图像检索:基于内容的图像检索技术
图像检索:基于内容的图像检索技术
- 1. 背景与意义
-
- **1.1 基于文本的图像检索方法:**
-
- 优点:
- 缺点:
- 1.2 基于内容的图像检索
-
- 原理:
- 优点:
- 缺点:
- 应用场景:
- 2. 基于内容的图像检索技术
-
- 2.1 相同物体图像检索
-
- 难点:
- 特征选取
- 编码 --> 全局描述
- 2.2 相同类别图像检索
-
- 相同类别图像检索面临的主要问题:
- 深度学习
- 2.3 大规模图像检索特点
-
- (1) 图像数据量大。
- (2) 特征维度高。
- (3) 要求响应速度快。
- 2.4 基于哈希的图像检索技术
-
- (1) 特征提取。
- (2) 哈希编码。
- (3) 汉明距离排序。
- (4) 重排。
- 3. 近似最近邻搜索
-
- 3.1 基于树的图像检索方法
- 3.2 基于哈希的图像检索方法
-
- 优点:
- 关键之处:
- 局部敏感哈希
- 3.3 向量量化
- 参考文献
1. 背景与意义
在Web2.0时代,尤其是随着Flickr、Facebook等社交网站的流行,图像、视频、音频、文本等异构数据每天都在以惊人的速度增长。例如, Facebook注册用户超过10亿,每月上传超过10亿的图片;Flickr图片社交网站2015年用户上传图片数目达7.28亿,平均每天用户上传约200万的图片;中国最大的电子商务系统淘宝网的后端系统上保存着286亿多张图片。针对这些包含丰富视觉信息的海量图片,如何在这些浩瀚的图像库中方便、快速、准确地查询并检索到用户所需的或感兴趣的图像,成为多媒体信息检索领域研究的热点。基于内容的图像检索方法充分发挥了计算机长于处理重复任务的优势,将人们从需要耗费大量人力、物力和财力的人工标注中解放出来。经过十来来的发展,基于内容的图像检索技术已广泛应用于搜索引擎、电子商务、医学、纺织业、皮革业等生活的方方面面。
图像检索按描述图像内容方式的不同可以分为两类,一类是基于文本的图像检索(TBIR, Text Based Image Retrieval),另一类是基于内容的图像检索(CBIR, Content Based Image Retrieval)。
1.1 基于文本的图像检索方法:
始于上世纪70年代,它利用文本标注的方式对图像中的内容进行描述,从而为每幅图像形成描述这幅图像内容的关键词,比如图像中的物体、场景等,这种方式可以是人工标注方式,也可以通过图像识别技术进行半自动标注。在进行检索时,用户可以根据自己的兴趣提供查询关键字,检索系统根据用户提供的查询关键字找出那些标注有该查询关键字对应的图片,最后将查询的结果返回给用户。
优点:
- 易于实现,
- 标注时有人工介入,所以其查准率也相对较高。在今天的一些中小规模图像搜索Web应用上仍有使用
缺点:
- 缺陷也是非常明显的:首先这种基于文本描述的方式需要人工介入标注过程,使得它只适用于小规模的图像数据,
- 在大规模图像数据上要完成这一过程需要耗费大量的人力与财力,而且随时不断外来的图像在入库时离不开人工的干预;
- 其次,”一图胜千言”,对于需要精确的查询,用户有时很难用简短的关键字来描述出自己真正想要获取的图像;
- 再次,人工标注过程不可避免的会受到标注者的认知水平、言语使用以及主观判断等的影响,因此会造成文字描述图片的差异。
1.2 基于内容的图像检索
随着图像数据快速增长,针对基于文本的图像检索方法日益凸现的问题,在1992年美国国家科学基金会就图像数据库管理系统新发展方向达成一致共识,即表示索引图像信息的最有效方式应该是基于图像内容自身的。自此,基于内容的图像检索技术便逐步建立起来,并在近十多年里得到了迅速的发展。
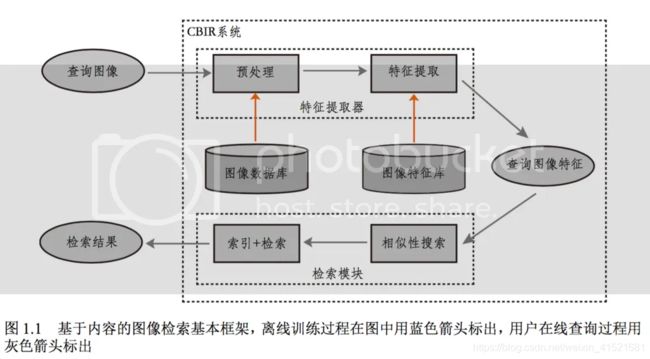
原理:
典型的基于内容的图像检索基本框架如上图1.1所示,它利用计算机对图像进行分析,建立图像特征矢量描述并存入图像特征库,当用户输入一张查询图像时,用相同的特征提取方法提取查询图像的特征得到查询向量,然后在某种相似性度量准则下计算查询向量到特征库中各个特征的相似性大小,最后按相似性大小进行排序并顺序输出对应的图片。
优点:
基于内容的图像检索技术将图像内容的表达和相似性度量交给计算机进行自动的处理,克服了采用文本进行图像检索所面临的缺陷,并且充分发挥了计算机长于计算的优势,大大提高了检索的效率,从而为海量图像库的检索开启了新的大门。
缺点:
不过,其缺点也是存在的,主要表现为特征描述与高层语义之间存在着难以填补的语义鸿沟,并且这种语义鸿沟是不可消除的。
应用场景:
基于内容的图像检索技术在电子商务、皮革布料、版权保护、医疗诊断、公共安全、街景地图等工业领域具有广阔的应用前景。
- 在电子商务方面,谷歌的Goggles、 阿里巴巴的拍立淘等闪拍购物应用允许用户抓拍上传至服务器端,在服务器端运行图片检索应用从而为用户找到相同或相似的衣服并提供购买店铺的链接;
- 在皮革纺织工业中,皮革布料生产商可以将样板拍成图片,当衣服制造商需要某种纹理的皮革布料时,可以检索库中是否存在相同或相似的皮革布料,使得皮革布料样本的管理更加便捷;
- 在版权保护方面,提供版权保护的服务商可以应用图像检索技术进行商标是否已经注册了的认证管理;
- 在医疗诊断方面,医生通过检索医学影像库找到多个病人的相似部位,从而可以协助医生做病情的诊断……
基于内容的图像检索技术已经深入到了许许多多的领域,为人们的生活生产提供了极大的便利。
2. 基于内容的图像检索技术
2.1 相同物体图像检索
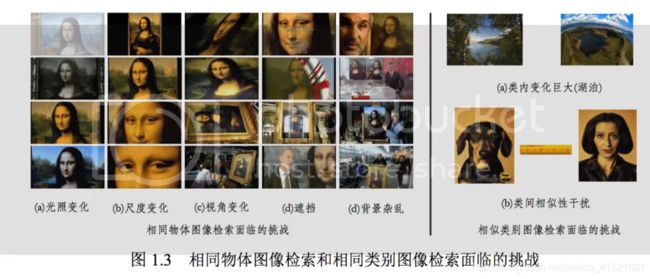
相同物体图像检索是指对查询图像中的某一物体,从图像库中找出包含有该物体的图像。这里用户感兴趣的是图像中包含的特定物体或目标,并且检索到的图片应该是包含有该物体的那些图片。如1.3图所示,给定一幅”蒙娜丽莎”的画像,相同物体检索的目标就是要从图像库中检索出那些包含有”蒙娜丽莎”人物的图片,在经过相似性度量排序后这些包含有”蒙娜丽莎”人物的图片尽可能的排在检索结果的前面。相似物体检索在英文文献中一般称为物体检索(Object Retrieval),**近似样本搜索或检测(Duplicate Search or Detection)**也可以归类于相同物体的检索,并且相同物体检索方法可以直接应用到近似样本搜索或检测上。相同物体检索不论是在研究还是在商业图像搜索产业中都具有重大的价值,比如购物应用中搜索衣服鞋子、人脸检索等。
难点:
对于相同物体图像检索,在检索相同的物体或目标时,易受拍摄环境的影响,比如:
- 光照变化、
- 尺度变化、
- 视角变化、
- 遮挡
- 背景的杂乱等
- 非刚性物体形变
图1.3左图给出了这几种变化的例子
特征选取
由于受环境干扰比较大,因而对于相同物体图像检索,在选取特征的时候,往往会选择那些抗干扰性比较好的不变性局部特征,比如SIFT1、SURF2、ORB3等,
编码 --> 全局描述
并以此为基础通过不同的编码方式构建图像的全局描述,具有代表性的工作有词袋模型(BoW, Bag of Words)、 局部特征聚合描述符(VLAD, Vector of Locally Aggregated Descriptors)以及Fisher向量(FV, Fisher Vector),
这一类以类SIFT为基础的图像检索方法, 由于结合了类SIFT不变性的特性,并且采用了由局部到全局的特征表达方式,并且在实际应用时在提取SIFT 的时候还可以使用siftGPU加速SIFT提取,因而从整体上来说能够获得比较好的检索效果,但这一类方法通常其特征维度往往是非常高的,如图1.2所示,在牛津建筑物图像数据库上采用词袋模型进行检索,为了获得较高的检索精度,在聚类时聚类数目一般都设置到了几十万,因而其最终表示的特征其维度高达几十万维,因此为它们设计高效的索引方式显得十分必要。
2.2 相同类别图像检索
对给定的查询图片,相似图像检索的目标是从图像库中查找出那些与给定查询图像属于同一类别的图像。这里用户感兴趣的是物体、场景的类别,即用户想要获取的是那些具有相同类别属性的物体或场景的图片。为了更好的区分相同物体检索和相同类别检索这两种检索方式区,仍以图1.3左图所举的”蒙娜丽莎”为例,用户如果感兴趣的就是”蒙娜丽莎”这幅画,那么检索系统此时工作的方式应该是以相同物体检索的方式进行检索,但如果用户感兴趣的并不是”蒙娜丽莎”这幅画本身,而是”画像”这一类图片,也就是说,用户所感兴趣的已经是对这幅具体的画进行了类别概念的抽象,那么此时检索系统应该以相同类别检索的方式进行检索。相同类别图像检索目前已广泛应用于图像搜索引擎,医学影像检索等领域。
相同类别图像检索面临的主要问题:
- 同一类别的图像类内变化巨大
如图1.3右图所示,对于”湖泊”这一类图像,属于该类别的图像在表现形式上存在很大的差异, - 而不同类的图像类间差异小
右图下面所示的”dog” 类和”woman”类两张图像,虽然它们属于不同的类,但如果采用低层的特征去描述,比如颜色、纹理以及形状等特征,其类间差异非常小,直接采用这些特征是很难将这两者分开的
因此相同类别图像检索在特征描述上存在着较大的类内变化和较小的类间差异等挑战。
深度学习
近年来,以深度学习(DL, Deep Learning)为主流的自动特征在应用到相同类别图像检索上时,能够极大的提高检索的精度,使得面向相同物体的检索在特征表达方面得到了较好的解决。
目前,以卷积神经网络(CNN, Convolutional Neural Network)为主导的特征表达方式也开始在相同物体图像检索上进行展开,并已有了一些相应的工作7,但由于相同物体在构造类样本训练数据时并不像相同类别图像检索那样那么方便,因而相同物体图像检索在CNN模型训练以及抽取自动特征等方面还有待深入。
不管是相同物体图像检索还是相同类别图像检索,在使用CNN模型提取自动特征的时候,最终得到的维度一般是4096维的特征,其维度还是比较高的,直接使用PCA等降维的手段,虽然能达到特征维度约减的目的,但在保持必要的检索精度前提下,能够降低的维度还是有限的,因而对于这一类图像检索,同样有必要为它构建够高效合理的快速检索机制,使其适应大规模或海量图像的检索。
2.3 大规模图像检索特点
无论是对于相同物体图像检索还是相同类别图像检索,在大规模图像数据集上,它们具有三个典型的主要特征:图像数据量大、特征维度高以及要求相应时间短。下面对这三个主要特征逐一展开说明:
(1) 图像数据量大。
得益于多媒体信息捕获、传输、存储的发展以及计算机运算速度的提升,基于内容的图像检索技术经过十几年的发展,其需要适用的图像规模范围也从原来的小型图像库扩大到大规模图像库甚至是海量图像数据集,比如在上世纪九十年代图像检索技术发展的早期阶段,研究者们在验证图像检索算法性能的时候,用得比较多是corel1k,该图像库共1000张图片,与今天同样可以用于图像检索的最流行的图像分类库imageNet数据集相比,其量级已经有了成千上万倍的增长,因而图像检索应满足大数据时代的要求,在大规模图像数据集上应该具备伸缩性。
(2) 特征维度高。
图像特征作为直接描述图像视觉内容的基石,其特征表达的好坏直接决定了在检索过程中可能达到的最高检索精度。如果前置特征未表达好,在构建后置检索模型的时候,不但会复杂化模型的构建,增加检索查询的响应时间,而且能够提升的检索精度也是极其有限的。所以在特征提取之初,应该有意识的选取那些比较高层特征。如果将局部特征表达方式也作为”高维”的一种,那么特征的描述能力跟特征的维度高低具有较大的关联,因而在特征描述方面大规模图像检索具有明显的特征维度高的特性,比如词袋模型BoW、VLAD、Fisher向量以及CNN特征。为了对这些高维的特征有一个维度量级的定量认识,本文以词袋模型构建的特征向量为例,在牛津大学建筑物图像数据集上试验了特征维度(在数值上跟聚类单词数目大小相等)对检索精度的影响,从图1.2中可以看到,词袋模型的特征维度是非常高的。因此,面向大规模图像数据集检索的另一个典型特点是图像特征描述向量维度高。
(3) 要求响应速度快。
对于用户的查询,图像检索系统应该具备迅速响应用户查询的能力,同时由于大规模图像数据量大、特征维度高,直接采用暴力搜索(Brute Search) 索引策略(也称为线性扫描)难以满足系统实时性的要求,图1.2右图所示的是在牛津大学建筑物图像数据集上平均每次查询所耗费的时间,可以看到在图像数量仅有4063张的牛津大学建筑物图像集,其查询时间在单词数目为100万且重排深度为1000的条件下就需要耗费1 秒左右的时间,并且整个程序还是运行在一台高配的服务器上,因此,大规模图像检索需要解决系统实时响应的问题。
2.4 基于哈希的图像检索技术
其具体框架如图1.4所示,按步骤可以分为特征提取、哈希编码、汉明距离排序以及重排四个步骤:

(1) 特征提取。
对图像数据库中的图像逐一进行特征提取,并将其以图像文件名和图像特征一一对应的方式添加到特征库中;
(2) 哈希编码。
哈希编码可以拆分成为两个子阶段,在对特征进行编码之前需要有哈希函数集,而哈希函数集则通过哈希函数学习阶段而得到,因此这两个子阶段分别为哈希函数学习阶段和正式的哈希编码阶段。
在哈希函数学习阶段,将特征库划分成训练集和测试集,在训练库上对构造的哈希函数集H(x)=h1(x),h2(x),…,hK(x) 进行训练学习;
正式的哈希编码阶段时,分别将原来的特征xi(i=1,2,…,N) 代入到学习得到的哈希函数集H(x) 中,从而得到相应的哈希编码。值得注意的是,如果设计的哈希算法已经经过实验验证有效,那么在实际的应用系统中,在划分数据集的时候,可以将整个图像库既作为训练集也作为图像数据库,从而使得在大规模图像上学到的哈希函数具备较好的适应性;
(3) 汉明距离排序。
在汉明距离排序阶段,对于给定的查询图像,逐一计算查询图像对应的哈希编码到其他各个哈希编码之间的汉明距离,然后按从小到大的顺序进行相似性排序,从而得到检索结果;
(4) 重排。
针对步骤(3)汉明排序后的结果,可以选择前M(M«N) 个结果或者对汉明距离小于某一设置的汉明距离dc 的结果进行重排。一般地,在重排的时候采用欧式距离作为相似性度量得到重排后的结果。因此,从这里可以看到,哈希过程可以看作是筛选候选样本或是粗排序的过程。在采用哈希方法进行大规模图像检索的应用系统中,通常会有重排这一步,但是在设计哈希算法的时候,对性能进行指标评价直接采用的是汉明距离,也就是在评价哈希算法性能的时候,不需要重排这一步。
随着视觉数据的快速增长,面向大规模视觉数据的基于内容的图像检索技术不论是在商业应用还是计算机视觉社区都受到了极大的关注。传统的暴力(brute-force) 搜索方法(又称线性扫描)通过逐个与数据库中的每个点进行相似性计算然后进行排序,这种简单粗暴的方式虽然很容易实现,但是会随着数据库的大小以及特征维度的增加其搜索代价也会逐步的增加,从而使得暴力搜索仅适用于数据量小的小规模图像数据库,在大规模图像库上这种暴力搜索的方式不仅消耗巨大的计算资源,而且单次查询的响应时间会随着数据样本的增加以及特征维度的增加而增加,为了降低搜索的空间的空间复杂度与时间复杂度,在过去的十几年里研究者们找到了一种可供替代的方案— 近似最近邻(ANN, Approximate Nearest Neighbor)搜索方法,并提出了很多高效的检索技术,其中最成功的方法包括基于树结构的图像检索方法、基于哈希的图像检索方法和基于向量量化的图像检索方法。
3. 近似最近邻搜索
基于树结构的最近邻搜索方法和基于哈希的最近邻搜索方法在理论计算机科学、机器学习以及计算机视觉中是一个很活跃的领域,这些方法通过将特征空间划分成很多小的单元,以此减少空间搜索的区域,从而达到次线性的计算复杂度。

3.1 基于树的图像检索方法
- 基于树的图像检索方法:
将图像对应的特征以树结构的方法组织起来,使得在检索的时候其计算复杂度降到关于图像库样本数目n的对数的复杂度。基于树结构的搜索方法有KD-树8、M-树9等。在众多的树结构搜索方法中,以KD-树应用得最为广泛,KD-树在构建树的阶段,不断以方差最大的维对空间进行划分,其储存对应的树结构则不断的向下生长,并将树结构保存在内存中,

如图2.1右图示例了一个简单的KD-树划分过程:在搜索阶段,查询数据从树根节点达到叶节点后,对叶节点下的数据与查询数据进行逐一比较以及回溯方式从而找到最近邻。
- 优点:
- 虽然基于树结构的检索技术大大缩减了单次检索的响应时间,
- 缺点:
- 但是对于高维特征比如维度为几百的时候,基于树结构的索引方法其在检索时候的性能会急剧的下降,甚至会下降到接近或低于暴力搜索的性能,如表2.1所示,在LabelMe数据集上对512维的GIST特征进行索引的时候,单次查询Spill树(KD-树的变形)耗时比暴力搜索用时还要多。
- 此外,基于树结构的检索方法在构建树结构的时候其占用的存储空间往往要比原来的数据大得多,并且对数据分布敏感,从而使得基于树结构的检索方法在大规模图像数据库上也会面临内存受限的问题。
3.2 基于哈希的图像检索方法
