Hadoop 安装 day01 + day02
-
目录
linux要求
伪分布式部署
部署hadoop
hdfs部署
部署yarn
完全分布式部署
1. 准备机器 3台 (bigdata13、bigdata14、bigdata15) 4G 2cpu 40G
2. ssh 免密登录【三台机器都要做】
3.文件发送命令
4.jdk 部署【三台机器都要安装】
5.部署hadoop 先部署bigdata13+ 同步 bigdata13 : nn dn nm bigdata14 : dn rm nm bigdata15 : snn dn nm
每次启动 补充
- 介绍
- 广义:以apache hadoop软件为主的生态圈:hive、flume、hbase、kafka、spark、flink
- 狭义:apache hadoop 软件
- 组成
- hdfs :存储海量的数据(mysql不够放数据)
- mapreduce :计算、数据分析
- yarn :资源和作业的调度
大数据平台:存储是第一位,存储和计算是相辅相成的
- 官网
- hadoop.apache.org
Apache Hadoop软件库是一个框架,允许使用简单的编程模型跨计算机集群对大型数据集进行分布式处理。它旨在从单个服务器扩展到数千台机器,每台机器都提供本地计算和存储。库本身不是依靠硬件来提供高可用性,而是旨在检测和处理应用程序层的故障,因此在计算机群集之上提供高可用性服务,每个计算机群集都可能容易出现故障。 - prohect.apache.org
- hadoop.apache.org
- 版本
1.x 2.x 3.x
主流 : 2.x 3.x
- 原生apache
2.x 3.x - cdh
5.x 6.x
6.3以后开始收费(平台求稳 不是更新)
- 原生apache
- 下载
- 官网
- 历史库:https://archive.a
- 部署
- hdfs 存储海量的数据
- namenode :负责指挥数据的存储 (老大)
- datanode :主要负责数据的村 (小弟)
- seconderynmenode :主要辅助namenode工作 (老二)
- yarn 资源和作业的调度
- resourcemanager :负责指挥资源分配(老大)
- :负责资源分配给谁(小弟)
- 部署模式
Apache Hadoop 3.3.4 – Hadoop: Setting up a Single Node Cluster. //官网部署步骤
- 单点模式 => 伪分布式:

- 完全分布式模式

- 本地分布式
- 单点模式 => 伪分布式:
- hdfs 存储海量的数据
-
linux要求
- 创建hadoop用户,从root切换到hadoop
- hadoop用户家目录
[hadoop@bigdata12 ~]$ mkdir app shell project software data log
- 配置jdk
- 解压
tar -zxvf ./jdk-8u45-linux-x64.gz -C ~/app/ 将压缩包解压到app文件夹中 - 软连接
切换版本 配置先关参数 比较方便[hadoop@bigdata12 app]$ ln -s ./jdk1.8.0_45/ java
[hadoop@bigdata12 app]$ cd java [hadoop@bigdata12 java]$ ll 总用量 25964 drwxr-xr-x. 2 hadoop hadoop 4096 4月 11 2015 bin java相关的脚本 drwxr-xr-x. 3 hadoop hadoop 132 4月 11 2015 include java运行过程中需要jar drwxr-xr-x. 5 hadoop hadoop 185 4月 11 2015 jre drwxr-xr-x. 5 hadoop hadoop 245 4月 11 2015 lib java运行过程中需要jar -rw-r--r--. 1 hadoop hadoop 21099089 4月 11 2015 src.zip java的源码包 - 配置环境变量 : java里面的脚本 在当llinux任何位置都可以使用
-
[hadoop@bigdata12 java]$ vim ~/.bashrc export JAVA_HOME=/home/hadoop/app/java export PATH=${JAVA_HOME}/bin:$PATH [hadoop@bigdata12 ~]$ source ~/.bashrc -
[hadoop@bigdata12 ~]$ java -version //检查是否在linux任何位置都可以使用
-
- 解压
-
伪分布式部署
-
部署hadoop
- 解压
[hadoop@bigdata12 app]$ tar -zxvf ./hadoop-3.3.4.tar.gz -C ~/app/ - 软连接
[hadoop@bigdata12 app]$ ln -s ./hadoop-3.3.4/ hadoop - 目录介绍
[hadoop@bigdata12 hadoop]$ ll 总用量 96 drwxr-xr-x. 2 hadoop hadoop 203 7月 29 21:44 bin hadoop相关脚本 drwxr-xr-x. 3 hadoop hadoop 20 7月 29 20:35 etc hadoop配置文件 drwxr-xr-x. 2 hadoop hadoop 106 7月 29 21:44 include drwxr-xr-x. 3 hadoop hadoop 20 7月 29 21:44 lib drwxr-xr-x. 3 hadoop hadoop 4096 7月 29 20:35 sbin hadoop组件启动停止脚本 drwxr-xr-x. 4 hadoop hadoop 31 7月 29 22:21 share hadoop相关案例删除/app/hadoop/bin中的.cmd文件(可以不删)
