关系型数据库,NoSQL数据库,NewSQL数据库权威整理
12种数据库的全方位整理:mysql,mariaDB,Percona Server,MongoDB,Redis,RocksDB,TiDB,CouchDB,Cassandra,TokuDB,MemDB,Oceanbase
- 数据库分类
- 数据库分类对比
- ACID规则
- CAP原理
- 关系型数据库
- MySQL
- MariaDB
- Percona Server
- NoSQL数据库
- 键值(Key-Value)存储数据库
- Redis
- RocksDB
- 列存储数据库
- Cassandra
- 文档型数据库
- CouchDB
- MongoDb
- 键值(Key-Value)存储数据库
- NewSQL数据库
- SQL引擎
- TokuDB
- 分布式数据库
- TiDB
- Oceanbase
- MemDB
- SQL引擎
数据库分类
数据库分类对比
| 英文名 | 中文名 | 定义 | 存储方式 | ACID规则支持情况 | CAP原理支持情况 |
|---|---|---|---|---|---|
| Relational database | 关系型数据库 | 采用了关系模型来组织数据的数据库 | 表格 | 支持ACID规则 | 满足CP,但A不完美 |
| NoSQL | 非关系型数据库 | 泛指非关系型的数据库,不保证关系数据的ACID特性 | 键值存储、列存储、文档存储等 | 不一定完全支持ACID规则 | 满足AP,但C不完美 |
| NewSQL | NewSQL | NewSQL是对各种新的可扩展/高性能数据库的简称 | 多种存储方式 | 支持ACID规则 | 满足CAP |
ACID规则
- 原子性(A)
一个事务的所有系列操作步骤被看成一个动作,所有的步骤要么全部完成,要么一个也不会完成。如果在事务过程中发生错误,则会回滚到事务开始前的状态,将要被改变的数据库记录不会被改变。 - 一致性(C)
一致性是指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏,即数据库事务不能破坏关系数据的完整性及业务逻辑上的一致性。 - 隔离性(I)
主要用于实现并发控制,隔离能够确保并发执行的事务按顺序一个接一个地执行。通过隔离,一个未完成事务不会影响另外一个未完成事务。 - 持久性(D)
一旦一个事务被提交,它应该持久保存,不会因为与其他操作冲突而取消这个事务。
CAP原理
- Consistency(一致性): 数据一致更新,所有数据变动都是同步的
- Availability(可用性): 好的响应性能
- Partition tolerance(分区耐受性): 可靠性
举例来说在高可用的网站架构中,对于数据基础提出了以下的要求:
- 分区耐受性
保证数据可持久存储,在各种情况下都不会出现数据丢失的问题。为了实现数据的持久性,不但需要在写入的时候保证数据能够持久存储,还需要能够将数据备份一个或多个副本,存放在不同的物理设备上,防止某个存储设备发生故障时,数据不会丢失。 - 数据一致性
在数据有多份副本的情况下,如果网络、服务器、软件出现了故障,会导致部分副本写入失败。这就造成了多个副本之间的数据不一致,数据内容冲突。 - 数据可用性
