基于SE的半监督元学习网络在小样本故障诊断中的应用
Semi-supervised meta-learning networks with
squeeze-and-excitation attention for few-shot fault diagnosis
基于SE的半监督元学习网络在小样本故障诊断中的应用
代码链接:https://github.com/fyancy/SSMN
本文提出了一种基于挤压和刺激注意的的半监督元学习网络(SSMN)用于少样本故障诊断,其中半监督元学习网络(SSMN)由一个参数编码器、一个非参数化原型细化过程和一个距离函数组成。基于注意机制,这个编码器能够提取不同的特征去生成原型,以增强识别的准确性。通过半监督小样本学习,SSMN利用未标注的数据去细化原始原型,以更好的识别故障。为了能够更有效的优化SSMN设计了一个组合学习优化器。
相关背景
传统的机器学习由于结构较浅,很难从故障数据中获得有代表性的特征。Wen等人提出用图像识别领域成熟的CNN,用于识别旋转机械故障并从原始数据中提取二维深度特征。邵等人提出了一种用于轴承故障检测的连续深层信念网络(CDBN),该网络可以获取轴承振动信号中的深层非线性关系。使用多核方法,通过域自适应获得故障信号在不同条件下的一般特征。
通过对大量前序方法研究的基础上,本文构建了一个基于原型网络的基于度量的元学习网络。所提出的半监督算法能够进一步利用无标签数据细化生成的原型,并显著的增强故障识别准确率。除此之外为了能够进一步增强提取特征的能力,注意机制被利用到所提的方法中以提取更多有效的特征。将经典的随机梯度下降(SGD)优化器和自适应矩估计(Adam)集成为组合优化器,以快速收敛SSMN的训练损失。
有监督的小样本分类
在图像识别中,小样本分类通常被定义为一个只有少量标注样本被给定的分类问题,并且该模型可以适应一些以前从未见过的新任务。其中孪生网络、匹配网络、原型网络和关系网络都是这个领域的杰出代表。
大多数的小样本学习策略遵循情景范式。首先一个含有多个类的标注的数据集![]() 被提供用于训练,一个与训练集不相交的数据集Dtest用于测试。与传统的DL不同FSL,FSL不仅仅是处理一个样本而是处理一个任务(一个支持集和一个查询集的组合),利用训练集Dtrain的两个子集学习泛化能力。FSL训练的内环称为情节(景,episode),外环称为轮回(epoch)。对于每一个情景,情景训练集由两个子集构成,一个是支持集
被提供用于训练,一个与训练集不相交的数据集Dtest用于测试。与传统的DL不同FSL,FSL不仅仅是处理一个样本而是处理一个任务(一个支持集和一个查询集的组合),利用训练集Dtrain的两个子集学习泛化能力。FSL训练的内环称为情节(景,episode),外环称为轮回(epoch)。对于每一个情景,情景训练集由两个子集构成,一个是支持集![]() ,一个是查询集
,一个是查询集![]() 。为了改善模型在不同输入数据集上的泛化能力,该模型通常利用从支持集上学习到的知识最小化在查询集上的分类损失,然后更新模型参数。
。为了改善模型在不同输入数据集上的泛化能力,该模型通常利用从支持集上学习到的知识最小化在查询集上的分类损失,然后更新模型参数。
如果支持集包含N个类每个类包含K个样本,这个分类问题被称为一个N-way K-shot问题。我们考虑将S(支持集)和Q(查询集)的组合,作为一个任务(task),它是小样本分类的基本单位。虽然每一个任务中地样本非常少,但训练集中可能有许多任务可以用于训练。例如:如果一个训练集包含10个类,每一个类中包含20个样本,对于一个3-way 5-shot问题,那么![]() 产生了120个新的任务和
