作者:京东工业 宛煜昕
测试的覆盖通常是指需求范围的执行程度,如需求、测试用例、缺陷的正向与逆向的双向追溯。便于对其相关属性的度量,即使用了覆盖率。
一、覆盖率与测试策略
覆盖率是度量测试完整性的一个手段,是测试有效性的一个度量。测试覆盖是对测试完全程度的评测。
测试策略按测试过程一般分为单元测试、集成测试、系统测试和验收测试四大阶段;按软件内部工作过程又有白盒、灰盒、黑盒;从过程是否执行软件又可将测试方法分为静态和动态。这样白盒测试对应着软件测试过程中的单元测试,一般由开发人员完成,而灰盒测试与黑盒测试一般测试人员介入较多,对应着集成测试、系统测试和验收测试。
二、覆盖率的基本应用
测试时担心之一就是无止境的、没有范围的,比如代码的改动或调整一个需求,需要全量回归测试,影响范围不清楚,某个功能或功能点是否需要测试,测试的程度如何不清楚等等的问题。
举个例子:需求是查询id与展示id相关数据的功能,进一步分析要做(开发)id输入框,【查询】按钮,显示的列表,涉及1个查询接口(HTTP),查库(数据库)的话,需要1条SQL语句。
开发后得到前端id输入框,【查询】按钮和结果列表,
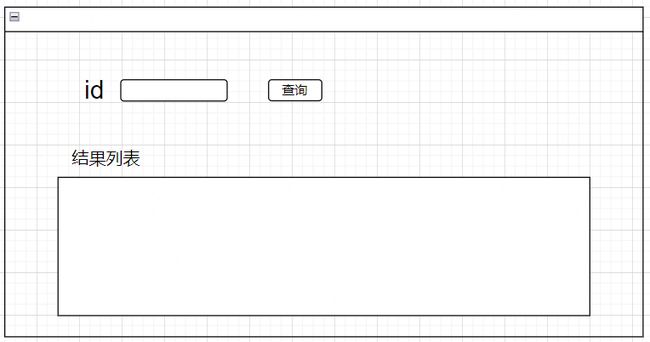
后端是通过一个查询方法调到数据库得到数据,显示在前端页面。
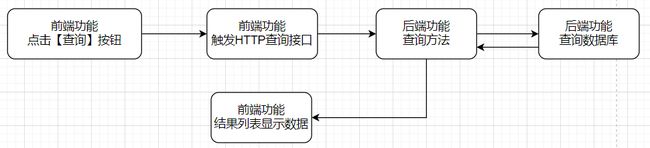
应用测试覆盖率
1、建立测试范围,这里简单些了,只是功能的
| 模块/功能 | 功能点 |
|---|---|
| 查询 | 输入框 |
| 查询 | 查询按钮 |
| 结果列表 | 显示结果列表 |
2、需求分析、用例设计、执行、提bug等,就是执行测试的过程
3、得到功能测试的结果
| 模块/功能 | 功能点 | 测试结果 |
|---|---|---|
| 查询 | 输入框 | 测试通过 |
| 查询 | 查询按钮 | 测试通过 |
| 结果列表 | 显示结果列表 | 测试通过 |
这么看上去没什么问题,双相的追溯(需求、用例、缺陷)已经是全覆盖了,那怕在算上接口,但也仅仅是功能上的覆盖,实则缺失了对代码等层面上的覆盖,
比如:代码中要有对查询id的判断,这里可能会有所遗漏,因为仅从功能或黑盒测试来讲,不知道这个判断是否执行。
这时测试覆盖是要由测试需求和测试用例的覆盖或已执行代码的覆盖表示。建立在对测试结果的评估和对测试过程中确定的变更请求(缺陷)的分析的基础上。
在"2、需求分析、用例设计、执行、提bug等,就是执行测试的过程"要介入代码覆盖率的工具,弥补这一缺失,覆盖率的表格也需要优化下。
