多标签评价指标
1. 符号系统
| 记号 | 含义 |
|---|---|
| X \mathcal{X} X | d d d 维实例空间 R d \mathbb{R}^d Rd (或 Z d \mathbb{Z}^d Zd) |
| Y \mathcal{Y} Y | 标签空间,有 q q q 种标签 { y 1 , y 2 , ⋯ , y q } \{y_1,y_2,\cdots,y_q\} {y1,y2,⋯,yq} |
| x i \boldsymbol{x}_i xi | d d d 维特征向量 ( x 1 , x 2 , ⋯ , x d ) ⊤ ( x ∈ X ) (x_1,x_2,\cdots,x_d)^\top(\boldsymbol{x}\in\mathcal{X}) (x1,x2,⋯,xd)⊤(x∈X) |
| Y Y Y | x \boldsymbol{x} x 上存在的标签集合 ( Y ∈ Y ) (Y\in\mathcal{Y}) (Y∈Y) |
| Y ˉ \bar{Y} Yˉ | Y Y Y 在 Y \mathcal{Y} Y 中的补集 |
| S \mathcal{S} S | 测试集 { ( x i , Y i ) ∣ 1 ≤ i ≤ p } \left\{(\boldsymbol{x}_i, Y_i) | 1 \leq i \leq p\right\} {(xi,Yi)∣1≤i≤p} |
| h ( ⋅ ) h(\cdot) h(⋅) | h ( x ) h(\boldsymbol{x}) h(x) 返回对 x \boldsymbol{x} x 的预测标签向量 |
| f ( ⋅ , ⋅ ) f(\cdot,\cdot) f(⋅,⋅) | 实值函数 f : X × Y → R f:\mathcal{X}\times\mathcal{Y}\rightarrow\mathbb{R} f:X×Y→R, f ( x , y ) f(\boldsymbol{x},y) f(x,y) 返回的是一个向量,其中的值代表标签存在的概率 |
| r a n k f ( ⋅ , ⋅ ) rank_f(\cdot,\cdot) rankf(⋅,⋅) | r a n k f ( x , y ) rank_f(\boldsymbol{x},y) rankf(x,y) 返回根据 f ( x , ⋅ ) f(\boldsymbol{x},\cdot) f(x,⋅) 的概率降序排列后, y y y 的排名 |
| ∣ ⋅ ∣ |\cdot| ∣⋅∣ | 返回集合的基数 |
| ⟦ ⋅ ⟧ \llbracket\cdot\rrbracket [[⋅]] | 如果谓词 π \pi π 成立, ⟦ π ⟧ \llbracket\pi\rrbracket [[π]] 返回 1 1 1,否则返回 0 0 0 |
2. example-based 与 label-based
- example-based:先分别评估 h ( ⋅ ) h(\cdot) h(⋅) 对每个测试示例的性能,最后返回在整个测试集上的平均值
- label-based:先分别评估 h ( ⋅ ) h(\cdot) h(⋅) 在每个标签上的性能,最后返回在所有标签上的 macro/micro-averaged value
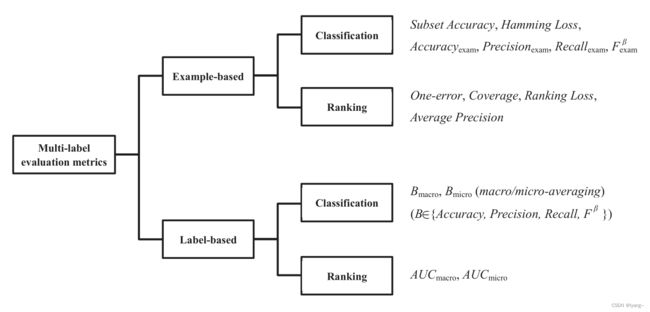
3. example-based
3.1 Subset Accuracy
subsetacc ( h ) = 1 p ∑ i = 1 p ⟦ h ( x i ) = Y i ⟧ \operatorname{subsetacc}(h)=\frac{1}{p} \sum_{i=1}^p\llbracket h\left(\boldsymbol{x}_i\right)=Y_i\rrbracket subsetacc(h)=p1i=1∑p[[h(xi)=Yi]]
- ⟦ h ( x i ) = Y i ⟧ \llbracket h\left(\boldsymbol{x}_i\right)=Y_i\rrbracket [[h(xi)=Yi]]:对一个实例预测出的标签向量和真实的标签向量完全相同,则得 1 1 1 分。
- 这实际上是对传统精度的自然推广,当标签向量尺寸非常大时,这个指标是非常严苛的
3.2 Hamming Loss
hloss ( h ) = 1 p ∑ i = 1 p ∣ h ( x i ) ⊕ Y i ∣ ∣ Y i ∣ \operatorname{hloss}(h)=\frac{1}{p} \sum_{i=1}^p\frac{\left|h\left(\boldsymbol{x}_i\right)\oplus Y_i\right|}{|Y_i|} hloss(h)=p1i=1∑p∣Yi∣∣h(xi)⊕Yi∣
- ⊕ \oplus ⊕:异或,效果是同 0 0 0 异 1 1 1
- ∣ ⋅ ∣ |\cdot| ∣⋅∣:返回集合的基数
- 越小越好
示例: 假设有两个样本
- 对样本一的预测值为 y p r e d = [ 0 , 1 , 1 , 0 , 0 ] y_{pred} = [0, 1, 1, 0, 0] ypred=[0,1,1,0,0],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],则预测值与真实标签有 2 2 2 个值不同,标签向量共有 5 5 5 个值,故这里得到 2 / 5 2/5 2/5