优点:
-
相比基于树结构的图像检索方法,基于哈希的图像检索方法由于能够将原特征编码成紧致的二值哈希码,使得基于哈希的图像检索方法能够大幅的降低内存的消耗,
-
计算汉明距离的时候可以使用计算机内部运算器具有的XOR异或运算,从而使的汉明距离的计算能够在微秒量级内完成,从而大大缩减了单次查询响应所需要的时间。
如表2.1所示,在LabelMe图像数据集上,相比于暴力搜索方法以及基于树结构的搜索方法,通过将图像的特征编码后进行搜索,在编码位数为30比特时基于哈希的搜索方法单次查询时间比暴力搜索以及基于树结构的方法降低了将近4个数量级,并且特征维度由原来的512维降低至30维,因而极大的提高了检索的效率。
关键之处:
设计一个有效的哈希函数集,使得原空间中的数据经过该哈希函数集映射后,在汉明空间其数据间的相似性能够得到较好的保持或增强。
难点:
- 由于未经编码的特征在数域上是连续的,而哈希编码得到的是一个二值哈希码,也就是说从数域上来讲哈希函数集是一个将数值从连续域变换到离散域的过程,因而会导致在优化哈希函数集时往往难于求解10,从而使得设计一个有效的哈希函数集极其不易。
进展:
- 在过去的十几年里,尽管设计有效的哈希函数集面临很大的挑战,但研究者们仍然提出了很多基于哈希的图像检索方法,其中最经典的哈希方法是局部敏感哈希方法11(LSH, Locality Sensitive Hashing)。
局部敏感哈希
局部敏感哈希被认为是高维空间(比如成百上千维)快速最近邻搜索的重要突破,它在构造哈希函数的时候采用随机超平面的方法,即使用随机超平面将空间分割成很多子区域,每一个子区域可以被视为一个”桶”,如图2.1右图所示。
在构建阶段,局部敏感哈希仅需要生成随机超平面,因而没有训练的过程;
在索引阶段,样本被映射成二进制哈希码,
如图2.1右图示意的二进制哈希码,具有相同的二进制哈希码的样本被保存在同一个“桶”中;在查询阶段,查询样本通过同样的映射后可以锁定查询样本位于哪个“桶”中,然后在锁定的”桶”中将查询样本与该“桶”中的样本进行逐一的比较,从而得到最终的近邻。
局部敏感哈希其有效性在理论分析中得到了保证,但是由于局部敏感哈希在构造哈希函数过程中并没有利用到数据本身,使得在应用局部敏感哈希时为了获得较高的精索精度常常采用很长的编码位,但在长编码位数下会降低相似样本在哈希离散过程中的碰撞概率,从而导致检索的召回率会出现比较大的下降,因此出现了多个哈希表的局部敏感哈希。
在相同的编码长度下,相比于只有一个哈希表的局部敏感哈希(即单哈希表局部敏感哈希),多哈希表局部敏感哈希中的每一个哈希表的编码长度减小为单哈希表局部敏感哈希编码长度的L 分之一倍(假设L 为多哈希表局部敏感哈希),因此多哈希表局部敏感哈希能够获得比具有相同编码长度的单哈希表局部敏感哈希更高的召回率,但无论是多哈希表局部敏感哈希还是单哈希表局部敏感哈希,它们的编码都不是紧致的,从而使得它们在内存使用效率方面并不是很有效。
3.3 向量量化
在面向大规模图像检索时,除了采用图像哈希方法外,还有另一类方法,即向量量化的方法,向量量化的方法中比较典型的代表是乘积量化(PQ, Product Quantization)方法,它将特征空间分解为多个低维子空间的笛卡尔乘积,然后单独地对每一个子空间进行量化。
在训练阶段,每一个子空间经过聚类后得到k个类心(即量化器),所有这些类心的笛卡尔乘积构成了一个对全空间的密集划分,并且能够保证量化误差比较小;
经过量化学习后,对于给定的查询样本,通过查表的方式可以计算出查询样本和库中样本的非对称距离12。
乘积量化方法虽然在近似样本间的距离时比较的精确,但是乘积量化方法的数据结构通常要比二值哈希码的复杂,它也不能够得到低维的特征表示,此外为了达到良好的性能必须加上不对称距离,并且它还需要每个维度的方差比较平衡,如果方差不平衡,乘积量化方法得到的结果很差。
参考文献
LOWE D G. Distinctive Image Features from Scale-Invariant Keypoints, Int. J. Comput. Vis., 2004, 60(2):91–110. ↩