多个副本分别存储于不同的物理设备的情况下,如果某个设备损坏,就需要从另一个数据存储设备上访问数据。如果这个过程不能很快完成,或者在完成的过程中需要停止终端用户访问数据,那么在切换存储设备的这段时间内,数据就是不可访问的。
关系型数据库
关系型数据库,是指采用了关系模型来组织数据的数据库
- 关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
- 通过SQL结构化查询语句存储数据。
- 强调ACID规则, 保持数据一致性。
MySQL
| 知识体系 | 存储引擎 | 面试题 | 优化与集群架构 | 源码与配置参数 | 视频资源 | 文章 | Paper | 电子书籍 | 常见问题 |
|---|---|---|---|---|---|---|---|---|---|
| ⭕ |
知识体系
MySQL体系详解
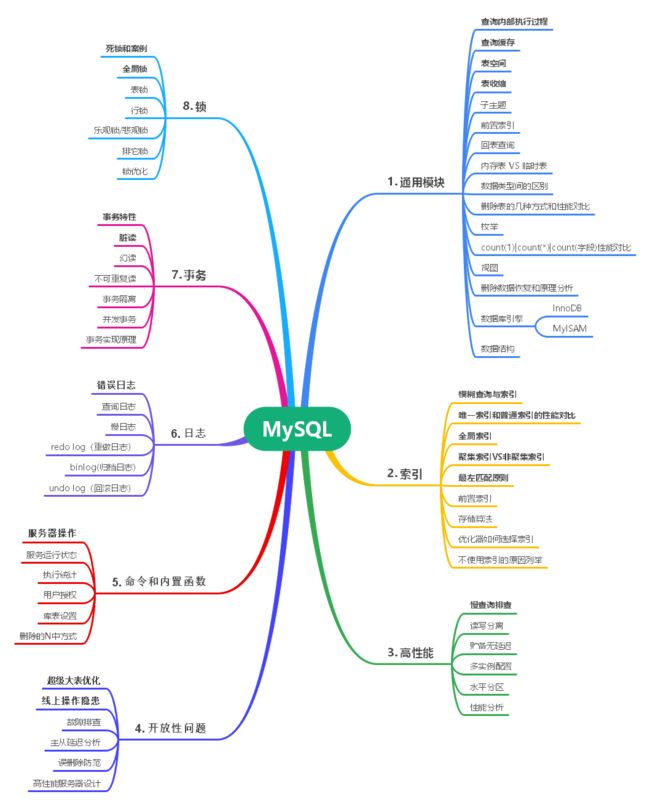
MySQL体系详解
MySQL架构图
MySQL架构图
MySQL亿级订单数据分库分表设计架构图
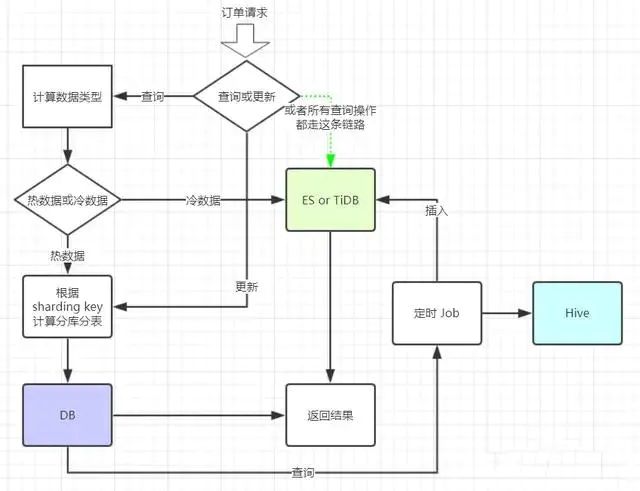
MySQL亿级订单数据分库分表设计架构图(鑫语人间)
MySQL亿级流量系统设计每秒十万查询的高并发架构图
MySQL亿级流量系统设计每秒十万查询的高并发架构图(石杉)
存储引擎
- MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
- InnoDB引擎使用B+Tree作为索引结构,叶节点保存了完整的数据记录(数据和索引)。
- B+树原理详解
MyISAM引擎
MyISAM索引实现
- MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
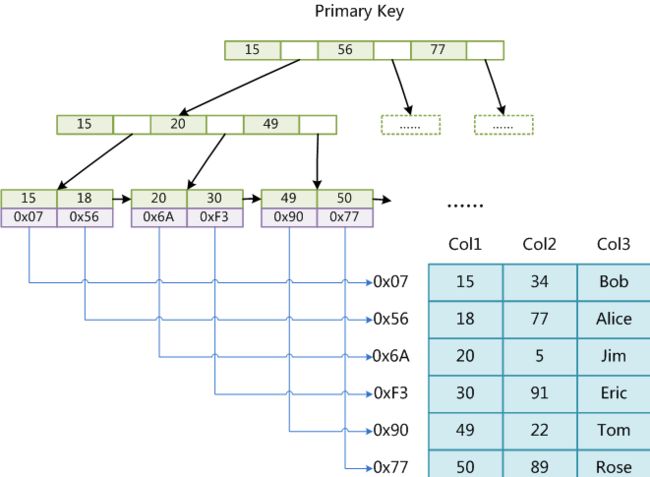
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
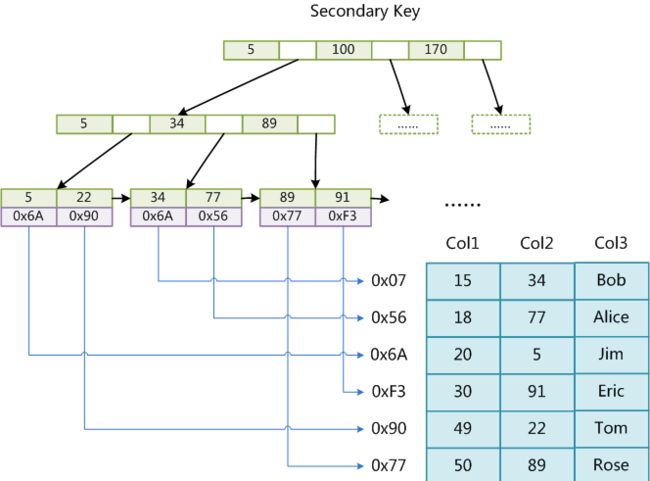
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
MyISAM引擎特点
- 不支持事务
- 表级锁定 数据更新时锁定整个表:其锁定机制是表级锁定,也就是对表中的一个数据进行操作都会将这个表锁定,其他人不能操作这个表,这虽然可以让锁定的实现成本很小但是也同时大大降低了其并发性能。
- 读写互相阻塞 不仅会在写入的时候阻塞读取,MyISAM还会再读取的时候阻塞写入,但读本身并不会阻塞另外的读。
- 只会缓存索引 MyISAM可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。
- 读取速度较快 占用资源相对较少
- 不支持外键约束,但只是全文索引
- MyISAM引擎是MySQL5.5版本之前的默认引擎,是对最初的ISAM引擎优化的产物。
MyISAM引擎适用的生产业务场景
- 不需要事务支持的业务(例如转账就不行,充值也不行)
- 一般为读数据比较多的应用,读写都频繁场景不适合,读多或者写多的都适合。
- 读写并发访问都相对较低的业务(纯读纯写高并发也可以)(锁定机制问题)
- 数据修改相对较少的业务(阻塞问题)
