基于session推荐的论文阅读

今天我们要看一下如下三篇论文:
- SR-GNN: Session-Based Recommendation with Graph Neural Networks
- TA-GNN: Target Attentive Graph Neural Networks for Session-based Recommendation
- GC-SAN: Graph Contextualized Self-Attention Network for Session-based Recommendation
SR-GNN

论文链接: https://arxiv.org/abs/1811.00855
模型结构:
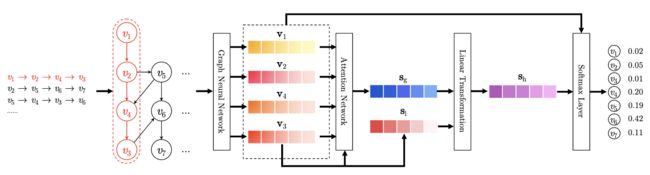
本文主要采用了一种基于门控更新的图神经网络进行节点的表示学习,然后再通过节点的表征信息进行推荐商品的预测。
这里的图,会针对每一个session的item序列构建一个图。具体构图的方式为:

根据出度和入度。上图右边的方框可以看成两部分,左半边为入度的统计,右半边为出度的统计。如: v 1 v_1 v1到 v 2 v_2 v2有一条边,所以左半边的一行二列处标记为1,其他类似。这里二行三列之所以是1/2,是因为 v 2 v_2 v2即连接了 v 3 v_3 v3也连接了 v 4 v_4 v4,所以折半。也就是按行进行归一化。
接下来,通过代码了解一下门控图网络一步的更新:
import torch
def GNNCell(A, hidden):
# A为构建的图矩阵
# hidden当前每个节点的表示
# print(A.size()) # torch.Size([128, 15, 30]) # 这里30就很容易理解了,因为前面是15 所有构建的图矩阵基于出度和入度考虑,就变成了30
# print(hidden.size()) # torch.Size([128, 15, 100])
# 首先将当前每个节点的表示进行一个线性映射
# 然后取出基于入度 信息聚合的表示
input_in = torch.matmul(A[:, :, :A.shape[1]], self.linear_edge_in(hidden)) + self.b_iah
# print(input_in.size()) # torch.Size([128, 15, 100])
# 接着取出基于出度 信息聚合的表示
input_out = torch.matmul(A[:, :, A.shape[1]: 2 * A.shape[1]], self.linear_edge_out(hidden)) + self.b_oah
# print(input_out.size()) # torch.Size([128, 15, 100])
# 将入度和出度聚合的信息进行拼接
inputs = torch.cat([input_in, input_out], 2)
# print(inputs.size()) # batch_size, max_len, 2 * hidden_size
# 将更新后每个节点的信息 通过线性层 映射到原来hidden_size的三倍
gi = F.linear(inputs, self.w_ih, self.b_ih) # 更新后各节点的表示
# 将上一步每个节点的信息 通过线性层 映射到原来hidden_size的三倍
gh = F.linear(hidden, self.w_hh, self.b_hh) # 更新前各节点的表示
# print(gi.size()) # batch_size, max_len, 3 * hidden_size torch.Size([128, 15, 300])
# print(gh.size()) # batch_size, max_len, 3 * hidden_size torch.Size([128, 15, 300])
# 接着沿第二个维度 将上面两种信息 分块
i_r, i_i, i_n = gi.chunk(3, 2) # 此时每一块的维度为 torch.Size([128, 15, 100])
h_r, h_i, h_n = gh.chunk(3, 2) # 此时每一块的维度为 torch.Size([128, 15, 100])
# 开始进行更新
resetgate = torch.sigmoid(i_r + h_r) # 上一步信息和当前更新后节点信息加和 经过一个sigmid得到重置门 torch.Size([128, 15, 100])
inputgate = torch.sigmoid(i_i + h_i) # 上一步信息和当前更新后节点信息加和 经过一个sigmid得到输入门 torch.Size([128, 15, 100])
newgate = torch.tanh(i_n + resetgate * h_n) # 新的信息
hy = newgate + inputgate * (hidden - newgate) # 也就是选择性更新
# print(hy.size()) # torch.Size([3, 15, 100])
return hy
这个基于门控的图网络是由这篇论文《Gated Graph Sequence Neural Networks》。链接:https://arxiv.org/pdf/1511.05493.pdf
上述代码的描述,可以参考下面的公式理解(其实很简单,类似rnn那种门控的机制):

通过上述图的反复迭代,最后学习到了每个节点的表征,也就是每个items的表征向量。 接着SA-GNN网络将每个节点的表示通过一个注意力网络进行了聚合,得到全局兴趣的表征限量:
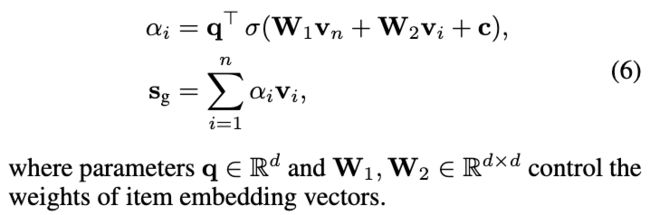
上式中 v n v_n vn为最后一步item的向量。
另外考虑了短期兴趣,即最后一步的item向量。将这两种向量拼接,然后去预测推荐商品:

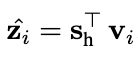

交叉熵损失:

实验结果:

TA-GNN

论文链接: https://arxiv.org/abs/2005.02844
模型结构:

TA-GNN复用SR-GNN网络中的GNN结构,学习每个节点的表征向量,创新点主要是提出了一种目标感知的注意力。
Constructing Target-Aware Embeddings
首先,对于一个session中的所有items,经过GNN,就会学习到一个表征。 假设对于整个数据集,总共去重后的item(也就是NLP中的词表)个数为vocab_size。
相当于拿着词表中每一个词 v i v_i vi都去和当前session的每一步输出进行注意力计算,得到权重因为α,然后将当前每一步的输出和其权重因子α进行加权和,得到当前词 v i v_i vi的感知表示。 那对词表中的所有词做这样的操作,最后得到词表中每个词的感知向量。维度为: (vocab_size, hidden_size),具体计算如下:


上式中 v t v_t vt为所有item(即词表中每一个词), v i v_i vi为当前session中的每个item。
此时要明白: s t a r g e t t s_{target}^{t} stargett维度应该是(batch_size, vocab_size, hidden_size)
Local embedding
局部embedding本文就是去的GNN输出session中最有一个item的向量。然后将这个向量重复vocab_size次,维度也就是(batch_size, vocab_size, hidden_size)
Global embedding

老套路了,就是将最有一步item的表征和前面每一步的表征做注意力计算,然后进行加权和。同理将最后的表征重复vocab_size次,最后维度变为:(batch_size, vocab_size, hidden_size)
predict
最后将这三者进行拼接:

其中 W 3 W_3 W3维度为: dx3d, 所以最后的 s t s_t st维度为: (batch_size, vocab_size, hidden_size)
接着和原始词表向量 v t v_t vt相乘:
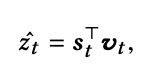
即: (batch_size, vocab_size, hidden_size) 和(vocab_size, hidden_size)矩阵乘。最后维度为: (batch_size, vocab_size),即预测出推荐的item的概率分布。
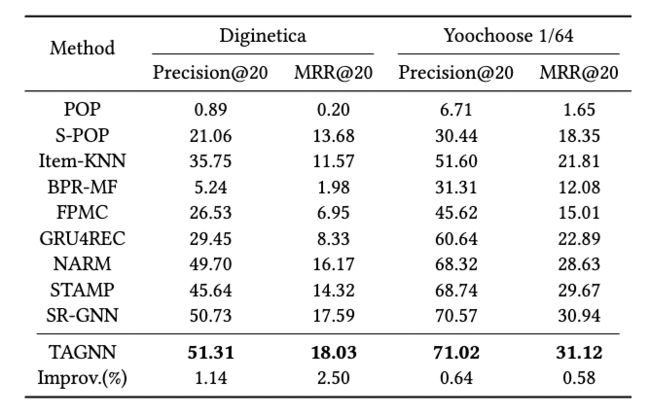
实验结果:
GC-SAN

论文链接: https://www.ijcai.org/proceedings/2019/0547.pdf
模型结构图:
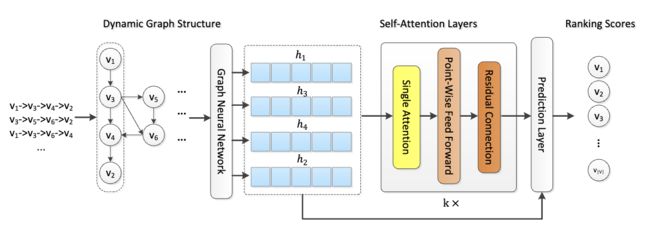
这篇论文很简单,前面部分也是复用SR-GNN学习表征,再将一个学习的表征经过一个self-attention中。然后将最后一个item在GNN中的表征向量,和self-attention交互完后的表征向量拼接起来,进行预测。
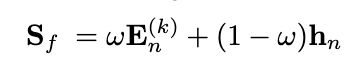
其中E为self-attention最后的输出, h n h_n hn为gnn最后的输出。 w为一个超参数,调整两个之间的权重。
最后预测,老套路了,就是复用embedding的参数,进行推荐商品的预测。
实验结果:

