【论文笔记】——PWCLO-Net
【论文笔记】——PWCLO-Net
开始前:cvpr2021新鲜出炉,我也正在开启自己的学术生涯,这篇论文是做激光雷达LiDAR里程计的,是我很感兴趣的方向,但是我正在从基础学习。肯定有很多我看不懂的,但是我还是试着翻译一下,试着跟随一下大佬的思路。好了,开始吧。
题目:PWCLO-Net Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization
使用分层嵌入掩码优化的 3D 点云中的深度 LiDAR 里程计
作者实验室:上海交通大学系统控制与信息处理教育部重点实验室医疗机器人研究所自动化系
代码网站:
https://github.com/IRMVLab/PWCLONet
论文网址:
https://arxiv.org/search/?query=PWCLO-Net&searchtype=all&source=header
CPVR open access:
https://openaccess.thecvf.com/CVPR2021
摘要
本文提出了一种用于深度 LiDAR 里程计( deep LiDAR odometry,这是干嘛的?)的新型 3D 点云学习模型,名为 PWCLO-Net,使用分层嵌入掩码优化(?)(hierarchical embedding mask optimization)。在该模型中,构建了用于 LiDAR 里程计任务的金字塔(Pyramid)、翘曲(Warping)和代价值函数(Cost volume)(?) (Pyramid, Warping, and Cost volume,PWC;翘曲这个词从三体中看到过,从三维到四维的翘曲点) 结构,分层的(hierarchically)以从粗到细(coarse-to-fine approach)的方法提取(refine)估计姿态( refine the estimated pose in a coarse-to-fine approach hierarchically )。建立了一个细致的代价容量函数(?cost volume)联系两个点云并得到嵌入式运动模态(?没明白这是啥意思)(An attentive cost volume is built to associate two point clouds and obtain embedding motion patterns.)然后,提出了一种新颖的可训练嵌入掩码(?embedding mask)来权衡所有点的局部运动模式(local motion patterns),以回归整体位姿并过滤离群点。估计的当前位姿用于扭转(warp)第一个点云跨过与第二个点云的距离,然后剩余的运动(residual motion)的 代价值函数(?cost volume) 就建立了。同时嵌入掩码(embedding mask)由粗到细分层优化,以获得更准确的过滤信息用以进行姿态提取。(the embedding mask is optimized hierarchically from coarse to fine to obtain more accurate filtering information for pose refinement. )可训练的姿态扭转提取过程(pose warp-refinement process)被反复使用,以使姿势估计对异常值更加稳健。我们的 LiDAR 里程计模型的卓越性能和有效性在 KITTI 里程计数据集上得到了证明。我们的方法优于所有最近的基于学习的方法,并且在 KITTI 里程计数据集的大多数序列上优于基于几何的方法,LOAM 与映射优化。我们的源代码将在 https://github.com/IRMVLab/PWCLONet 上发布。
1.Introduction
视觉/激光雷达里程计是自动驾驶的关键技术之一。该任务使用两个连续的图像或点云来获得两帧之间的相对姿态变换,并作为移动机器人后续规划(subsequential planning)和决策的基础[13]。最近,与基于手工特征(hand-crafted)的传统方法相比,基于学习的里程计方法在数据集上显示出令人印象深刻的准确性。发现基于学习的方法可以处理稀疏特征(sparse features)和动态环境(dynamic environments)[9, 14],这对于传统方法来说通常是困难的。据我们所知,大多数基于学习的方法都是基于 2D 视觉里程计 [26, 33, 15, 29, 23, 25] 或利用 LiDAR 的 2D 投影 [16, 22, 27, 10, 11] ,基于3D 点云的 LiDAR 里程计未有探索过。本文旨在通过原始 3D 点云直接估计 LiDAR 里程计。
对于 3D 点云中的 LiDAR 里程计,存在三个挑战:1)由于离散的(discrete) LiDAR 点数据是在两个连续帧(consecutive frame)中分别获得的,因此很难找到两帧之间的点对;2) 帧中属于某个物体的某些点如果被其他物体遮挡或由于激光雷达分辨率的限制而未被捕获,则在其他视图中可能看不到;3)一些属于动态物体的点不适合用于姿态估计,因为这些点具有动态物体的不确定运动。