产生了120个新的任务和![]() 个不同得情景。基于这种范式,训练资源足以让模型学习泛化能力。情景范例的核心是模拟仅有少量的样本能够使用的测试环境,这可以促进模型在查询集上有很好的泛化能力。
个不同得情景。基于这种范式,训练资源足以让模型学习泛化能力。情景范例的核心是模拟仅有少量的样本能够使用的测试环境,这可以促进模型在查询集上有很好的泛化能力。
半监督的小样本分类
有监督的小样本学习显示了它在解决数据稀缺问题,同时使用特殊的情景范式改善分类模型泛化能力的潜力。但是小样本训练要求一个数据集包含大量的多类任务,这在图像识别领域容易实现但在故障诊断领域较为困难。在有限类和有限数据量的情况下,有监督的小样本模型的性能会降低。在真实情景中,无标签的数据相比有标签的数据更容易获取,因此半监督的小样本学习方法更可能被使用。
半监督小样本学习的目标是仅仅利用少量有标签的样本和额外无标签的样本为每一个类产生强大的特征表示(原型)。
在本文所提的方法中为无标签的数据使用软聚类。
基于度量的元学习
元学习通常被用于解决小样本分类的问题,因此它也可以被叫做小样本学习。基于度量的元学习方法——原型网络假设从输入数据编码的的特征向量作为一个点存在在嵌入空间中,在嵌入空间中点簇围绕在每个类信号点的周围。一个编码器被构建去实施从输入到映射空间的非线性映射(一个映射函数)。如下图所示,每一个类的原型通过来自支持集的嵌入向量来产生。通过测量多类原型与查询点之间的距离,找到最近的原型,完成对查询集Q的分类。
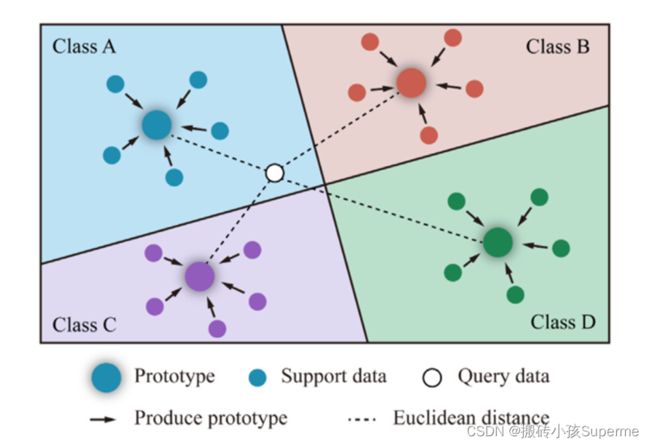
原型网络通过一个嵌入函数![]() 计算原型
计算原型![]() ,该嵌入函数包含了网络的所有学习参数
,该嵌入函数包含了网络的所有学习参数 ,原型
,原型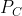 是通过计算支持集中C类嵌入向量的平均值形成的,如下所示:
是通过计算支持集中C类嵌入向量的平均值形成的,如下所示:
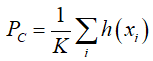 这里K是支持集中每一个类的样本数
这里K是支持集中每一个类的样本数
嵌入查询向量![]() 和原型之间的距离通过距离函数
和原型之间的距离通过距离函数![]() 进行计算,然后的概率通过下边的公式进行计算:
进行计算,然后的概率通过下边的公式进行计算:
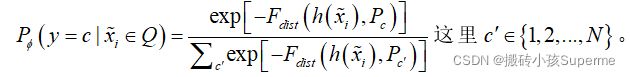
损失函数被定义为在一个训练情境中所有查询集样本的平均负对数概率(即softmax),如下:
 训练时通过最小化该函数,来不断地更新编码器。
训练时通过最小化该函数,来不断地更新编码器。
注意模块
受人类生物系统地启发,注意机制(AM)被使用到许多地神经网络中,因为输入和提取特征的不同部分对于最后输出得贡献各不相同,AM可以通过学习注意权重来增强重要部分,削弱其它部分,以获得一些更有效的推理。简单来说基于AM的输出由加权输出决定,如: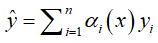 ,其中权重
,其中权重 表示输入的相关性。因此,注意模块现在已经成为了在某些深度神经网络中实现最先进性能的重要组成部分。