[hadoop@bigdata12 bin]$ rm -rf ./*.cmd
- 配置环境变量
-
[hadoop@bigdata12 java]$ vim ~/.bashrc #HADOOP_HOME export HADOOP_HOME=/home/hadoop/app/hadoop export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH [hadoop@bigdata12 ~]$ source ~/.bashrc
-
- 配置参数
etc/hadoop/hadoop-env.sh[hadoop@bigdata12 hadoop]$ vim hadoop-env.sh #插入 export JAVA_HOME=/home/hadoop/app/java [hadoop@bigdata31 hadoop]$ pwd /home/hadoop/app/hadoop/etc/hadoop [hadoop@bigdata12 hadoop]$ hadoop version Hadoop 3.3.4
- 解压
-
hdfs部署
- 1.core-site.xml
fs.defaultFS 指定 namenode 所在机器路径:app/hadoop/etc/hadoop/core-site.xml [hadoop@bigdata12 hadoop]$ vim core-site.xmlfs.defaultFS hdfs://bigdata12:9000 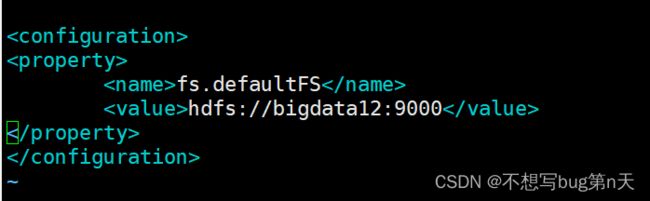
-
2.hdfs-site.xml
[hadoop@bigdata12 hadoop]$ vim hdfs-site.xmldfs.replication 1 - 3.ssh 远程登陆并执行的命令
(切换root用户 设置hadoop用户的密码: password hadoop)
ssh [user@]hostname [command][hadoop@bigdata12 hadoop]$ ssh bigdata12- 官方要求免密登录ssh to the localhost without a passphrase
- 1.ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- 2.cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 3.chmod 0600 ~/.ssh/authorized_keys

- 官方要求免密登录ssh to the localhost without a passphrase
- 4.Format the filesystem:【格式化文件系统】
[hadoop@bigdata12 ~]$ hdfs namenode -format见到“successfully formatted.”则成功
- 5.启动hdfs
路径:/home/hadoop/app/hadoop/bin [hadoop@bigdata12 bin]$ start-dfs.sh- 检查hdfs进程
[hadoop@bigdata12 ~]$ ps -ef | grep hdfs jps路径:app/java/bin/jps [hadoop@bigdata12 ~]$ jps 10740 SecondaryNameNode 10539 DataNode 10381 NameNode 11023 Jps监控:[hadoop@bigdata12 logs]$ cd app/hadoop/logs
[hadoop@bigdata12 logs]$ tail -200f hadoop-hadoop-namenode- bigdata12.log
(没有error即可)
- 检查hdfs进程
- 6.查看namenode web ui
- http://bigdata12:9870/
window需要配置映射,才能打开路径:C:\Windows\System32\drivers\etc\hosts 更改hosts文件 //添加 192.168.41.11 bigdata11 192.168.41.12 bigdata12 192.168.41.13 bigdata13 192.168.41.14 bigdata14 192.168.41.15 bigdata15 192.168.41.16 bigdata16 192.168.41.17 bigdata17 - http://192.168.41.12:9870/ 在浏览器进行搜索

- http://bigdata12:9870/
- 7.操作案例
- hdfs dfs =》 hadoop fs
[hadoop@bigdata12 ~]$ hadoop fs -mkdir /data

- 插入数据
[hadoop@bigdata12 ~]$ vim wc.data [hadoop@bigdata12 ~]$ cat wc.data a a a b b b [hadoop@bigdata12 ~]$ hadoop fs -put ./wc.data /data