对于第一个挑战,Zheng [32]使用在 2D 深度图像中判断的匹配关键点对。 然而,由于 LiDAR 的离散感知(discrete perception),对应关系很粗糙(rough)。本文采用 3D 点云的代价值函数(cost volume) [28, 24] 来获得两个连续帧之间的加权软对应(weighted soft correspondence)。对于第二个和第三个挑战,需要过滤不符合整体位姿的不匹配点或动态对象。 LO-Net [10] 通过对 3D 点法线的一致性误差( consistency error of the normal) 进行加权(weighting)来训练额外的掩码估计网络(mask estimation network) [33, 30]。在我们的网络中,提出了一个内部可训练嵌入掩码(internal trainable embedding mask),从 代价值函数(cost volume) 中 权衡局部运动模式以回归整体位姿(weigh local motion patterns from the cost volume to regress the overall pose) 。 通过这种方式,可以优化掩码(mask)以获得更准确的姿态估计,而不是依赖于几何对应(geometry correspondence)。另外,建立PWC结构来得到稀疏点层的大运动,并且在密集层中提取位姿。如图1显示,嵌入掩码(embedding mask)也进行了分层优化,以获得更准确的过滤信息来提取位姿估计。
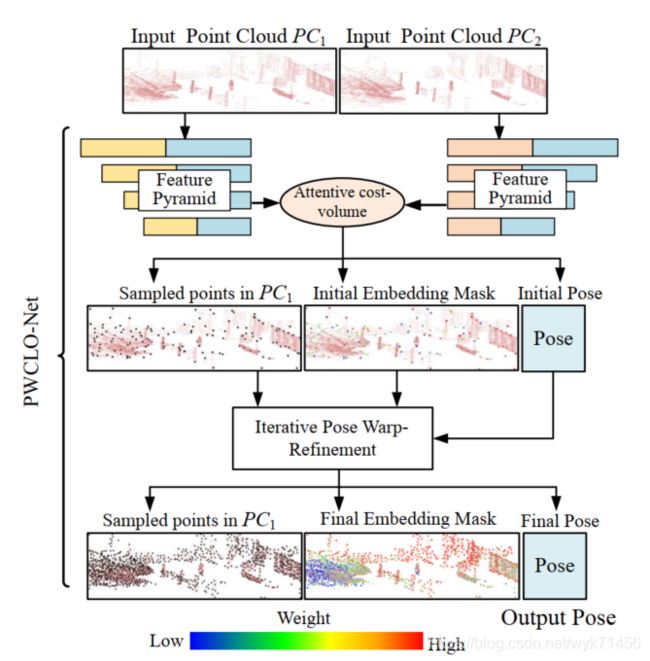
图1 我们提出的PWCLO-Net中的点特征金字塔,位姿扭转,和细致代价值函数(PWC,翻译的可能不准确,先理解吧)结构。通过 迭代位姿扭转-提取(iterative pose warp-refinement) 的方法逐层提取位姿。通过使所有模块可微分实现端到端的整个过程(The whole process is realized end-to-end by making all modules differentiable) 在LiDAR点云中,小的红色点群是整个点云。大的黑点是PC1中的采样点。嵌入掩码(embedding mask,翻译可能不太准,我还不太明白mask是做什么用的) 中大点的不同颜色衡量采样点对姿态估计的贡献。
总的来说,我们的贡献如下:
-
用于3D LiDAR里程计任务的点特征金字塔(Point Feature Pyramid),位姿扭转(pose wrapping),和代价值函数(cost volume)(PWC) 旨在捕捉两帧之间的大运动(large motion) 并完成可训练的迭代3D特征匹配(iterative 3D feature matching )和位姿回归(pose regression)。
-
在这个结构中,提出了分层嵌入掩码来过滤不匹配点并将点中的代价值函数(cost volume embedded in points)转换为在每个提取层的整体自我运动(overall egomotion in each refinement level)(这段也不太懂,整体的自我运动和之前的大运动,局部运动有什么说法?还有这里的refine是细化还是提取的意思呢?一直都有这个问题。还有cost volume是个常用的概念定义,我还不太懂。。)同时,分层地优化和提取了嵌入掩码,以获得更准确的过滤信息,为了(以)按照点的密度进行位姿提取。
-
基于位姿变换的特点,提出了位姿扭转和位姿提取来逐层迭代地提取估计位姿。建立了一个完全端到端的框架,名为PWCLO-Net,其中所有的模块都是完全可微的(differentiable),使每个过程不再独立(independent)和组合优化(combinedly optimized)。
-
最后,我们的理论在KITTI里程计数据集上进行了演示[8,7]。最终实验和研究表明了所提出理论的优越性和每个设计的有效性。据我们所知,据我们所知,我们的方法优于所有最近的基于学习的 LiDAR 里程计,甚至在大多数序列(sequences) 上优于基于几何的 映射优化 LOAM(geometry-based LOAM with mapping optimization) [31]。(这里的序列,LOAM我还不太明白是什么,序列可能是KITTI的数据集的一些内容,LOAM应该是另一种算法)
2.相关工作
2.1 深度 LiDAR 里程计
深度学习在视觉里程计中取得了令人瞩目的进展[15,29]。然而,带有深度学习的3D LiDAR里程计仍是个挑战性问题。在一开始,Nicolai等[16]将两个连续的LiDAR点云投影到2D平面得到2个2D深度图,然后用2D卷积核(convolution)和全连接层(FC,fully connected) 实现基于学习的LiDAR里程计。他们的工作证实了基于学习的理论对于LiDAR里程计是可行的尽管他们的实验结果并不优秀。Velas等[22]也把LiDAR点云投影到2D平面但是用了三个通道来编码信息,包括高度height,范围range和强度intensity。然后卷积核和FC全连接层用于位姿回归(pose regression)。 仅在估计平移(translation)时性能很好,但在估计 6-DOF (6自由度)位姿时性能很差。