Few-shot Object Detection via Feature Reweighting跑自己的数据集
Few-shot Object Detection via Feature Reweighting跑自己的数据集
- 说明
-
- 配置环境
说明
上篇文章记录了我配置环境的过程,现在看来感觉有点啰嗦,所以打算写一篇简洁的配置环境的流程,这篇文章是few-shot learning运用于目标检测的比较早的文章,最近貌似few-shot learning比较火,估计很多人都会以这篇文章作为切入点。
配置环境
很多人可能会用pycharm创建环境,但是在租用服务器的时候有时候没有图形界面,比较麻烦,所以我写一个黑框(终端)的比较通用(在pycharm的终端里也可以使用)的版本,步骤如下:
(1)基础电脑操作系统为ubantu(为了更好的操作,可以装个ubantu,变为双系统,如果条件允许,多分点内存给ubantu吧,不然后面内存不足太难受了),我目前只在ubantu上配通。另外还需要装个Anocaonda(去官网找对应ubantu的安装包),常用的版本就行。租用服务器的话一般都自带有Anocaonda。我常租用的服务器是 MistGPU,其他的没怎么用过。关于MistGPU的使用,我写了一个教程: MistGPU云服务器的使用.
(2)下载代码: 代码,并解压。
(3)cd进入到主目录下,或者在主目录下打开终端。
(4)创建虚拟环境:
conda create -n xxx python=2.7 # xxx为你设定的虚拟环境的名字,假设为few
会提示下载一些东西,输入y,摁Enter。
(5)激活虚拟环境
conda activate few
(6)执行requirements.txt
pip install -r requirements.txt
requirements.txt为代码运行需要的一些包。
如果显示requirements.txt中opencv版本不匹配,没有3.4.2,我修改equirements.txt中opencv版本为3.4.2.16后,再执行pip install -r requirements.txt,没有报错,就是看你的报错里显示支持哪个版本,选一个改一下再执行requirements.txt即可。
(7)执行requirements.txt成功后,配置pytorch和cuda,执行
pip install torch==1.4.0+cu92 torchvision==0.5.0+cu92 -f https://download.pytorch.org/whl/torch_stable.html
记得验证下cuda是否能用:import torch … 具体语句记不清了,网上都能查到的。
以上都没有报错的话,环境是没多大问题了。接下来就是准备数据集,具体可以看上一篇文章链接: Few-shot Object Detection via Feature Reweighting论文学习以及复现,可能遇到的问题啥的基本都记录了。后面有时间再写下如何准备数据集吧,特别是对于新的数据集怎么处理、怎们改使其符合代码需要的格式。
(8)数据集格式
将整个代码工程放在一个名为fewshot的文件夹下,在里面创建一个名为voc的文件夹存放数据集。整个框架如下:
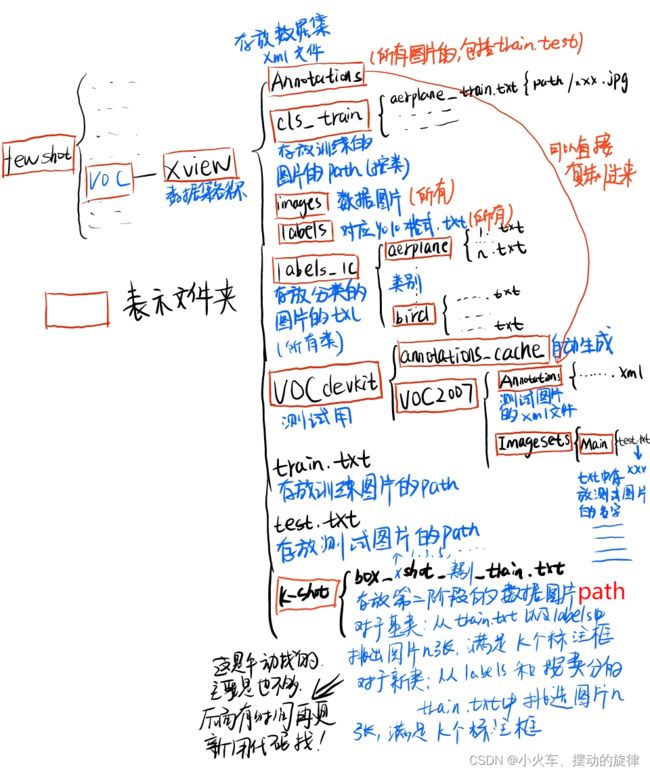
关于数据集类别的问题:
代码里有关于voc、coco数据集的代码,如果训练这些数据集的话,可以直接选对应的参数既可,数据集的准备过程按照作者给的步骤操作就行,假如训练新的数据集的话就可以用我的数据准备的方法,我也是模仿作者所给的步骤所得出的框架。
训练新的数据集,如果直接改类别,就要改一些代码,而且还可能报错,我尝试了一下,报错了,改起来貌似挺麻烦。其实可以这样,把自己的类别与代码里的类别对应即可,就是用代码里的类别代替自己数据的类别,自己注意对应关系即可,训练过程中使用的是class_id。
__C.voc_classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train", "tvmonitor"]
修改示例:
假如我有6个类,plane1、tank1、ship1、plane2、tank2、ship2,用voc class中的 [“aeroplane”, “bicycle”, “bird”, “boat”, “bottle”, “bus”]来表示即可(记得修改xml文件对应),并修改标签类别id分别为0、1、2、3、4、5、6(修改txt).
具体步骤:
(1).先把目标域和源域的数据集标签格式转为yolo格式:class_id x,y,w,h (网上代码很多)
(2).把目标域和源域的数据集合起来,images和labels放在一起,数据集按类分出来,得到label_1c对应的文件,代码如下:
txtpath = r"path/labels" // 定位到数据集标签所在的文件夹labels
txtnames = os.listdir(txtpath)
# 分类
for i in txtnames:
with open(txtpath + '/' + i, "r") as f:
l = []
file = f.readlines()
print(i)
# flag = 0
for line in file:
line = line.strip("\n")
dd = line.split()
if dd[0] == '2':
# flag = flag + 1
l.append(dd)
if len(l)>0:
with open(r"xxx\labels_1c/xx/" + i, 'w') as q: // xx为类别名称
for j in l:
tem =j[0]+" "+j[1]+" "+j[2]+" "+j[3]+" "+j[4]
q.write(tem+'\n')
(3)制作xml文件(所有图片的,如果自带xml文件,记得修改对应的类别,详见修改示例),也可以重新生成txt,txt文件转xml,代码如下:
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
"""
dic = {'0': "aeroplane", # 创建字典用来对类型进行转换
'1': "bicycle", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
'2': "bird",
'3': "boat",
'4': "cow",
'5': "bus",
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".tif")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".tif")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = r"D:\BaiduNetdiskDownload\fewshot\xView_split_clearE1\train\test_image/" # 图片所在文件夹路径,后面的/一定要带上
txtPath = r"D:\BaiduNetdiskDownload\fewshot\xView_split_clearE1\train\test_txt/" # txt所在文件夹路径,后面的/一定要带上
xmlPath = r"D:\BaiduNetdiskDownload\fewshot\xView_split_clearE1\train\1/" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
自己修改对应的路径即可。
(4)分训练数据trian.txt(只含有源域数据图片)和测试数据test.txt(源域、目标域)(测试数据,控制每个类的数量尽量均衡),分好后,获取训练数据图片的路径,制作train.txt,获取测试图片的路径,制作test.txt,代码如下:
# 统计每个类别数目
# cc = 0
# c1,c2,c3 = 0,0,0
# for i in range(len(txtnames)):
# cc =cc+1
# with open(txtpath + '/' + txtnames[i], "r") as f:
# file = f.readlines()
# print(file)
# for line in file:
# line = line.strip("\n")
# dd = line.split()
# if dd[0] == '0':
# c1 = c1+1
# elif dd[0] == '1':
# c2 = c2 + 1
# elif dd[0] == '2':
# c3 = c3 + 1
import os
p = r"xxx\testtxt"
paths = r"xxx\images"
f = open(r"xxx/"+'名字.txt', 'w')
filenames = os.listdir(p)
imanames = os.listdir(paths)
# filenames.sort()
for imaname in imanames:
tem = imaname.replace("tif","txt")
if tem not in filenames:
out_path = "xxx/images/" + imaname