后边的类、方法的覆盖率可以根据情况不同自行获取
| 功能/模块 | 功能点 | HTTP接口类型 | HTTP接口 | 类名 | 方法名 | 覆盖率 | 测试结果 |
|---|---|---|---|---|---|---|---|
| 查询 | 输入框 | 无 | 无 | 无 | 无 | 100% | 测试通过 |
| 查询 | 查询按钮 | POST | /api/queryById | query | queryById | 100% | 测试通过 |
| 结果列表 | 显示结果列表 | POST | /api/results | query | results | 100% | 测试通过 |
覆盖率的计算由浅入深来说一般从功能、功能点、接口、代码中类、方法等得到,如:两个功能、三个功能点,以功能点为覆盖,覆盖率公式为(至少执行一次的功能点 / 功能点总数) 100% = (1 / 1)100%,查询按钮的覆盖率为100%
注:测试结果是否通过,不单是看覆盖率,还要通过测试用例的执行,缺陷的关闭等情况来决定。
三、可视化系统
通过完全手工绘制已经有了初步概念,考虑些许情况,这种已经不能满足于此。
面对复杂的业务系统,经验已经把业务功能、逻辑关系等相关知识点深深的印在当事人的脑子里,而要沉淀、展示于旁人,这就是一个让人很头疼的问题,就像告诉一个人从哪里到哪里一样,讲的人清楚,但听得人却有些一头雾水,此时如果有个地图就一目了然了。

通过一些维度的图形展示,谁都可以直观、更好的加深对系统的了解。"知识库"中保存着涉及到的功能、接口等信息。简单实现,现在有了共享表格,可以直接维护上去,形式是哪种并不重要,主要是掌握了方法。
链路关系像这样,业务系统-页面-功能-接口-代码(拓扑图),业务系统-页面-功能-接口-架构(拓扑图)。
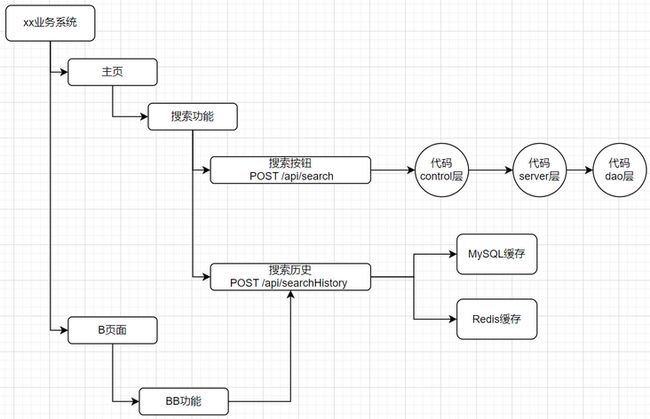
·功能层面
实现方式上比如可以像文件目录那样实现一颗树,某个页面下有哪些功能,功能中有哪些接口,而接口中有代码的类、方法及覆盖率等信息。
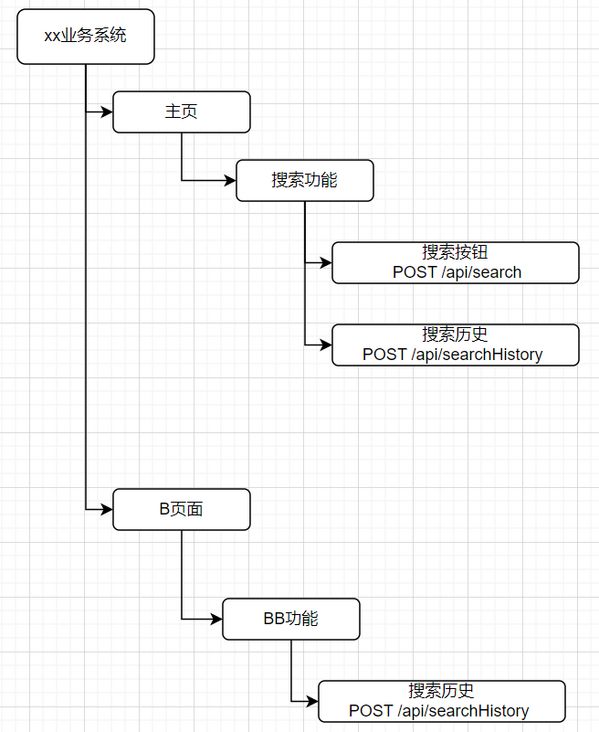
或者可以采用类似知识图谱来构建一个结构化的语义知识库,页面、功能、接口信息,可视为实体-节点,而彼此间的关系既是连接的线。或者接口信息也可看做是属性值。
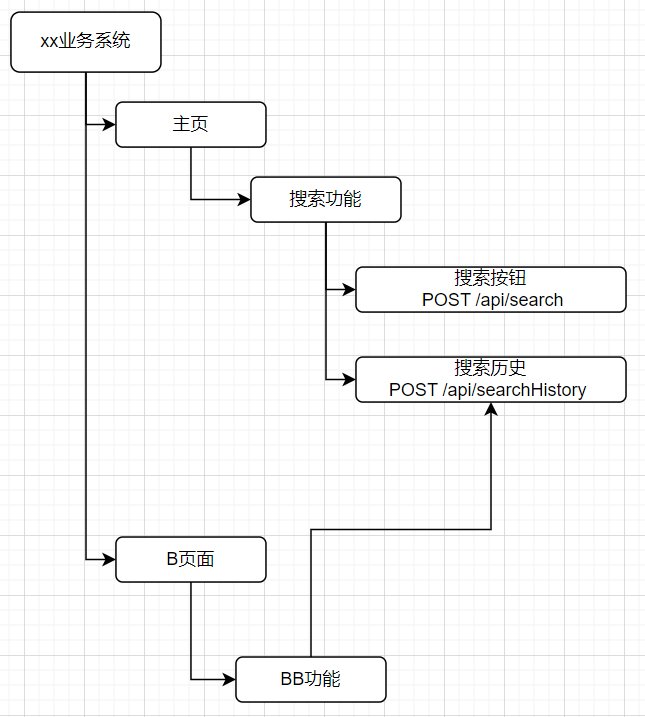
·代码层面
从接口下去就到了代码层面,可以看到代码的关系拓扑图