Wang等人[27]将点云投影到全景深度图(panoramic depth images)上,并堆叠两帧图像一起作为输入。然后平移子网络和Flownet[5]方向子网络分别用来估计平移和方向。[10]也把3D LiDAR点云预处理成2D信息但是用了圆柱投影[2]。然后,估计出每个3D点的法向量建立两帧之间的一致性约束(consistency constraint),并且估计不确定性掩码(uncertainty mask)以掩蔽动态区域(dynamic regions)(掩码是用来干嘛的呢?小白表示看不太懂。。动态区域又是啥呢。。)zheng等人[32]在从3D LiDAR点云投影到**2D球形深度图(2D spherical depth images)**中,通过经典检测和匹配算法提取了匹配的关键点对(matched keypoint pairs)。然后使用了基于结构的PointNet[17]以从匹配的关键点对回归位姿。[11]提出一个基于学习的网络来生成高置信度的匹配点对,然后采用奇异值分解(SVD)得到6-DOF(6自由度)的位姿。[3]介绍了一种关于 LiDAR 里程计的无监督学习方法。
2.2 相关深度点(Deep Point Correlation)
以上的研究都用2D投影信息用于LiDAR里程计学习,把LiDAR里程计转变为2D学习问题。Wang[27]基于相同的2D卷积模型把3D点输入和2D投影信息输入进行比较。发现基于3D输入的方法性能较差。随着3D深度学习的发展[17,18],FlowNet3D[12]提出了一个嵌入式层来学习两个连续帧中的点的相关性。之后,Wu[28]提出了点云的代价值函数(cost volume,原来是这个人提出来的,等下找找) 理论,并且Wang发展出了细致代价值理论(attentive cost volume method 我也不知道是不是这么翻译。。先跟着感觉走,后面我要问问导师和同学) 。点的代价值函数引入了每个点的运动模式(motion patterns)。从代价值函数回归位姿成了一个新的方向和挑战,而且,并非所有的点运动都是针对整体位姿运动的。我们利用原始3D点云数据中直接估计位姿,并解决遇到的新挑战。
另外,我们受到Su提出的流网络中的 金字塔(Pyramid),扭转(Wraping),和代价值函数(cost volume)(PWC)结构 的启发[20].(这一坨是这篇论文中提出的。。)这篇工作使用了三个模块(金字塔(Pyramid),扭转(Wraping),和代价值函数(cost volume))来通过由粗到细的方法提取光流(optical flow) (光流是什么?。。)[28,24]这两篇关于3D场景流(3D scene flow) 的工作也用了PWC结构来提取估计的点云中的3D场景流。本文中,这个idea应用到了位姿估计提取,用于LiDAR里程计的PWC结构第一次建立。
3.PWCLO-Net
我们的理论从原始3D点云中通过端到端的方法学习LiDAR里程计,无需将点云预先投影到2D数据,与相关工作部分中介绍的深度LiDAR里程计方法有着显著不同。

图2 所提出的PWCLO-Net结构细节。该网络由点特征金字塔(point feature pyramid)中的四个集合卷积层、一个注意力代价值函数(attentive cost volume)、一个初始嵌入掩码(initial embedding mask)和位姿生成模块(pose generation module)以及三个位姿扭转-提取(pose wrap-refinement modules)模块组成。 网络从四个级别输出预测位姿以进行监督训练。
图2展示了PWCLO-Net的完整结构。输入网络的是两个点云 P C 1 = { x i ∣ x i ∈ R 3 } i = 1 N PC1=\{ x_i|x_i \in \mathbb R^3\}_{i=1}^{N} PC1={xi∣xi∈R3}i=1N 和 P C 2 = { y i ∣ y i ∈ R 3 } i = 1 N PC2=\{ y_i|y_i \in \mathbb R^3\}_{i=1}^{N} PC2={yi∣yi∈R3}i=1N 从两个相邻帧采样得到。这两个点云首先通过由3.1部分介绍的 多个集合卷积层(several set conv layers) 组成的孪生特征金字塔(siamese feature pyramid) 进行降采样(decode) 。然后attentive cost volume用于产生embedding features,这部分将在Sec2中进行描述。为了从embedding features 回归位姿变换(pose transformation) ,提出了分层embedding mask优化,在Sec3.3。接下来,Sec3.4中提出位姿 扭转提取 方法(pose warp-refinement method) 用由粗到细的方法(coarse-to-fine) 提取位姿估计。最后,网络输出四元数(quaternion) q ∈ R 4 q \in \mathbb R^4 q∈R4 和平移向量(translation vector) t ∈ R 3 t \in \mathbb R^3 t∈R3 .