表示输入的相关性。因此,注意模块现在已经成为了在某些深度神经网络中实现最先进性能的重要组成部分。
提出的一些注意模块例如初始模块和内外网,以利用卷积运算提取的空间信息来强调模型更感兴趣的区域。有鉴于此,一系列基于卷积层的便携模型被发展。
如果将注意机制(AM)应用到FSL中,可以从特征提取额角度进一步提高识别能力,在本文中,与其它模块相比,挤压核刺激(SE)注意被聚合到SSMN中,以实现更强大的功能核更加短时的计算。
方法论述
提出的方法遵循半监督小样本学习范式的学习策略。在这一个范式中,没有标签的数据被视为支持集的一部分,这将有助于在训练和测试时调整原型的位置。因此,在一个学习情景中支持集可以被定义为:
![]() 在这里U和L分别为在一个情景中的无标签集和带标签集。和分别时U和L中样本的数量。对于半监督小样本分类中的N-way K-shot设置,它仅指标记的支持集而不是整个支持集,即从L(有标签的支持集)中随机的选取
在这里U和L分别为在一个情景中的无标签集和带标签集。和分别时U和L中样本的数量。对于半监督小样本分类中的N-way K-shot设置,它仅指标记的支持集而不是整个支持集,即从L(有标签的支持集)中随机的选取![]() 个有标签的样本以产生N个类的原型。半监督的元学习网络(SSMN)每一个情景的学习策略详细描述如下图所示:
个有标签的样本以产生N个类的原型。半监督的元学习网络(SSMN)每一个情景的学习策略详细描述如下图所示:
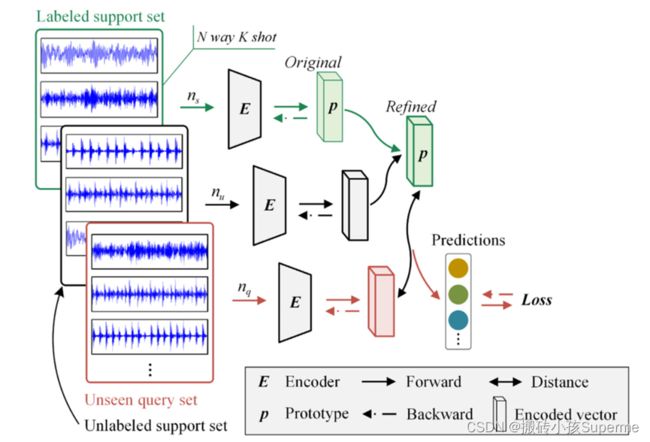
首先来自于有标签的支持集的N-way K-shot样本被输入到模型中去产生每一个类的原始原型,同时对来自无标签的支持集的 个无标签样本进行编码,然后用于改进(细化)原型,这将指示有偏差的原始原型调整其位置,直到在多次迭代中收敛。
个无标签样本进行编码,然后用于改进(细化)原型,这将指示有偏差的原始原型调整其位置,直到在多次迭代中收敛。 个查询样本按细化原型分类,每个查询样本的预测公式如下:
个查询样本按细化原型分类,每个查询样本的预测公式如下:
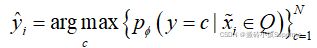 ,这里
,这里![]() 表示一个查询样本属于c类的概率。然后计算损失和反向传播去更新模型。值得注意的是所有提供的用于训练的无标签样本被用来细化每一个情景中的原型。
表示一个查询样本属于c类的概率。然后计算损失和反向传播去更新模型。值得注意的是所有提供的用于训练的无标签样本被用来细化每一个情景中的原型。
SSMN主要包含3个部件,编码器、原型细化和距离函数。具体的结构见下图;
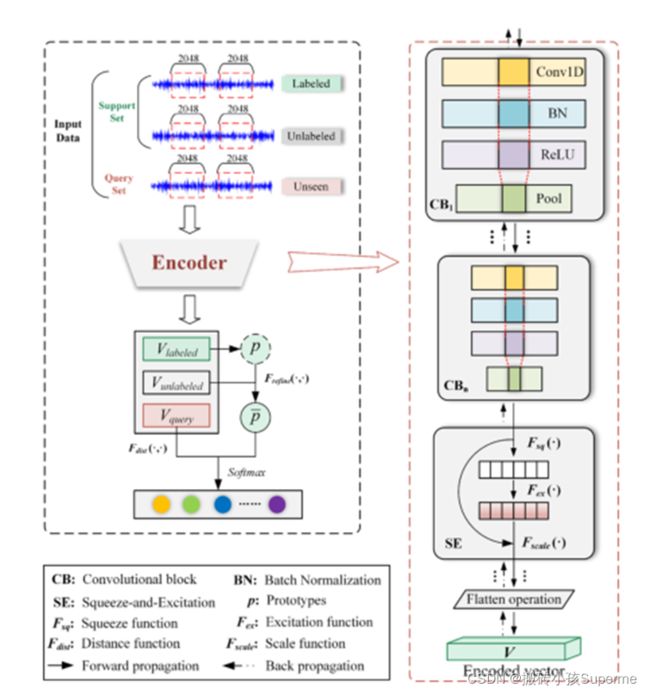
编码器将输入映射到高维嵌入空间,原型细化过程增强了原始原型的质量和距离函数执行预测和分类。
(1) 输入:SSMN的输入样本包括由2048个由时域序列生成的数据点,例如:![]() 。在训练时,输入可以表示为
。在训练时,输入可以表示为![]() ,其中D=2048,
,其中D=2048,![]() 。在输入编码器之前,对样本进行如下的预处理:
。在输入编码器之前,对样本进行如下的预处理: 这里
这里
(2) 编码器:这个编码器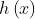 由几个卷积块
由几个卷积块![]() 和挤压和刺激块(SE)构成。每一个CB包含四层:一个一维卷积层
