已解决pandas正确创建DataFrame对象的四种方法(通过list列表、dict字典、ndarray、Series对象创建)
已解决(pandas创建DataFrame对象失败)ValueError: 4 columns passed, passed data had 2 columns
文章目录
- 报错代码
- 报错翻译
- 报错原因
- 解决方法
- 创建DataFrame对象的四种方法
-
- 1. list列表构建DataFrame
- 2. dict字典构建DataFrame
- 3. ndarray创建DataFrame
- 4. Series创建DataFrame
- 帮忙解决
报错代码
粉丝群一个小伙伴想pandas创建DataFrame对象,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错代码如下:
import pandas as pd
data = [[1, 2], [3, 4], [5, 6], [7, 9]]
df = pd.DataFrame(data, columns=list('ABCD'))
print(df)
报错信息截图如下所示:
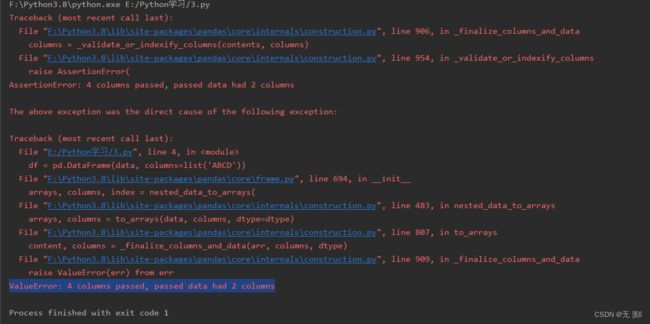
报错翻译
报错信息翻译如下:
值错误:传递了4列,传递的数据有2列
报错原因
报错原因:
粉丝通过嵌套列表创建DataFrame,[1, 2]为两个元素,所以所对应的列也应该是两列,但是columns传递了4列,所以报错。小伙伴们按下面的代码创建即可!!!
解决方法
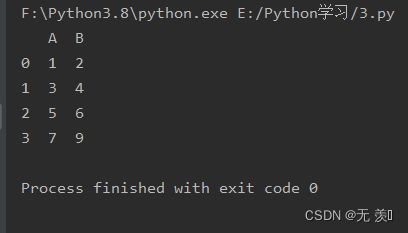
正确的创建语句:
import pandas as pd
data = [[1, 2], [3, 4], [5, 6], [7, 9]]
df = pd.DataFrame(data, columns=list('AB'))
print(df)
运行结果:
创建DataFrame对象的四种方法
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
-
data:一组数据(ndarray、series, map, lists, dict 等类型)。
-
index:索引值,或者可以称为行标签。
-
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
-
dtype:数据类型。
-
copy:拷贝数据,默认为 False。
1. list列表构建DataFrame
1)通过单列表创建
>>> import pandas as pd
>>>
>>> data = [0, 1, 2, 3, 4, 5]
>>> df = pd.DataFrame(data)
>>> print(df)
0
0 0
1 1
2 2
3 3
4 4
5 5
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2)通过嵌套列表创建
>>> import pandas as pd
>>>
>>> data = [['小明', 20], ['小红', 10]]
>>> df = pd.DataFrame(data, columns=['name', 'age'], dtype=float)
sys:1: FutureWarning: Could not cast to float64, falling back to object. This behavior is deprecated. In a future version, when a dtype is passed to 'DataFrame', either all columns will be cast to that dtype, or a TypeError will be raised
>>> print(df)
name age
0 小明 20.0
1 小红 10.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
3)列表中嵌套字典(字典的键被用作列名,缺失则赋值为NaN):
>>> import pandas as pd
>>>
>>> data = [{'A': 1, 'B': 2}, {'A': 3, 'B': 4, 'C': 5}]
>>> df = pd.DataFrame(data)
>>> print(df)
A B C
0 1 2 NaN
1 3 4 5.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2. dict字典构建DataFrame
使用 dict 创建,dict中列表的长度必须相同, 如果传递了index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
1)普通创建:
>>> import pandas as pd
>>>
>>> data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
>>> df = pd.DataFrame(data)
>>> print(df)
name age
0 小红 10
1 小明 20
2 小白 30
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2)设置index创建:
>>> import pandas as pd
>>>
>>> data = {'name': ['小红', '小明', '小白'], 'age': [10, 20, 30]}
>>> df = pd.DataFrame(data, index=['老三', '老二', '老大'])
>>> print(df)
name age
老三 小红 10
老二 小明 20
老大 小白 30
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
3. ndarray创建DataFrame
1)普通方式创建:
>>> import pandas as pd
>>> import numpy as np
>>>
>>> data = np.random.randn(3, 3)
>>> print(data)
[[-1.9332579 0.70876382 -0.44291914]
[-0.26228642 -1.05200338 0.57390067]
[-0.49433001 0.70472595 -0.50749279]]
>>> print(type(data))
<class 'numpy.ndarray'>
>>> df = pd.DataFrame(data)
>>> print(df)
0 1 2
0 -1.933258 0.708764 -0.442919
1 -0.262286 -1.052003 0.573901
2 -0.494330 0.704726 -0.507493
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
2)设置列名创建:
>>> import pandas as pd
>>> import numpy as np
>>>
>>> data = np.random.randn(3, 3)
>>> print(data)
[[-0.22028147 0.62374794 -0.66210282]
[-0.71785439 -1.21004547 1.15663811]
[ 1.47843923 0.4385811 0.31931312]]
>>> print(type(data))
<class 'numpy.ndarray'>
>>> df = pd.DataFrame(data, columns=list("ABC"))
>>> print(df)
A B C
0 -0.220281 0.623748 -0.662103
1 -0.717854 -1.210045 1.156638
2 1.478439 0.438581 0.319313
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
4. Series创建DataFrame
>>> import pandas as pd
>>>
>>> data = {'A': pd.Series(1, index=list(range(4)), dtype='float32'),
... 'B': pd.Series(2, index=list(range(4)), dtype='float32'),
... 'C': pd.Series(3, index=list(range(4)), dtype='float32')
... }
>>> df = pd.DataFrame(data)
>>> print(df)
A B C
0 1.0 2.0 3.0
1 1.0 2.0 3.0
2 1.0 2.0 3.0
3 1.0 2.0 3.0
>>> print(type(df))
<class 'pandas.core.frame.DataFrame'>
帮忙解决
本文已收录于:《告别Bug》专栏
本专栏用于记录学习和工作中遇到的各种疑难Bug问题,以及粉丝群里小伙伴提出的各种问题,文章形式:报错代码 + 报错翻译 + 报错原因 + 解决方法,包括程序安装、运行程序过程中等等问题,订阅专栏+关注博主后如遇到其他问题可私聊帮忙解决!!!