2021李宏毅机器学习课程-YouTube第十三部分、元學習Meta Learning
第十三部分、元學習Meta Learning
-
-
- 1.复习机器学习(ML)
- 2.元学习(Meta Learning)
-
- 1)第一步,定义F(φ)
- 2)第二步,求Loss()损失
- 3)第三步,找一个φ,让L(φ)最小
- 3.ML v.s. Meta
-
- 1)目标不同(Goal)
- 2)训练数据不同(Training Data)
- 3)学习任务不同(Task)
- 4)损失函数不同(Loss)
- 5)相似点
- 4.我们能学哪些内容
-
- 1)学习初始化参数(Initialize)
- 2)MAML v.s. Pre-training
- 3)学习网络架构Network Architecture Search (NAS)
- 5.应用
-
元学习(Meta Learning)就是学习如何学习。例如,我们能否通过学习的方式学习超参数(hyperparameters)。
1.复习机器学习(ML)
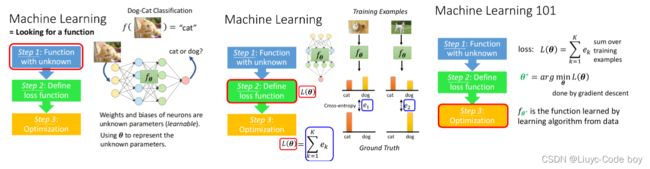
机器学习的本质就是找函数,一般为如下图所示的三个步骤。
- 第一步是找一个带有未知参数的函数。
- 第二步是定义损失函数,是关于未知参数θ。
- 第三步是定义优化器,找一个θ使得损失越小越好,这个参数称为θ*。
2.元学习(Meta Learning)
元学习就是在之前机器学习的基础上,目标是得到Learning algorithm,即,学习学习的学习。
比如下图所示,我们可以让机器去学习网络架构、初始参数、学习率等等,这些之前都是人为去完成的。
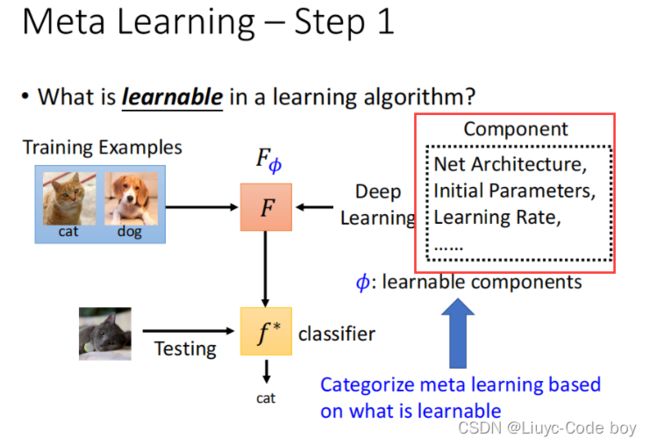
1)第一步,定义F(φ)
我们需要学的未知的部分就是φ,学习φ的函数就是F(φ)。

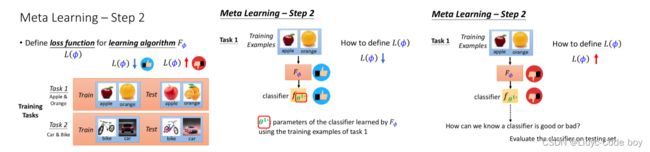
2)第二步,求Loss()损失
然后就是用φ求损失Loss,如果L(φ)是小的那么就说明我们的学习是好的。
评价我们学习之后的Learning algorithm是好的,那么放到测试集之后最终求交叉熵得到的损失l1是小的,反之学习的效果不好l1就是大的。
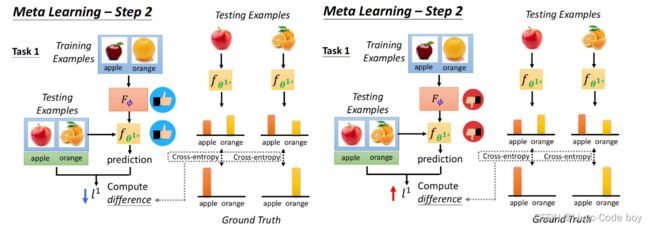
我们在做Meta learning元学习的时候往往是跑很多个模型,最终把所有损失加起来得出learning algorithm是不是好的。
我们可以把这些不同的任务称作是不同的Task,也可以称为不同的Domain。
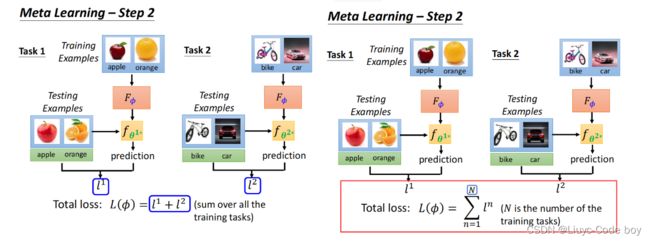
3)第三步,找一个φ,让L(φ)最小
这个使得L(φ)最小的φ,叫做φ*。
如下面右图所示,我们得到最好的φ的过程一般是用测试集中用来做训练的部分去找到最好的φ,而在测试集的测试部分去测试Learning algorithm的结果。(这部分是和ML的区别,ML里训练的时候不会动测试集的数据。)

