pytorch-优化与深度学习
优化与深度学习
优化与估计
尽管优化方法可以最小化深度学习中的损失函数值,但本质上优化方法达到的目标与深度学习的目标并不相同。
- 优化方法目标:训练集损失函数值
- 深度学习目标:测试集损失函数值(泛化性)
%matplotlib inline
import sys
sys.path.append('/home/kesci/input')
import d2lzh1981 as d2l
from mpl_toolkits import mplot3d # 三维画图3d图
import numpy as np
def f(x): return x * np.cos(np.pi * x)
def g(x): return f(x) + 0.2 * np.cos(5 * np.pi * x)
d2l.set_figsize((5, 3))
x = np.arange(0.5, 1.5, 0.01)
fig_f, = d2l.plt.plot(x, f(x),label="train error")
fig_g, = d2l.plt.plot(x, g(x),'--', c='purple', label="test error")
fig_f.axes.annotate('empirical risk', (1.0, -1.2), (0.5, -1.1),arrowprops=dict(arrowstyle='->'))
fig_g.axes.annotate('expected risk', (1.1, -1.05), (0.95, -0.5),arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('risk')
d2l.plt.legend(loc="upper right")
# str是给数据点添加注释的内容,支持输入一个字符串
# xy=是要添加注释的数据点的位置
# xytext=是注释内容的位置
# bbox=是注释框的风格和颜色深度,fc越小,注释框的颜色越深,支持输入一个字典
# va="center", ha="center"表示注释的坐标以注释框的正中心为准,而不是注释框的左下角(v代表垂直方向,h代表水平方向)
# xycoords和textcoords可以指定数据点的坐标系和注释内容的坐标系,通常只需指定xycoords即可,textcoords默认和xycoords相同
# arrowprops可以指定箭头的风格支持,输入一个字典
# 所以总体来说,我们的目标是为了找到测试集合的最小损失
优化在深度学习中的挑战
- 局部最小值
- 鞍点
- 梯度消失
局部最小值
f ( x ) = x cos π x f(x) = x\cos \pi x f(x)=xcosπx
def f(x):
return x * np.cos(np.pi * x)
d2l.set_figsize((4.5, 2.5))
x = np.arange(-1.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, f(x))
fig.axes.annotate('local minimum', xy=(-0.3, -0.25), xytext=(-0.77, -1.0),
arrowprops=dict(arrowstyle='->'))
fig.axes.annotate('global minimum', xy=(1.1, -0.95), xytext=(0.6, 0.8),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');
# 局部最小值和全局最小值
鞍点
- 鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。 在泛函中,既不是极大值点也不是极小值点的临界点,叫做鞍点。 在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。 在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。
x = np.arange(-2.0, 2.0, 0.1)
fig, = d2l.plt.plot(x, x**3)
fig.axes.annotate('saddle point', xy=(0, -0.2), xytext=(-0.52, -5.0),
arrowprops=dict(arrowstyle='->'))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)');
A = [ ∂ 2 f ∂ x 1 2 ∂ 2 f ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ∂ x 1 ∂ x n ∂ 2 f ∂ x 2 ∂ x 1 ∂ 2 f ∂ x 2 2 ⋯ ∂ 2 f ∂ x 2 ∂ x n ⋮ ⋮ ⋱ ⋮ ∂ 2 f ∂ x n ∂ x 1 ∂ 2 f ∂ x n ∂ x 2 ⋯ ∂ 2 f ∂ x n 2 ] A=\left[\begin{array}{cccc}{\frac{\partial^{2} f}{\partial x_{1}^{2}}} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{n}}} \\ {\frac{\partial^{2} f}{\partial x_{2} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{2}^{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{2} \partial x_{n}}} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {\frac{\partial^{2} f}{\partial x_{n} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{n} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{n}^{2}}}\end{array}\right] A=⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
e.g.
x, y = np.mgrid[-1: 1: 31j, -1: 1: 31j]
# print(x)
# print(y)
# 一个是行展开,一个是列展开
z = x**2 - y**2
d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 2, 'cstride': 2})
ax.plot([0], [0], [0], 'ro', markersize=10)
ticks = [-1, 0, 1]
d2l.plt.xticks(ticks)
d2l.plt.yticks(ticks)
ax.set_zticks(ticks)
d2l.plt.xlabel('x')
d2l.plt.ylabel('y');
#从下图看,从一个方向看,他是极大值点,另一个方向看,它是极小值点
梯度消失
x = np.arange(-2.0, 5.0, 0.01)
fig, = d2l.plt.plot(x, np.tanh(x))
d2l.plt.xlabel('x')
d2l.plt.ylabel('f(x)')
fig.axes.annotate('vanishing gradient', (4, 1), (2, 0.0) ,arrowprops=dict(arrowstyle='->'))
Text(2, 0.0, 'vanishing gradient')
凸性 (Convexity):两点连线上的点也在图形内部
基础
集合
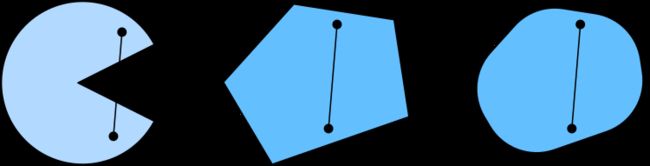
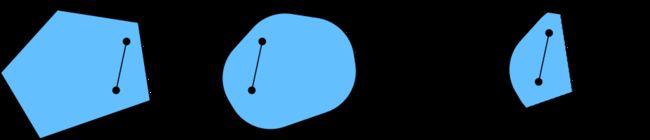
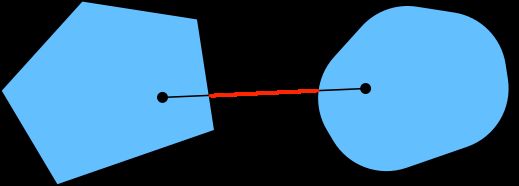
函数
λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) \lambda f(x)+(1-\lambda) f\left(x^{\prime}\right) \geq f\left(\lambda x+(1-\lambda) x^{\prime}\right) λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
def f(x):
return 0.5 * x**2 # Convex
def g(x):
return np.cos(np.pi * x) # Nonconvex
def h(x):
return np.exp(0.5 * x) # Convex
x, segment = np.arange(-2, 2, 0.01), np.array([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):
ax.plot(x, func(x))
ax.plot(segment, func(segment),'--', color="purple")
# d2l.plt.plot([x, segment], [func(x), func(segment)], axes=ax)
Jensen 不等式:数学归纳法证明
∑ i α i f ( x i ) ≥ f ( ∑ i α i x i ) and E x [ f ( x ) ] ≥ f ( E x [ x ] ) \sum_{i} \alpha_{i} f\left(x_{i}\right) \geq f\left(\sum_{i} \alpha_{i} x_{i}\right) \text { and } E_{x}[f(x)] \geq f\left(E_{x}[x]\right) i∑αif(xi)≥f(i∑αixi) and Ex[f(x)]≥f(Ex[x])
性质
- 无局部极小值
- 与凸集的关系
- 二阶条件
无局部最小值
证明:假设存在 x ∈ X x \in X x∈X 是局部最小值,则存在全局最小值 x ′ ∈ X x' \in X x′∈X, 使得 f ( x ) > f ( x ′ ) f(x) > f(x') f(x)>f(x′), 则对 λ ∈ ( 0 , 1 ] \lambda \in(0,1] λ∈(0,1]:
f ( x ) > λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≥ f ( λ x + ( 1 − λ ) x ′ ) f(x)>\lambda f(x)+(1-\lambda) f(x^{\prime}) \geq f(\lambda x+(1-\lambda) x^{\prime}) f(x)>λf(x)+(1−λ)f(x′)≥f(λx+(1−λ)x′)
与凸集的关系
对于凸函数 f ( x ) f(x) f(x),定义集合 S b : = { x ∣ x ∈ X and f ( x ) ≤ b } S_{b}:=\{x | x \in X \text { and } f(x) \leq b\} Sb:={x∣x∈X and f(x)≤b},则集合 S b S_b Sb 为凸集