- 运行计算程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar-
路径:/home/hadoop/app/hadoop [hadoop@bigdata12 hadoop]$ hadoop jar share/hadoop/ mapreduce/ hadoop-mapreduce-examples-3.3.4.jar -
[hadoop@bigdata12 hadoop]$ hadoop jar share/hadoop /mapreduce/hadoop-mapreduce-examples-3.3.4.jar \ wordcount /data/wc.data /out
运行结果再/out中
结果数据:part - r - 00000
-
- 下载结果数据:
[hadoop@bigdata12 ~]$ cd data [hadoop@bigdata12 data]$ hadoop fs -get /out ./out [hadoop@bigdata12 data]$ ll 总用量 0 drwxr-xr-x. 2 hadoop hadoop 42 11月 12 15:33 out [hadoop@bigdata12 data]$ cd out [hadoop@bigdata12 out]$ ll 总用量 4 -rw-r--r--. 1 hadoop hadoop 8 11月 12 15:33 part-r-00000 -rw-r--r--. 1 hadoop hadoop 0 11月 12 15:33 _SUCCESS [hadoop@bigdata12 out]$ cat part-r-00000 a 3 b 3
- hdfs dfs =》 hadoop fs
- 8.停止hdfs
stop-dfs.sh[hadoop@bigdata12 out]$ jps 12961 Jps 10740 SecondaryNameNode 10539 DataNode 10381 NameNode [hadoop@bigdata12 out]$ stop-dfs.sh Stopping namenodes on [bigdata12] Stopping datanodes Stopping secondary namenodes [bigdata12] [hadoop@bigdata12 out]$ jps 13496 Jps
- 1.core-site.xml
-
部署yarn
- mapred-site.xml
路径:/home/hadoop/app/hadoop/etc/hadoopmapreduce.framework.name yarn mapreduce.application.classpath $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/* - yarn-site.xml
路径:/home/hadoop/app/hadoop/etc/hadoopyarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME - 启动yard
路径:/home/hadoop/app/hadoop/sbin [hadoop@bigdata12 sbin]$ start-yarn.sh
- 打开RM
http://bigdata12:8088/
http://192.168.41.12:8088/
- mapred-site.xml
-
-
完全分布式部署
- 集群划分
- hdfs:
- namenode nn
- datanode dn
- seconderynamenode snn
- yarn :
- resourcemanager rm
- nodemanager nm
bigdata32 : nn dn nm
bigdata33 : dn rm nm
bigdata34 : snn dn nm
- hdfs:
-
1. 准备机器 3台 (bigdata13、bigdata14、bigdata15)
4G 2cpu 40G- 克隆机器
修改虚拟机hostname、ip映射、ip[root@bigdata13 ~]# vim /etc/hostname [root@bigdata14 ~]# vim /etc/hosts [root@bigdata15 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33 - 远程连接3台Xshell
- 克隆机器
-
2. ssh 免密登录【三台机器都要做】
[hadoop@bigdata13 ~]$ mkdir app software data shell project [hadoop@bigdata13 ~]$ ssh-keygen -t rsa- 拷贝公钥
[hadoop@bigdata13 ~]$ssh-copy-id bigdata13 [hadoop@bigdata13 ~]$ssh-copy-id bigdata14 [hadoop@bigdata13 ~]$ssh-copy-id bigdata15
- 拷贝公钥
-
3.文件发送命令
- scp:
scp [[user@]host1:]file1 ... [[user@]host2:]file2[hadoop@bigdata13 ~]$ scp bigdata13:~/1.log bigdata14:~ - rsync:
rsync [OPTION]... SRC [SRC]... [USER@]HOST:DEST - 编写文件同步脚本
脚本名字xsync#路径 /shell #!/bin/bash #三台机器 进行文件发放 if [ $# -lt 1 ];then echo "参数不足" echo "eg:$0 filename..." fi #遍历发送文件到 三台机器 for host in bigdata32 bigdata33 bigdata34 do echo "=============$host==================" #1.遍历发送文件的目录 for file in $@ do #2.判断文件是否存在 if [ -e ${file} ];then pathdir=$(cd $(dirname ${file});pwd) filename=$(basename ${file}) #3.同步文件 ssh $host "mkdir -p $pathdir" rsync -av $pathdir/$filename $host:$pathdir else echo "${file} 不存在" fi done done- 赋予权限
[hadoop@bigdata13 shell]$ vim xsync [hadoop@bigdata13 shell]$ chmod u+x xsync -
给脚本配置环境变量
vim ~/.bashrc //插入 export SHELL_HOME=/home/hadoop/shell export PATH=${PATH}:${SHELL_HOME} [hadoop@bigdata13 shell]$ source ~/.bashrc
- 赋予权限
-
4.jdk 部署【三台机器都要安装】
-
bigdata13 先安装jdk
-
解压、软连接
[hadoop@bigdata13 software]$ tar -zxvf jdk-8u45-linux-x64.gz -C ~/app/ [hadoop@bigdata13 app]$ ln -s jdk1.8.0_45/ java -
配置环境变量
[hadoop@bigdata32 app]$ vim ~/.bashrc #插入JAVA_HOME export JAVA_HOME=/home/hadoop/app/java export PATH=${PATH}:${JAVA_HOME}/bin -
测试
[hadoop@bigdata13 app]$ which java ~/app/java/bin/java [hadoop@bigdata13 app]$ java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode
-
-
bigdata13 同步 jdk安装目录 到其他机器 14 15
[hadoop@bigdata13 app]$ xsync java/ [hadoop@bigdata13 app]$ xsync jdk1.8.0_45 [hadoop@bigdata13 app]$ xsync ~/.bashrc [hadoop@bigdata13 app]$ source ~/.bashrc //三台机器都做
-
-
5.部署hadoop
先部署bigdata13+ 同步
bigdata13 : nn dn nm
bigdata14 : dn rm nm
bigdata15 : snn dn nm-
1. bigdata13先安装hadoop
-
解压、软连接
[hadoop@bigdata13 software]$ tar -zxvf hadoop-3.3.4.tar.gz -C ~/app/ [hadoop@bigdata13 app]$ ln -s hadoop-3.3.4/ hadoop -
配置环境变量
[hadoop@bigdata13 app]$ vim ~/.bashrc #HADOOP_HOME export HADOOP_HOME=/home/hadoop/app/hadoop export PATH=${PATH}:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin [hadoop@bigdata13 app]$ source ~/.bashrc //测试 [hadoop@bigdata13 app]$ which hadoop ~/app/hadoop/bin/hadoop -
【三台机器一起做】
[hadoop@bigdata13 hadoop]$ pwd /home/hadoop/data/hadoop [hadoop@bigdata13 data]$ mkdir hadoop
-
-
2. 配置hdfs
-
·/home/hadoop/app/hadoop/etc/hadoop
core-site.xml:fs.defaultFS hdfs://bigdata32:9000 hadoop.tmp.dir /home/hadoop/data/hadoop dfs.replication 3 dfs.namenode.secondary.http-address bigdata34:9868 dfs.namenode.secondary.https-address bigdata34:9869 -
同步bigdata32内容 到bigdata33 bigdata34