# out_path = filename.replace(".txt","")
# if filename[0] == "P":
# out_path = "xxx/images/" + filename.replace(".txt",".png")
# else:
# out_path = "xxx/images/"+filename.replace(".txt", ".tif")
print(out_path)
f.write(out_path + '\n')
f.close()
代码不难,看懂改改就行。
(5)制作各类别的train.txt,即cls_train下的文件
代码思路:
(2)中得到了按类的所有图片(train、test)的txt,按类别(文件夹)读取类别对应的图片的文件名(replace替换,后缀得到图片名称.jpg/png…)假设为listA,然后获取test.txt中的图片名称,假设为listB,在A中去除B,然后路径+图片名称 保存为 类别_train.txt。(过程略有复杂…)
————————————
以上,第一阶段就可以训练了:
参数文件metayolo.data配置:
metayolo=1
metain_type=2
data=voc
neg = 1
rand = 0
novel = data/voc_novels.txt
novelid = 0
scale = 1
meta = data/voc_traindict_full.txt
train = path/train.txt
valid = path/test.txt
backup = backup/metayolo
gpus=1,2,3,4
其中:
data = voc 代表类别为voc类别,如果上面按照我所说的替换类别对应,这里就不用改(voc类别对应一些数据参数,如代码中的scale参数,暂时不考虑改,默认,在调参数阶段可以根据数据集进行调整)。
voc_novels.txt 为新类别名称 novelid = 0 为 新类别的位置,例如voc_novels.txt ,novelid = 1:
bird,bus,cow,motorbike,sofa
aeroplane,bottle,cow,horse,sofa
boat,cat,motorbike,sheep,sofa
bicycle,bird,motorbike,train,tvmonitor
aeroplane,bird,bus,cat,person
car,diningtable,motorbike,pottedplant,tvmonitor
则新类别(目标域)为第二行对应的类别:aeroplane,bottle,cow,horse,sofa
meta = data/voc_traindict_full.txt
voc_traindict_full.txt文件的内容为:(类别_train.txt的路径),例如:
aeroplane /home/bykang/voc/voclist/aeroplane_train.txt
bicycle /home/bykang/voc/voclist/bicycle_train.txt
bird /home/bykang/voc/voclist/bird_train.txt
boat /home/bykang/voc/voclist/boat_train.txt
bottle /home/bykang/voc/voclist/bottle_train.txt
bus /home/bykang/voc/voclist/bus_train.txt
car /home/bykang/voc/voclist/car_train.txt
(6)制作测试需要的文件,即:
在相应的目录下建立上图对应文件夹,这里注意名称大小写 VOCdevkit VOC2007 ImageSets Main,VOC2007下的Annotations直接整个复制已经有的Annotations,Main中test.txt为测试图片的名称,不带路径和后缀。
测试第一阶段:
在darknet_meta.py中的 def meta_forward(self, metax, mask):函数中
语句
for model in self.learnet_models:
metax = model(metax)
改为:
for model in self.learnet_models:
with torch.no_grad():
metax = model(metax)
训练的时候记得把 with torch.no_grad():去了哈
执行
python valid_ensemble.py cfg/metayolo.data cfg/darknet_dynamic.cfg cfg/reweighting_net.cfg path/toweightfile
执行完,得到测试的txt,在results文件下,执行
python scripts/voc_eval.py results/path/to/comp4_det_test_
需要修改: