清华大学王晨阳:轻量级Top-K推荐框架及相关论文介绍

本文内容整理自 PaperWeekly 和 biendata 在 B 站组织的直播回顾,点击文末阅读原文即可跳转至 B 站收看本次分享完整视频录像,如需嘉宾课件,请在 PaperWeekly 公众号回复关键词课件下载获取下载链接。
构建一个公平的推荐算法“合唱团”,这也是框架名称 ReChorus 的由来 图片出处:pixabay
作者简介:王晨阳,清华大学计算机系人智所信息检索课题组二年级博士生,研究方向为推荐系统中用户的动态需求,主要包括序列推荐、引入知识及时间动态性的意图理解等,在WWW、SIGIR等会议发表多篇论文。
推荐系统中基于深度学习的方法近几年来层出不穷,然而不同工作之间实验设定和实现细节的差异使得我们很难直接比较不同论文的相对效果。有论文针对推荐领域中实验的可复现性提出了质疑,认为百花齐放的表象背后的实际情况是推荐系统领域长时间的停滞不前。
为此,我们基于最近发表在 SIGIR’20 工作的代码,整理出了一个轻量级的 Top-K推荐框架 ReChorus,旨在分离模型间共同的实验设定和不同的模型设计,使得各个模型能够在一个公平的 benchmark 上进行对比。ReChorus 足够简单易上手,既适合初学者了解推荐领域的经典模型,也适合研究者快速实现自己的想法;同时 ReChorus 足够灵活,可以轻松适配个性化的数据格式和评测流程。
本文还会介绍目前 ReChorus 中表现最好的模型——引入商品关系和时间动态性的商品表示。这个工作显式建模了目标商品和近期交互商品之间的关系,以及不同关系所产生的影响如何随时间变化。实验表明该方法得到的商品表示可以灵活地应用于各种推荐算法并取得显著的效果提升。

推荐系统领域的劣币驱逐良币

在开始介绍 ReChorus 前,让我们先思考几个问题。
第一个问题,如上图所示,简单回忆的话,推荐系统领域所用的 baseline 是不是往往就那么几个?可能研究者们不再像过去那样倾向于同某个领域或问题设定下最好的 baseline 做比较,转而和比较流行的 baseline 做比较。只做到了比某个流行的baseline 表现好一点,研究者就宣称自己达到了 state-of-the-art(SOTA) 的性能。如果你去找那些非常强的 SOTA 的模型做比较,提升就会相对变小,论文相对更难发,而这样的状况很可能导致劣币驱逐良币的趋势。
近期就有这样的一批论文发表,研究者们都自称达到了 SOTA 的性能。可以预见的是后续的研究者撰写新一批论文,选择 baseline 进行比较时会更倾向于选这批论文中表现比较差的,由此对比出他们的论文算法有了比较大的提升。虽然这样会让整体的论文发表呈现百家争鸣、百花齐放的表象。但是这样的机制会使真正高质量 baseline 在浪潮中被淹没。
在推荐领域,即使是比较资深的专家,也很难指出在某个任务设定下 SOTA 模型到底是哪一个。或许你会觉得这有什么难的,直接将新论文同一个 baseline 相对提升的幅度做比较不就可以了?
这就引出来了第二个问题,比较后会发现一个诡异的现象,同一组的 baseline 在不同的论文中相对的优劣是不一样的。虽然有时候审稿人会指出这些问题,但是在很多已发表的论文中也能观察到这样的现象,虽然数据集在其中造成了一定的影响,但是我觉得很大程度上还是因为没有把参数调好。
现在很多研发者不会下功夫对 baseline 做调整,调出一个差不多的结果后就做罢了。但这样的后果是,如果想比较两个自身达到了 SOTA 性能的模型,其相对提升就不会有特别明显的可比性,可能其中一个 baseline 调的非常好,另外一个则没有。这时就很难比较到底哪个模型在整个领域上达到了一个更优的效果。
那么,将在同一个数据集上进行过实验的模型拿来比较效果不就行了吗?这就引出了第三个问题:很多论文即使是在同一个数据集上,实验结果也不太有可比性。其中的原因有很多,我们来看几个比较有代表性的例子:
1. 推荐领域比较常见的数据预处理,是否去除了那些交互数量比较少的用户item(常见去掉小于等于5的)?
2. 是否去掉了比较 popular 的 item ?
3. 在数据划分时,直接用 leave-one-out 的方法把每个用户的最后一个序列作为测试集,还是为了防止时间泄露,设置一个时间来做一刀切来做数据集?
4. 在负例选取上是直接选用户没有交互过的作为负例,还是选择一个按照 item popular 的程度进行加权的负例采样?
上述例子看起来都是一些细节的设定,可能并不会非常明确的在论文中体现,但它们对模型的效果却有很大的影响。在同一个数据集上,两篇论文的实验结果可能会因为这些细节设定的差别存在跨数量级的差别。
最近 RecSys 的一篇论文 Are we really making much progress? A worrying analysis of recent neural recommendation approaches 也讲了这个问题。在推荐系统中,实验设定有很多具有分歧的地方,在这篇论文中就总结了多达8个分歧点,看起来不多,但假如说每一个分歧点至少有两种选择,2的8次方就是256种实验组合。
虽然实际中可能并不会这么多,常见的情况可能接近10种。这依然意味着很难保证想比较的两篇论文采取了完全一样的实验设定,也就导致即使两篇在同一个数据集上进行实验的论文,它们的结果也无法做比较科学的比较。
可能你会产生新的疑问,现在代码不都开源吗?我直接将代码在我的实验设定下跑一跑就可以了。我们来看看会发生什么:假设你准备下周一跟导师开组会汇报,你和导师说这周要把一个开源的 baseline 在自己的实验设定下跑一跑结果。周二你下载了代码,但发现把它改到能在自己的实验设定下去跑是非常困难的。
这其实是现在比较常见的一个现象,按说代码开源要满足的最低要求是可以复现论文的结果,先不说有些开源代码连这个最低的要求都没有实现,即使是达到最低要求的代码可能也很难匹配你的实验设定。我遇到过一个最极端的例子,当时要去补充一个带商品关系的 baseline(具体的名字就不说了)。
拿到代码后首先发现这篇论文有两个数据集,但奇怪的是代码载入时好像只有一个数据集的相关的内容。再看模型就更奇怪了,这份商品关系的baseline带有一个知识图谱,其中所有关于商品关系的代码,都按商品关系的数量去写了多份,比如数据其实有两种关系,就需要把同样的代码段写两份,把变量名做一个像X1、X2这样的区分。
我当时非常震惊,第二个数据集怎么办?果然有其他人问了论文作者同样的问题,作者怎么回应呢?给了一个百度网盘的链接用来下载第二个数据集的代码,我下载后发现第二个数据集有3种关系,类似第一个数据集,作者又把所有跟这种商品关系相关的代码段写了3遍,所有的变量用X1、X2、X3来替代,这让我非常崩溃,我的数据集有十几种关系,如果像他这样写,就要写上一个几千行且bug非常多的程序。
其实整个开源领域的代码质量非常参差不齐。回到上文假设的场景,整整一周你都没有把开源的 baseline 在自己的实验设定下真正跑起来。但和跟老师汇报时,老师可能会质疑你这一周都干了啥?既然是开源代码,为什么一周连一个实验的结果都没跑出来,你到底有没有在做实验?你只能一肚子的委屈。
上面的这些问题,也是一、两年间我们在做推荐领域研究中观察到的。上图右边,去年 RecSys 上的 best paper 也讨论了这些问题,在推荐系统领域,我们是否在真正的 making progress ?作者选择了18篇推荐领域的论文,但他只成功复现了其中的7篇,这7篇中效果能超过优质传统模型的又少之又少。
在目前看来,推荐系统论文百花齐放的表象下,确实很有可能隐藏着一个长期的停滞不前,或至少是一个比较缓慢的前行实际情况。

ReChorus推荐框架介绍

2.1 ReChorus推荐框架介绍
如何改善这样的状况呢?我们认为关键点在于是提供一个比较公平的 benchmark 评测平台,让不同的模型在同样的设定下进行评测。研究者可以直观、清晰地看到不同的模型之间的优劣关系。好比看家用显卡天梯图一样:我基于现在的预算,就知道我该选什么样的显卡。
类似的,有了评测平台提供的模型天梯图,研究者就能知道基于自己的实验设定,应该选择哪个 baseline 去作为我对比的目标、超越的对象,同时也可以帮助初学者更快地了解常见推荐算法。
我们基于上述的想法,同时在整理这次 SIGIR 一篇论文的代码时,就思考如何做成更通用的操作,可以推荐框架,促进领域中的模型来做公平的对比,从而构建一个真正的推荐算法“合唱团”,这也是框架名称 ReChorus 的由来。
在设计框架时,最主要的核心思想是如何分离模型间共同的实验设定到共享的类中,突出不同的模型的细节,从而让不同的模型可以在完全相同的实验设定下进行对比。另外我们希望框架具有以下四个特点:
轻量:易上手,代码self-contain;
高效:尽可能加速通用的训练和评测过程;
灵活:适配不同的数据输入格式和实验设定;
专注:实现新模型时只需要关注一个文件。
针对第4点再补充说明几句,为什么很多开源出来不是特别好的代码,都是一个文件把一个模型写完?因为这样的好处非常明显,使得研究者在调试时非常方便,只关注这一个文件,哪里有问题直接翻到那去找。
而一些框架会分很多很多类,非常面向对象。研究者可能写一个模型代码,在数据准备时要翻到前面去,看看所用的类如何适配自己的模型,这需要翻很多其他的文件,甚至还要对文件做改动,牵一发而动全身,研究者又要顾及改动会不会影响自己构建的其他模型,构建模型的思路就会被打乱。
我们希望实现把模型间不同的部分尽可能都集中到统一文件中去。

上图显示了已有的模型?目前实现的模型主要是基于 SIGIR 那篇论文的 baseline ,添加了一些常见的模型,还在继续扩充当中,上图的右面的二维码指向GitHub的链接,欢迎查看。
可以看到目前实现的模型包括从2009年比较经典的BPR,到后续的2016年、2017年、2018年、2019年、2020年的算法,既包括传统的模型,也有序列的模型,同时结合知识图谱、结合时间信息的也有了一些实践,性能的对比、各自的特点和运行时间列在了上图右侧。后文还会再讲这个结果,这里先不做详细分析。
2.2 框架主体
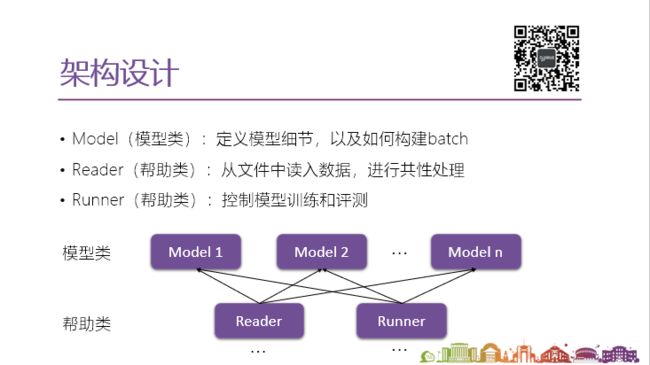
如上图,首先把框架分成了两个类型的类,核心的模型类和帮助类。核心的模型类以 model 结尾,主要用来定义模型的细节,也就是体现模型之间差异化的内容,以及如何构建输入的batch,这些都放在同一个文件里面,而且并不长。
帮助类分reader 和 runner 。reader 从硬盘中读取文件、数据集放到内存里,然后进行统一的预处理。runner 控制模型训练和评测的过程,会和所用到的深度学习框架训练和评测的代码有关,这里是基于pytorch的一个实现。
从上图可以看出,模型可以共享帮助类。虽然目前帮助类只实现了两个(base reader 和 base runner),如果我们的实验有变化,比如数据集的格式有变化,我们可以实现新的 reader,也可以用其他的 runner 来实现不同的评测的机制。这些 reader 和 runner 帮助类都是可以指定给每个模型,有点像 OOP 里面的设计模式,这些就像它的“厨师”,可以把它指定给每一个模型,实现灵活的适配。
接下来带大家从代码的层面梳理一遍 ReChorus 框架。
文件夹层面大概分data、log和src,log包含输出的log文件,src包含主要的模型代码。下面快速看一下data中的内容,数据集大概长什么样。

上面的代码非常简单,包含四个文件,其中train、test和dev 这三个文件比较重要,关键数值是user ID、item ID,还有每个的时间戳。
对于测试集和验证集来说,测试的时候我们一般会 sample 一些负例,和正例组成 candidate set,然后把正例和负例一起做排序,看正例到底排在第几位,所以train、test和dev这三个文件是必须的。后面选择性的提供 item 的、特征知识图谱的一些信息。r_complement 部分代表第一个item跟这一类item有互补的关系。
r_complement 部分代表第一个item跟这一类item有互补的关系。到这个 src 中的代码层面。主要分为三部分,一个是前文说的帮助类,实现了 base reader 和 base runner,第二部分 models 层面除了 base model 是一个基本的类以外,可以理解为一个抽象类,后面对于每个模型实现一个类,继承这个 base model 来实现它具体的功能。第三部分 util 层面是一些工具性的函数。函数主要入口在main,从main开始来看一下完整的框架。
# -*- coding: UTF-8 -*-
import os
import sys
import pickle
import logging
import argparse
import numpy as np
import torch
from models import *
from helpers import *
from utils import utils
def parse_global_args(parser):
parser.add_argument('--gpu', type=str, default='0',
help='Set CUDA_VISIBLE_DEVICES')
parser.add_argument('--verbose', type=int, default=logging.INFO,
help='Logging Level, 0, 10, ..., 50')
parser.add_argument('--log_file', type=str, default='',
help='Logging file path')
parser.add_argument('--random_seed', type=int, default=2019,
help='Random seed of numpy and pytorch.')
parser.add_argument('--load', type=int, default=0,
help='Whether load model and continue to train')
parser.add_argument('--train', type=int, default=1,
help='To train the model or not.')
parser.add_argument('--regenerate', type=int, default=0,
help='Whether to regenerate intermediate files.')
return parser
def main():
logging.info('-' * 45 + ' BEGIN: ' + utils.get_time() + ' ' + '-' * 45)
exclude = ['check_epoch', 'log_file', 'model_path', 'path', 'pin_memory',
'regenerate', 'sep', 'train', 'verbose']
logging.info(utils.format_arg_str(args, exclude_lst=exclude))
# Random seed
np.random.seed(args.random_seed)
torch.manual_seed(args.random_seed)
torch.cuda.manual_seed(args.random_seed)
# GPU
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
logging.info("# cuda devices: {}".format(torch.cuda.device_count()))
# Read data
corpus_path = os.path.join(args.path, args.dataset, model_name.reader + '.pkl')
if not args.regenerate and os.path.exists(corpus_path):
logging.info('Load corpus from {}'.format(corpus_path))
corpus = pickle.load(open(corpus_path, 'rb'))
else:
corpus = reader_name(args)
logging.info('Save corpus to {}'.format(corpus_path))
pickle.dump(corpus, open(corpus_path, 'wb'))
# Define model
model = model_name(args, corpus)
logging.info(model)
model = model.double()
model.apply(model.init_weights)
model.actions_before_train()
if torch.cuda.device_count() > 0:
model = model.cuda()
# Run model
data_dict = dict()
for phase in ['train', 'dev', 'test']:
data_dict[phase] = model_name.Dataset(model, corpus, phase)
runner = runner_name(args)
logging.info('Test Before Training: ' + runner.print_res(model, data_dict['test']))
if args.load > 0:
model.load_model()
if args.train > 0:
runner.train(model, data_dict)
logging.info(os.linesep + 'Test After Training: ' + runner.print_res(model, data_dict['test']))
model.actions_after_train()
logging.info(os.linesep + '-' * 45 + ' END: ' + utils.get_time() + ' ' + '-' * 45)
首先定义了一些global的参数,主要控制整体的,比如 manual_seed的问题。主函数部分还包含一些比较通用的设置,像随机数参数(随机数的种子)、具体用哪一个GPU。我调用 reade r这个类去进行 corpus 的构建。
有一些预处理会比较花费时间,所以默认把读入数据进行存储,也可以修改比如 regenerate 这样的参数,让它实现每一次都进行一个重复的预处理。还可以定义 model,根据所定义的model的内容,来做初始化参数的操作以及决定是否输入到显卡中。
之后调用 runner 类对模型进行评测和训练。还定义了每个的 dataset ,也就是pytorch 面内置的 dataset 一个集成的类,可以看到我把 dataset 写到了 model 中作为一个内部类。
为什么不把准备batch写到reader里面去?基于前文说过的设计框架指导原则,就是要把模型间不同的地方都集中到一个文件里,其实准备batch不同模型往往非常不一样,所以我就把它集成到了模型这类里面去。runner 通过 runner.train 这行代码控制整个训练的过程,看一下训练结果这部分就结束了。以上,main主要就是把所有的部分串联起来。
class BaseReader(object):
@staticmethod
def parse_data_args(parser):
parser.add_argument('--path', type=str, default='../data/',
help='Input data dir.')
parser.add_argument('--dataset', type=str, default='Grocery_and_Gourmet_Food',
help='Choose a dataset.')
parser.add_argument('--sep', type=str, default='\t',
help='sep of csv file.')
parser.add_argument('--history_max', type=int, default=20,
help='Maximum length of history.')
return parser
def __init__(self, args):
self.sep = args.sep
self.prefix = args.path
self.dataset = args.dataset
self.history_max = args.history_max
t0 = time.time()
self._read_data()
self._append_info()
logging.info('Done! [{:<.2f} s]'.format(time.time() - t0) + os.linesep)
def _read_data(self):
logging.info('Reading data from \"{}\", dataset = \"{}\" '.format(self.prefix, self.dataset))
self.data_df, self.item_meta_df = dict(), pd.DataFrame()
self._read_preprocessed_df()
logging.info('Formating data type...')
for df in list(self.data_df.values()) + [self.item_meta_df]:
for col in df.columns:
df[col] = df[col].apply(lambda x: eval(str(x)))
logging.info('Constructing relation triplets...')
self.triplet_set = set()
relation_types = [r for r in self.item_meta_df.columns if r.startswith('r_')]
heads, relations, tails = [], [], []
for idx in range(len(self.item_meta_df)):
head_item = self.item_meta_df['item_id'][idx]
for r_idx, r in enumerate(relation_types):
for tail_item in self.item_meta_df[r][idx]:
heads.append(head_item)
relations.append(r_idx + 1)
tails.append(tail_item)
self.triplet_set.add((head_item, r_idx + 1, tail_item))
self.relation_df = pd.DataFrame()
self.relation_df['head'] = heads
self.relation_df['relation'] = relations
self.relation_df['tail'] = tails
logging.info('Counting dataset statistics...')
self.all_df = pd.concat([self.data_df[key][['user_id', 'item_id', 'time']] for key in ['train', 'dev', 'test']])
self.n_users, self.n_items = self.all_df['user_id'].max() + 1, self.all_df['item_id'].max() + 1
self.n_relations = self.relation_df['relation'].max() + 1
logging.info('"# user": {}, "# item": {}, "# entry": {}'.format(self.n_users, self.n_items, len(self.all_df)))
logging.info('"# relation": {}, "# triplet": {}'.format(self.n_relations, len(self.relation_df)))
def _append_info(self):
"""
Add history info to data_df: item_his, time_his, his_length
! Need data_df to be sorted by time in ascending order
:return:
"""
logging.info('Adding history info...')
user_his_dict = dict() # store the already seen sequence of each user
for key in ['train', 'dev', 'test']:
df = self.data_df[key]
i_history, t_history = [], []
for uid, iid, t in zip(df['user_id'], df['item_id'], df['time']):
if uid not in user_his_dict:
user_his_dict[uid] = []
i_history.append([x[0] for x in user_his_dict[uid]])
t_history.append([x[1] for x in user_his_dict[uid]])
user_his_dict[uid].append((iid, t))
df['item_his'] = i_history
df['time_his'] = t_history
if self.history_max > 0:
df['item_his'] = df['item_his'].apply(lambda x: x[-self.history_max:])
df['time_his'] = df['time_his'].apply(lambda x: x[-self.history_max:])
df['his_length'] = df['item_his'].apply(lambda x: len(x))
self.user_clicked_set = dict()
for uid in user_his_dict:
self.user_clicked_set[uid] = set([x[0] for x in user_his_dict[uid]])
def _read_preprocessed_df(self):
for key in ['train', 'dev', 'test']:
self.data_df[key] = pd.read_csv(os.path.join(self.prefix, self.dataset, key + '.csv'), sep=self.sep)
item_meta_path = os.path.join(self.prefix, self.dataset, 'item_meta.csv')
if os.path.exists(item_meta_path):
self.item_meta_df = pd.read_csv(item_meta_path, sep=self.sep)
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
parser = argparse.ArgumentParser()
parser = BaseReader.parse_data_args(parser)
args, extras = parser.parse_known_args()
args.path = '../../data/'
corpus = BaseReader(args)
corpus_path = os.path.join(args.path, args.dataset, 'Corpus.pkl')
logging.info('Save corpus to {}'.format(corpus_path))
pickle.dump(corpus, open(corpus_path, 'wb'))
接着看上面 base reader 的代码,先看如何把数据集加载到内存里,其中两个函数 read_data 和 append_info。read_data 把数据读到内存中,转成 dataframe 的形式,可能会去根据 item_meta_data 构建三元组的形式,也会做整个数据集的统计特征。
appen_info 主要做统一的、之后模型可能都会用到的预处理。具体工作主要包括把item交互的历史拼到对应的dataframe里面去,tradeoff 整个的训练过程非常快,不过可能比较占内存,对于更大一点数据集可以考虑把它放到 dataset 里面在多线程准备的时动态的找对应的这个历史。
补充一点说明,需要把数据一次性读到内存里面去吗?确实是,推荐领域中,至少在研究中很少很少像 CV 领域,可能因为图片都比较大,无法一次全部装载到内存里。在推荐领域,如上文展示的那种数据集的格式,主要是 ID 和一些特征,直接讲 CSV 装载到内存还是比较方便的。
如果整个数据集比较大,无法预先的把历史和一些特征先准备好的话,可以之后写在 batch 里做动态的准备,牺牲一点时间来减少内存的使用。
总结base reader 这部分就是讲数据读到 dataframe 里,做一个统一的预处理。
class BaseRunner(object):
@staticmethod
def parse_runner_args(parser):
parser.add_argument('--epoch', type=int, default=100,
help='Number of epochs.')
parser.add_argument('--check_epoch', type=int, default=1,
help='Check some tensors every check_epoch.')
parser.add_argument('--early_stop', type=int, default=5,
help='The number of epochs when dev results drop continuously.')
parser.add_argument('--lr', type=float, default=1e-3,
help='Learning rate.')
parser.add_argument('--l2', type=float, default=0,
help='Weight decay in optimizer.')
parser.add_argument('--batch_size', type=int, default=256,
help='Batch size during training.')
parser.add_argument('--eval_batch_size', type=int, default=256,
help='Batch size during testing.')
parser.add_argument('--optimizer', type=str, default='Adam',
help='optimizer: GD, Adam, Adagrad, Adadelta')
parser.add_argument('--num_workers', type=int, default=5,
help='Number of processors when prepare batches in DataLoader')
parser.add_argument('--pin_memory', type=int, default=1,
help='pin_memory in DataLoader')
parser.add_argument('--topk', type=str, default='[5,10]',
help='The number of items recommended to each user.')
parser.add_argument('--metric', type=str, default='["NDCG","HR"]',
help='metrics: NDCG, HR')
return parser
def __init__(self, args):
self.epoch = args.epoch
self.check_epoch = args.check_epoch
self.early_stop = args.early_stop
self.learning_rate = args.lr
self.batch_size = args.batch_size
self.eval_batch_size = args.eval_batch_size
self.l2 = args.l2
self.optimizer_name = args.optimizer
self.num_workers = args.num_workers
self.pin_memory = args.pin_memory
self.topk = eval(args.topk)
self.metrics = [m.strip().upper() for m in eval(args.metric)]
self.main_metric = '{}@{}'.format(self.metrics[0], self.topk[0]) # early stop based on main_metric
self.time = None # will store [start_time, last_step_time]
def _check_time(self, start=False):
if self.time is None or start:
self.time = [time()] * 2
return self.time[0]
tmp_time = self.time[1]
self.time[1] = time()
return self.time[1] - tmp_time
def _build_optimizer(self, model):
optimizer_name = self.optimizer_name.lower()
if optimizer_name == 'gd':
logging.info("Optimizer: GD")
optimizer = torch.optim.SGD(
model.customize_parameters(), lr=self.learning_rate, weight_decay=self.l2)
elif optimizer_name == 'adagrad':
logging.info("Optimizer: Adagrad")
optimizer = torch.optim.Adagrad(
model.customize_parameters(), lr=self.learning_rate, weight_decay=self.l2)
elif optimizer_name == 'adadelta':
logging.info("Optimizer: Adadelta")
optimizer = torch.optim.Adadelta(
model.customize_parameters(), lr=self.learning_rate, weight_decay=self.l2)
elif optimizer_name == 'adam':
logging.info("Optimizer: Adam")
optimizer = torch.optim.Adam(
model.customize_parameters(), lr=self.learning_rate, weight_decay=self.l2)
else:
raise ValueError("Unknown Optimizer: " + self.optimizer_name)
return optimizer
def train(self, model, data_dict):
main_metric_results, dev_results, test_results = list(), list(), list()
self._check_time(start=True)
try:
for epoch in range(self.epoch):
# Fit
self._check_time()
loss = self.fit(model, data_dict['train'], epoch=epoch + 1)
training_time = self._check_time()
# Observe selected tensors
if len(model.check_list) > 0 and self.check_epoch > 0 and epoch % self.check_epoch == 0:
utils.check(model.check_list)
# Record dev and test results
dev_result = self.evaluate(model, data_dict['dev'], self.topk[:1], self.metrics)
test_result = self.evaluate(model, data_dict['test'], self.topk[:1], self.metrics)
testing_time = self._check_time()
dev_results.append(dev_result)
test_results.append(test_result)
main_metric_results.append(dev_result[self.main_metric])
logging.info("Epoch {:<5} loss={:<.4f} [{:<.1f} s]\t dev=({}) test=({}) [{:<.1f} s] ".format(
epoch + 1, loss, training_time, utils.format_metric(dev_result),
utils.format_metric(test_result), testing_time))
# Save model and early stop
if max(main_metric_results) == main_metric_results[-1] or \
(hasattr(model, 'stage') and model.stage == 1):
model.save_model()
if self.early_stop and self.eval_termination(main_metric_results):
logging.info("Early stop at %d based on dev result." % (epoch + 1))
break
except KeyboardInterrupt:
logging.info("Early stop manually")
exit_here = input("Exit completely without evaluation? (y/n) (default n):")
if exit_here.lower().startswith('y'):
logging.info(os.linesep + '-' * 45 + ' END: ' + utils.get_time() + ' ' + '-' * 45)
exit(1)
# Find the best dev result across iterations
best_epoch = main_metric_results.index(max(main_metric_results))
logging.info(os.linesep + "Best Iter(dev)={:>5}\t dev=({}) test=({}) [{:<.1f} s] ".format(
best_epoch + 1, utils.format_metric(dev_results[best_epoch]),
utils.format_metric(test_results[best_epoch]), self.time[1] - self.time[0]))
model.load_model()
def fit(self, model, data, epoch=-1):
gc.collect()
torch.cuda.empty_cache()
if model.optimizer is None:
model.optimizer = self._build_optimizer(model)
data.negative_sampling() # must sample before multi thread start
model.train()
loss_lst = list()
dl = DataLoader(data, batch_size=self.batch_size, shuffle=True, num_workers=self.num_workers,
collate_fn=data.collate_batch, pin_memory=self.pin_memory)
for batch in tqdm(dl, leave=False, desc='Epoch {:<3}'.format(epoch), ncols=100, mininterval=1):
batch = utils.batch_to_gpu(batch)
model.optimizer.zero_grad()
prediction = model(batch)
loss = model.loss(prediction)
loss.backward()
model.optimizer.step()
loss_lst.append(loss.detach().cpu().data.numpy())
return np.mean(loss_lst)
def eval_termination(self, criterion):
if len(criterion) > 20 and utils.non_increasing(criterion[-self.early_stop:]):
return True
elif len(criterion) - criterion.index(max(criterion)) > 20:
return True
return False
def evaluate(self, model, data, topks, metrics):
"""
Evaluate the results for an input dataset.
:return: result dict (key: metric@k)
"""
predictions = self.predict(model, data)
return utils.evaluate_method(predictions, topks, metrics)
def predict(self, model, data):
"""
The returned prediction is a 2D-array, each row corresponds to all the candidates,
and the ground-truth item poses the first.
Example: ground-truth items: [1, 2], 2 negative items for each instance: [[3,4], [5,6]]
predictions order: [[1,3,4], [2,5,6]]
"""
model.eval()
predictions = list()
dl = DataLoader(data, batch_size=self.eval_batch_size, shuffle=False, num_workers=self.num_workers,
collate_fn=data.collate_batch, pin_memory=self.pin_memory)
for batch in tqdm(dl, leave=False, ncols=100, mininterval=1, desc='Predict'):
prediction = model(utils.batch_to_gpu(batch))
predictions.extend(prediction.cpu().data.numpy())
return np.array(predictions)
def print_res(self, model, data):
"""
Construct the final result string before/after training
:return: test result string
"""
result_dict = self.evaluate(model, data, self.topk, self.metrics)
res_str = '(' + utils.format_metric(result_dict) + ')'
return res_str
上面是是 base runner 部分,主要控制整个训练的流程和评测。通过设置参数控制整个训练的流程,如check time是一些工具性的函数,通过build_optimizer 去构建具体的优化器。
训练方面,可以看到主要调用的是 train 函数,去调用后面的fit的函数,对训练集做参数的更新,它主要解决验证集上的结果,在测试集上的结果进行一个输出,看是否在验证集上达到最好。达到最好的话需要 save model,是否满足 early_stop 的条件,如果满足就 break ,这里其实也检测了手动的 Ctrl C break ,可能训练到中间的某一个轮次觉得这个明显不会好,所以就先去掉。
去掉了之后,它会问你是否要真正退出,如果最后想要再评测一下看最后效果、最后的指标,可以不退出,如果连最后指标都不想看,可以完全退出。
最后训练完,我会找到在验证集上最优的一轮,去做模型的load ,方便后续进行测试。fit 这部分是刚才 train 中去调用的,代码都是 pytorch 用户非常熟悉的。
每一个 batch 参数的更新,前面是准备性工作,包括训练的时候因为是 top_k 的训练,应是一个 ranking loss ,会采样一些负例。这里还会定义 dataloader,dataloader 是 pytorch 内置的类,是 dataset 相应的那个类,它会返回一个迭代器,当你每次去迭代它的时候,它会多线程从 data 中去准备相应的 batch。
这个 batch 具体是什么样是要靠你在 dataset 类里面去设定的。它会根据参数的不同,是否 shuffle ,每次返回对应的batch,这就相当于是 for dataloader 得到对应的batch之后,让model 得到 batch prediction 的结果,进行参数的更新,以上就是fit 这部分代码所做的工作。
def eval_termination 开始这部分是之前调用的、判断是否 early_stop 的标准,evaluate 这部分这些比较简单,直接调用 prediction ,得到 predictions 之后,用到工具类中写到的评测函数去进行评测。这个评测其实也针对目前的 topk 实验设定进行了相应优化,会让整个算 NDCG、算 HR 都会非常快。
predict 与 fit 比较像,不需要进行参数的更新,也是定义相应的 dataloader ,每一个 batch 得到预测的结果即可,最后规范输出的 string 格式。
整个 baserunner 大概不到200行,整个核心框架不到800行,所以说这是一个非常容易上手的框架。上述很多是比较细节的信息,希望帮助新手能更快上手。
class BaseModel(torch.nn.Module):
reader = 'BaseReader'
runner = 'BaseRunner'
extra_log_args = []
@staticmethod
def parse_model_args(parser):
parser.add_argument('--model_path', type=str, default='',
help='Model save path.')
parser.add_argument('--num_neg', type=int, default=1,
help='The number of negative items during training.')
parser.add_argument('--dropout', type=float, default=0.2,
help='Dropout probability for each deep layer')
parser.add_argument('--buffer', type=int, default=1,
help='Whether to buffer feed dicts for dev/test')
return parser
@staticmethod
def init_weights(m):
if 'Linear' in str(type(m)):
torch.nn.init.normal_(m.weight, mean=0.0, std=0.01)
if m.bias is not None:
torch.nn.init.normal_(m.bias, mean=0.0, std=0.01)
elif 'Embedding' in str(type(m)):
torch.nn.init.normal_(m.weight, mean=0.0, std=0.01)
def __init__(self, args, corpus):
super(BaseModel, self).__init__()
self.model_path = args.model_path
self.num_neg = args.num_neg
self.dropout = args.dropout
self.buffer = args.buffer
self.item_num = corpus.n_items
self.optimizer = None
self.check_list = list() # observe tensors in check_list every check_epoch
self._define_params()
self.total_parameters = self.count_variables()
logging.info('#params: %d' % self.total_parameters)
"""
Methods must to override
"""
def _define_params(self):
self.item_bias = torch.nn.Embedding(self.item_num, 1)
def forward(self, feed_dict):
"""
:param feed_dict: batch prepared in Dataset
:return: prediction with shape [batch_size, n_candidates]
"""
i_ids = feed_dict['item_id']
prediction = self.item_bias(i_ids)
return prediction.view(feed_dict['batch_size'], -1)
"""
Methods optional to override
"""
def loss(self, predictions):
"""
BPR ranking loss with optimization on multiple negative samples
@{Recurrent neural networks with top-k gains for session-based recommendations}
:param predictions: [batch_size, -1], the first column for positive, the rest for negative
:return:
"""
pos_pred, neg_pred = predictions[:, 0], predictions[:, 1:]
neg_softmax = (neg_pred - neg_pred.max()).softmax(dim=1)
neg_pred = (neg_pred * neg_softmax).sum(dim=1)
loss = F.softplus(-(pos_pred - neg_pred)).mean()
# ↑ For numerical stability, we use 'softplus(-x)' instead of '-log_sigmoid(x)'
return loss
def customize_parameters(self):
# customize optimizer settings for different parameters
weight_p, bias_p = [], []
for name, p in filter(lambda x: x[1].requires_grad, self.named_parameters()):
if 'bias' in name:
bias_p.append(p)
else:
weight_p.append(p)
optimize_dict = [{'params': weight_p}, {'params': bias_p, 'weight_decay': 0}]
return optimize_dict
"""
Auxiliary methods
"""
def save_model(self, model_path=None):
if model_path is None:
model_path = self.model_path
utils.check_dir(model_path)
torch.save(self.state_dict(), model_path)
logging.info('Save model to ' + model_path[:50] + '...')
def load_model(self, model_path=None):
if model_path is None:
model_path = self.model_path
self.load_state_dict(torch.load(model_path))
logging.info('Load model from ' + model_path)
def count_variables(self):
total_parameters = sum(p.numel() for p in self.parameters() if p.requires_grad)
return total_parameters
def actions_before_train(self):
pass
def actions_after_train(self):
pass
"""
Define dataset class for the model
"""
再来看最关键basemodel,这涉及到模型具体是怎么实现的。首先用静态变量的方式指定 reader 和 runner ,指定了它的帮助类是什么,具体用哪个 reader 去读数据,用哪个 runner 去训练和评测模型。
这里有一些通用的与模型相关的参数,可以增量的添加。前面是一些与模型相关的参数,包括定义模型里面具体有哪些可学习的参数,prediction 怎么去进行,loss 具体是什么,每个 customize parameters 应该是怎么样去设置。
后面有一些工具类的函数,再往后是上文提到的把 dataset 的类写成一个 model 的内部类,目的主要还是希望能在写模型的过程中,在一个文件里既准备对应的 batch,同时定义模型具体在前面怎么forward的。
因为在构建模型时,特别在研究过程中,经常需要变换输入的信息、输入的格式,在 forward 中来做相应的这种变换,如果经常需要换文件,或者改动调试,是比较痛苦的,所以考虑把它以内部类的形式呈现。
代码继承的 basedataset 其实是 pytorch 中内置的传给 dataloader 的 dataset ,只是把它改了一个名字,因为这个类本身也想要dataset。如果想用dataset,通过官方方式去使用它的话,一般需要去重写两个函数,一个是 len 函数,一个是 getitem 函数。len 函数完成的任务是获得 basedataset 中存的数据一共有多少个?getitem 是根据给定的 index ,去获得对应数据中的 index ,要输入给模型的 batch 。
如何实现这两个函数?这里面的data是什么?是basereader 读进来的dataframe ,但是这里为了方便,准备了多线程 batch(dataframe 对于多线程访问不太友好),所把它转成一个dict。
class Dataset(BaseDataset):
def __init__(self, model, corpus, phase):
self.model = model
self.corpus = corpus
self.phase = phase
self.data = utils.df_to_dict(corpus.data_df[phase])
# ↑ DataFrame is not compatible with multi-thread operations
self.neg_items = None if phase == 'train' else self.data['neg_items']
# ↑ Sample negative items before each epoch during training
self.buffer_dict = dict()
self.buffer = self.model.buffer and self.phase != 'train'
self._prepare()
def __len__(self):
for key in self.data:
return len(self.data[key])
def __getitem__(self, index):
return self.buffer_dict[index] if self.buffer else self._get_feed_dict(index)
# Prepare model-specific variables and buffer feed dicts
def _prepare(self):
if self.buffer:
for i in tqdm(range(len(self)), leave=False, ncols=100, mininterval=1,
desc=str('Prepare ' + self.phase)):
self.buffer_dict[i] = self._get_feed_dict(i)
# Key method to construct input data for a single instance
def _get_feed_dict(self, index):
target_item = self.data['item_id'][index]
neg_items = self.neg_items[index]
item_ids = np.concatenate([[target_item], neg_items])
feed_dict = {'item_id': item_ids}
return feed_dict
# Sample negative items for all the instances (called before each epoch)
def negative_sampling(self):
self.neg_items = np.random.randint(1, self.corpus.n_items, size=(len(self), self.model.num_neg))
for i, u in enumerate(self.data['user_id']):
user_clicked_set = self.corpus.user_clicked_set[u]
for j in range(self.model.num_neg):
while self.neg_items[i][j] in user_clicked_set:
self.neg_items[i][j] = np.random.randint(1, self.corpus.n_items)
# Collate a batch according to the list of feed dicts
def collate_batch(self, feed_dicts):
feed_dict = dict()
for key in feed_dicts[0]:
stack_val = np.array([d[key] for d in feed_dicts])
if stack_val.dtype == np.object: # inconsistent length (e.g. history)
feed_dict[key] = pad_sequence([torch.from_numpy(x) for x in stack_val], batch_first=True)
else:
feed_dict[key] = torch.from_numpy(stack_val)
feed_dict['batch_size'] = len(feed_dicts)
feed_dict['phase'] = self.phase
return feed_dict
上面的代码是我主要的 data ,确定phase具体在哪个阶段,是train 的阶段还是在评测 validation 、test 阶段。
len 部分直接获得了data的长度,被很多人吐槽,把data变成了一个dict的形式,它本身是一个data frame,每一列的长度是一样的,直接返回了第一列的长度。
getitem主要的功能放在 get_feed_dict 里面去完成。这是根据是否需要 buffer 去做选择。在数据集比较小的时候,如果条件允许的话,对于验证集跟测试集,完全可以把它所有的 batch 提前准备好放在内存里,这样训练、测试就会更快一些。如果不去 buffer 的话,每次现场做准备都要重复工作。
get_feed_dict 主要给index 返回对应的 predict ,也就是输入到模型的 batch 。base model 本来可能是抽象的,但还是把它写成可以运行的类。模型之后可以回返回来再看,根据给定的每一个 item ID ,去定义每个 item ID 对应的 bias ,然后直接把输出的 bias 作为预测的值。所以在这要为它准备 item ID ,target_item ID可以直接从data中item ID的类直接取出即可。
我们会提前准备好负例。训练集通过函数在每一轮之前进行采样。可以通过这一步从成员变量中直接获得对应的负例,并和target一起传到模型里,相当于返回了每一个index 对应的 free_dict 。而要传递模型的一个 batch 相当于一个群组,好多index 组成一个 batch ,也相当于一个 free_dict 的list 来组成一个 batch ,等于把相同的 key 当中的 value 组合到了一起。
注意看代码部分默认带有函数,由于后面可能涉及到不同的历史、长度,这里需要做动态的pad,这部分也重写了一些。当然,如果检测到序列的长度不一致,也会进行一个填充的操作,填充到同样的长度。也可以去添加一些整体上的控制变量。
以上这部分这是 dataset 比较重要的一部分,控制了怎么去给模型输入,包含了每个 batch 必须要有的内容。
可以再看看整体的模型, item_bias 部分对于我输入的 item_ID ,可以直接取对应的 bias 作为 prediction ,进而返回对应的 prediction 结果。
到这一部分,其实整个框架已经完成了对使用者的帮助工作。全部的代码量非常少,所以使用者可以很快上手。
2.3 实例演示
看完以上的引导,还是不知道怎么创建新模型怎么办?下面继续手把手教到底,通过一段视频教大家怎么基于框架在 5 分钟时间里实现一个 BPR。
看完快速上手视频,我们对整个框架做完了比较细致的梳理,希望能够帮助大家更好地上手、更好地使用它。

相关论文方法介绍
下面准备了一些相关具体算法的介绍,也是我们最近一项工作的介绍,可能比较偏模型、偏理论一些。

上图是我们现在所实现的模型的性能对比,可以看到,基于深度模型的NCF,如果在调参调得不好的情况下,比 BPR 还要差很多。引入了时间信息的 Tensor ,效果会有明显提升。对于序列的模型来说,因为有序列的信息效果是不错的。
我们逐一简单讲一讲:
1. SASRec 基于 self_attention,如果好好调参,效果确实会非常好。
2. TiSASRec是今年刚提出来的,把时间间隔用embedding的方式去融入到self_attention,也能取得稍微更好一点点的结果,但它的运行时间就会多很多。
3. CFKG 则是一个融入知识图谱的推荐,效果也是很不错的。
4. 最后两个模型,是把知识图谱、时间相关,还有序列的信息都用进来,也获得非常好的结果。
接着介绍一下,这里面表现最好的模型,大概是一个什么样的结构。

这是我们团队在SIGIR的论文:Make It a Chorus:Knowledge-and Time-aware Item Modeling for Sequential Recommendation。

首先是motivation,做这项工作的目的在于,我们感觉现在的推荐系统有很多问题。举个例子,我刚买完手机,你认为我会很喜欢电子产品,所以就会推荐很多款手机,但其实我此时已经不需要了。
如果比较智能的算法,可能会去推荐Air Pods,作为配件而言,我对它的需求可能会提升。但是这样的智能可能还是不够,如果我已经在其他平台上买过无线耳机,我现在也就不需要无线耳机,系统可能觉得我需要,但是我实际不需要。我刚开始可能觉得系统挺智能的,但是如果一直去推Air Pods,我会觉得很蠢。
不同的推荐应该会随着时间有一定的衰减,所以这篇文章所提出来的主要想法,就是每一个item可能在不同的context下,在不同的时间下,扮演不同的角色。


还有一些具体的例子,如果我之前买的是iphone,它对于目标商品Air Pods有没有互补的关系?它对我购买Air Pods影响应该短期内是正的,但会随时间慢慢递减的影响。而如果我之前买的商品是Air Pods同类商品,是替代品Powerbeats,那么短期内应该是有负向的影响,但是随着时间的增长,可能到该换耳机的时候,反而会得到正向的影响,是分配时间和负向变化正向的这样的一个过程。

具体怎么去设计这个模型?我们想让模型在item扮演不同角色的时候,有不一样的静态表示,比如在context下扮演互补品、替代品的时候是怎样的角色。然后根据序列的情况,把这些静态的表示,与现在有没有在扮演这个角色进行动态结合,包括之间间隔的时间,每一个扮演的角色有可能有正向、负向影响或者不起作用。例如给AirPods一个基本的表示,还有作为互补品的表示,作为替代品的表示,在不同context下就会都会起到更多的作用,下图是具体的模型图。


上图左边部分,进行了知识图谱嵌入,但这其实并不是工作重点,所以我们用了一个比较常见的关系建模,对商品之间的关系进行向量的切入,这些向量也会作为每个商品的基本表示进行数据化。
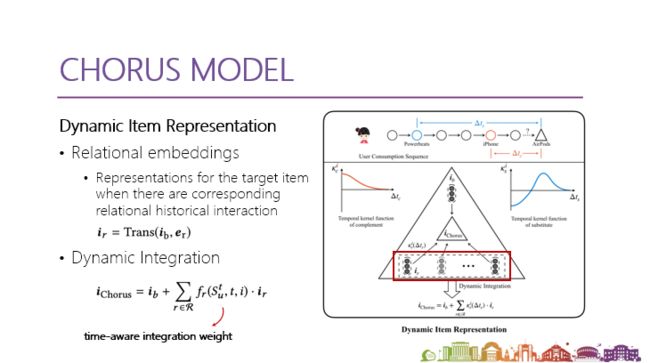

上图右半部分是第二个阶段,基于左边的表示,即对每个商品有很基本的表示,我们还希望得到它跟relation相关的表示,通过这样的translation,在第一个阶段里面使用的translation方式,去得到扮演不同角色时的静态表示,这样对于每一个商品,都有了基本表示和扮演不同角色时的表示。
这时候,就需要根据 context 去对它们做动态加和,用到叫做 time_aware integration weight 的方法,它是怎么设计的呢?就是去挑选历史里面跟目标商品有关系的历史交互,看它们对我的影响到底是什么,这个具体的影响有一个称为temporal kernel function 设计的函数去控制,是一个叠加的效应。
temporal kernel function 的方式怎么设计?其实会根据先验知识,或者是希望这个系统展现出来一个什么样的效果去设计,比如对于互补品设计成递减,对于替代品则是从负向到正向的变化,这样能控制扮演不同角色时的静态 embedding 在整个动态的结合过程中所做的贡献。

基于这样动态表示,就等于得到了一个目标商品在目前context下的动态表示,这个表示可以用到很多基于embedding模型里面,比如像BPR、GMF最后会统一去ranking loss。

上图是大概数据的信息,和刚才所提到的两种关系。

上图是实验结果,大致情况是我们的模型能够比之前所提到的引入知识、引入时间动态性的模型有比较明显的提升。
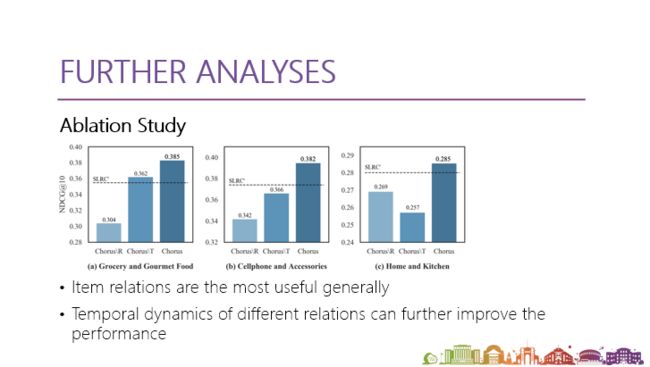
上图是 relation 的分析,图中的\R跟\T分别是去掉第一阶段的 knowledge graph 和第二阶段的 temporal kernel function ,不考虑时间动态变化的影响。可以看到,影响最大的还是商品关系所带来的,但是有时候商品关系可能处理得不好,这个时候动态结果就起到很大作用,如果不对不同的关系做时间动态变化的结合,\T会带来非常严重的损失,所以时间在所有数据上也有比较一致的提升。

最后,有趣的是,我们看了不同类型商品所求出的 temporal kernel function 方式长什么样?是否反映该类商品的一些特征?
上图左边是互补品求出来的 temporal kernel function ,它相较于可替代商品,下降曲线会更缓一些。这说明什么?说明可能用户过了一段时间之后,还会对这种可替代商品,比如替换的电池和之前老的智能手机还有兴趣,有可能过很长时间才会换。
而对于头戴式耳机来说,interest 下降就会非常快。就像上文提到的,有可能这个耳机我就不需要了,所以这个分数很快降下来,而不会过多打扰到用户。
上图右边是替代品的 temporal kernel function 方式写出来的结果。对于像手机壳这一类商品,它的负向影响基本上被削平了,主要是正向的影响,使得它的峰值会不太一样。这说明了,之前购买手机壳的行为对于购买下一个手机壳,其实没有很多负向影响。用户可能因为很多原因去换手机壳,比如摔坏了一个角,或者只是看到外观就换了,所以负向影响非常少。
而对于充电器、手机,它的负向影响和正向影响都非常明显。比较奇妙的是,两者峰值大概都处于一个位置,这其实也说明它俩是有一定依赖关系,因为可能不同的类型的手机配不同类型的充电头,反映了商品内部的这种关联。

这个模型在我们现在的框架中表现也是比较突出的。总结来说,这种模型主要提出了对于目标商品的动态表示,能够比较方便运用到各种基于 embedding 的方法中,并且进一步提升模型的性能等。

总结

最后做个总结,我们介绍 ReChorus 这种 top k 推荐框架,它目前会比较适合两类人群:作为初学者,可能想要了解一些经典推荐系统相关的算法,可以通过它去快速了解经典算法具体是怎么实现的;对于研究者来说,也可用它来测试一些新的idea,比较模型的性能。
但现在我觉得 ReChorus 还有很多的问题,包括只有一个内置数据集去比较,可能某些实验设定上还需要进一步提炼,比如最近一篇 ACL best paper 提出的思路,用类似软工的形式进行NLP的全面评测。不知道之后推荐系统方向是否会有相应的内容。
ReChorus 未来存在很多可以改善的空间,也非常欢迎广大同行研究者们提交 issue 来完善这个框架,共同构建真正的推荐算法的“合唱团”,不仅仅实现表面上的百花齐放(大量论文的涌现),也去真正推动这个领域一步一个脚印、实打实地进步。
关于数据实战派
数据实战派希望用真实数据和行业实战案例,帮助读者提升业务能力,共建有趣的大数据社区。

更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