- 以读为主的业务,例如:blog,图片信息数据库,用户数据库,商品库等业务
- 对数据一致性要求不是很高的业务。
- 中小型的网站部分业务会用。
- 小结:单一对数据库的操作都可以示用MyISAM,所谓单一就是尽量纯读,或纯写(insert,update,delete)等。
MyISAM引擎调优精要
- 设置合适的索引(缓存机制)(where、join后面的列建立索引,重复值比较少的建索引等)
- 调整读写优先级,根据实际需求确保重要操作更优先执行,读写的时候可以通过参数设置优先级。
- 启用延迟插入改善大批量写入性能(降低写入频率,尽可能多条数据一次性写入)。
- 尽量顺序操作让insert数据都写入到尾部,较少阻塞。
- 分解大的操作,降低单个操作的阻塞时间,就像操作系统控制cpu分片一样。
- 降低并发数(减少对MySQL访问),某些高并发场景通过应用进行排队队列机制Q队列。
- 对于相对静态(更改不频繁)的数据库数据,充分利用Query Cache(可以通过配置文件配置)或memcached缓存服务可以极大的提高访问频率。
- MyISAM的Count只有在全表扫描的时候特别高效,带有其他条件的count都需要进行实际的数据访问。
InnoDB引擎
InnoDB索引实现
- InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。叶节点保存了完整的数据记录(数据和索引)。
InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
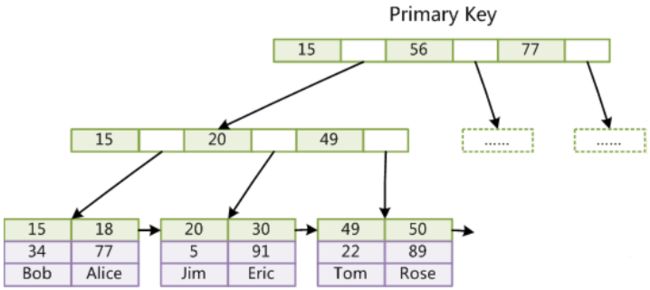
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
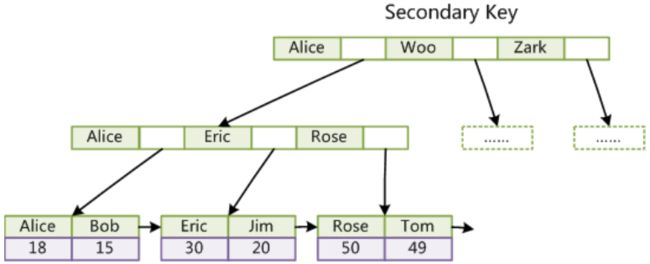 这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
InnoDB引擎适用的生产业务场景
- 支持事务
- 行级锁定对高并发有很好的适应能力,但需要确保查询是通过索引完成。
- 数据更新较为频繁的场景,如:BBS(论坛)、SNS(社交平台)、微博等
- 数据一致性要求较高的业务,例如:充值转账,银行卡转账。
- 硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,尽可能减少磁盘IO,可以通过一些参数来设置
- 相比MyISAM引擎,Innodb引擎更消耗资源,速度没有MyISAM引擎快
InnoDB引擎调优精要
- 主键尽可能小,避免给Secondery index带来过大的空间负担。
- 避免全表扫描,因为会使用表锁。
- 尽可能缓存所有的索引和数据,提高响应速度,较少磁盘IO消耗。
- 在大批量小插入的时候,尽量自己控制事务而不要使用autocommit自动提交,有开关可以控制提交方式。
- 合理设置innodb_flush_log_at_trx_commit参数值,不要过度追求安全性。 如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作。
- 避免主键更新,因为这会带来大量的数据移动。
其他引擎
- 其他引擎
⭕ 面试题
- 1. 能说下myisam 和 innodb的区别吗?
- 2. 说下mysql的索引有哪些吧,聚簇和非聚簇索引又是什么?
- 3. 那你知道什么是覆盖索引和回表吗?
- 4. 锁的类型有哪些呢?
- 5. 你能说下事务的基本特性和隔离级别吗?
- 6. 那ACID靠什么保证的呢?
- 7. 那你说说什么是幻读,什么是MVCC?
- 8. 那你知道什么是间隙锁吗?
- 9. 你们数据量级多大?分库分表怎么做的?
- 10. 那分表后的ID怎么保证唯一性的呢?
- 11. 分表后非sharding_key的查询怎么处理呢?
- 12. 说说mysql主从同步怎么做的吧?
- 13. 那主从的延迟怎么解决呢?
- 14. 为什么用自增列作为主键?
- 15. 为什么使用数据索引能提高效率?
- 16. B+树索引和哈希索引的区别?
- 17. 哈希索引的优势?
- 18. 哈希索引不适用的场景?
- 19. B树和B+树的区别?
- 20. 为什么说B+比B树更适合实际应用中操作系统的文件索引和数据库索引?
- 21. MySQL联合索引?
- 22. 什么情况下应不建或少建索引?
- 23. 什么是表分区?
- 24. 表分区与分表的区别?
- 25. 表分区有什么好处?
- 26. 分区表的限制因素?
- 27. 如何判断当前MySQL是否支持分区?
- 28. MySQL支持的分区类型有哪些?
- 29. 四种隔离级别?
- 30. 关于MVVC的运行原理介绍?
- 31. 在MVCC并发控制中,读操作可以分成两类?
- 32. 行级锁定的优点有哪些?
- 33. 行级锁定的缺点有哪些?
- 34. 你对MySQL优化了解多少?
- 35. key和index的区别?
- 36. Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
- 37. 数据库表创建注意事项?
- 38. MyISAM和InnoDB存储引擎使用的锁?
- 39. 数据库一个大表如何优化?
- 40. 如何理解字符集及校对规则?
优化与集群架构
- MySQL体系结构和组件
- MySQL架构体系
- MySQL调优策略
源码与配置参数
- MySQL5.7源码地址: https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-boost-5.7.18.tar.gz
- MySQL8.0源码地址: https://cdn.mysql.com//Downloads/MySQL-8.0/mysql-8.0.19.tar.gz
- MySQL源码文件结构及主要数据结构
- MySQL5.7配置文件
- MySQL8.0配置文件
视频资源
- MySQL不了解这些,好意思说搞懂了MySQL
- 性能优化的方法论,异步的原理与实现,mysqlredis,dns, http,服务器并发
- 大厂面试,Mysql必问的问题
- MySQL的块数据操作
- mysql索引 myisam,innodb,b树b+树
- 一节课搞懂 MySQL 索引和事务
- 90分析搞懂mysql索引及其优化
- 90分钟搞懂MySQL InnoDB索引以及事务
- 90分钟搞懂mysql缓存问题的解决方案
- 大厂如何解决mysql读写效率问题
- 你所需要掌握的MySQL基本原理:索引和事务
- —节课搞懂MySQL索引和事务
- —节课详尽讲解提升MySQL读写性能的方案
- 高并发场景下,mysql与redis的数据同步方案
文章
| No. | Article | Author |
|---|---|---|
| 1 | MySQL远程客户端连接问题 | milo |
| 2 | 亿级订单数据分库分表设计方案 | 鑫语人间 |
| 3 | 数据库扩展性架构设计 | |
| 4 | 分库分表需要考虑的问题及方案 | |
| 5 | 无限容量数据库架构设计 | |
| 6 | MQ消息可达性+幂等性+延时性架构设计 | |
| 7 | 高可用+高并发+负载均衡架构设计 | |
| 8 | 数据库秒级平滑扩容架构方案 | |
| 9 | 100亿数据平滑数据迁移,不影响服务 | |
| 10 | 一分钟掌握数据库垂直拆分 | |
| 11 | 5kw数据量,如何为表增加一列 | |
| 12 | 互联网在线表结构变更 | |
| 13 | 58同城,1万属性100亿数据量数据库架构设计 |
电子书籍
| 书籍 | 翻译 |
|---|---|
| 《MySQL 5.7 Reference Manual》 | 《MySQL 5.7参考手册》 |
| 《MySQL 8.0 Reference Manual》 | 《MySQL 8.0参考手册》 |
| 《MySQL》 | 《MySQL》 |
| 《MySQL Notes For Professionals》 | 《MySQL专业指南》 |
| 《Intrusion Detection with SNORT: Using SNORT, Apache, MySQL, PHP, and ACID》 | 《Snort入侵检测:使用Snort、Apache、MySQL、PHP和ACID》 |
| 《MySQL 从入门到精通》 | 《MySQL 从入门到精通》 |
| 《MySQL Workbench教程》 | 《MySQL Workbench教程》 |
| 《高性能MySQL_中文版》 | 《高性能MySQL(中文版)》 |