3.ML v.s. Meta
1)目标不同(Goal)
ML的目标就是得到一个分类的结果。
Meta的结果是输入一个F,通过学习得到一个f,这个f可以用来做分类任务。

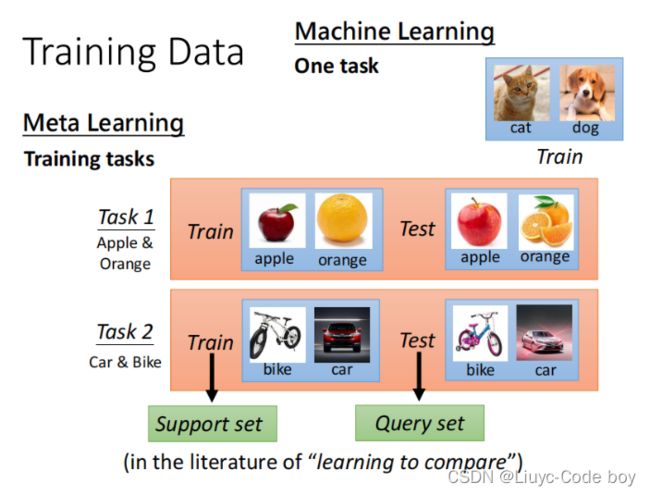
2)训练数据不同(Training Data)
ML的训练集就是单纯的训练集。
Meta的训练集还有测试集中训练的部分,为了避免叫混,有的人称其为Support set,测试部分称为Query set。
3)学习任务不同(Task)
ML的任务是一个单一的任务。
Meta的任务不止一个,又叫做跨任务训练(Across-task Training)

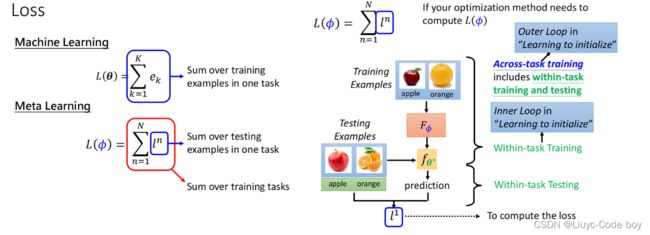
4)损失函数不同(Loss)
ML的Loss是一次任务的所有e的和。
Meta的Loss是所有任务的loss的和。
5)相似点
比如,两者都有overfitting的问题,一种解决方案是增加多的训练资料,或者是对训练资料进行数据增强处理。
另外Meta也有一堆超参数需要调整,但是调整完毕后可以一劳永逸,ML模型的参数通过learning algorithm就可以直接得到。
Development task理解为验证模型,介于训练任务和测试任务之间,当我们得到了一堆learning algorithm后,我们可以通过Development task确定哪个模型最好。

4.我们能学哪些内容
1)学习初始化参数(Initialize)
对于一个梯度下降过程我们不同的初始化参数会带来不同的训练结果,而这个初始化参数(Init)是我们可以通过大量的任务学出来的。
学习初始化参数的一个经典解法就是Model-Agnostic Meta-Learning (MAML),另一个变形是Reptile。

2)MAML v.s. Pre-training
如左图所示,对于初始化参数的讨论,我们之前在学习Self-supervised learning的时候也有提到过,当时是用无标记的数据使用BERT做填空题得到初始化的参数。而MAML是有标记的研究初始化参数的问题。
如右图所示,我们还有一种更为常用的Pre-training的方法叫做multi-task learning,意思是我们把多个任务的带有标记的数据倒在一起研究初始化参数的问题,这个方法现在常常被用在Meta中用作MAML的基线(baseline)。

3)学习网络架构Network Architecture Search (NAS)
如果我们想要去学习网络架构的话,那么φ就表示的是我们的网络架构。


5.应用
最常见的一个应用就是做数据资料比较少的分类问题(Few-shot Image Classification),比如一个类别的训练资料只有极少数的几张图片。
另一个是N-ways K-shot classification也就是我们有n个类别,每个类别里有k个资料。例如,下面这个三类,每类两张图片的分类问题就是3-ways 2-shot。
一般做一个Few-shot Image Classification的问题,我们会选择Omniglot(一共1623类,每个类20个资料)的一个数据集,从中挑出我们需要的ways和shot做训练。例如,最右边的图就是一个从Omniglot中选了20各类别,每个类别选一个资料构成的,20-ways 1-shot的数据集。
