督训练方法,但不用对比学习,需要做的事情就是:1,搜集很多马的图片,构成集合X,搜集很多斑马的图片,构成集合Y,X和Y中的内容不会一一对应;2,将X中的一张图片输入generator,生成一张假斑马,再从Y中选出一张图片,作为真斑马,真假斑马去构成GAN的loss。听起来挺简单的,但是肯定效果不好,如果你明白CycleGAN的原理,那么你就会明白如果只是这样做,是不太合理的。这个不合理之处,可能会表现为:你输入的是站着的马,但输出的会是坐着的马。这个例子可能有点夸张,但想说明的是:模型丧失了内容的一致性(联想到CycleGAN的cycle consistency)。
有了上述思考后,我们来看作者将对比学习引入无监督训练的动机:作者认为,CycleGAN的确是可以做image translation的,但是它所利用的cycle consistency要求两个domain(如果你不知道domain的含义,就先简单理解成刚才说的集合X和Y)之间拥有双射关系。作者认为这个要求或者说约束过于严格,所以他不想使用循环一致性,但是image translation的确需要保证内容的一致性(将马变成斑马,改变的只能有马身上的花纹,马的形状姿势、背景图案等等都不能有改变)。
而对比学习就能够有助于维持内容的一致性。具体而言,将生成的斑马中选一个patch,作为query;input的马中选若干patch,和query位置相同的patch作为正样本,其他作为负样本:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第2张图片](http://img.e-com-net.com/image/info8/6aabf1657a004ff79c83e310b24a4de5.jpg)
上图的z是query, z + z^+ z+和 z − z^- z−分别是正样本和负样本,然后就可以愉快地做对比学习了。
作者提出了PatchNCE,一种新的对比损失;以及对比学习的负样本是在单张input图片内部选取patch,而不是从数据集中选取其他图片。
1.2,multi-layer、patchwise的对比学习
为了方便起见,模型图再放到这里:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第3张图片](http://img.e-com-net.com/image/info8/46a2b47837f04eae99825c3ac4867c30.jpg)
上图的generator是一个encoder-decoder架构,它的encoder部分连接了灰色的线条,意思就是将马和斑马的图片都要通过这个encoder,选取encoder的L个层输出的feature maps,在特征空间中而不是原图像上来做对比学习。具体见公式:
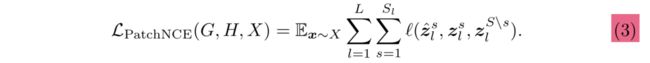
上图的 l l l代表InfoNCE,是一种对比损失,之后会讲它的表达式。H是MLP。注意上式的求和符号, L L L代表一共采用encoder的 L L L个层输出的feature maps来做对比损失,不同层的feature maps中的不同空间位置对应着原图中不同的图像patch,层数越深对应的patch越大。 S l S_l Sl代表当前层的feature maps一共有 S l S_l Sl个spatial locations。 z ^ l = H l ( G e n c l ( G ( x ) ) ) \hat z_l=H_l(G_{enc}^l(G(x))) z^l=Hl(Gencl(G(x))),(其中H代表MLP)表示将生成的斑马通过generator的encoder,在encoder的第 l l l层输出的feature maps,通过MLP获得 z ^ l \hat z_l z^l。 z l = H l ( G e n c l ( x ) ) z_l=H_l(G_{enc}^l(x)) zl=Hl(Gencl(x)),表示将马的图片输入generator的encoder,在encoder的第 l l l层输出的feature maps,通过MLP获得 z l z_l zl。 z ^ l s \hat z_l^s z^ls就是 z ^ l \hat z_l z^l的一个spatial location,它是query, z l s z_l^s zls就是正样本, z l S \ s z_l^{S\backslash s} zlS\s表示 z l z_l zl中s以外的location,它们是负样本。特别注意 z l s ∈ R C l z_l^s∈R^{C_l} zls∈RCl, z l S \ s ∈ R ( S l − 1 ) × C l z_l^{S\backslash s}∈R^{(S_l-1)\times C_l} zlS\s∈R(Sl−1)×Cl, C l C_l Cl表示feature maps的channel数量。每个spatial location对应到原图上,都是一个patch,所以才叫patchwise的对比学习。通过MLP H获得的新feature maps中的每个spatial location,都是一个维度是channel数量的vector。现在我们知道,query、正样本、负样本都是vector,所以可以顺势给出InfoNCE公式的介绍(⚠️在将vector输入下列公式前,需要先将它们归一化至单位球中,以防止空间塌缩或扩张):