| 《高性能MySQL(英文版)》 | 《高性能MySQL(英文版)》 |
| 《MySQL技术内幕:SQL编程》 | 《MySQL技术内幕:SQL编程》 |
| 《MySQL技术内幕:InnoDB存储引擎 第二版》 | 《MySQL技术内幕:InnoDB存储引擎 第二版》 |
Paper
| No. | Title | Translate | Company |
|---|---|---|---|
| 1 | 《MySQL V5 - Ready forPrime Time Business Intelligence》 | MySQL V5 - 为黄金时段商业智能做好准备 | |
| 2 | 《TDSQL for MySQL Security White Paper Product Documentation》 | TDSQL for MySQL安全白皮书产品文档 | |
| 3 | 《MONGODB VS MYSQL: A COMPARATIVE STUDY OF PERFORMANCE IN SUPER MARKET MANAGEMENT SYSTEM》 | MONGODB与MYSQL:超市管理系统性能的比较研究 | |
| 4 | 《Optimizing MySQL Database System on Information Systems Research , Publications and Community Service》 | 在信息系统研究、出版物和社区服务方面优化MySQL数据库系统 | |
| 5 | 《A Comparative Study: MongoDB vs MySQL》 | MongoDB与MySQL的比较研究 | |
| 6 | 《Best Practices for Migrating MySQL Databases to Amazon Aurora》 | 将MySQL数据库迁移到Amazon Aurora的最佳实践 | |
| 7 | 《Comparative Performance Analysis of MySQL and SQL Server Relational Database Management Systems in Windows Environment》 | Windows环境下MySQL与sqlserver关系数据库管理系统性能比较分析 | |
| 8 | 《MySQL Cluster Internal Architecture》 | MySQL集群内部架构 | |
| 9 | 《MySQL Database Service with HeatWave》 | MySQL数据库服务与HeatWave | |
| 10 | 《Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases》 | Amazon Aurora:高通量云本地关系数据库的设计考虑 | |
| 11 | 《Recovery Principles of MySQL Cluster 5.1》 | MySQL集群的恢复原理 |
⚒ 集群架构
常见问题
- 远程客户端连接问题
- 库表设计问题
- 慢SQL问题
MariaDB
MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品。
在存储引擎方面,使用XtraDB来代替MySQL的InnoDB。
MariaDB基于事务的Maria存储引擎,替换了MySQL的MyISAM存储引擎。
MariaDB直到5.5版本,均依照MySQL的版本。
MariaDB项目
- MariaDB项目地址。
- MySQ迁移到MariaDB。
- MariaDB优势。
- MariaDB是MySQL的二进制替代品
MariaDB与MySQL比较
- MariaDB与MySQL特性比较
- MariaDB与MySQL兼容性比较
- MariaDB各个发行版的异同
- MariaDB发行注记
MariaDB第三方工具
- DBEdit 一个免费的MariaDB数据库和其他数据库管理应用程序。
- Navicat 一系列Windows、Mac OS X、Linux下专有数据库管理应用程序。
- HeidiSQL 一个Windows上自由和开放源码的MySQL客户端。它支持MariaDB的5.2.7版本和以后的版本。[5][6]
- phpMyAdmin 一个基于网络的MySQL数据库管理应用程序
Percona Server
Percona Server项目
Percona Server由领先的MySQL咨询公司Percona发布。
Percona Server是一款独立的数据库产品,其可以完全与MySQL兼容,可以在不更改代码的情况了下将存储引擎更换成XtraDB。是最接近官方MySQL Enterprise发行版的版本。
Percona提供了高性能XtraDB引擎,还提供PXC高可用解决方案,并且附带了percona-toolkit等DBA管理工具箱。
Percona Server 只包含 MySQL 的服务器版,并没有提供相应对 MySQL 的 Connector 和 GUI 工具进行改进。
Percona Server 使用了一些 google-mysql-tools, Proven Scaling, Open Query 对 MySQL 进行改造。
