吴恩达深度学习第一课第二周编程作业
吴恩达深度学习第一课第二周编程作业
- 建议
- 进入本文主题,第二周编程作业
-
- 你将学会:
- 本人在写这篇作业时的手写笔记:
- 1.导入包
- 2.习题集概述
-
- 练习1
- 练习 2
- 3.学习算法的一般结构
- 4.构建我们算法的各个部分
-
- 4.1 Helper functions(助手函数)
- 4.2初始化参数
- 4.3正向和反向传播
- 4.4优化
- 5.将所有函数合并到一个模型中
- 6.进一步分析(可选/不分级练习)
- 7.使用自己的图像进行测试(可选/未分级练习)
建议
本篇博文是本人在学习做笔记使用,同时仅供大家学习参考,如有错误之处,烦请各位不吝指出,【建议】:大家在做这个编程作业时先把第一个关于如何使用IPython notebooks以及numpy库的练习做完,对于做这一编程作业很有帮助,链接附上:点这进去
进入本文主题,第二周编程作业
你将学会:
构建学习算法的总体架构,包括:
1.初始化参数
2.成本函数及其梯度的计算
3使用优化算法(梯度下降)
4按照正确的顺序将以上三个函数集合到一个主模型函数中。
声明:本作业都是在coursera网站在线完成,不需要并且不建议使用其他编辑器和开发环境,具体怎么使用该在线环境请看开头建议中的链接
本人在写这篇作业时的手写笔记:
好记性不如烂笔头,在手写一边后,可以更清晰的了解这个分类器的构造过程,将理论知识付诸实践的作用,本人字迹不太好看,希望各位不要介意







1.导入包
首先,让我们运行下面的单元格以导入此任务期间需要的所有包。
1.numpy是使用Python进行科学计算的基本包。
2.h5py是一个与存储在H5文件中的数据集交互的通用包。
3.matplotlib是Python用来绘制图形的著名库。
4.PIL和scipy测试您的模型,并在最后使用您自己的图片。
import numpy as np
import copy
import matplotlib.pyplot as plt
import h5py
import scipy
from PIL import Image
from scipy import ndimage
from lr_utils import load_dataset
from public_tests import *
%matplotlib inline
%load_ext autoreload
%autoreload 2
2.习题集概述
问题陈述:您将获得一个数据集(“data.h5”),其中包含:
-标记为cat(y=1)或non-cat(y=0)的m_train图像训练集
-标记为cat或non-cat的m_test图像的测试集
-每个图像的形状(num_px,num_px,3),其中3表示3个通道(RGB)。因此,每个图像都是正方形(高度=num_px)和(宽度=num_px)。
您将建立一个简单的图像识别算法,可以正确地将图片分类为猫或非猫。
让我们更熟悉数据集。通过运行以下代码加载数据。
# Loading the data (cat/non-cat)
train_set_x_orig, train_set_y, test_set_x_orig, test_set_y, classes = load_dataset()
我们在图像数据集(train和test)的末尾添加了“_orig”,因为我们将对它们进行预处理。在预处理之后,我们将得到train_set_x和test_set_x(train_set_y和test_set_y标签不需要任何预处理)。
train_set_x_orig和test_set_x_orig的每一行都是一个表示图像的数组。您可以通过运行以下代码来可视化示例。也可以随意更改索引值并重新运行以查看其他图像。
# Example of a picture
index = 25
plt.imshow(train_set_x_orig[index])
print ("y = " + str(train_set_y[:, index]) + ", it's a '" + classes[np.squeeze(train_set_y[:, index])].decode("utf-8") + "' picture.")
得到如下结果:
y = [1], it’s a ‘cat’ picture.