- 对样本二的预测值为 y p r e d = [ 1 , 1 , 0 , 0 , 0 ] y_{pred} = [1, 1, 0, 0, 0] ypred=[1,1,0,0,0],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 1 ] y_{true} =[1, 0, 1, 0, 1] ytrue=[1,0,1,0,1],则预测值与真实标签有 3 3 3 个值不同,标签向量共有 5 5 5 个值,故这里得到 3 / 5 3/5 3/5
- 返回 Hamming Loss \operatorname{Hamming\ Loss} Hamming Loss 的值为 1 2 × ( 2 5 + 3 5 ) = 1 2 \frac{1}{2}\times(\frac{2}{5}+\frac{3}{5})=\frac{1}{2} 21×(52+53)=21
3.3 Accuracy, Precision, Recall, F
3.3.1 Accuracy
A c c u r a c y e x a m ( h ) = 1 p ∑ i = 1 p ∣ Y i ∩ h ( x i ) ∣ ∣ Y i ∪ h ( x i ) ∣ Accuracy_{exam}(h)=\frac{1}{p}\sum\limits_{i=1}^p\frac{\left|Y_i\cap h(\boldsymbol{x}_i)\right|}{\left|Y_i\cup h(\boldsymbol{x}_i)\right|} Accuracyexam(h)=p1i=1∑p∣Yi∪h(xi)∣∣Yi∩h(xi)∣
- 越大越好
3.3.2 Precision
查准率,是被预测为正例的样本中,真正的正例所占的比例
P r e c i s i o n e x a m ( h ) = 1 p ∑ i = 1 p ∣ Y i ∩ h ( x i ) ∣ ∣ h ( x i ) ∣ Precision_{exam}(h)=\frac{1}{p}\sum\limits_{i=1}^p\frac{\left|Y_i\cap h(\boldsymbol{x}_i)\right|}{\left|h(\boldsymbol{x}_i)\right|} Precisionexam(h)=p1i=1∑p∣h(xi)∣∣Yi∩h(xi)∣
- 越大越好
3.3.3 Recall
查全率,是真正例中被预测为正例的样本所占的比例
R e c a l l e x a m ( h ) = 1 p ∑ i = 1 p ∣ Y i ∩ h ( x i ) ∣ ∣ Y i ∣ Recall_{exam}(h)=\frac{1}{p}\sum\limits_{i=1}^p\frac{\left|Y_i\cap h(\boldsymbol{x}_i)\right|}{\left|Y_i\right|} Recallexam(h)=p1i=1∑p∣Yi∣∣Yi∩h(xi)∣
- 越大越好
3.3.4 F
F 值是对查准率和查全率的综合考量,不同场景下查准和查全的重要程度不同,参数 β \beta β 用来调整查准和查全的权值,当 β \beta β 为 1 1 1 时,退化为标准的 F 1 F_1 F1 值
F e x a m β ( h ) = ( 1 + β 2 ) ⋅ P r e c i s i o n e x a m ( h ) ⋅ R e c a l l e x a m ( h ) β 2 ⋅ P r e c i s i o n e x a m ( h ) + R e c a l l e x a m ( h ) F_{exam}^\beta(h)=\frac{(1+\beta^2)\cdot Precision_{exam}(h)\cdot Recall_{exam}(h)}{\beta^2\cdot Precision_{exam}(h)+Recall_{exam}(h)} Fexamβ(h)=β2⋅Precisionexam(h)+Recallexam(h)(1+β2)⋅Precisionexam(h)⋅Recallexam(h)
- 越大越好
3.4 One-error
one-error ( f ) = 1 p ∑ i = 1 p ⟦ [ arg max y ∈ Y f ( x i , y ) ] ∉ Y i ⟧ \operatorname{one-error}\left(f\right)=\frac{1}{p}\sum\limits_{i=1}^p\llbracket\left[\arg\max\limits_{y\in\mathcal{Y}}f\left(\boldsymbol{x}_i,y\right)\right]\notin Y_i\rrbracket one-error(f)=p1i=1∑p[[[argy∈Ymaxf(xi,y)]∈/Yi]]