- Percona Server项目地址
- Percona XtraDB群集
- Percona XtraDB Cluster安装
- Galera Cluster
MySQL,MariaDB,Percona Server如何选择
综合多年使用经验和性能对比,首选Percona分支,其次是MariaDB,如果你不想冒一点风险,那就选择MYSQL官方版本。
NoSQL数据库
键值(Key-Value)存储数据库
- 相关产品: Redis、RocksDB
- 典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
- 数据模型: 一系列键值对
- 优势: 快速查询
- 劣势: 存储的数据缺少结构化
Redis
| 知识体系 | 数据类型 | 面试题 | 优化与集群架构 | 源码与配置参数 | 视频资源 | 文章 | Paper | 电子书籍 | 常见问题 |
|---|---|---|---|---|---|---|---|---|---|
| ♨ | ⭕ |
知识体系
Redis知识体系图

Redis知识体系图
Redis Cluster方案图
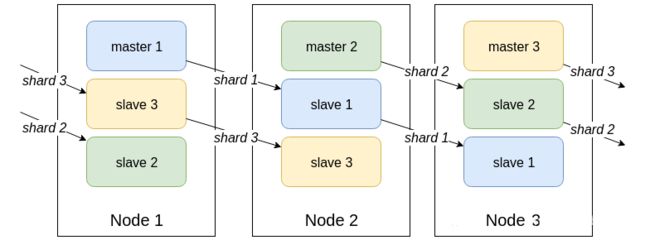
官方Redis Cluster 方案(服务端路由查询)
Redis集群方案(单副本)

Redis集群方案(单副本)
♨ 数据类型
Redis的五大数据类型也称五大数据对象;Redis并没有直接使用这些结构来实现键值对数据库,而是使用这些结构构建了一个对象系统redisObject;
这个对象系统包含了五大数据对象,字符串对象(string)、列表对象(list)、哈希对象(hash)、集合(set)对象和有序集合对象(zset);
而这五大对象的底层数据编码可以用命令OBJECT ENCODING来进行查看。
//redisObjecttypedef struct redisObject {
// 类型属性存储的是对象的类型,也就是我们说的 string、list、hash、set、zset中的一种, //可以使用命令 TYPE key 来查看。
unsigned type:4;
// 编码,记录了队形所使用的编码,即这个对象底层使用哪种数据结构实现。
unsigned encoding:4;
// 指向底层实现数据结构的指针
void *ptr;
// ...
} robj;
redis是以键值对存储数据的,所以对象又分为键对象和值对象,即存储一个key-value键值对会创建两个对象,键对象和值对象。键对象总是一个字符串对象,而值对象可以是五大对象中的任意一种。

- 字符串对象(string)
- 列表对象(list)
- 哈希对象(hash)
- 集合对象(set)
- 有序集合对象(zset)
⭕ 面试题
- 01. Redis相比memcached有哪些优势?
- 02. Redis支持哪几种数据类型?
- 03. Redis主要消耗什么物理资源?
- 04. Redis的全称是什么?
- 05. Redis有哪几种数据淘汰策略?
- 06. Redis官方为什么不提供Windows版本?
- 07. 一个字符串类型的值能存储最大容量是多少?
- 08. 为什么Redis需要把所有数据放到内存中?
- 09. Redis集群方案应该怎么做?都有哪些方案?
- 10. Redis集群方案什么情况下会导致整个集群不可用?
- 11. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据?
- 12. Redis有哪些适合的场景?
- 13. Redis支持的Java客户端都有哪些?官方推荐用哪个?
- 14. Redis和Redisson有什么关系?
- 15. Jedis与Redisson对比有什么优缺点?
- 16. Redis如何设置密码及验证密码?
- 17. 说说Redis哈希槽的概念?
- 18. Redis集群的主从复制模型是怎样的?
- 19. Redis集群会有写操作丢失吗?为什么?
- 20. Redis集群之间是如何复制的?
- 21. Redis集群最大节点个数是多少?
- 22. Redis集群如何选择数据库?
- 23. 怎么测试Redis的连通性?
- 24. Redis中的管道有什么用?
- 25. 怎么理解Redis事务?
- 26. Redis事务相关的命令有哪几个?
- 27. MySQL里有2000w数据,redis中只存20w的数据,如何保证Redis中的数据都是热点数据?
- 28. Redis的并发竞争问题如何解决?
- 29. Redis如何做内存优化?
- 30. Redis回收进程如何工作的?
- 31. Redis回收使用的是什么算法?
- 32. Redis如何做大量数据插入?
- 33. 为什么要做Redis分区?
- 34. 你知道有哪些Redis分区实现方案?
- 35. Redis分区有什么缺点?
- 36. Redis持久化数据和缓存怎么做扩容?
- 37. 分布式Redis是前期做还是后期规模上来了再做好?为什么?
- 38. Twemproxy是什么?
- 39. 支持一致性哈希的客户端有哪些?
- 40. Redis与其他key-value存储有什么不同?
- 41. Redis的内存占用情况怎么样?