和挤压和刺激块(SE)构成。每一个CB包含四层:一个一维卷积层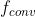 ,一个批量归一化(BN)层,一个激活函数
,一个批量归一化(BN)层,一个激活函数![]() 和一个池化操作
和一个池化操作![]() 。在卷积快中,我们构建了一个BN层来加速训练过程,同时减少由于各层输入分布的不同而导致的协变量偏移。批量归一化的操作如下:
。在卷积快中,我们构建了一个BN层来加速训练过程,同时减少由于各层输入分布的不同而导致的协变量偏移。批量归一化的操作如下:
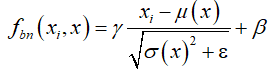 其中
其中 表示第i个输入样本,可学习的参数与分别初始设置为1和0。均值和方差分别被定义为:
表示第i个输入样本,可学习的参数与分别初始设置为1和0。均值和方差分别被定义为:

在这里K表示小批量的大小。激活函数![]() 被描述为;
被描述为;
![]()
让C和W分别表示通道维度和输入数据的长度,然后第n个CB的输出![]() ,可以被描述为:
,可以被描述为:
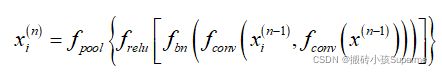
(3) SE 注意:
在SSMN中,编码器采用SE模块去提高从有限数据中提取有效特征的能力。在SSMN中SE块被放在卷积快之后,因此继续使用![]() 表示SE块的输入。首先,输入每个通道的全局空间信息被压缩为标量,如下所示:
表示SE块的输入。首先,输入每个通道的全局空间信息被压缩为标量,如下所示:

这里![]() 表示
表示![]() 的组成部分,
的组成部分,![]() 表示压缩数据。然后由两个线性层和两个激活函数组成的全连接块来处理被挤压操作聚合的信息,如下所示:
表示压缩数据。然后由两个线性层和两个激活函数组成的全连接块来处理被挤压操作聚合的信息,如下所示:
![]()
其中![]() ,r表示通道的减少率,
,r表示通道的减少率,![]() 是sigmoid激活函数表示为;
是sigmoid激活函数表示为;
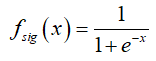
最后通过缩放操作生成输出,如下所示:
![]()
编码器最后的输出,以合并所有通道的特征,如下所示:
![]()
其中![]() 是一个M维的特征向量。
是一个M维的特征向量。
(4)原型细化:在这个过程中,无标签样本被用来矫正原始原型以消除由于有标签支持数据有限所引起的位置偏差。如下图所示,最初的原型无法正确的表示簇质心,因为在一个情景中可用的标记样本非常的少。
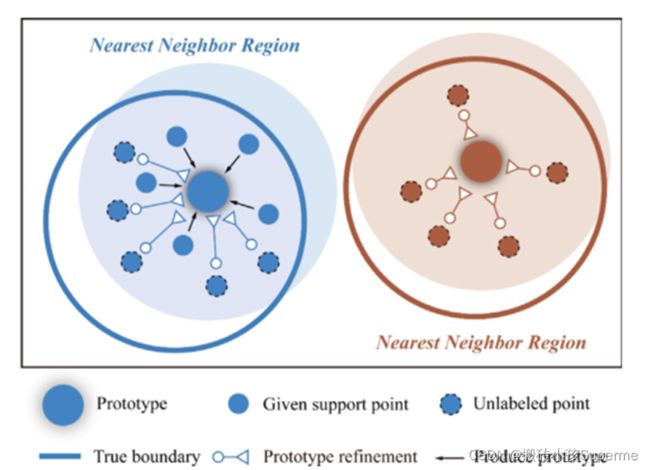
未标签数据可以稍微的引导原型,并将信息合并到原型中去。首先原始原型探测无标签样本并分配给他们软标签即:概率,无标签样本数据的概率被聚合到现有的原型中,并提供更多的信息。具体的算法流程如下图所示:
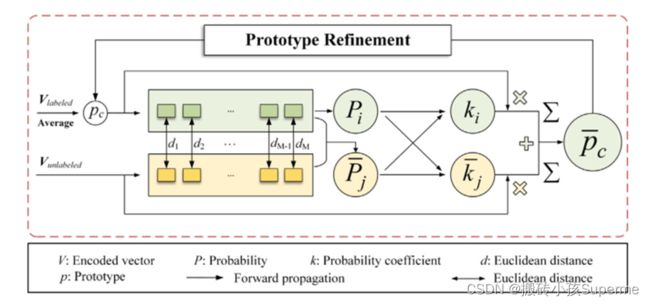
有标签数据被用来产生每一个类的原始原型![]() ,然后在
,然后在![]() 的每个类别上分配标记样本的概率,如下所示:
的每个类别上分配标记样本的概率,如下所示:
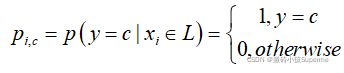
同样,无标记样本的概率通过如下给出:
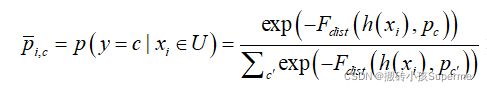 这里欧几里得距离