3.1 Siamese Point Feature Pyramid孪生点特征金字塔
输入点云通常无序而稀疏地分布在很大的3D空间。建立了一个由多个集合卷积层组成的孪生特征金字塔(siamese feature pyramid consisting of several set conv layers) 进行降采样(decode)和提取(extract) 每个点云的分层特征(hierarchical features)。使用了最远点采样(Farthest Point Sampling (FPS)) [18] 和共享多层感知机(shared Multi-Layer Perceptron(MLP) )。卷积层(set conv) 的公式是:
f i = max k = 1 , 2 , . . . K ( M L P ( ( x i k − x i ) ⊕ f i k ⊕ f i c ) ) f_i= \max_{k=1,2,...K}(MLP((x_i^k-x_i)\oplus f_i^k\oplus f_i^c)) fi=k=1,2,...Kmax(MLP((xik−xi)⊕fik⊕fic))
(这个公式我还不太懂。。。)
其中 x i x_i xi通过FPS得到第i个采样点。并且 x i x_i xi周围的 K K K点由KNN(K Nearest Neighbors )算法选出。 f i c f_i^c fic和 f i k f_i^k fik是 x i x_i xi和 x i k x_i^k xik 的局部特征local features(他们在金字塔第一层是空的)。 f i f_i fi是位于中心点 x i x_i xi的输出特征output feature。 ⊕ \oplus ⊕代表两个向量级联(concatenation of two vectors 不太明白这个级联的意思。。)并且 max k = 1 , 2 , . . . K ( ) \max\limits_{k=1,2,...K}() k=1,2,...Kmax()代表最大池化(max pooling)操作。图2展示了建立的分层特征金字塔(hierarchical feature)。孪生金字塔(siamese pyramid)[4]意思是所建的金字塔的学习参数对于这两个点云是共享的。
3.2 Attentive cost volume
(这个attentive是啥意思?专注的?细心的?肯帮忙的?我还不理解,但是估计是cost volume的升级版)
接着,采用了[24]中的带注意力的点代价值函数来联系两个点云。cost volume通过联系特征金字塔后的两个点云来生成点的embedding features。
embedding features包括了两个点云中点的联系信息。如图3所示, F 1 = { f i ∣ f i ∈ R c } i = 1 n F_1=\{ f_i|f_i \in \mathbb R^c\}_{i=1}^{n} F1={fi∣fi∈Rc}i=1n 是点云 P C 1 = { x i ∣ x i ∈ R 3 } i = 1 n PC_1=\{ x_i|x_i \in \mathbb R^3\}_{i=1}^{n} PC1={xi∣xi∈R3}i=1n 的特征, F 2 = { g j ∣ g j ∈ R c } i = 1 n F_2=\{ g_j|g_j \in \mathbb R^c\}_{i=1}^{n} F2={gj∣gj∈Rc}i=1n 是点云 P C 2 = { y i ∣ y i ∈ R 3 } i = 1 n PC_2=\{ y_i|y_i \in \mathbb R^3\}_{i=1}^{n} PC2={yi∣yi∈R3}i=1n 的特征。两个点云的embedding features用下面的方法计算:
w 1 , i k = s o f t m a x ( u ( x i , y j k , f i , g j k ) ) k = 1 K 1 w_{1,i}^k=softmax(u(x_i,y_j^k,f_i,g_j^k))_{k=1}^{K_1} w1,ik=softmax(u(xi,yjk,fi,gjk))k=1K1 p e i = ∑ k = 1 k 1 w 1 , i k ⊙ v ( x i , y j k , f i , g j k ) pe_i=\sum_{k=1}^{k_1}w_{1,i}^k\odot v(x_i,y_j^k,f_i,g_j^k) pei=k=1∑k1w1,ik⊙v(xi,yjk,fi,gjk) w 2 , i k = s o f t m a x ( u ( x i , x i k , p e i , p e i k ) ) k = 1 K 2 w_{2,i}^k=softmax(u(x_i,x_i^k,pe_i,pe_i^k))_{k=1}^{K_2} w2,ik=softmax(u(xi,xik,pei,peik))k=1K2 e i = ∑ k = 1 k 2 w 2 , i k ⊙ v ( x i , x i k , p e i , p e i k ) e_i=\sum_{k=1}^{k_2}w_{2,i}^k\odot v(x_i,x_i^k,pe_i,pe_i^k) ei=k=1∑k2w2,ik⊙v(xi,xik,pei,peik)
其中 y i k y_i^k yik和 g j k g_j^k gjk分别代表了从 P C 2 PC_2 PC2中所选 K 1 K_1 K1点的坐标和局部变量。 ⊙ \odot ⊙代表点乘。 u ( ⋅ ) u(\cdot) u(⋅)和 v ( ⋅ ) v(\cdot) v(⋅)代表注意力降采样(attention encode)和特征降采样方程,参考[24]。 u ( ⋅ ) u(\cdot) u(⋅)对3D欧几里得空间信息和点特征进行降采样来产生注意力权重(attention weights), v ( ⋅ ) v(\cdot) v(⋅)表示对两帧点云的空间信息和特征的进一步降采样。输出 E = { e i ∣ e i ∈ R c } i = 1 n E=\{e_i|e_i \in \mathbb R^c \}_{i=1}^n E={ei∣ei∈Rc}i=1n是 P C 1 PC_1 PC1的embedding features。