- ⟦ [ arg max y ∈ Y f ( x i , y ) ] ∉ Y i ⟧ \llbracket\left[\arg\max\limits_{y\in\mathcal{Y}}f\left(\boldsymbol{x}_i,y\right)\right]\notin Y_i\rrbracket [[[argy∈Ymaxf(xi,y)]∈/Yi]]:预测的标签向量中,概率最大的那个标签不存在则记 1 1 1 分,否则记 0 0 0 分
- 越小越好
示例: 假设有两个样本
- 对样本一的预测值为 y s c o r e = [ 0.3 , 0.4 , 0.5 , 0.1 , 0.15 ] y_{score} = [0.3, 0.4, 0.5, 0.1, 0.15] yscore=[0.3,0.4,0.5,0.1,0.15],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],则预测值中概率最大的是第 3 3 3 个标签,概率为 0.5 0.5 0.5,对应到标签向量中第 3 3 3 个标签,其值为 1 1 1,故记 0 0 0 分
- 对样本二的预测值为 y s c o r e = [ 0.4 , 0.5 , 0.7 , 0.2 , 0.6 ] y_{score} = [0.4, 0.5, 0.7, 0.2, 0.6] yscore=[0.4,0.5,0.7,0.2,0.6],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 1 ] y_{true} =[1, 0, 1, 0, 1] ytrue=[1,0,1,0,1],则预测值中概率最大的是第 3 3 3 个标签,概率为 0.7 0.7 0.7,对应到标签向量中第 3 3 3 个标签,其值为 1 1 1,故记 0 0 0 分
- 返回 one-error \operatorname{one-error} one-error 的值为 1 2 × ( 0 + 0 ) = 0 \frac{1}{2}\times(0+0)=0 21×(0+0)=0
3.5 Coverage
coverage ( f ) = 1 p ∑ i = 1 p ( max y ∈ Y i r a n k f ( x i , y ) − 1 ) \operatorname{coverage}\left(f\right)=\frac{1}{p}\sum\limits_{i=1}^p\left(\max\limits_{y\in Y_i}rank_f\left(\boldsymbol{x}_i,y\right)-1\right) coverage(f)=p1i=1∑p(y∈Yimaxrankf(xi,y)−1)
- max y ∈ Y i r a n k f ( x i , y ) − 1 \max\limits_{y\in Y_i}rank_f\left(\boldsymbol{x}_i,y\right)-1 y∈Yimaxrankf(xi,y)−1:根据预测的概率将标签降序排序,能把存在的标签覆盖完毕时的个数再减 1 1 1
- 在 python 的 sklearn 库中对 coverage 的实现没有减 1 1 1,我也不太理解这里为什么要减 1 1 1
- 越小越好
示例: 假设有两个样本
- 对样本一的预测值为 y s c o r e = [ 0.3 , 0.4 , 0.5 , 0.1 , 0.15 ] y_{score} = [0.3, 0.4, 0.5, 0.1, 0.15] yscore=[0.3,0.4,0.5,0.1,0.15],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],按概率排序有 [ 0.5 , 0.4 , 0.3 , 0.15 , 0.1 ] [0.5, 0.4, 0.3, 0.15, 0.1] [0.5,0.4,0.3,0.15,0.1],对应的真实标签变为 [ 1 , 0 , 1 , 0 , 0 ] [1, 0, 1, 0, 0] [1,0,1,0,0],前 3 3 3 个标签将 1 1 1 全部覆盖,这里得到 3 − 1 = 2 3-1=2 3−1=2
- 对本二的预测值为 y s c o r e = [ 0.4 , 0.5 , 0.7 , 0.2 , 0.6 ] y_{score} = [0.4, 0.5, 0.7, 0.2, 0.6] yscore=[0.4,0.5,0.7,0.2,0.6],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 1 ] y_{true} =[1, 0, 1, 0, 1] ytrue=[1,0,1,0,1],按概率排序有 [ 0.7 , 0.6 , 0.5 , 0.4 , 0.2 ] [0.7, 0.6, 0.5, 0.4, 0.2] [0.7,0.6,0.5,0.4,0.2],对应的真实标签变为 [ 1 , 1 , 0 , 1 , 0 ] [1, 1, 0, 1, 0] [1,1,0,1,0],前 4 4 4 个标签将 1 1 1 全部覆盖,这里得到 4 − 1 = 3 4-1=3 4−1=3
- 返回 coverage \operatorname{coverage} coverage 的值为 1 2 × ( 2 + 3 ) = 2.5 \frac{1}{2}\times(2+3)=2.5 21×(2+3)=2.5