- 42. 都有哪些办法可以降低Redis的内存使用情况呢?
- 43. Redis持久化的几种方式?
- 44. 谈谈对Redis的缓存失效策略和主键失效机制的理解?
- 45. Redis 最适合的场景?
- 46. 一个Redis实例最多能存放多少的keys?
- 47. Redis常见性能问题和解决方案?
- 48. Redis提供了哪几种持久化方式?
- 49. 如何选择合适的持久化方式?
- 50. 修改配置不重启Redis会实时生效吗?
优化与集群架构
Redis集群方式
- Redis主从复制
- Redis哨兵模式
- Redis分片模式
源码与配置参数
- Redis-6.2.5.tar.gz
- Redis参数解释
视频资源
- Redis有序集合,跳表
- 性能优化的方法论,异步的原理与实现,mysqlredis,dns, http,服务器并发
- epoll的网络模型,从redis, memcached到nginx
- 如何在开发中使用redis
- Redis训练营一
- Redis训练营二
- Redis实战场景分析
- Redis使用场景实战
- Redis主从复制
- —起实现Redis驱动与Redis协议深度剖析
- 网络服务器模型, Redis, Memcached, Nginx对比
- Redis, Nginx以及Skynet源码分析探究
- TCP网络服务模型,Redis, Nginx,Memcached一起搞定
- 10年大厂程序员是如何学习使用Redis
- 秃顶大佬程序员如何制定Redis学习路线
- 90分钟搞定Redis面试
- 90分钟搞懂Redis存储结构
- Redis,Skynet,Nginx,Memcached网络模块对比分析
- Redis的rehash,布隆过滤器,redis持久化一节课搞定
- Redis如何实现分布式锁延时队列以及限流应用
- 大厂Redis面试,你能get到几个点
- 大厂秋招面试必备-从Redis应用以及原理说起
- 多维度了解Redis以及原理实现
- 手把手带你看Redis, skynet网络模块实现
- —场Redis线上事故引发的思考
- 醍醐灌顶搞懂分布式多播以及消息队列的Redis解决方案
- 茅塞顿开搞懂开源框架(Redis, Nginx, Skynet)中锁的使用
- Redis,Memcached到Nginx,底层网络io中剥离精髓
- 高并发场景下,Mysql与Redis的数据同步方案
- Redis是什么,用来做什么,要掌握到什么程度
文章
后续更新…
Paper
| No. | Title | Translate | Company |
|---|---|---|---|
| 1 | 《Implementing Information System Using MongoDB and Redis》 | 利用MongoDB和Redis实现信息系统 | |
| 2 | 《15 Reasons to use Redis as an Application Cache》 | 使用Redis作为应用程序缓存的15个原因 | |
| 3 | 《AMAZON ELASTICACHE》 | 弹性评估 | |
| 4 | 《PLeveraging Django and Redis using Web Scraping》 | 使用网页抓取对Django和Redis进行编辑 | |
| 5 | 《Cloud Native at the Edge: High-performance Edge Inference with RedisAI》 | 边缘原生云:使用RedisAI进行高性能边缘推断 | |
| 6 | 《Contrail Architecture》 | 轨迹结构 | |
| 7 | 《Database Caching Strategies Using Redis AWS Whitepaper》 | 使用Redis AWS白皮书的数据库缓存策略 | |
| 8 | 《Deploying a Highly Available Distributed Caching Layer on Oracle Cloud Infrastructure using Memcached & Redis》 | 使用Memcached和Redis在Oracle云基础架构上部署高可用的分布式缓存层 | |
| 9 | 《Scaling Memcache at Facebook》 | 在Facebook上扩展Memcache | |
| 10 | 《From advert to action: behavioural insights into the advertising of financial products》 | 从广告到行动:金融产品广告的行为洞察 | |
| 11 | 《Persistent Memory Performance in vSphere 6.7》 | vSphere 6.7中的持久内存性能 | |
| 12 | 《Performance at Scale with Amazon ElastiCache》 | 使用Amazon ElastiCache实现大规模性能 | |