深度学习中的许多软件缺陷来自于矩阵/向量维度不合适。如果你能保持你的矩阵/向量维度笔直的话,你将在消除许多错误方面走很长的路。
练习1
查找以下值:
-m_train(训练示例数)
-m_test(测试示例数)
-num_px(=高度=训练图像的宽度)
记住train_set_x_orig是一个numpy形状数组(m_train,num_px,num_px,3)。例如,您可以通过写入train_set_x_orig.shape[0]来访问m_train。
#(≈ 3 lines of code)
# m_train =
# m_test =
# num_px =
# YOUR CODE STARTS HERE
#我的作答:
m_train = train_set_x_orig.shape[0]
m_test = test_set_x_orig.shape[0]
num_px = train_set_x_orig.shape[1]
# YOUR CODE ENDS HERE
print ("Number of training examples: m_train = " + str(m_train))
print ("Number of testing examples: m_test = " + str(m_test))
print ("Height/Width of each image: num_px = " + str(num_px))
print ("Each image is of size: (" + str(num_px) + ", " + str(num_px) + ", 3)")
print ("train_set_x shape: " + str(train_set_x_orig.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x shape: " + str(test_set_x_orig.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
运行结果:
Number of training examples: m_train = 209
Number of testing examples: m_test = 50
Height/Width of each image: num_px = 64
Each image is of size: (64, 64, 3)
train_set_x shape: (209, 64, 64, 3)
train_set_y shape: (1, 209)
test_set_x shape: (50, 64, 64, 3)
test_set_y shape: (1, 50)
为方便起见,你现在应该reshape 每个图像的shape为(num_px,num_px,3)变成一个shape为(num_pxnum_px3,1)的numpy数组,在这之后,我们的训练(和测试)数据集是一个numpy数组,其中每列表示一个展平的图像。应该有m_train(分别为m_test)列。
练习 2
重新调整训练和测试数据集的形状,以便将大小(num_px,num_px,3)的图像展平为单个形状向量(num_px∗ num_px∗ 3, 1).
一个技巧,当你想把一个X形的矩阵(a,b,c,d)展平到一个X形的矩阵(b∗ c∗ d, a)使用:
X_flatten = X.reshape(X.shape[0], -1).T # X.T is the transpose of X
# Reshape the training and test examples
#(≈ 2 lines of code)
# train_set_x_flatten = ...
# test_set_x_flatten = ...
# YOUR CODE STARTS HERE
train_set_x_flatten = train_set_x_orig.reshape(train_set_x_orig.shape[0],-1).T
test_set_x_flatten = test_set_x_orig.reshape(test_set_x_orig.shape[0],-1).T
# YOUR CODE ENDS HERE
# 检查第二个图像的前10个像素是否在正确的位置
assert np.alltrue(train_set_x_flatten[0:10, 1] == [196, 192, 190, 193, 186, 182, 188, 179, 174, 213]), "Wrong solution. Use (X.shape[0], -1).T."
assert np.alltrue(test_set_x_flatten[0:10, 1] == [115, 110, 111, 137, 129, 129, 155, 146, 145, 159]), "Wrong solution. Use (X.shape[0], -1).T."
print ("train_set_x_flatten shape: " + str(train_set_x_flatten.shape))
print ("train_set_y shape: " + str(train_set_y.shape))
print ("test_set_x_flatten shape: " + str(test_set_x_flatten.shape))
print ("test_set_y shape: " + str(test_set_y.shape))
运行结果为:
train_set_x_flatten shape: (12288, 209)
train_set_y shape: (1, 209)
test_set_x_flatten shape: (12288, 50)
test_set_y shape: (1, 50)
要表示彩色图像,必须为每个像素指定红、绿和蓝通道(RGB),因此像素值实际上是一个由0到255之间的三个数字组成的向量。
机器学习中一个常见的预处理步骤是集中并标准化数据集,这意味着从每个示例中减去整个numpy数组的平均值,然后将每个示例除以整个numpy数组的标准差。但对于图片数据集来说,将数据集的每一行除以255(像素通道的最大值)更简单、更方便,效果也几乎一样。
让我们标准化我们的数据集。
train_set_x = train_set_x_flatten / 255.
test_set_x = test_set_x_flatten / 255.
你需要记住的是:
预处理新数据集的常见步骤有:
1.算出问题的大小和形状(m_train,m_test,num_px,…)
2.重新调整数据集的形状,使每个示例现在都是一个大小为(num_px*num_px*3,1)的向量
3.“标准化”数据
3.学习算法的一般结构
是时候设计一个简单的算法来区分cat图像和非cat图像了。
你将建立一个Logistic回归,使用神经网络的思想。下图解释了为什么逻辑回归实际上是一个非常简单的神经网络!