3.6 Ranking Loss
rloss ( f ) = 1 p ∑ i = 1 p 1 ∣ Y i ∣ ∣ Y ˉ i ∣ ∣ { ( y ′ , y ′ ′ ) ∣ f ( x i , y ′ ) ≤ f ( x i , y ′ ′ ) , ( y ′ , y ′ ′ ) ∈ Y i × Y ˉ i } ∣ \operatorname{rloss}(f)=\frac{1}{p} \sum_{i=1}^p \frac{1}{\left|Y_i\right|\left|\bar{Y}_i\right|} \left|\left\{\left(y^{\prime}, y^{\prime \prime}\right) \mid f\left(\boldsymbol{x}_i, y^{\prime}\right) \leq f\left(\boldsymbol{x}_i, y^{\prime \prime}\right), \quad\left(y^{\prime}, y^{\prime \prime}\right) \in Y_i \times \bar{Y}_i\right\} \right| rloss(f)=p1i=1∑p∣Yi∣ Yˉi 1 {(y′,y′′)∣f(xi,y′)≤f(xi,y′′),(y′,y′′)∈Yi×Yˉi}
- 1 ∣ Y i ∣ ∣ Y ˉ i ∣ ∣ { ( y ′ , y ′ ′ ) ∣ f ( x i , y ′ ) ≤ f ( x i , y ′ ′ ) , ( y ′ , y ′ ′ ) ∈ Y i × Y ˉ i } ∣ \frac{1}{\left|Y_i\right|\left|\bar{Y}_i\right|} \left|\left\{\left(y^{\prime}, y^{\prime \prime}\right) \mid f\left(\boldsymbol{x}_i, y^{\prime}\right) \leq f\left(\boldsymbol{x}_i, y^{\prime \prime}\right), \quad\left(y^{\prime}, y^{\prime \prime}\right) \in Y_i \times \bar{Y}_i\right\} \right| ∣Yi∣∣Yˉi∣1 {(y′,y′′)∣f(xi,y′)≤f(xi,y′′),(y′,y′′)∈Yi×Yˉi} :即,由为 0 0 0 的标签集合与为 1 1 1 的标签集合组成的二元组中,将不存在的标签排在存在的标签前面的二元组所占的比例
- 越小越好
示例: 假设有两个样本
- 对样本一的预测值为 y s c o r e = [ 0.3 , 0.4 , 0.5 , 0.1 , 0.15 ] y_{score} = [0.3, 0.4, 0.5, 0.1, 0.15] yscore=[0.3,0.4,0.5,0.1,0.15],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],为 1 1 1 的标签集合大小为 2 2 2,为 0 0 0 的标签集合大小为 3 3 3,笛卡尔积为 2 × 3 = 6 2\times 3=6 2×3=6 个二元组,按概率排序后得到 [ 0.5 , 0.4 , 0.3 , 0.15 , 0.1 ] [0.5, 0.4, 0.3, 0.15, 0.1] [0.5,0.4,0.3,0.15,0.1],对应的真实标签变为 [ 1 , 0 , 1 , 0 , 0 ] [1, 0, 1, 0, 0] [1,0,1,0,0],即有且仅有概率为 0.4 0.4 0.4 的值为 0 0 0 的标签排在了概率为 0.3 0.3 0.3 的值为 1 1 1 的标签前面这么一个二元组,故这里得到值 1 / 6 1/6 1/6
- 对样本二的预测值为 y s c o r e = [ 0.4 , 0.5 , 0.7 , 0.2 , 0.6 ] y_{score} = [0.4, 0.5, 0.7, 0.2, 0.6] yscore=[0.4,0.5,0.7,0.2,0.6],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 1 ] y_{true} =[1, 0, 1, 0, 1] ytrue=[1,0,1,0,1],为 1 1 1 的标签集合大小为 2 2 2,为 0 0 0 的标签集合大小为 3 3 3,笛卡尔积为 2 × 3 = 6 2\times 3=6 2×3=6 个二元组,按概率排序有 [ 0.7 , 0.6 , 0.5 , 0.4 , 0.2 ] [0.7, 0.6, 0.5, 0.4, 0.2] [0.7,0.6,0.5,0.4,0.2],对应的真实标签变为 [ 1 , 1 , 0 , 1 , 0 ] [1, 1, 0, 1, 0] [1,1,0,1,0],即有且仅有概率为 0.5 0.5 0.5 的值为 0 0 0 的标签排在了概率为 0.4 0.4 0.4 的值为 1 1 1 的标签前面这么一个二元组,故这里得到值 1 / 6 1/6 1/6