[hadoop@bigdata13 app]$ xsync hadoop [hadoop@bigdata13 app]$ xsync hadoop-3.3.4 [hadoop@bigdata13 app]$ xsync ~/.bashrc 三台机器都要做souce ~/.bashrc -
格式化:
【格式化操作 部署时候做一次即可】namenode在哪 就在哪台机器格式化[hadoop@bigdata13 app]$ hdfs namenode -format -
启动hdfs:
namenode在哪 就在哪启动[hadoop@bigdata13 app]$ start-dfs.sh -
访问namenode web ui:
http://bigdata32:9870/
-
-
3.配置yarn
-
·/home/hadoop/app/hadoop/etc/hadoop
mapred-site.xml:mapreduce.framework.name yarn mapreduce.application.classpath $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/* -
/home/hadoop/app/hadoop/etc/hadoop
yarn-site.xml:yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.env-whitelist JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME yarn.resourcemanager.hostname bigdata33 - bigdata13机器 配置文件分发到bigdata14 15:
[hadoop@bigdata13 app]$ xsync hadoop-3.3.4 - 启动yarn:
resourcemanager在哪 就在哪启动[hadoop@bigdata13 app]$ start-yarn.sh - 访问RM web ui:
bigdata13:8088
-
-
-
每次启动 补充
- 伪分布式 :
hdfs: start-dfs.sh
yarn: start-yarn.sh
启动hadoop : start-all.sh
关闭hadoop :stop-all.sh - 完全分布式 :
start-all.sh =》 rm 所在节点 - 自己编写一个 群起脚本:
[hadoop@bigdata13 ~]$ vim shell/hadoop-cluster #!/bin/bash if [ $# -lt 1 ];then echo "Usage:$0 start|stop" exit fi case $1 in "start") echo "========启动hadoop集群========" echo "========启动 hdfs========" ssh bigdata32 "/home/hadoop/app/hadoop/sbin/start-dfs.sh" echo "========启动 yarn========" ssh bigdata33 "/home/hadoop/app/hadoop/sbin/start-yarn.sh" ;; "stop") echo "========停止hadoop集群========" echo "========停止 yarn========" ssh bigdata33 "/home/hadoop/app/hadoop/sbin/stop-yarn.sh" echo "========停止 hdfs========" ssh bigdata32 "/home/hadoop/app/hadoop/sbin/stop-dfs.sh" ;; *) echo "Usage:$0 start|stop" ;; esac 3.编写查看 java 进程的脚本 [hadoop@bigdata32 ~]$ vim shell/jpsall for host in bigdata32 bigdata33 bigdata34 do echo "==========$host=========" ssh $host "/home/hadoop/app/java/bin/jps| grep -v Jps" done- 赋予权限
[hadoop@bigdata13 shell]$ vim hadoop-cluster [hadoop@bigdata13 shell]$ chmod u+x hadoop-cluster - 启动关闭命令
//启动 [hadoop@bigdata13 ~]$ hadoop-cluster start //关闭 [hadoop@bigdata13 ~]$ hadoop-cluster stop
- 赋予权限
- 伪分布式 :
- scp:
- 分布式启动后的jps
- bigdata13
[hadoop@bigdata13 ~]$ jps 11120 ResourceManager 3847 NameNode 3991 DataNode 11255 NodeManager 11598 Jps - bigdata14
[hadoop@bigdata14 ~]$ jps 10001 Jps 9752 NodeManager 3613 DataNode 3743 SecondaryNameNode -
bigdata15
[hadoop@bigdata15 ~]$ jps 3568 DataNode 8902 Jps 8665 NodeManager
- bigdata13
- 集群划分