人工智能学习(九):贝叶斯网路——墨大版
目录
9.1 什么是贝叶斯网络
9.2 贝叶斯网路的语义
9.2.1 种构造贝叶斯网络的方法
9.2.2 贝叶斯网络中的条件独立关系
9.3 贝叶斯网络中的精确推理
9.3.1 通过枚举进行推理
9.3.2 变量消元算法
9.3.3 不相关的变量
9.4 具体问题学习
9.4.1 联合概率为什么可以表示为局部条件概率表的乘积?
9.4.1.1 变量独立性 vs 条件独立性
9.4.1.2 概率影响的流动性
9.4.1.3 贝叶斯网络中的独立性
9.4.2 贝叶斯网络推理的直观理解
9.1 什么是贝叶斯网络
贝叶斯网络是一个有向图,其中每个结点都标注了定量的概率信息。其完整的说明如下:
每个结点对应一个随机变量(变量可以是离散的或者连续的)。
一组有向边或箭头连接结点对。如果有从结点X指向结点Y的箭头,则称X是Y的一个父结点。
图中没有有向回路(因此被称为有向无环图,或简写为DAG)。
每个结点X,有一个条件概率分布
,量化其父结点对该结点的影响。
一个简单例子:
由Toothache、Cavity、Catch以及Weather构成的简单世界。我们认为Weather 独立于其他变量,而且给定Cavity后Toothache和Catch是条件独立的。

一个稍微复杂的例子:
情景:你在家里安装了一个新防盗报警器。这个报警器探测盗贼很可靠,偶尔也对小地震有反应。你还有两个邻居John和Mary,他们承诺在你工作时如果听到警报声就给你打电话。John有时候会把电话铃声当成警报声,然后给你打电话。Mary 特别喜欢大声听音乐,因此有时根本听不见警报声。给定了他们是否给你打电话的证据,我们希望估计有人入室行窃的概率。
变量:盗贼(B),地震(E),警报(A),JohnCalls(J),MaryCalls(M)。
这个问题域的贝叶斯网络显示在下图中:

网络拓扑结构反映了“因果”知识:
- 窃贼可以触发警报
- 地震可以触发警报
- 警报可会导致玛丽打电话来
- 警报会导致约翰打电话来
网络结构显示盗贼和地震直接影响到警报的概率,但是John或者Mary是否打电话只取决于警报声(他们不直接感知盗贼,也不会注意到轻微的地震,并且他们不会在打电话之前交换意见)。
条件概率表(conditional probability table,CPT):
图中的条件概率分布是用条件概率表给出的。
CPT中的每一行包含了结点的每个取值对于一个条件事件(conditioning case)的条件概率。条件事件就是所有父结点的一个可能的取值组合。
每一行的概率加起来的和必须为1,因为每一行中的条目代表了对应变量的所有的取值情况组成的集合。
对于布尔变量,一旦你知道了它为真的概率为
,那么它为假的概率就是
。因此,我们经常省略第二个数值。
一般而言,一个具有
个布尔父结点的布尔变量的条件概率表中有
个可独立指定的概率。而对于没有父结点的结点而言,它的概率分布表只有一行,表示该变量可能取值的先验概率。
如果每个变量有不超过
个数字。
9.2 贝叶斯网路的语义
从“语法”上看,贝叶斯网络是一个每个结点都附有数值参数的有向无环图。定义贝叶斯网语义的一一种方法是定义它对所有变量的具体的联合分布的表示方式。为此,我们首先需要暂时收回对每个结点所关联的参数的一些说法:我们说过这些参数对应于条件概率![]() ;这种说法是正确的,但在我们从整体上对网络赋予语义之前,我们应该仅仅把它们看作是数值
;这种说法是正确的,但在我们从整体上对网络赋予语义之前,我们应该仅仅把它们看作是数值![]() 。
。
联合分布中的一个一般条目是对每个变量赋一个特定值的合取概率,比如![]() 。我们用符号
。我们用符号![]() 作为这个概率的简化表示。这个条目的值可以由下面的公式给出:
作为这个概率的简化表示。这个条目的值可以由下面的公式给出:

即:

所以对于上一部分,给定了他们是否给你打电话的证据,我们希望估计有人入室行窃的概率是:

9.2.1 种构造贝叶斯网络的方法
公式:
这个公式蕴含了一定的条件独立关系,这些条件独立关系可以用于指导知识工程师们构造网络的拓扑结构。首先,我们利用乘法规则基于条件概率重写联合概率分布:

然后我们重复这个过程,把每个合取概率归约为更小的条件概率和更小的合取概率。最后我们得到一个大的乘法式:

这个等式称为链式规则(chain rule),它对于任何一个随机变量集合都是成立的。将它与公式进行比较就会看到联合分布的详细描述等价于一般断言:对于网络中的每个变量 ,倘若
,倘若![]() ,则
,则

只要按照与蕴含在图结构中的偏序一致的顺序对结点进行编号,这个断言中的条件![]() 就能得到满足。
就能得到满足。
由公式
得到只有当给定了父结点之后,每个结点条件独立于结点排列顺序中的其他祖先结点时,贝叶斯网络才是问题域的正确表示。我们可以用下面的贝叶斯网络构造方法来满足这个条件:
结点(Nodes):
首先确定为了对问题域建模所需要的变量集合。对变量进行排序得到
,任何排列顺序都是可以的,但如果变量的排序使得原因排列在结果之前,则得到的网络会更紧致。
边(Links):
从
到
,执行
- 从
中选择
得到满足。
- 在每个父结点与
- 条件概率表(CPTs): 写出条件概率表
。
例子:
假设我们选择M, J, A, B, E的排序:

![]()

![]()
![]()

![]()
![]()
![]()
![]()

![]()
![]()
![]()
![]()
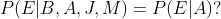
![]()

![]()
![]()
![]()
![]()
![]()
![]()
在非因果方向上决定条件独立性是很难的(症状→原因)。因果模型(原因→症状)和条件独立性,对人类来说似乎更容易!
9.2.2 贝叶斯网络中的条件独立关系
给定父结点,一个结点条件独立于它的其他祖先结点。
我们也可以走另一个方向。我们可以从确定图结构所编码的条件独立关系的“拓扑”语义出发,由此推导出“数值”语义。拓扑语义规定了,给定父结点后,每个变量条件独立于它的非后代结点。例如下图:

给定结点Alarm的取值后,结点JohnCalls条件独立于结点Burglary、Earthquake及MaryCalls。下图(a)说明了这种定义:

从这些条件独立断言,以及将网络参数![]() 解释 为条件概率
解释 为条件概率![]() 。这个意义上,“数值”语义和“拓扑”语义是等价的。
。这个意义上,“数值”语义和“拓扑”语义是等价的。
![]()
拓扑语义蕴含了另一个重要的独立性特性:
给定一个结点的父结点、子结点以及子结点的父结点——也就是说给定它的马尔可夫覆盖(Markov blanket)——这个结点条件独立于网络中的所有其他结点。
例如,给定Alarm和Earthquake后,Burglary独立于JohnCalls及MaryCalls。上图(b)说明了这个特性。
9.3 贝叶斯网络中的精确推理
简单查询:计算后验边际值
。
连接性查询:
所需的概率推理。
信息的价值:接下来要寻找哪些证据?
敏感性分析:哪些概率值是最关键的?
解释:为什么我需要一个新的启动发动机?
我们专注于简单和连带的查询
9.3.1 通过枚举进行推理
以略带智能的方式从联合体中求出变量,而不实际构建其显式表示法。
对盗窃网络的简单查询:


使用CPT条目的乘积重写全部联合条目:

递归深度优先的枚举的空间复杂度是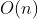 。时间复杂度是
。时间复杂度是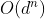 。
。
表达树:

但是枚举法效率低下会有很多重复的计算。例如: 为每个 计算
计算![]() 。
。
9.3.2 变量消元算法
变量消除:从右到左进行求和,存储中间结果(因子)以避免重新计算。

变量消除:基本操作
从一个因子的乘积中求出(Summing out)一个变量:
将任何常数因素移到求和之外在其余因子的点状乘积中加入子矩阵。
![]()
假设![]() 不依赖于
不依赖于 。
。
因子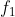 和
和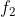 的点状积(Pointwise product):
的点状积(Pointwise product):

例如:![]()
9.3.3 不相关的变量
考虑查询![]()


 的总和为1;
的总和为1; 与查询无关。
与查询无关。

9.4 具体问题学习
对一个学生能否拿到老师的推荐信这一问题进行建模研究。
相关的变量:试题难度、学生智力、考试成绩、高考成绩、是否得到老师推荐信。
如果使用枚举法,参数的个数会有
个(每个变量都有
个取值,一共有
个变量)。
假设变量之间相互独立,联合概率分布大大简化
如何利用图的结构优势降低模型的复杂度?



联合概率分布:
D和P没有父节点,G的父节点是I和D,S的父节点是I,L的父节点是G。



联合概率分布结构化分解的好处:
枚举法:
个参数
结构化分解:
个参数
更一般地,假设
个参数。如果用贝叶斯网络建模,假设每个节点最多有
,一般每个变量局部依赖于少数变量。
9.4.1 联合概率为什么可以表示为局部条件概率表的乘积?
条件独立性
条件独立例子回顾:

联合概率分布链式法则: 条件独立:





9.4.1.1 变量独立性 vs 条件独立性
变量独立性
随机变量 X,Y 相互独立, 如果满足

条件独立性
随机变量 X,Y 在给定 Z 条件下条件独立, 如果满足

9.4.1.2 概率影响的流动性
概率影响的流动性:在一定的观测条件下,变量间的取值概率是否会相互影响。
观测变量:变量取值可观测,或变量取值已经确定
隐变量:变量取值未知,通常根据观测变量取值,对隐变量的取值概率进行推理
考虑 C 是否为观测变量的情况下,变量 A 和 B 的取值概率是否会相互影响
C 为观测变量,变量 A 和 B 的取值是不会相互影响
C 不是观测变量,变量 A 和 B 的取值是会相互影响

W 是否为观测变量,概率影响的流动性

解释一下第一个,当W是不定的时候,X会通过影响W的取值进而影响Y的取值,具备流动性。但是当W是观测变量,值定下来的时候,X就影响不到Y了。

9.4.1.3 贝叶斯网络中的独立性
引理:父节点已知时,该节点与其所有非后代的节点(non-descendants)满足d-separated。

定理:父节点已知时,该节点与其所有非后代的节点(non-descendants)条件独立。

9.4.2 贝叶斯网络推理的直观理解
因果推断(Causal Reasoning):顺着箭头方向推断

证据推断(Evidential Reasoning):逆着箭头推断

交叉因果推断( Intercausal Reasoning ):双向箭头推断