- 返回 Ranking Loss \operatorname{Ranking\ Loss} Ranking Loss 的值为 1 2 × ( 1 6 + 1 6 ) = 1 6 \frac{1}{2}\times(\frac{1}{6}+\frac{1}{6})=\frac{1}{6} 21×(61+61)=61
3.7 Average Precision
avgprec ( f ) = 1 p ∑ i = 1 p 1 ∣ Y i ∣ ∑ y ∈ Y i ∣ { y ′ ∣ rank f ( x , y ′ ) ≤ rank f ( x i , y ) , y ′ ∈ Y i } ∣ rank f ( x i , y ) \operatorname{avgprec}(f)=\frac{1}{p} \sum_{i=1}^p \frac{1}{\left|Y_i\right|} \sum_{y \in Y_i} \frac{\left|\left\{y^{\prime} \mid \operatorname{rank}_f\left(\boldsymbol{x}, y^{\prime}\right) \leq \operatorname{rank}_f\left(\boldsymbol{x}_i, y\right), y^{\prime} \in Y_i\right\}\right|}{\operatorname{rank}_f\left(\boldsymbol{x}_i, y\right)} avgprec(f)=p1i=1∑p∣Yi∣1y∈Yi∑rankf(xi,y)∣{y′∣rankf(x,y′)≤rankf(xi,y),y′∈Yi}∣
- ∣ { y ′ ∣ rank f ( x , y ′ ) ≤ rank f ( x i , y ) , y ′ ∈ Y i } ∣ rank f ( x i , y ) \frac{\left|\left\{y^{\prime} \mid \operatorname{rank}_f\left(\boldsymbol{x}, y^{\prime}\right) \leq \operatorname{rank}_f\left(\boldsymbol{x}_i, y\right), y^{\prime} \in Y_i\right\}\right|}{\operatorname{rank}_f\left(\boldsymbol{x}_i, y\right)} rankf(xi,y)∣{y′∣rankf(x,y′)≤rankf(xi,y),y′∈Yi}∣:即,对于值为 1 1 1 的某个标签,在根据预测出的概率降序排序后,排在它前面的 (含它本身) 值为 1 1 1 的标签个数比上它在该排序中的排名。
- 越大越好
示例: 假设有两个样本
- 对样本一的预测值为 y s c o r e = [ 0.3 , 0.4 , 0.5 , 0.1 , 0.15 ] y_{score} = [0.3, 0.4, 0.5, 0.1, 0.15] yscore=[0.3,0.4,0.5,0.1,0.15],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],按概率排序有 [ 0.5 , 0.4 , 0.3 , 0.15 , 0.1 ] [0.5, 0.4, 0.3, 0.15, 0.1] [0.5,0.4,0.3,0.15,0.1],对应的真实标签变为 [ 1 , 0 , 1 , 0 , 0 ] [1, 0, 1, 0, 0] [1,0,1,0,0]
- 对第 1 1 1 个 1 1 1,其排名为 1 1 1,排在它前面(含它本身) 的 1 1 1 个数为 1,故得 1 / 1 = 1 1/1=1 1/1=1
- 对第 2 2 2 个 1 1 1,其排名为 3 3 3,排在它前面(含它本身) 的 2 2 2 个数为 1,故得 2 / 3 2/3 2/3
- 这里总共得到 1 2 ( 1 + 2 3 ) = 5 6 \frac{1}{2}(1+\frac{2}{3})=\frac{5}{6} 21(1+32)=65
- 对样本二的预测值为 y s c o r e = [ 0.4 , 0.5 , 0.7 , 0.2 , 0.6 ] y_{score} = [0.4, 0.5, 0.7, 0.2, 0.6] yscore=[0.4,0.5,0.7,0.2,0.6],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 1 ] y_{true} =[1, 0, 1, 0, 1] ytrue=[1,0,1,0,1],按概率排序有 [ 0.7 , 0.6 , 0.5 , 0.4 , 0.2 ] [0.7, 0.6, 0.5, 0.4, 0.2] [0.7,0.6,0.5,0.4,0.2],对应的真实标签变为 [ 1 , 1 , 0 , 1 , 0 ] [1, 1, 0, 1, 0] [1,1,0,1,0]
- 对第 1 1 1 个 1 1 1,其排名为 1 1 1,排在它前面(含它本身) 的 1 1 1 个数为 1,故得 1 / 1 = 1 1/1=1 1/1=1
- 对第 2 2 2 个 1 1 1,其排名为 2 2 2,排在它前面(含它本身) 的 1 1 1 个数为 2,故得 2 / 2 = 1 2/2=1 2/2=1