BAY H, TUYTELAARS T, GOOL L J V. SURF: Speeded Up Robust Features, Proc. IEEE Int. Conf. Comput. Vis., 2006:404–417. ↩
RUBLEE E, RABAUD V, KONOLIGE K, et al. ORB: An Efficient Alternative to SIFT or SURF, Proc. IEEE Int. Conf. Comput. Vis., 2011:2564–2571. ↩
CSURKA G, DANCE C, FAN L, et al. Visual Categorization with Bags of Keypoints, Workshop on statistical learning in computer vision, Eur. Conf. Comput. Vis., 2004,1:1–2. ↩
JEGOU H, DOUZE M, SCHMID C, et al. Aggregating Local Descriptors into A Compact Image Representation, Proc. IEEE Int. Conf. Comput. Vis. Pattern Recognit., 2010:3304–3311. ↩
PERRONNIN F, SÁNCHEZ J, MENSINK T. Improving the Fisher Kernel for Large-Scale Image Classification, Proc. Eur. Conf. Comput. Vis., 2010:143–156. ↩
KIAPOUR M H, HAN X, LAZEBNIK S, et al. Where to Buy It: Matching Street Clothing Photos in Online Shops, Proc. IEEE Int. Conf. Comput. Vis., 2015:3343–3351. ↩
BENTLEY J L. Multidimensional Binary Search Trees Used for Associative Searching, Commun. ACM, 1975, 18(9):509–517. ↩
UHLMANN J K. Satisfying General Proximity/Similarity Queries with Metric Trees, Inf. Process. Lett., 1991, 40(4):175–179. ↩
GE T, HE K, SUN J. Graph Cuts for Supervised Binary Coding, Proc. Eur. Conf. Comput. Vis., 2014:250–264. ↩
DATAR M, IMMORLICA N, INDYK P, et al. Locality-Sensitive Hashing Scheme Based on p-stable Distributions, Proc. Symp. Comput. Geom., 2004:253–262. ↩
DONG W, CHARIKAR M, LI K. Asymmetric Distance Estimation with Sketches for Similarity Search in High-dimensional Spaces, Proc. ACM SIGIR Conf. Res. Develop. Inf. Retr., 2008:123–130. ↩
请我喝杯咖啡
←数据分类:特征处理Hive与SQL零碎知识汇总→
comments powered by Disqus
Friend: Lichao Tolias heyuhang yuanbin pluskid yihui VisualData GoogleAI
Made with Jekyll, hosted on Github Pages. Inspired by saunier, designed by Willard.
Attribution-NonCommercial-ShareAlike 4.0 International 2013-2020