这里欧几里得距离![]() 被定义为:
被定义为:
 这里
这里![]() 。对于原型细化,我们定义了两个概率系数:
。对于原型细化,我们定义了两个概率系数:

然后每个类的初始原型被与它相对应的概率系数校正:
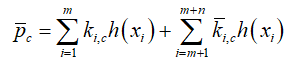 这里
这里![]() 分别表示支持集中每一个类的样本数量和未标注集。我们可以将
分别表示支持集中每一个类的样本数量和未标注集。我们可以将![]() 的值分配给
的值分配给 ,然后连续执行细化过程。
,然后连续执行细化过程。
用细化原型![]() 替换原型,通过细化原型获取查询样本的预测概率。
替换原型,通过细化原型获取查询样本的预测概率。
在优化时采用一个组合优化器能够更加高效。研究发现随机梯度下降(SGD)优化器能够在早期训练阶段快速降低损失,自适应距估计(Adam)能够将损失收敛到相对理想的最小值。因此我们将两个优化器结合起来,并预先确定一个阈值![]() ,将优化器从SGD转换为Adam。当损失大于,参数将会进行如下的更新;
,将优化器从SGD转换为Adam。当损失大于,参数将会进行如下的更新;
![]() 其中
其中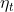 是学习率。
是学习率。
如果损失小于![]() ,参数将会进行如下的更新:
,参数将会进行如下的更新:
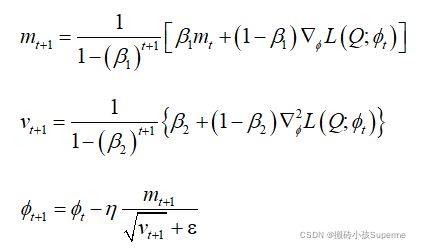
这里 和
和 都是距估计的学习率,
都是距估计的学习率,![]() 和
和![]() 分别是梯度的偏差校正平均值和方差。
分别是梯度的偏差校正平均值和方差。
方法贡献
首先,SSMN基于,基于度量的元学习。所有可学习的参数存在于编码器中,这简化了结构并减少了参数的数量。另外,SSMN采取小样本情景范式的训练策略以改善模型在其它任务上的泛化能力,它通过任务的随机组合来利用有标签数据的潜能。
第二,在SSMN中利用无标签数据发展了半监督小样本学习。一方面,在多次迭代中,原始原型的校准由通过无标签数据来完成,这促进了每一类原型的表示性。
第三,由于应用了注意机制SSMN能够从原始数据中提取有用的特征,这增强了原型的质量和细化过程的稳定性。
最后,SSMN通过组合优化器SDG和Adam进行优化。这种优化方法能够快速减小损失到一个足够理想的最小值。
方法不足
首先,这个度量函数不足够复杂,无法测量出嵌入空间中最好的距离。设计的欧几里得距离在训练和测试时是固定的,但它应该自动选择点之间的最佳距离,尤其是当数据遵循不同的分布式。
第二,我们应该考虑未标签的数据可能不属于任何一类给定的有标签数据的情况。在现实生活中,无标签额数据是随机收集的,不需要手动标记。因此,出现外部类点,未标记的数据可能会影响原型细化。因此原型细化的方法应该在未来的工作中进行改善。
最后,几个超参数的值由经验或实验决定,阈值![]() ,SGD的初始学习率,CB的核大小等等。为了改进,可以将自适应技术运用到所提的方法中。
,SGD的初始学习率,CB的核大小等等。为了改进,可以将自适应技术运用到所提的方法中。
总结
在这一篇文章中,基于挤压核刺激注意的半监督元学习网络被提出用于小样本机械故障诊断。这一种方法客服了机械故障诊断中数据的不足,同时利用无标签数据改善了识别能力。在原型细化中使用无标签数据,提出的半监督方法生成无偏原型进行分类。在编码器中运用注意机制,特征提取能力显著提高。