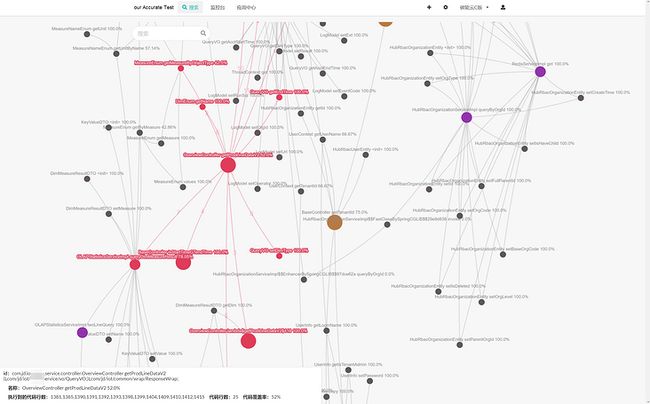
这里不仅能看到单个接口中代码和关系图,还能展示出不同接口与代码的关系
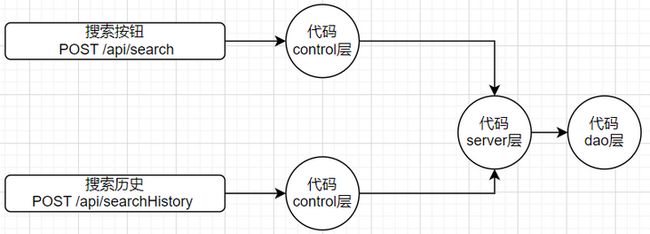
当关注到代码层面的覆盖后,好处很多,其中之一是可以更好帮助开发提高或约束代码质量,比如:代码中有时判断会使用常量,而不是枚举或宏/全局变量。当然也可以看到执行的代码分支,每条代码逻辑分支是否执行到。
·架构层面
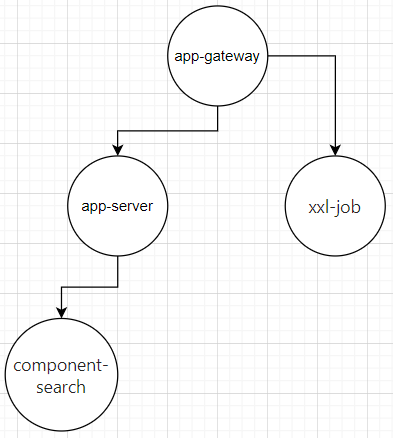
通过平台获取到的数据,不仅可以做功能、代码层面的覆盖,系统架构也可完成可视化的呈现,
比如:应用服务的环境模块拓扑图
分布式调用链的拓扑图
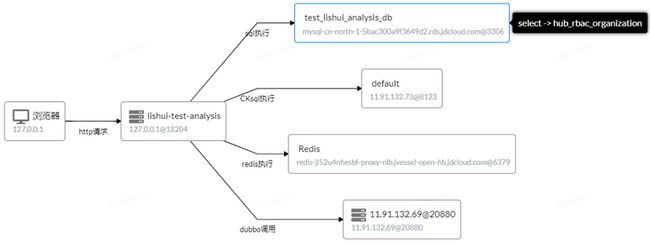
还是用查询功能举例,有时因为一些需要,该功能下使用了缓存。当第一次查询是直接从数据库中查询回来的数据,同时也在缓存中记录了该条数据,而在一定时间内再查询,实则是从缓存中查询回来的。同样的,如果只覆盖了功能,这里可能会有所遗漏,从功能来看,查询后数据是返回了,而至于是从数据库还是从缓存获取到的,就不得而知了。再有是获取到的数据可能未必是想要的,奇怪的是,为什么输入/请求的数据,功能、接口都是一样的,而返回的数据在一段时间后就发生了变化。中间发生了什么不清楚,真的是"黑盒子"。想要知道SQL语句,只能费劲的从日志、代码或xml中查找,还有等等的不便问题。
除此之外,还可以展示不同接口与数据库的关系
只要脑洞够大,通过数据还可以实现出很多覆盖,并呈现出各种可视化图形。
四、未来已来
使用数据驱动将抽象的字符、逻辑等等可视化展示,从而得到想要的效果,但这种效果无论是静态或动态产生的、主动或被动的等等,都会遇到时间的问题,而对时间有着强依赖的我们,无论采用哪种开发方式,即使在快,有着时间的限制和约束,这种苦恼始终会伴随着,在现实世界中目前是无法解决,但有了虚拟世界,现在叫元宇宙,那就不同了,里面有还原现实一切的1比1模型,在虚拟世界里,可以搭建出想要的系统,每一个环节,无论是从项目或需求、产品设计、开发、测试到上线等,都可以清晰的关注到,无论功能与非功能均可以进行模拟,原来的项目或开发周期可能要1年,而现在可能半年不到的时间,虚拟世界的一切贴近现实,最终是通过空间换取时间从而得到这宝贵的经验,然后这种虚拟产物可以搬到现实世界进行应用,从而避免很多试错,也大大压缩、节省了时间。目前这种方式已经慢慢被应用到各个行业、领域,这种虚拟与现实的结合可以更好地服务我们的生活。