*图3 Attention Cost-volume.这个模块把带有局部特征两帧点云作为输入并关联两个点云。最后,模块输出位于 P C 1 PC_1 PC1的嵌入特征embedding features
3.3 分层embedding mask优化
把两帧之间的 嵌入特征 E E E(embedding features E E E) 转换到 全局的连续位姿变换(global consistent pose transformation) 是一个新问题。在这个部分,提出了一种新的embedding mask以从embedding features 生成位姿转换(pose transformation,这是矩阵吧?)
应当提及,一些点可能属于动态目标或者在另一帧中被遮挡了。有必要过滤掉这些点,保留对LiDAR里程计任务有用的点。为了解决这个问题,嵌入特征embedding features E = { e i ∣ e i ∈ R c } i = 1 n E=\{e_i|e_i \in \mathbb R^c\}_{i=1}^n E={ei∣ei∈Rc}i=1n和 P C 1 PC_1 PC1的特征 F 1 F_1 F1输入一个共享的MLP(多层感知机),然后沿着点的维度进行softmax操作来获得embedding mask(如图2中的初始embedding mask):
M = s o f t m a x ( s h a r e d M L P ( E ⊕ F 1 ) ) M=softmax(sharedMLP(E \oplus F_1)) M=softmax(sharedMLP(E⊕F1))
其中 M = { m i ∣ m i ∈ R c } i = 1 n M=\{m_i|m_i \in \mathbb R^c\}_{i=1}^n M={mi∣mi∈Rc}i=1n代表可训练masks,用于优先考虑 P C 1 PC_1 PC1在的 n n n个点的embedding features(represents trainable masks for prioritizing embedding features of n points in PC1)。每个点都有一个在0到1之间的特征权重。一个点的权重越低,这个点就更有可能需要被滤除,反之亦然。然后,四元数(quaternion) q ∈ R 4 q \in \mathbb R^4 q∈R4和平移向量 t ∈ R 3 t \in \mathbb R^3 t∈R3可以分别通过 embedding features 和 全连接层(FC layers) 进行加权来生成, q q q被归一化来符合旋转的特征。
q = F C ( ∑ i = 1 n e i ⊙ m i ) ∣ F C ( ∑ i = 1 n e i ⊙ m i ) ∣ q=\frac{FC(\sum\limits_{i=1}^{n}e_i \odot m_i)}{ \bigg\vert FC(\sum\limits_{i=1}^{n}e_i \odot m_i) \bigg\vert} q=∣∣∣∣FC(i=1∑nei⊙mi)∣∣∣∣FC(i=1∑nei⊙mi) t = F C ( ∑ i = 1 n e i ⊙ m i ) t=FC(\sum\limits_{i=1}^{n}e_i \odot m_i) t=FC(i=1∑nei⊙mi)
可训练的mask M M M 也是分层提取的一部分。如图2所示,embedding mask被传播到点云的密集层,就像embedding features E E E和位姿一样。embedding mask在扭转-提取过程中用由粗到细的方法优化,使得最终的mask估计和位姿变换的计算准确和可靠。我们称这个过程为分层embedding mask优化。
3.4 位姿 扭转-提取 模块
为了以端到端的方式实现 由粗到细的提取过程,我们提出了如图4所示的基于位姿变换的可微分的wrap-refinement模块。这个模块包含了几个关键部分:集合上卷积层(set upconv layer),位姿扭转,embedding feature和embedding mask refinement,和pose refinement。
set upconv layer:为了用由粗到细的方法提取位姿估计,这里采用了set upconv layer[12]来使点云的特征能够从稀疏层传递到稠密层。 l + 1 l+1 l+1层的embedding features E l + 1 E^{l+1} El+1和embedding masks M l + 1 M^{l+1} Ml+1通过set upconv layer传播,来获得需要在第 l l l 层被优化的粗的embedding features C E l = { c e i l ∣ c e i l ∈ R c l } i = 1 n l CE^l=\{ce_i^l|ce_i^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} CEl={ceil∣ceil∈Rcl}i=1nl 和粗的embedding masks C M l = { c m i l ∣ c m i l ∈ R c l } i = 1 n l CM^l=\{cm_i^l|cm_i^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} CMl={cmil∣cmil∈Rcl}i=1nl.