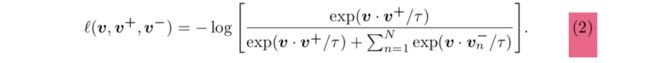
本质上其实就是交叉熵损失函数,它能够拉近query和正样本在特征空间中的距离,同时推开query和负样本在特征空间中的距离。实际上就相当于一个N+1类的分类问题(对query进行分类,类别有一个正样本对应的类和N个负样本对应的类)。
放出作者画的对比损失示意图:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第4张图片](http://img.e-com-net.com/image/info8/4417145e591d4b08b904ae860f642f31.jpg)
1.3,完整的loss
![]()
这个是完整的loss,包含了GAN的loss,不用再多说;patchNCE的loss包含了两项,刚才在1.2中讲述的是前者。后者的含义是input不是普通的马,而是斑马本身,我对这项的理解就是等价于CycleGAN的identity loss。
λ X \lambda_X λX和 λ Y \lambda_Y λY都为1的时候,模型叫CUT; λ X = 10 \lambda_X=10 λX=10, λ Y = 0 \lambda_Y=0 λY=0时,模型叫做FastCUT,可以看做更快更轻量级的CycleGAN。
1.4,实验结果
前两列是作者的方法。其他实验内容就不放在这里了,有需要的可以自行下载paper阅读。
1.5,小结
最大的亮点其实就是负样本仅从单个input图像本身中抽取,作者说这样做使得他们的方法能够在两个域分别只有一张图的时候,训练也是能够进行的:
Our method can operate even when X and Y only contain a single image each.
2,[CVPR22]Unpaired Deep Image Deraining Using Dual Contrastive Learning
2.1,方法介绍
这篇文章的方法不难,但是作者没有选择一个通俗易懂的写法。直接放出架构图:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第5张图片](http://img.e-com-net.com/image/info8/7c9c4bcf381a401a94a32b8423e2c904.jpg)
本质上就是一个CycleGAN结合了对比学习。负责对比学习的模块叫CGB,实际上就是和上篇paper类似,利用将图片经过generator的encoder,再经过MLP获得的若干feature maps,进行对比学习。
不过需要注意的是,作者说之前的方法(就是上篇paper)只在单张input图片内部选取负样本,这在此paper中被称为internal latent codes。作者的意思是负样本也应该在数据集中的其他图片中选取,也就是将internal和external latent codes都用到。
选取负样本的具体做法作者没有讲的很清楚,只有等后续他们放出代码再看了。从文中一直的信息可以知道:对于一个query,作者选取了255个internal的负样本,和256个external的负样本。有可能external的负样本就来自于CycleGAN的另一个cycle consistency分支。
2.2,复杂的loss
作者的loss要素太多:
![]()
第一项是InfoNCE,第三项是GAN的对抗损失。第二项是:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第6张图片](http://img.e-com-net.com/image/info8/4df89b374d4d465c90aca6f5a9884b54.jpg)
作者说对每个通道单独做cycle consistency,这样做的理由是避免cycle consistency loss中存在的通道污染问题。因为如果一次生成一个完整的图像,会导致不同通道相互作用,从而在最终结果中产生伪影。
第四项是:
![如何利用对比学习做无监督——[CVPR22]Deraining&[ECCV20]Image Translation_第7张图片](http://img.e-com-net.com/image/info8/d254752893bf4bcc8953889f7db19ff9.jpg)
FT是傅里叶变换,意思是利用傅里叶变换,在频域也做一个cycle consistency loss。
3,小结
其实两篇paper都是在用对比学习来保证content consistency。无论是马边斑马,还是去雨,其实都是对图像进行部分调整,但一些要素内容不应当发生变化,而不能发生变化的部分,就可以尝试采用对比学习去保证content consistency。但也正如第二篇paper所讲:他们在小规模数据集上表现不佳,因为对比学习往往需要大量的样本才能获取不错的性能:
Limitation. Our method has limitation in SID performance when training on the small-scale datasets, due to contrastive learning tends to require a large number of sample pairs to achieve excellent performance.