- 对第 3 3 3 个 1 1 1,其排名为 4 4 4,排在它前面(含它本身) 的 1 1 1 个数为 3,故得 3 / 4 3/4 3/4
- 这里总共得到 1 3 ( 1 + 1 + 3 4 ) = 11 12 \frac{1}{3}(1+1+\frac{3}{4})=\frac{11}{12} 31(1+1+43)=1211
- 返回 average precision \operatorname{average\ precision} average precision 的值为 1 2 × ( 5 6 + 11 12 ) = 13 24 \frac{1}{2}\times(\frac{5}{6}+\frac{11}{12})=\frac{13}{24} 21×(65+1211)=2413
3.8 NDCG
N D C G ( f ) = D C G ( f ) I D C G = ∑ i = 1 k y ^ i log ( 1 + l ) ∑ i = 1 m 1 log ( 1 + l ) NDCG\left(f\right)=\frac{DCG\left(f\right)}{IDCG}=\frac{\sum\limits_{i=1}^k\frac{\hat{y}_i}{\log\left(1+l\right)}}{\sum\limits_{i=1}^m\frac{1}{\log\left(1+l\right)}} NDCG(f)=IDCGDCG(f)=i=1∑mlog(1+l)1i=1∑klog(1+l)y^i
- NDCG 是 DCG 的归一化
- DCG:即,根据预测出的概率进行排序,对该排序的打分
- IDCG:即,完全预测正确时的完美评分
- 越大越好
示例: 假设有多个样本,可以直接将标签矩阵展开成标签向量
- 预测值为 y s c o r e = [ 0.3 , 0.4 , 0.5 , 0.1 , 0.15 ] y_{score} = [0.3, 0.4, 0.5, 0.1, 0.15] yscore=[0.3,0.4,0.5,0.1,0.15],真实标签向量为 y t r u e = [ 1 , 0 , 1 , 0 , 0 ] y_{true} = [1, 0, 1, 0, 0] ytrue=[1,0,1,0,0],按概率排序有 [ 0.5 , 0.4 , 0.3 , 0.15 , 0.1 ] [0.5, 0.4, 0.3, 0.15, 0.1] [0.5,0.4,0.3,0.15,0.1],对应的真实标签变为 [ 1 , 0 , 1 , 0 , 0 ] [1, 0, 1, 0, 0] [1,0,1,0,0],完美排序标签为 [ 1 , 1 , 0 , 0 , 0 ] [1, 1, 0, 0, 0] [1,1,0,0,0]
- DCG 得分为 1 log ( 1 + 1 ) + 1 log ( 1 + 3 ) \frac{1}{\log\left(1+1\right)}+\frac{1}{\log\left(1+3\right)} log(1+1)1+log(1+3)1,因为两个 1 1 1 的位置在第 1 1 1 位和第 3 3 3 位
- IDCG 得分为 1 log ( 1 + 1 ) + 1 log ( 1 + 2 ) \frac{1}{\log\left(1+1\right)}+\frac{1}{\log\left(1+2\right)} log(1+1)1+log(1+2)1
- 得到 N D C G = D C G I D C G NDCG=\frac{DCG}{IDCG} NDCG=IDCGDCG
3.9 peak-F1
当 β \beta β 取值为 1 1 1 时, F β F^\beta Fβ 退化为标准 F 1 F_1 F1,此时查准率和查全率一样重要。对得到的一个预测结果,按概率进行降序排序后,依次将每个标签预测为 1 1 1,可以得到一系列的 F 1 F_1 F1 值,其中最大的那个,就记做 peak-F1
- 越大越好
4. label-based
针对每个标签可以由一个二元分类器 h ( ⋅ ) h(\cdot) h(⋅) 得到以下四个度量性能的指标,下图被称为分类结果混淆矩阵。
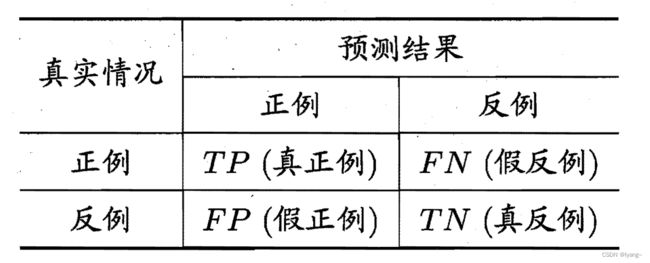
T P j = ∣ { x i ∣ y j ∈ Y i ∧ y j ∈ h ( x i ) , 1 ≤ i ≤ p } ∣ ; F P j = ∣ { x i ∣ y j ∉ Y i ∧ y j ∈ h ( x i ) , 1 ≤ i ≤ p } ∣ T N j = ∣ { x i ∣ y j ∉ Y i ∧ y j ∉ h ( x i ) , 1 ≤ i ≤ p } ∣ ; F N j = ∣ { x i ∣ y j ∈ Y i ∧ y j ∉ h ( x i ) , 1 ≤ i ≤ p } ∣ \begin{gathered} T P_j=\left|\left\{\boldsymbol{x}_i \mid y_j \in Y_i \wedge y_j \in h\left(\boldsymbol{x}_i\right), 1 \leq i \leq p\right\}\right| ; \quad F P_j=\left|\left\{\boldsymbol{x}_i \mid y_j \notin Y_i \wedge y_j \in h\left(\boldsymbol{x}_i\right), 1 \leq i \leq p\right\}\right| \\ T N_j=\left|\left\{\boldsymbol{x}_i \mid y_j \notin Y_i \wedge y_j \notin h\left(\boldsymbol{x}_i\right), 1 \leq i \leq p\right\}\right| ; \quad F N_j=\left|\left\{\boldsymbol{x}_i \mid y_j \in Y_i \wedge y_j \notin h\left(\boldsymbol{x}_i\right), 1 \leq i \leq p\right\}\right| \end{gathered} TPj=∣{xi∣yj∈Yi∧yj∈h(xi),1≤i≤p}∣;FPj=∣{xi∣yj∈/Yi∧yj∈h(xi),1≤i≤p}∣TNj=∣{xi∣yj∈/Yi∧yj∈/h(xi),1≤i≤p}∣;FNj=∣{xi∣yj∈Yi∧yj∈/h(xi),1≤i≤p}∣
4.1 Macro-averaging 与 Micro-averaging
令 B ( T P j , F P j , T N j , F N j ) B(TP_j,FP_j,TN_j,FN_j) B(TPj,FPj,TNj,FNj) 为一种特定的二分类度量,即 B ∈ { A c c u r a c y , P r e c i s i o n , R e c a l l , F β } B\in\left\{Accuracy, Precision, Recall, F^\beta\right\} B∈{Accuracy,Precision,Recall,Fβ},由此可以得到 Macro-averaging 与 Micro-averaging 两种评价指标
4.1.1 Macro-averaging
B macro ( h ) = 1 q ∑ j = 1 q B ( T P j , F P j , T N j , F N j ) B_{\text {macro }}(h)=\frac{1}{q} \sum_{j=1}^q B\left(T P_j, F P_j, T N_j, F N_j\right) Bmacro (h)=q1j=1∑qB(TPj,FPj,TNj,FNj)
- 即,先分别求各个标签的二分类度量,再求均值
4.1.2 Micro-averaging
B micro ( h ) = B ( ∑ j = 1 q T P j , ∑ j = 1 q F P j , ∑ j = 1 q T N j , ∑ j = 1 q F N j ) B_{\text {micro }}(h)=B\left(\sum_{j=1}^q T P_j, \sum_{j=1}^q F P_j, \sum_{j=1}^q T N_j, \sum_{j=1}^q F N_j\right) Bmicro (h)=B(j=1∑qTPj,j=1∑qFPj,j=1∑qTNj,j=1∑qFNj)
- 即,先将所有标签的 T P j , F P j , T N j , F N j TP_j,FP_j,TN_j,FN_j TPj,FPj,TNj,FNj 各自累加起来,得到一个混淆矩阵,再求得二分类度量
4.2 AUCmacro 与 AUCmicro
4.2.1 单标签的 AUC
AUC 是 Area Under ROC Curve 的缩写,而 ROC 是以假正例率为横轴,真正例率为纵轴所绘制出的图线,具体的绘图过程如下,
- 按学习器预测结果进行排序
- 将分类阈值设为最大,所有样例被分为反例,此时可以得到一个混淆矩阵,因而可以绘制出 ROC 图中的一个点 (0, 0)
- 减小阈值,即依次将阈值设为每个样例的预测值,每次可以在 ROC 图中绘制一个点
- 用线段连接相邻点即可
注:
- 假正例率: T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP,即,真正例中被预测为正例的比例
- 真正例率: F P R = F P T N + F P FPR=\frac{FP}{TN+FP} FPR=TN+FPFP,即,真反例中被预测为正例的反例
4.2.2 AUCmacro
A U C macro = 1 q ∑ j = 1 q A U C j = 1 q ∑ j = 1 q ∣ { ( x ′ , x ′ ′ ) ∣ f ( x ′ , y j ) ≥ f ( x ′ ′ , y j ) , ( x ′ , x ′ ′ ) ∈ Z j × Z ˉ j } ∣ ∣ Z j ∣ ∣ Z ˉ j ∣ A U C_{\text {macro }}=\frac{1}{q} \sum_{j=1}^q A U C_j=\frac{1}{q} \sum_{j=1}^q \frac{\left|\left\{\left(\boldsymbol{x}^{\prime}, \boldsymbol{x}^{\prime \prime}\right) \mid f\left(\boldsymbol{x}^{\prime}, y_j\right) \geq f\left(\boldsymbol{x}^{\prime \prime}, y_j\right),\left(\boldsymbol{x}^{\prime}, \boldsymbol{x}^{\prime \prime}\right) \in \mathcal{Z}_j \times \bar{\mathcal{Z}}_j\right\}\right|}{\left|\mathcal{Z}_j\right|\left|\bar{\mathcal{Z}}_j\right|} AUCmacro =q1j=1∑qAUCj=q1j=1∑q∣Zj∣ Zˉj {(x′,x′′)∣f(x′,yj)≥f(x′′,yj),(x′,x′′)∈Zj×Zˉj}
- 其中, Z j = { x i ∣ y j ∈ Y i , 1 ≤ i ≤ p } ( Z ˉ j = { x i ∣ y j ∉ Y i , 1 ≤ i ≤ p } ) \mathcal{Z}_j=\left\{\boldsymbol{x}_i\mid y_j\in Y_i, 1\leq i\leq p\right\}(\bar{\mathcal{Z}}_j=\left\{\boldsymbol{x}_i\mid y_j\notin Y_i, 1\leq i\leq p\right\}) Zj={xi∣yj∈Yi,1≤i≤p}(Zˉj={xi∣yj∈/Yi,1≤i≤p})
- 即,针对每个标签分别求出 A U C AUC AUC 指标,再求均值
4.2.3 AUCmicro
A U C micro = ∣ { ( x ′ , x ′ ′ , y ′ , y ′ ′ ) ∣ f ( x ′ , y ′ ) ≥ f ( x ′ ′ , y ′ ′ ) , ( x ′ , y ′ ) ∈ S + , ( x ′ ′ , y ′ ′ ) ∈ S − } ∣ ∣ S + ∣ ∣ S − ∣ A U C_{\text {micro }}=\frac{\left|\left\{\left(\boldsymbol{x}^{\prime}, \boldsymbol{x}^{\prime \prime}, y^{\prime}, y^{\prime \prime}\right) \mid f\left(\boldsymbol{x}^{\prime}, y^{\prime}\right) \geq f\left(\boldsymbol{x}^{\prime \prime}, y^{\prime \prime}\right),\left(\boldsymbol{x}^{\prime}, y^{\prime}\right) \in \mathcal{S}^{+},\left(\boldsymbol{x}^{\prime \prime}, y^{\prime \prime}\right) \in \mathcal{S}^{-}\right\}\right|}{\left|\mathcal{S}^{+}\right|\left|\mathcal{S}^{-}\right|} AUCmicro =∣S+∣∣S−∣∣{(x′,x′′,y′,y′′)∣f(x′,y′)≥f(x′′,y′′),(x′,y′)∈S+,(x′′,y′′)∈S−}∣
- 其中, S + = { ( x i , y ) ∣ y ∈ Y i , 1 ≤ i ≤ p } ( S − = { ( x i , y ) ∣ y ∉ Y i , 1 ≤ i ≤ p } ) \mathcal{S}^+=\left\{(\boldsymbol{x}_i,y)\mid y\in Y_i, 1\leq i\leq p\right\}(\mathcal{S}^-=\left\{(\boldsymbol{x}_i,y)\mid y\notin Y_i, 1\leq i\leq p\right\}) S+={(xi,y)∣y∈Yi,1≤i≤p}(S−={(xi,y)∣y∈/Yi,1≤i≤p}),分别代表 x i \boldsymbol{x}_i xi 中有 (无) 标签 y y y,二者的并就是 X \mathcal{X} X 与 Y \mathcal{Y} Y 的笛卡尔积
- 该式的含义为,先将 X \mathcal{X} X 与 Y \mathcal{Y} Y 求笛卡尔积,得到的 ( x , y ) (\boldsymbol{x}, y) (x,y) 可以根据 x \boldsymbol{x} x 中是否有标签 y y y 来进行分类,从而划分得到两个集合 S + \mathcal{S}^+ S+ 和 S − \mathcal{S}^- S−
- 再将 S + \mathcal{S}^+ S+ 和 S − \mathcal{S}^- S− 作笛卡尔积,统计将 S + \mathcal{S}^+ S+ 的元素排在 S − \mathcal{S}^- S− 前面的元素所占的比例 (根据预测的概率进行排序)
- 即,和 Ranking Loss \operatorname{Ranking\ Loss} Ranking Loss 相反