Pose Warping:pose warping过程意思是第 ( l + 1 ) (l+1) (l+1)层的四元数 q l + 1 q^{l+1} ql+1和平移向量 t l + 1 t^{l+1} tl+1用于扭转 P C 1 l = { x i l ∣ x i l ∈ R c l } i = 1 n l PC^l_1=\{x_i^l|x_i^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} PC1l={xil∣xil∈Rcl}i=1nl来产生 P C 1 , w a r p e d l = { x i , w a r p e d l ∣ x i , w a r p e d l ∈ R c l } i = 1 n l PC^l_{1,warped}=\{x_{i,warped}^l|x_{i,warped}^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} PC1,warpedl={xi,warpedl∣xi,warpedl∈Rcl}i=1nl.扭转后的 P C 1 , w a r p e d l PC^l_{1,warped} PC1,warpedl比原来的 P C 1 l PC^l_{1} PC1l距离 P C 2 l PC^l_{2} PC2l更近,这使得在 l l l 层残余运动估计(residual motion estimation)更简单。扭转变换的方程如下:
[ 0 , x i , w a r p e d l ] = q l + 1 [ 0 , x i l ] ( q l + 1 ) − 1 + [ 0 , t l + 1 ] [0,x_{i,warped}^l]=q^{l+1}[0,x_i^l](q^{l+1})^{-1}+[0,t^{l+1}] [0,xi,warpedl]=ql+1[0,xil](ql+1)−1+[0,tl+1]
然后, P C 1 , w a r p e d l PC_{1,warped}^l PC1,warpedl和 P C 2 l PC_2^l PC2l 之间的attentive cost volume被重新计算以估计剩余运动(residual motion).根据3.2中介绍的方法, P C 1 , w a r p e d l PC_{1,warped}^l PC1,warpedl和 P C 2 l PC_{2}^l PC2l之间的re-embeding features被重新计算,记为 R E l = { r e i l ∣ r e i l ∈ R c l } i = 1 n l RE^l=\{re_i^l|re_i^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} REl={reil∣reil∈Rcl}i=1nl.

图4 所提出的在第 l l l 层的Pose Warp-Refinement 模块的细节
Embedding Feature and Embedding Mask Refinement:
产生的粗embedding feature c e i l ce_i^l ceil ,re-embedding feature r e i l re_i^l reil,和 P C 1 l PC_1^l PC1l的特征 f i l f_i^l fil级联操作,然后输入一个共享的MLP中以获得在第 l l l 层的embedding features E l = { e i l ∣ e i l ∈ R c l } i = 1 n l E^l=\{e_i^l|e_i^l \in \mathbb R^{c^l}\}_{i=1}^{n^l} El={eil∣eil∈Rcl}i=1nl
e i l = M L P ( c e i l ⊕ r e i l ⊕ f i l ) e_i^l=MLP(ce_i^l \oplus re_i^l \oplus f_i^l) eil=MLP(ceil⊕reil⊕fil)这个 MLP 的输出是第 l l l 层优化的嵌入特征embedding features,它不仅会参与后续的位姿生成操作,还会作为输入输出到下一层 warp-refinement 模块。
与embedding feature的refinement(refinement这个是 什么意思?改进?
提取?细化?还没太明白。。)一样,将新生成的embedding feature 嵌入特征 e i l e^l_i eil、生成的粗嵌入掩码coarse embedding mask c m i l cm_i^l cmil ,和 P C 1 PC_1 PC1的局部特征 f i l f_i^l fil 连接起来,并沿点维度输入到共享的 MLP 和 softmax 操作中,以获得第 l l l 层的 嵌入掩码embedding mask M l = { m i l ∣ m i l ∈ R c l } i = 1 l M^l=\{m_i^l|m_i^l \in \mathbb R^{c^l}\}_{i=1}^l Ml={mil∣mil∈Rcl}i=1l :

Pose Refinement:
残差 △ q l \bigtriangleup q^l △ql和 △ t l \bigtriangleup t^l △tl 可以根据3.3中的公式(7)和(8)从细化(refined)嵌入特征和掩码中获得. 最后,第 l l l 层的refined quaternion四元数 q l q_l ql 和平移向量 t l t^l tl 可以通过以下方式计算:
q l = △ q l q l + 1 q^l=\bigtriangleup q^lq^{l+1} ql=△qlql+1 [ 0 , t l ] = △ q l [ 0 , t l + 1 ] ( △ q l ) − 1 + [ 0 , △ t l ] . [0,t^l]=\bigtriangleup q^l[0,t^{l+1}](\bigtriangleup q^l)^{-1}+[0,\bigtriangleup t^l]. [0,tl]=△ql[0,tl+1](△ql)−1+[0,△tl].
3.5 Training loss 训练损失
网络从点云的四个不同的层级输出四元数 q l q^l ql 和平移向量 t l t^l tl 。每层的输出都会进入一个设计好的损失函数,用来计算监督损失 l l l^l ll .由于平移向量 t t t 和四元数 q q q 的尺度和单位不同,两个可以学习的参数 s x s_x sx 和 s q s_q sq 被引入,就像之前深度里程计工作[10]。训练损失函数在 l l l 层的函数:

其中 ∣ ∣ ⋅ ∣ ∣ ||\cdot|| ∣∣⋅∣∣ 和 ∣ ∣ ⋅ ∣ ∣ 2 ||\cdot||_2 ∣∣⋅∣∣2分别代表 l 1 − norm l_1-\text{norm} l1−norm和 l 2 − norm l_2-\text{norm} l2−norm. t g t t_{gt} tgt 和 q g t q_{gt} qgt 分别是ground-truth位姿变换矩阵,生成的ground-truth平移向量和四元数。然后,采用多尺度监督的方法。整个的训练损失 l l l 是:

其中 L L L 是warp-refinement层的总数, α l α^l αl 表示第 l l l 层的权重.
4.Implementation 应用
4.1. KITTI Odometry Dataset
KITTI里程计[8,7]由22个独立序列。我们的实验中使用了数据集中的 Velodyne LiDAR 点云。所有点云扫描都有 XYZ 坐标和反射率信息。 序列 00-10(23201 次扫描)包含地面实况位姿(轨迹),而其余序列 11-21(20351 次扫描)没有公开可用的地面实况。通过在高速公路、住宅区道路、校园道路等不同道路环境下行驶,采样车从不同环境中采集点云用于激光雷达测距任务。
数据预处理: 我们的方法中仅使用 LiDAR 点的坐标。 由于地面实况姿态表示在左相机坐标系中,因此该网络的所有训练和评估过程都在左相机坐标系中进行。 因此,从 Velodyne LiDAR 捕获的点云首先通过以下方式转换到左相机坐标系:

其中 P c a m P_{cam} Pcam和 P v e l P_{vel} Pvel分别是左相机坐标系和激光雷达坐标系中的点云坐标, T r T_r Tr是每个序列的标定矩阵。 此外,LiDAR 传感器收集的点云通常在每一帧的点云边缘都包含异常值。 这通常是因为物体远离 LiDAR 传感器,从而在边缘形成不完整的点云。 为了过滤掉这些离群点,对于每个点云 P c a m P_{cam} Pcam,车辆周围30×30 m 2 m^2 m2正方形区域中的点都被过滤掉了。 为加快数据读取和训练速度,将高度小于 0.55m 的地面移除。 对于我们的模型,去除和保留地面的性能是相似的。 详细对比见补充材料.
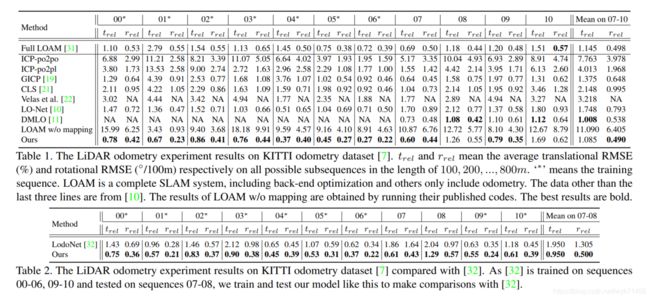
表1 LiDAR里程计在KITTI里程计数据集上的实验结果。 t r e l t_{rel} trel和 r r e l r_{rel} rrel意思分别是在长度为100,200…800m的所有可能的子序列的平均平移RMSE(均方根误差,%)和旋转的RMSE(°/100m)。‘*’意思是训练序列。LOAM是一个完整的SLAM系统,包括后端优化(back-end optimization)而其他的只包含里程计。除了最后三行,数据来源于[10]。LOAM w/o mapping的结果通过运行他们公开的代码而获得。最好的结果是大胆的。(啥意思?。。)
表2 与[32]相比,LiDAR里程计在KITTI里程计数据集上的实验结果。由于[32]是在00-06,09-10序列上训练的,并且在07-08序列上测试的,为了与[32]进行对比,我们也这样训练和测试我们的模型。
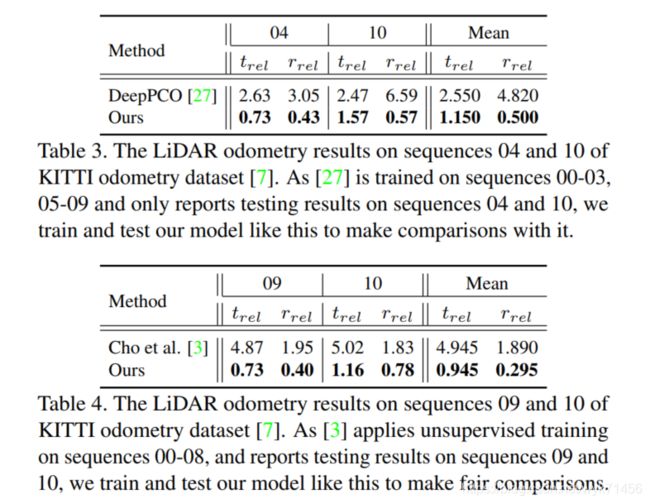
表3 LiDAR里程计在KITTI里程计数据集的04和10序列的结果[7]。由于[27]在序列00-03,05-09上训练,并且只报道了04和10序列的测试结果,我们为与之对比也采用同样的训练和测试方法。
表4 LiDAR 里程计结果在 KITTI 里程计数据集 [7] 的序列 09 和 10 上。 由于 [3] 对序列 00-08 应用无监督训练,并报告序列 09 和 10 的测试结果,我们像这样训练和测试我们的模型以进行公平比较。
Data Augmentation (数据增强): 我们通过增强矩阵 T a u g T_{aug} Taug 来增强训练数据集,该矩阵由旋转矩阵 R a u g R_{aug} Raug 和平移向量 t a u g t_{aug} taug 生成。 偏航-俯仰-滚转欧拉角的变化值由 0° 附近的高斯分布生成。 然后可以从这些随机欧拉角中获得 R a u g R_{aug} Raug 。 类似地, t a u g t_{aug} taug 是由相同的过程生成的。 然后使用组合的 T a u g T_{aug} Taug 来增强 P C 1 PC_1 PC1 以获得新的点云 P C 1 , a u g PC_{1,aug} PC1,aug :
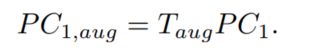
相应地,ground truth 变换矩阵也修改为:
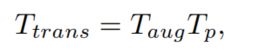
其中 T p T_p Tp 表示从 P C 1 PC_1 PC1 到 P C 2 PC_2 PC2 的原始地面实况姿态变换矩阵。 然后使用 T t r a n s T_{trans} Ttrans 生成 q g t q_{gt} qgt 和 t g t t_{gt} tgt 来监督网络的训练。
4.2 Networks Details
在训练和评估过程中,输入的 N N N 个点分别从两帧的点云中随机采样。 不需要原始输入的两个点云具有相同的点数。 在提议的网络中, N N N 设置为 8192。 MLP 中的每一层都包含 ReLU 激活函数,除了 FC 层。 对于共享 MLP, 1 × 1 1 × 1 1×1 卷积 1 步长是实现方式。 补充材料中描述了详细的层参数,包括 MLP 中的每个线性层宽度。 所有训练和评估实验均在具有 TensorFlow 1.9.0 的单个 NVIDIA RTX 2080Ti GPU 上进行。 采用 Adam 优化器, β 1 = 0.9 β1 = 0.9 β1=0.9, β 2 = 0.999 β2 = 0.999 β2=0.999。 初始学习率为 0.001,每 200000 步呈指数衰减,直到 0.00001。 公式(14)中可训练参数 s x s_x sx和 s q s_q sq的初始值分别设置为0.0和-2.5。对于公式(15), α 1 = 1.6 α1 = 1.6 α1=1.6, α 2 = 0.8 α2 = 0.8 α2=0.8, α 3 = 0.4 α3 = 0.4 α3=0.4, L = 4 L = 4 L=4。
批量大小为 8。
(未完待续)