select每门可说大于90分_Stata:分位数回归中的样本自选择问题
? 连享会主页:lianxh.cn

New!
lianxh命令发布了:
随时搜索连享会推文、Stata 资源,安装命令如下:. ssc install lianxh
使用详情参见帮助文件 (有惊喜):. help lianxh
连享会 · 名师讲坛
? 空间计量 专题
⌚ 2020.12.10-13? 主讲:杨海生 (中山大学);范巧 (兰州大学)
? 课程主页:https://gitee.com/arlionn/SP

作者: 徐云娇 & 甘徐沁 (厦门大学)邮箱: [email protected] & [email protected]
目录
1. 背景介绍
1.1 样本选择问题 vs 自选择问题
1.2 实例说明
1.3 分位数回归
2. qregsel 命令介绍
2.1 理论部分
2.2 语法结构
3. Stata 实例
4. 结语
5. 参考资料
1. 背景介绍
样本选择问题是实证研究中令人头疼的一个问题,大多数修正样本选择偏差的方法都关注于条件均值模型,但是刻画结果变量的整个分布情况也很重要,所以我们还需要借助分位数回归。
本推文将要介绍的新命令 qregsel 便是在分位数回归的框架下去修正样本选择偏差,为了对此命令的应用场景有更清晰的认识,下面对命令涉及的一些背景知识进行介绍:
1.1 样本选择问题 vs 自选择问题
许多人分不清样本选择偏差 (sample selection bias) 与自选择偏差 (self selection bias),甚至将二者等同起来,这是不太严谨的做法,所以首先有必要对这二者的概念进行区分。
样本选择问题指的是我们所使用的数据无法拿到全样本,比如:失业者的工资数据是缺失的 (不参与劳动力市场有时候并不是失业者的主动选择);自选择问题则指的是模型中的核心解释变量不是随机分配的,而是个体可以自主选择的,比如:比如在研究培训对求职的帮助时,求职者可以自主选择是否参加培训 (慧航, 2020)。
1.2 实例说明
我们以一个经典的例子来帮助大家理解样本选择偏差产生的原因。
当我们研究教育水平对女性工资水平的影响时,就存在样本选择问题。这是因为只有参加了工作的妇女,我们才能观测到其工资水平,而存在某些干扰因素 (比如个体的性格、颜值等),它既会影响妇女是否参加工作,又会影响其工资水平,此时 OLS 的估计系数是有偏的,用因果图可以表示如下:

上图中,干扰因素 和教育水平共同影响着妇女参加工作的效用,而效用是一个被控制住的变量 (只有当效用大于 0 的妇女才会参加工作),所以此时 和教育在样本中产生了相关性,出现了一条衍生路径 “教育 ··· ”,那么教育与工资之间便有了两条路径:一条是因果路径 “教育 工资”;另一条是混淆路径 “教育 ··· 工资”。假如不考虑混淆路径直接进行回归,估计出的系数就会出现样本选择偏差。
Heckman 样本选择模型是修正样本选择偏差的一个模型,详细内容可参见「Heckman 模型:你用对了吗?」。
1.3 分位数回归
Heckman 样本选择模型解决的是条件均值回归中出现的样本选择偏差,但劳动经济学家们也关心收入差距和收入不平等问题,所以此时需要借助分位数回归,更多有关分位数回归的介绍可参见「分位数回归及 Stata 实现」。
那么当存在样本选择问题时,进行分位数回归时该如何去修正选择偏差呢?Stata 新命令 qregsel 便应运而生。
2. qregsel 命令介绍
2.1 理论部分
我们以经典的样本选择模型为例:
其中, 为潜在收入, 为指示变量 (等于 1 时代表个体参与劳动力市场), 和 是误差项, 中包含 变量,并且还包括协变量 。我们可以观测到 ,所以潜在收入 只有在 时才可被观测到。本模型中,样本选择偏差的来源是 和 之间存在相关性。
Arellano & Bonhomme (2017) 提出了分位数回归中解决此样本选择偏差的方法,具体可分为以下三个步骤:
Step1: 估计倾向得分参数
这一步中利用了 Probit 模型进行最大似然估计,可以得到倾向得分参数 的一致估计量 ,用于下面两步中。
Step2: 估计 copula 参数
在基础模型的假设之下 (具体细节可见论文),可以推导得到 的条件累积分布函数 (CDF):
其中, 是条件 copula 函数,它衡量了 和 之间的相关性,即样本选择偏差的来源。
为进一步分析,假设 copula 函数是由参数向量 复合而成的,即:
根据 (5) 式便有矩条件:
其中, 是关于参数 的已知方程。
接下去结合第一步中估计得到的
,通过最小化矩条件来估计 Copla 参数 :其中, 分布于 (0,1), 代表的是欧氏距离, 是定义的工具方程,并且还有:
Step3: 修正的分位数回归在得到了 与 之后,对任意的 ,都可计算:
其中,
我们可以比较修正的分位数回归的 与普通分位数回归的 :
以上可见,为了修正样本选择偏差,传统分位数回归中的 被 所替代了。
2.2 语法结构
qregsel命令是 Siravegna & Munoz (2020) 根据以上估计方法所编写的 Stata 新命令,其语法结构如下:
qregsel depvar varlist [if] [in] , ///
select([depvar_s =] varlist_s) ///
quantile(#) ///
[copula(copula) noconstant finergrid rescale]
depvar:被解释变量;varlist:不进入选择模型的解释变量;select:必需,设定选择模型;[depvar_s]:如果设定,那么需要设定为 0-1 哑变量。其中 0 表示无法观测,1 表示可被观测;varlist_s:进入选择模型的变量;quantile:在特定分位数处进行估计,可设定多个;copula:设定连接函数,可为gaussian或frank,默认为前者;nonconstant:略去截距项估计;finergrid:使用 199 的网格搜索连接函数参数,默认值为 100;rescale:在估计前对解释变量进行标准化。
3. Stata 实例
下面我们用一个调查的女性工资数据来检验此命令。这是一个 Stata 官方在介绍 heckman 命令时所使用的虚拟数据集。
webuse womenwk, clear
/* Notes:
数据中每个个体为一名女性,包括了其工资,以及其他一些人口地理学特征。
其中一部分女性的工资为缺失值,意味着未进入劳动力市场。
county:居住的县
age:年龄
education:受教育年限
married:是否已婚
children:12 岁以下孩子数量
wage:小时工资
*/
我们假设小时工资是教育年限和年龄的函数,而是否参与靠劳动力市场(工资是否被观测到)是婚姻状态、孩子数量以及潜在工资(通过排除年龄和教育)。我们没有对因变量采取对数化是因为在此虚拟数据集中因变量已经是接近正态分布。我们首先进行简单的 OLS 回归:
. reg wage educ age
Source | SS df MS Number of obs = 1,343
----------+---------------------------------- F(2, 1340) = 227.49
Model | 13524.0337 2 6762.01687 Prob > F = 0.0000
Residual | 39830.8609 1,340 29.7245231 R-squared = 0.2535
----------+---------------------------------- Adj R-squared = 0.2524
Total | 53354.8946 1,342 39.7577456 Root MSE = 5.452
---------------------------------------------------------------------------
wage | Coef. Std. Err. t P>|t| [95% Conf. Interval]
----------+----------------------------------------------------------------
education | .8965829 .0498061 18.00 0.000 .7988765 .9942893
age | .1465739 .0187135 7.83 0.000 .109863 .1832848
_cons | 6.084875 .8896182 6.84 0.000 4.339679 7.830071
---------------------------------------------------------------------------
可以看出,当教育年限每上升一年,小时工资会上升 0.897 美元左右。同样,年龄越高——这衡量了工作经验,则工资越高。二者都在 1% 的水平上显著。下面我们使用分位数回归 sqreg 来看一下这两个因素对于不同工资分布区域女性的影响。
. sqreg wage educ age, quantile(.1 .5 .9)
(fitting base model)
Bootstrap replications (20)
----+--- 1 ---+--- 2 ---+--- 3 ---+--- 4 ---+--- 5
....................
Simultaneous quantile regression Number of obs = 1,343
bootstrap(20) SEs .10 Pseudo R2 = 0.1068
.50 Pseudo R2 = 0.1429
.90 Pseudo R2 = 0.1523
------------------------------------------------------------------------------
| Bootstrap
wage | Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
q10 |
education | .8578176 .1010446 8.49 0.000 .6595948 1.05604
age | .1234271 .0252196 4.89 0.000 .073953 .1729012
_cons | .5154006 1.971378 0.26 0.794 -3.351922 4.382723
-------------+----------------------------------------------------------------
q50 |
education | .9064927 .096846 9.36 0.000 .7165064 1.096479
age | .160184 .0285698 5.61 0.000 .1041375 .2162305
_cons | 5.312029 1.283163 4.14 0.000 2.794801 7.829256
-------------+----------------------------------------------------------------
q90 |
education | .930661 .0928315 10.03 0.000 .7485501 1.112772
age | .1579835 .033773 4.68 0.000 .0917298 .2242373
_cons | 12.20975 1.744174 7.00 0.000 8.788146 15.63136
------------------------------------------------------------------------------
观察从上到下,工资三个分位数处的结果,很明显可以观察到,教育的回报率在从 10% 分位数到 50% 分位数,再到 90% 分位数有逐渐升高的过程。但是这一现象的发生并没有考虑样本选择偏差在内。下面我们将女性是否选择进入劳动力市场的自选择视为 婚姻、孩子数量 (与潜在工资) 的结果,使用 qregsel 命令进行估计。
// 注意:qregsel 需要函数 mm_cond。
// 可以使用如下命令进行安装。
/*
ssc install moremata, replace
*/
qregsel wage educ age, select(married children educ age) quantile(.1 .5 .9)
//结果窗口显示:
. qregsel wage educ age, select(married children educ age) quantile(.1 .5 .9) //注意这条命令运行时间比较长
Quantile selection model Number of obs = 1343
| q10 q50 q90
-------------+---------------------------------
education | 1.112866 1.017025 .8888879
age | .204362 .2028979 .2272004
_cons | -8.498507 .5828089 8.914994
. ereturn list
scalars:
e(N) = 1343
e(rank) = 3
e(df_r) = 1340
e(rho) = -.647834836
e(kendall) = -.43389025
e(spearman) = -.63
macros:
e(copula) : "gaussian"
e(depvar) : "wage"
e(indepvars) : "education age _cons"
e(cmdline) : "qregsel wage education age, select(married children educ age)"
e(outcome_eq) : "wage education age"
e(select_eq) : "married children educ age"
e(cmd) : "qregsel"
e(predict) : "qregsel_p"
e(rescale) : "non-rescaled"
e(title) : "Quantile selection model"
matrices:
e(coefs) : 3 x 3
e(grid) : 100 x 4
functions:
e(sample)
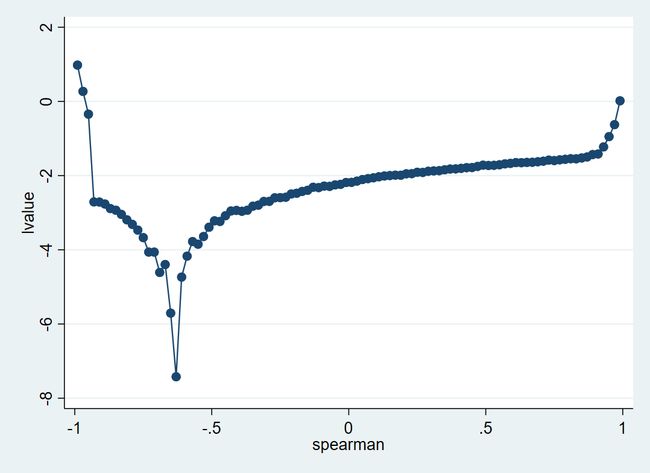
从上述结果可以看到,同不考虑选择偏差的 qreg 结果不同。考虑选择偏差后,从较低工资到较高工资分布的女性教育回报率并不是上升,而是有所下降。其中 的数值大约为 -0.65 ,这可以解释为有更高工资的女性( U 更高)更倾向于参与劳动力市场( V 更低)。同时,我们将目标函数在最小化网格范围内的数值绘制出来。
. svmat e(grid),name(col)
. gen lvalue=log10(value)
(1,900 missing values generated)
输出图如下:
. twoway connected lvalue spearman
在 qregsel 命令之后,我们还可以使用 predict 来估算反事实的结果变量。其语法如下:
predict newvarlist [if] [in]
其中 newvarlist 必须包含两个变量名,第一个为反事实结果变量,第二个为选择哑变量。我们可以使用这个命令来估计修正了样本选择偏差后的反事实的工资分布,并将其和实际观测到的分布进行对比。
set seed 1
/*
注意下面这一行代码可能无法执行,打开安装外部命令的ado文件qregsel_p.ado,在第21行下方加入一行:
if ("`noconstant'"!="") local noconstant ""
如果已经运行过发现无法运行,再修改ado文件的,记得 program drop 噢。
*/
predict wage_hat participation
_pctile wage_hat,nq(20)
mat qs = J(19,3,.)
forvalues i=1/19 {
mat qs[`i',1] = r(r`i')
}
_pctile wage,nq(20)
forvalues i=1/19 {
mat qs[`i',2] = r(r`i')
mat qs[`i',3] = `i'
}
svmat qs, name(quantiles)
twoway connected quantiles1 quantiles2 quantiles3, ///
xtitle("Ventile") ytitle("Wage") legend(order(1 "Corrected" 2 "Uncorrected"))
得到输出图如下:

可以看到,经过修正选择偏差的工资分布处于真实分布之下。最后我们使用 bootstrap 命令来构建 qregsel 中各变量系数在三个不同的分位数处以及连接函数参数 的的标准误。
set seed 2
webuse womenwk,clear
global wage_eqn wage educ age
global seleqn married children educ age
capture program drop myqregsel
program myqregsel, eclass
version 16
tempname bb
quietly qregsel $wage_eqn, select($seleqn) quantile(.1 .5 .9)
local colnames : colfullnames e(coefs)
local rownames : rowfullnames e(coefs)
foreach lname1 of local colnames {
foreach lname2 of local rownames {
local names = "`names' `lname1':`lname2'"
}
}
mata: st_matrix("`bb'", vec(st_matrix("e(coefs)")))
matrix `bb' = `bb',e(rho)
mat colnames `bb' = `names' rho:rho
ereturn post `bb'
ereturn local cmd="bootstrap"
end
bootstrap _b, reps(99) nowarn: myqregsel //这行命令的执行时间可能相当长,需要几小时
得到结果如下:
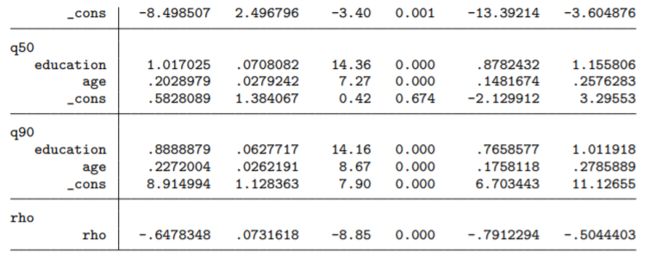
4. 结语
样本选择偏差 (sample selection bias) 是在实证经济学中同内生性问题同样重要的话题。当我们想要研究某种因果关系时,需要关注这种因果关系是否只在某一个群体内成立,以及这种群体具备什么样的特征。例如潜在工资更高的女性更可能去工作,因此直接使用分位数估计可能会产生因为忽略样本选择的而导致的偏差。而我们本次介绍的 qregsel 正是用来解决这一问题。
5. 参考资料
温馨提示: 文中链接在微信中无法生效。请点击底部
- 专题:回归分析
- Stata+R:分位数回归一文读懂 (微信版)
- Stata:分位数回归简介 (微信版)
- 专题:内生性-因果推断
- Heckman 模型:你用对了吗? (微信版)
- Arellano M, Bonhomme S. Quantile selection models with an application to understanding changes in wage inequality[J]. Econometrica, 2017, 85(1): 1-28. -PDF-
- Siravegna M, Munoz E. Implementing quantile selection models in Stata[C]//2020 Stata Conference. Stata Users Group, 2020 (2).-PDF-
? 空间计量 专题 ⌚ 2020.12.10-13
? 主讲:杨海生 (中山大学);范巧 (兰州大学)
? 课程主页:https://gitee.com/arlionn/SP

? ? ? ?
连享会主页:? www.lianxh.cn
直播视频:lianxh.duanshu.com

免费公开课:
- 直击面板数据模型:https://gitee.com/arlionn/PanelData - 连玉君,时长:1小时40分钟
- Stata 33 讲:https://gitee.com/arlionn/stata101 - 连玉君, 每讲 15 分钟.
- Stata 小白的取经之路:https://gitee.com/arlionn/StataBin - 龙志能, 2 小时
- 部分直播课课程资料下载 ? https://gitee.com/arlionn/Live (PPT,dofiles等)
温馨提示: 文中链接在微信中无法生效,请点击底部
关于我们
- ? 连享会 ( 主页:lianxh.cn ) 由中山大学连玉君老师团队创办,定期分享实证分析经验。
- ? 直达连享会:【百度一下:连享会】即可直达连享会主页。亦可进一步添加 主页,知乎,面板数据,研究设计 等关键词细化搜索。
- New!
lianxh命令发布了: 在 Stata 命令窗口中输入ssc install lianxh即可安装,随时搜索连享会推文、Stata 资源,详情:help lianxh。
 连享会主页 lianxh.cn
连享会主页 lianxh.cn
? 连享会小程序:扫一扫,看推文,看视频……

? 扫码加入连享会微信群,提问交流更方便

? 连享会学习群-常见问题解答汇总:
? https://gitee.com/arlionn/WD
New!
lianxh命令发布了:
随时搜索连享会推文、Stata 资源,安装命令如下:. ssc install lianxh
使用详情参见帮助文件 (有惊喜):. help lianxh