证明:对于点 x , x ′ ∈ S b x,x' \in S_b x,x′∈Sb, 有 f ( λ x + ( 1 − λ ) x ′ ) ≤ λ f ( x ) + ( 1 − λ ) f ( x ′ ) ≤ b f\left(\lambda x+(1-\lambda) x^{\prime}\right) \leq \lambda f(x)+(1-\lambda) f\left(x^{\prime}\right) \leq b f(λx+(1−λ)x′)≤λf(x)+(1−λ)f(x′)≤b, 故 λ x + ( 1 − λ ) x ′ ∈ S b \lambda x+(1-\lambda) x^{\prime} \in S_{b} λx+(1−λ)x′∈Sb
f ( x , y ) = 0.5 x 2 + cos ( 2 π y ) f(x, y)=0.5 x^{2}+\cos (2 \pi y) f(x,y)=0.5x2+cos(2πy)
x, y = np.meshgrid(np.linspace(-1, 1, 101), np.linspace(-1, 1, 101),
indexing='ij')
z = x**2 + 0.5 * np.cos(2 * np.pi * y)
# Plot the 3D surface
d2l.set_figsize((6, 4))
ax = d2l.plt.figure().add_subplot(111, projection='3d')
ax.plot_wireframe(x, y, z, **{'rstride': 10, 'cstride': 10})
ax.contour(x, y, z, offset=-1)
ax.set_zlim(-1, 1.5)
# Adjust labels
for func in [d2l.plt.xticks, d2l.plt.yticks, ax.set_zticks]:
func([-1, 0, 1])
凸函数与二阶导数
f ′ ′ ( x ) ≥ 0 ⟺ f ( x ) f^{''}(x) \ge 0 \Longleftrightarrow f(x) f′′(x)≥0⟺f(x) 是凸函数
必要性 ( ⇐ \Leftarrow ⇐):
对于凸函数:
1 2 f ( x + ϵ ) + 1 2 f ( x − ϵ ) ≥ f ( x + ϵ 2 + x − ϵ 2 ) = f ( x ) \frac{1}{2} f(x+\epsilon)+\frac{1}{2} f(x-\epsilon) \geq f\left(\frac{x+\epsilon}{2}+\frac{x-\epsilon}{2}\right)=f(x) 21f(x+ϵ)+21f(x−ϵ)≥f(2x+ϵ+2x−ϵ)=f(x)
故:
f ′ ′ ( x ) = lim ε → 0 f ( x + ϵ ) − f ( x ) ϵ − f ( x ) − f ( x − ϵ ) ϵ ϵ f^{\prime \prime}(x)=\lim _{\varepsilon \rightarrow 0} \frac{\frac{f(x+\epsilon) - f(x)}{\epsilon}-\frac{f(x) - f(x-\epsilon)}{\epsilon}}{\epsilon} f′′(x)=ε→0limϵϵf(x+ϵ)−f(x)−ϵf(x)−f(x−ϵ)
f ′ ′ ( x ) = lim ε → 0 f ( x + ϵ ) + f ( x − ϵ ) − 2 f ( x ) ϵ 2 ≥ 0 f^{\prime \prime}(x)=\lim _{\varepsilon \rightarrow 0} \frac{f(x+\epsilon)+f(x-\epsilon)-2 f(x)}{\epsilon^{2}} \geq 0 f′′(x)=ε→0limϵ2f(x+ϵ)+f(x−ϵ)−2f(x)≥0
充分性 ( ⇒ \Rightarrow ⇒):
令 a < x < b a < x < b a<x<b 为 f ( x ) f(x) f(x) 上的三个点,由拉格朗日中值定理:
f ( x ) − f ( a ) = ( x − a ) f ′ ( α ) for some α ∈ [ a , x ] and f ( b ) − f ( x ) = ( b − x ) f ′ ( β ) for some β ∈ [ x , b ] \begin{array}{l}{f(x)-f(a)=(x-a) f^{\prime}(\alpha) \text { for some } \alpha \in[a, x] \text { and }} \\ {f(b)-f(x)=(b-x) f^{\prime}(\beta) \text { for some } \beta \in[x, b]}\end{array} f(x)−f(a)=(x−a)f′(α) for some α∈[a,x] and f(b)−f(x)=(b−x)f′(β) for some β∈[x,b]
根据单调性,有 f ′ ( β ) ≥ f ′ ( α ) f^{\prime}(\beta) \geq f^{\prime}(\alpha) f′(β)≥f′(α), 故:
f ( b ) − f ( a ) = f ( b ) − f ( x ) + f ( x ) − f ( a ) = ( b − x ) f ′ ( β ) + ( x − a ) f ′ ( α ) ≥ ( b − a ) f ′ ( α ) \begin{aligned} f(b)-f(a) &=f(b)-f(x)+f(x)-f(a) \\ &=(b-x) f^{\prime}(\beta)+(x-a) f^{\prime}(\alpha) \\ & \geq(b-a) f^{\prime}(\alpha) \end{aligned} f(b)−f(a)=f(b)−f(x)+f(x)−f(a)=(b−x)f′(β)+(x−a)f′(α)≥(b−a)f′(α)
def f(x):
return 0.5 * x**2
x = np.arange(-2, 2, 0.01)
axb, ab = np.array([-1.5, -0.5, 1]), np.array([-1.5, 1])
d2l.set_figsize((3.5, 2.5))
fig_x, = d2l.plt.plot(x, f(x))
fig_axb, = d2l.plt.plot(axb, f(axb), '-.',color="purple")
fig_ab, = d2l.plt.plot(ab, f(ab),'g-.')
fig_x.axes.annotate('a', (-1.5, f(-1.5)), (-1.5, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('b', (1, f(1)), (1, 1.5),arrowprops=dict(arrowstyle='->'))
fig_x.axes.annotate('x', (-0.5, f(-0.5)), (-1.5, f(-0.5)),arrowprops=dict(arrowstyle='->'))
Text(-1.5, 0.125, 'x')
限制条件
minimize x f ( x ) subject to c i ( x ) ≤ 0 for all i ∈ { 1 , … , N } \begin{array}{l}{\underset{\mathbf{x}}{\operatorname{minimize}} f(\mathbf{x})} \\ {\text { subject to } c_{i}(\mathbf{x}) \leq 0 \text { for all } i \in\{1, \ldots, N\}}\end{array} xminimizef(x) subject to ci(x)≤0 for all i∈{1,…,N}
拉格朗日乘子法
Boyd & Vandenberghe, 2004
L ( x , α ) = f ( x ) + ∑ i α i c i ( x ) where α i ≥ 0 L(\mathbf{x}, \alpha)=f(\mathbf{x})+\sum_{i} \alpha_{i} c_{i}(\mathbf{x}) \text { where } \alpha_{i} \geq 0 L(x,α)=f(x)+i∑αici(x) where αi≥0
惩罚项
欲使 c i ( x ) ≤ 0 c_i(x) \leq 0 ci(x)≤0, 将项 α i c i ( x ) \alpha_ic_i(x) αici(x) 加入目标函数,如多层感知机章节中的 λ 2 ∣ ∣ w ∣ ∣ 2 \frac{\lambda}{2} ||w||^2 2λ∣∣w∣∣2
投影
Proj X ( x ) = argmin x ′ ∈ X ∥ x − x ′ ∥ 2 \operatorname{Proj}_{X}(\mathbf{x})=\underset{\mathbf{x}^{\prime} \in X}{\operatorname{argmin}}\left\|\mathbf{x}-\mathbf{x}^{\prime}\right\|_{2} ProjX(x)=x′∈Xargmin∥x−x′∥2

总结
- 鞍点是对所有自变量一阶偏导数都为0,且Hessian矩阵特征值有正有负的点,代表在某一个方向是极大值点,某一个方向是极小值点
- 假设A和B都是凸集合,那以下是凸集合的是:A和B的交集