| 13 | 《Redis Enterprise For Financial Services》 | Redis金融服务企业 | |
| 14 | 《Persisting Objects in Redis Key-Value Database》 | 在Redis键值数据库中持久化对象 | |
| 15 | 《Break the Cost and Capacity Barrier with Intel® Optane™ DC Persistent Memory》 | 使用Intel®Optane打破成本和容量壁垒™ DC持久存储器 | |
| 16 | 《Redistribution, Inequality,and Growth》 | 再分配、不平等和增长 | |
| 17 | 《In-Memory Data processing using Redis Database》 | 使用Redis数据库进行内存数据处理 | |
| 18 | 《USING REDIS WITH SOURCEPRO DB》 | 将REDIS与SOURCEPRO DB一起使用 | |
| 19 | 《Redis on Samsung NVMe Benchmarking Results》 | 三星NVMe基准测试结果的Redis |
电子书籍
- 《Redis的主从复制》
- 《Redis存储结构》
- 《Redis实现分析》
- 《Redis与网站架构》
- 《Redis入门指南(第2版)》
- 《Redis在京东到家的订单中的使用》
- 《Redis实战》
- 《Redis原代码分析》
- 《Redis实现分析》
- 《Redis集群》
- 《Redis大数据之路》
- 《深入了解Redis》
- 《大厂Redis面试,你能get到几个点》
- 《新浪微博Redis优化历程》
- 《Redis 多机特性工作原理简介》
- 《Redis设计与实现(第二版)》
- 《Redis编程发布与订阅》
- 《Redis cluster Specification (work in progress)》
常见问题
后续更新…
RocksDB
RocksDB特点:
RocksDB是嵌入式持久化存储系统,它是一个单点高性能的存储DB,不是分布式存储系统。
RocksDB能支持非常高吞吐量的IO读写,可以作为大型分布式存储系统元数据的存储媒介,比如Hadoop Ozone就将其元数据使用RocksDB作为元数据的结果写出。
-
高性能: RocksDB使用一套日志结构的数据库引擎,为了更好的性能,这套引擎是用C++编写的。 Key和value是任意大小的字节流。
-
为快速存储而优化: RocksDB为快速而又低延迟的存储设备(例如闪存或者高速硬盘)而特殊优化处理。 RocksDB将最大限度的发挥闪存和RAM的高度率读写性能。
-
可适配性: RocksDB适合于多种不同工作量类型。 从像MyRocks这样的数据存储引擎, 到应用数据缓存, 甚至是一些嵌入式工作量,RocksDB都可以从容面对这些不同的数据工作量需求。
-
基础和高级的数据库操作: RocksDB提供了一些基础的操作,例如打开和关闭数据库。 对于合并和压缩过滤等高级操作,也提供了读写支持。
-
RocksDB官方网址
-
RocksDB中文网址
RocksDB的典型场景(低延时访问):
- 需要存储用户的查阅历史记录和网站用户的应用
- 需要快速访问数据的垃圾检测应用
- 需要实时scan数据集的图搜索query
- 需要实时请求Hadoop的应用
- 支持大量写和删除操作的消息队列
知识体系
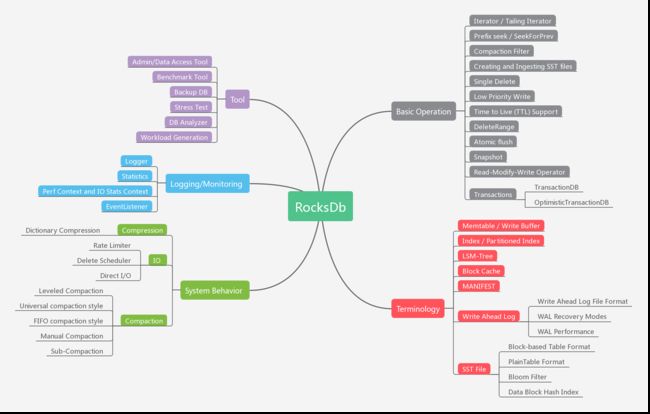
RocksDB5大子模块,分别为:
- Basic Operation,基本操作定义
- Terminology,内部术语定义
- Tool,内部工具
- Logging/Monitoring ,日志和监控
- System Behavior,内部系统行为
高性能存储引擎RocksDB模块详解
列存储数据库
- 相关产品:Cassandra, HBase
- 典型应用:分布式的文件系统
- 数据模型:以列簇式存储,将同一列数据存在一起
- 优势:查找速度快,可扩展性强,更容易进行分布式扩展
- 劣势:功能相对局限
Cassandra
Cassandra是开源分布式NoSQL数据库系统。用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon Dynamo的完全分布式的架构于一身,由于Cassandra良好的可扩展性,现在成为了一种流行的分布式结构化数据存储方案。是一个网络社交云计算方面理想的数据库。
特征
- 分布式
- 基于column的结构化
- 高伸展性
文档型数据库
- 相关产品:CouchDB、MongoDB、SequoiaDB
- 典型应用:Web应用(与Key-Value类似,Value是结构化的)
- 数据模型: 一系列键值对
- 优势:数据结构要求不严格
- 劣势: 查询性能不高,而且缺乏统一的查询语法
CouchDB
后续更新…
MongoDb
NewSQL数据库
SQL引擎
后续更新…
TokuDB
后续更新…
分布式数据库
TiDB
Oceanbase
后续更新…
MemDB
后续更新…