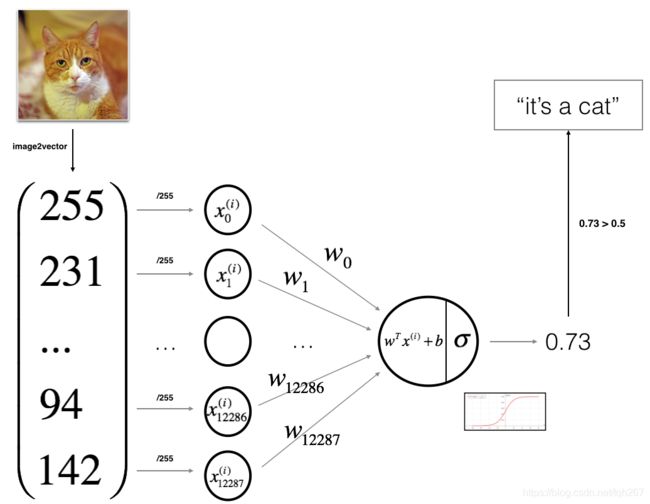
算法的数学表达式:
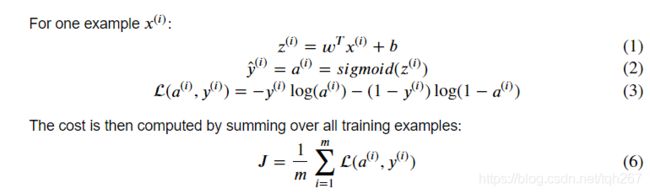
关键步骤:在本练习中,您将执行以下步骤:
-初始化模型的参数
-通过最小化成本学习模型的参数
-使用学习的参数进行预测(在测试集上)
-分析结果并得出结论
4.构建我们算法的各个部分
构建神经网络的主要步骤是:
1.定义模型结构(例如输入特征的数量)
2.初始化模型参数
3.循环:
计算目前的损耗(正向传播)
计算目前的梯度(反向传播)
更新参数(梯度下降)
您通常单独构建1-3,并将它们集成到一个我们称为model()的函数中。
4.1 Helper functions(助手函数)
Exercise 3 - sigmoid
使用“Python基础”中的代码,实现sigmoid()。如上图所示,您需要计算()=1/(1+e^−) 为了=+ 做预测。使用np.exp()。
# GRADED FUNCTION: sigmoid
def sigmoid(z):
"""
Compute the sigmoid of z
Arguments:
z -- A scalar or numpy array of any size.
Return:
s -- sigmoid(z)
"""
#(≈ 1 line of code)
# s = ...
# YOUR CODE STARTS HERE
# YOUR CODE ENDS HERE
return s
print ("sigmoid([0, 2]) = " + str(sigmoid(np.array([0,2]))))
sigmoid_test(sigmoid)
运行结果:
sigmoid([0, 2]) = [0.5 0.88079708]
4.2初始化参数
练习4-initialize_with_zeros
在下面的单元格中实现参数初始化。你必须把w初始化为一个零向量。如果不知道要使用什么numpy函数,请在numpy库的文档中查找np.zeros()。
# GRADED FUNCTION: initialize_with_zeros
def initialize_with_zeros(dim):
"""
This function creates a vector of zeros of shape (dim, 1) for w and initializes b to 0.
Argument:
dim -- size of the w vector we want (or number of parameters in this case)
Returns:
w -- initialized vector of shape (dim, 1)
b -- initialized scalar (corresponds to the bias) of type float
"""
# (≈ 2 lines of code)
# w = ...
# b = ...
# YOUR CODE STARTS HERE
w = np.zeros(shape = (dim,1))
b = 0.0#此处不能使用0,得使用0.0,因为后面断言是float类型
# YOUR CODE ENDS HERE
return w, b
dim = 2
w, b = initialize_with_zeros(dim)
assert type(b) == float
print ("w = " + str(w))
print ("b = " + str(b))
initialize_with_zeros_test(initialize_with_zeros)
运行结果为:
w = [[0.]
[0.]]
b = 0.0
All tests passed!
4.3正向和反向传播
现在参数已经初始化,您可以执行“向前”和“向后”传播步骤来学习参数。
练习5-传播
实现一个函数propagate(),用于计算代价函数及其梯度。
提示:
正向传播:

在这里一定要搞清楚""与np.dot的区别,以及各矩阵的维度,以及np.sum()相加是从行还是列*
# GRADED FUNCTION: propagate
def propagate(w, b, X, Y):
"""
Implement the cost function and its gradient for the propagation explained above
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of size (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if non-cat, 1 if cat) of size (1, number of examples)
Return:
cost -- negative log-likelihood cost for logistic regression
dw -- gradient of the loss with respect to w, thus same shape as w
db -- gradient of the loss with respect to b, thus same shape as b
Tips:
- Write your code step by step for the propagation. np.log(), np.dot()
"""
m = X.shape[1]
# FORWARD PROPAGATION (FROM X TO COST)
#(≈ 2 lines of code)
# compute activation
# A = ...
# compute cost using np.dot. Don't use loops for the sum.
# cost = ...
# YOUR CODE STARTS HERE
#在这里一定要搞清楚*与np.dot的区别,以及各矩阵的维度,以及np.su()相加是从行还是列
A = 1/(1+np.exp(-(np.dot(w.T,X)+b)))
cost = (-1/m)*(np.sum(Y*(np.log(A))+(1-Y)*(np.log(1-A))))
# YOUR CODE ENDS HERE
# BACKWARD PROPAGATION (TO FIND GRAD)
#(≈ 2 lines of code)
# dw = ...
# db = ...
# YOUR CODE STARTS HERE
dw = (1/m)*np.dot(X,(A-Y).T)
db = (1/m)*np.sum(A-Y)
# YOUR CODE ENDS HERE
cost = np.squeeze(np.array(cost))
grads = {"dw": dw,
"db": db}
return grads, cost
w = np.array([[1.], [2.]])
b = 2.
X =np.array([[1., 2., -1.], [3., 4., -3.2]])
Y = np.array([[1, 0, 1]])
grads, cost = propagate(w, b, X, Y)
assert type(grads["dw"]) == np.ndarray
assert grads["dw"].shape == (2, 1)
assert type(grads["db"]) == np.float64
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print ("cost = " + str(cost))
propagate_test(propagate)
运行结果:
dw = [[0.99845601]
[2.39507239]]
db = 0.001455578136784208
cost = 5.801545319394553
All tests passed!
4.4优化
已初始化参数。
您还可以计算成本函数及其梯度。
现在,您需要使用梯度下降来更新参数。
练习6-优化
写下优化函数。目标是学习 以及 通过最小化成本函数 . 对于参数 , 更新规则是=− , 其中 是学习速率。
# GRADED FUNCTION: optimize
def optimize(w, b, X, Y, num_iterations=100, learning_rate=0.009, print_cost=False):
"""
This function optimizes w and b by running a gradient descent algorithm
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of shape (num_px * num_px * 3, number of examples)
Y -- true "label" vector (containing 0 if non-cat, 1 if cat), of shape (1, number of examples)
num_iterations -- 优化循环的迭代次数
learning_rate -- learning rate of the gradient descent update rule
print_cost -- True to print the loss every 100 steps
Returns:
params -- dictionary containing the weights w and bias b
grads -- dictionary containing the gradients of the weights and bias with respect to the cost function
costs -- list of all the costs computed during the optimization, this will be used to plot the learning curve.
Tips:
You basically need to write down two steps and iterate through them:
1) Calculate the cost and the gradient for the current parameters. Use propagate().
2) Update the parameters using gradient descent rule for w and b.
"""
w = copy.deepcopy(w)
b = copy.deepcopy(b)
costs = []
for i in range(num_iterations):
# (≈ 1 lines of code)
# Cost and gradient calculation
# grads, cost = ...
# YOUR CODE STARTS HERE
grads, cost = propagate(w, b, X, Y)
# YOUR CODE ENDS HERE
# Retrieve derivatives from grads
dw = grads["dw"]
db = grads["db"]
# update rule (≈ 2 lines of code)
# w = ...
# b = ...
# YOUR CODE STARTS HERE
w = w - learning_rate * dw
b = b - learning_rate * db
# YOUR CODE ENDS HERE
# Record the costs
if i % 100 == 0:
costs.append(cost)
# Print the cost every 100 training iterations
if print_cost:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
params, grads, costs = optimize(w, b, X, Y, num_iterations=100, learning_rate=0.009, print_cost=False)
print ("w = " + str(params["w"]))
print ("b = " + str(params["b"]))
print ("dw = " + str(grads["dw"]))
print ("db = " + str(grads["db"]))
print("Costs = " + str(costs))
optimize_test(optimize)
运行结果:
w = [[0.19033591]
[0.12259159]]
b = 1.9253598300845747
dw = [[0.67752042]
[1.41625495]]
db = 0.21919450454067652
Costs = [array(5.80154532)]
All tests passed!
练习7-预测
上一个函数将输出学习的w和b。我们可以使用w和b来预测数据集X的标签。实现predict()函数。计算预测有两个步骤:
1.计算̂ ==(+)
2.将a的条目转换为0(如果激活<=0.5)或1(如果激活>0.5),将预测存储在向量Y\u预测中。如果愿意,可以在for循环中使用If/else语句(尽管也有一种方法可以将其矢量化)。
# GRADED FUNCTION: predict
def predict(w, b, X):
'''
Predict whether the label is 0 or 1 using learned logistic regression parameters (w, b)
Arguments:
w -- weights, a numpy array of size (num_px * num_px * 3, 1)
b -- bias, a scalar
X -- data of size (num_px * num_px * 3, number of examples)
Returns:
Y_prediction -- a numpy array (vector) containing all predictions (0/1) for the examples in X
'''
m = X.shape[1]
Y_prediction = np.zeros((1, m))
w = w.reshape(X.shape[0], 1)
# Compute vector "A" predicting the probabilities of a cat being present in the picture
#(≈ 1 line of code)
# A = ...
# YOUR CODE STARTS HERE
A = sigmoid(np.dot(w.T , X) + b)
# YOUR CODE ENDS HERE
for i in range(A.shape[1]):
# Convert probabilities A[0,i] to actual predictions p[0,i]
#(≈ 4 lines of code)
# if A[0, i] > ____ :
# Y_prediction[0,i] =
# else:
# Y_prediction[0,i] =
# YOUR CODE STARTS HERE
if A[0, i] > 0.5 :
Y_prediction[0,i] = 1
else:
Y_prediction[0,i] = 0
# YOUR CODE ENDS HERE
return Y_prediction
w = np.array([[0.1124579], [0.23106775]])
b = -0.3
X = np.array([[1., -1.1, -3.2],[1.2, 2., 0.1]])
print ("predictions = " + str(predict(w, b, X)))
predict_test(predict)
运行结果:
predictions = [[1. 1. 0.]]
All tests passed!
记住什么:
您已经实现了几个功能:
1.初始化(w,b)
2.迭代优化损失以学习参数(w,b):
2.1计算成本及其梯度
2.2用梯度下降法更新参数
3.使用所学的(w,b)来预测给定示例集的标签
5.将所有函数合并到一个模型中
现在,您将看到如何按照正确的顺序将所有构建块(在前面的部分中实现的功能)组合在一起,从而构建整个模型。
练习8-模型
实现模型功能。使用以下符号:
- Y_prediction_test for your predictions on the test set
- Y_prediction_train for your predictions on the train set
- parameters, grads, costs for the outputs of optimize()
# GRADED FUNCTION: model
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.5, print_cost=False):
"""
Builds the logistic regression model by calling the function you've implemented previously
Arguments:
X_train -- training set represented by a numpy array of shape (num_px * num_px * 3, m_train)
Y_train -- training labels represented by a numpy array (vector) of shape (1, m_train)
X_test -- test set represented by a numpy array of shape (num_px * num_px * 3, m_test)
Y_test -- test labels represented by a numpy array (vector) of shape (1, m_test)
num_iterations -- hyperparameter representing the number of iterations to optimize the parameters
learning_rate -- hyperparameter representing the learning rate used in the update rule of optimize()
print_cost -- Set to True to print the cost every 100 iterations
Returns:
d -- dictionary containing information about the model.
"""
# (≈ 1 line of code)
# initialize parameters with zeros
# w, b = ...
#(≈ 1 line of code)
# Gradient descent
# parameters, grads, costs = ...
# Retrieve parameters w and b from dictionary "parameters"
# w = ...
# b = ...
# Predict test/train set examples (≈ 2 lines of code)
# Y_prediction_test = ...
# Y_prediction_train = ...
# YOUR CODE STARTS HERE
w , b = initialize_with_zeros(X_train.shape[0])#
parameters , grads , costs = optimize(w , b , X_train , Y_train,num_iterations , learning_rate , print_cost)
w , b = parameters["w"] , parameters["b"]#从字典参数中检索参数w和b
#预测测试/训练集的例子
Y_prediction_test = predict(w , b, X_test)
Y_prediction_train = predict(w , b, X_train)
# YOUR CODE ENDS HERE
# Print train/test Errors
if print_cost:
print("train accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations}
return d
测试是否通过:
model_test(model)
All tests passed!
如果你通过了所有的测试,运行下面的单元来训练你的模型。
logistic_regression_model = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations=2000, learning_rate=0.005, print_cost=True)
结果如下
Cost after iteration 0: 0.693147
Cost after iteration 100: 0.584508
Cost after iteration 200: 0.466949
Cost after iteration 300: 0.376007
Cost after iteration 400: 0.331463
Cost after iteration 500: 0.303273
Cost after iteration 600: 0.279880
Cost after iteration 700: 0.260042
Cost after iteration 800: 0.242941
Cost after iteration 900: 0.228004
Cost after iteration 1000: 0.214820
Cost after iteration 1100: 0.203078
Cost after iteration 1200: 0.192544
Cost after iteration 1300: 0.183033
Cost after iteration 1400: 0.174399
Cost after iteration 1500: 0.166521
Cost after iteration 1600: 0.159305
Cost after iteration 1700: 0.152667
Cost after iteration 1800: 0.146542
Cost after iteration 1900: 0.140872
train accuracy: 99.04306220095694 %
test accuracy: 70.0 %
点评:训练准确率接近100%。这是一个很好的健全性检查:您的模型正在工作,并且具有足够大的容量来适应训练数据。测试准确率为70%。考虑到我们使用的小数据集和logistic回归是一个线性分类器,这个简单模型实际上并不坏。但是不用担心,下周你会建立一个更好的分类器!
此外,您还可以看到,模型明显过度拟合了训练数据。在本专业的后面,您将学习如何减少过度拟合,例如通过使用正则化。使用下面的代码(并更改索引变量),您可以查看测试集图片上的预测。
# Example of a picture that was wrongly classified.
index = 1
plt.imshow(test_set_x[:, index].reshape((num_px, num_px, 3)))
print ("y = " + str(test_set_y[0,index]) + ", you predicted that it is a \"" + classes[int(logistic_regression_model['Y_prediction_test'][0,index])].decode("utf-8") + "\" picture.")
运行结果:
y = 1, you predicted that it is a “cat” picture.

我们也来画成本函数和梯度。
# Plot learning curve (with costs)
costs = np.squeeze(logistic_regression_model['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title("Learning rate =" + str(logistic_regression_model["learning_rate"]))
plt.show()
运行结果:
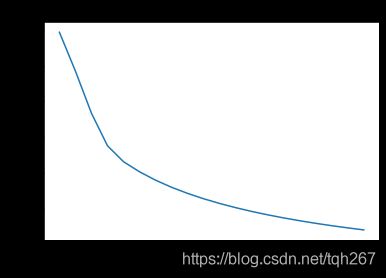
你可以看到成本在下降。这表明参数正在学习中。但是,您可以在训练集中对模型进行更多的训练。尝试增加上面单元格中的迭代次数,然后重新运行单元格。您可能会看到训练集的准确度提高了,但测试集的准确度降低了。这叫做过度装配。
6.进一步分析(可选/不分级练习)
恭喜你建立了你的第一个图像分类模型。让我们进一步分析它,并检查学习率的可能选择 .
学习率的选择
提醒:为了使梯度下降工作,你必须选择学习率明智。学习率 确定更新参数的速度。如果学习率过大,我们可能会“超调”最优值。类似地,如果它太小,我们将需要太多的迭代来收敛到最佳值。这就是为什么使用一个良好的学习率是至关重要的。
让我们比较一下我们模型的学习曲线和几种学习率的选择。运行下面的单元格。这大约需要1分钟。也可以尝试不同于我们初始化的learning_rates变量所包含的三个值,看看会发生什么。
learning_rates = [0.01, 0.001, 0.0001]
models = {}
for lr in learning_rates:
print ("Training a model with learning rate: " + str(lr))
models[str(lr)] = model(train_set_x, train_set_y, test_set_x, test_set_y, num_iterations=1500, learning_rate=lr, print_cost=False)
print ('\n' + "-------------------------------------------------------" + '\n')
for lr in learning_rates:
plt.plot(np.squeeze(models[str(lr)]["costs"]), label=str(models[str(lr)]["learning_rate"]))
plt.ylabel('cost')
plt.xlabel('iterations (hundreds)')
legend = plt.legend(loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()
运行结果:
Training a model with learning rate: 0.01
-------------------------------------------------------
Training a model with learning rate: 0.001
-------------------------------------------------------
Training a model with learning rate: 0.0001
-------------------------------------------------------
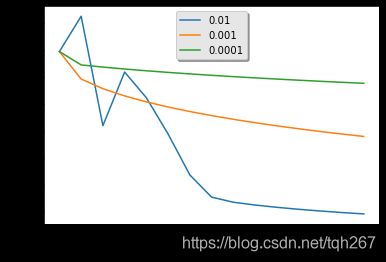
解释:
1.不同的学习率会产生不同的成本,从而产生不同的预测结果。
2.如果学习率太大(0.01),成本可能会上下波动。它甚至可能会出现分歧(尽管在本例中,使用0.01最终还是会得到一个很好的成本值)。
3.更低的成本并不意味着更好的模式。你得检查一下是否有可能过度拟合。当训练精度远远高于测试精度时,就会出现这种情况。
4.在深度学习中,我们通常建议您:
4.1选择更好地最小化成本函数的学习率。
4.2如果您的模型过拟合,请使用其他技术来减少过拟合(我们将在后面的视频中讨论这一点。)
7.使用自己的图像进行测试(可选/未分级练习)
恭喜你完成这项任务。您可以使用自己的图像并查看模型的输出。为此:
1点击本笔记本上方栏中的“file”,然后点击“open“进入Coursera Hub。
2将您的图像添加到这个Jupyter笔记本的目录中,在“images”文件夹中
3.在以下代码中更改图像的名称
4运行代码并检查算法是否正确(1=cat,0=非cat)!
# change this to the name of your image file
my_image = "my_image.jpg"
# We preprocess the image to fit your algorithm.
fname = "images/" + my_image
image = np.array(Image.open(fname).resize((num_px, num_px)))
plt.imshow(image)
image = image / 255.
image = image.reshape((1, num_px * num_px * 3)).T
my_predicted_image = predict(logistic_regression_model["w"], logistic_regression_model["b"], image)
print("y = " + str(np.squeeze(my_predicted_image)) + ", your algorithm predicts a \"" + classes[int(np.squeeze(my_predicted_image)),].decode("utf-8") + "\" picture.")
运行结果:
y = 0.0, your algorithm predicts a “non-cat” picture.

作业中要记住的内容:
1.对数据集进行预处理很重要。
2.您分别实现了每个函数:initialize()、propagate()、optimize()。然后你建立了一个模型()。
3.调整学习率(这是一个“超参数”的例子)可以对算法产生很大的影响。您将在本课程后面看到更多的例子!
最后,如果你愿意的话,我们邀请你在这个笔记本上尝试不同的东西。在尝试任何东西之前一定要提交。提交后,可以玩的东西包括:
-利用学习率和迭代次数
-尝试不同的初始化方法并比较结果
-测试其他预处理(将数据居中,或将每行除以其标准差)
参考文献:
http://www.wildml.com/2015/09/implementing-a-neural-network-from-scratch/
https://stats.stackexchange.com/questions/211436/why-do-we-normalize-images-by-subtracting-the-datasets-image-mean-and-not-the-c