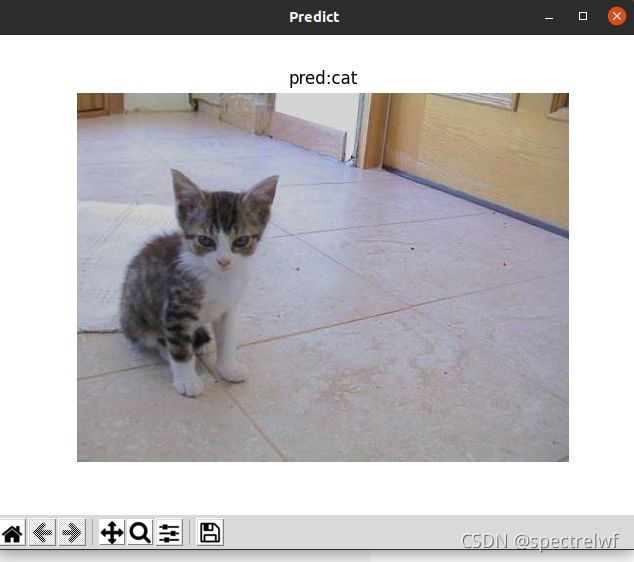
使用PYTORCH复现ALEXNET实现猫狗识别
完整代码链接:https://github.com/SPECTRELWF/pytorch-cnn-study
网络介绍:
Alexnet网络是CV领域最经典的网络结构之一了,在2012年横空出世,并在当年夺下了不少比赛的冠军,下面是Alexnet的网络结构:
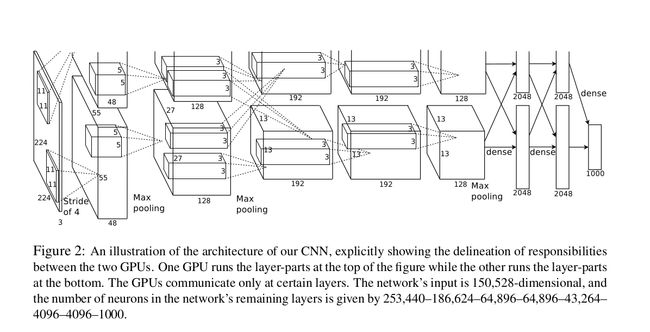
网络结构较为简单,共有五个卷积层和三个全连接层,原文作者在训练时使用了多卡一起训练,具体细节可以阅读原文得到。
Alexnet文章链接:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
作者在网络中使用了Relu激活函数和Dropout等方法来防止过拟合,更多细节看文章。
数据集介绍
使用的是ImageNet里面的猫和狗类的数据集,共包含10000+图片,其中划分测试集8000,测试集2000+,猫和狗类别平衡。
定义网络结构
就按照网络结构图中一层一层的定义就行,其中第1,2,5层卷积层后面接有Max pooling层和Relu激活函数,五层卷积之后得到图像的特征表示,送入全连接层中进行分类。
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/11/2 下午3:25
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, width_mult=1):
super(AlexNet, self).__init__()
# 定义每一个就卷积层
self.layer1 = nn.Sequential(
# 卷积层 #输入图像为1*28*28
nn.Conv2d(3, 32, kernel_size=3, padding=1),
# 池化层
nn.MaxPool2d(kernel_size=2, stride=2), # 池化层特征图通道数不改变,每个特征图的分辨率变小
# 激活函数Relu
nn.ReLU(inplace=True),
)
self.layer2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.ReLU(inplace=True),
)
self.layer3 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
)
self.layer4 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, padding=1),
)
self.layer5 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.ReLU(inplace=True),
)
# 定义全连接层
self.fc1 = nn.Linear(256 * 27 * 27, 1024)
self.fc2 = nn.Linear(1024, 512)
self.fc3 = nn.Linear(512, 2)
# 对应两个类别的输出
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
# print(x.shape)
x = x.view(-1, 256 * 27 * 27)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
训练
# !/usr/bin/python3
# -*- coding:utf-8 -*-
# Author:WeiFeng Liu
# @Time: 2021/11/4 下午12:59
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from alexnet import AlexNet
from utils import plot_curve
from dataload.dog_cat_dataload import Dog_Cat_Dataset
# 定义使用GPU
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 设置超参数
epochs = 30
batch_size = 32
lr = 0.01
transform = transforms.Compose([
transforms.Resize([224,224]),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# transforms.Normalize(mean=[.5,.5,.5],std=[.5,.5,.5]),
])
train_dataset = Dog_Cat_Dataset(r'/home/lwf/code/pytorch学习/alexnet-cat-dag/ImageNet/train',transform=transform)
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle = True,)
net = AlexNet().cuda(device)
loss_func = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(),lr=lr,momentum=0.9)
train_loss = []
for epoch in range(epochs):
sum_loss = 0
for batch_idx,(x,y) in enumerate(train_loader):
x = x.to(device)
y = y.to(device)
pred = net(x)
optimizer.zero_grad()
loss = loss_func(pred,y)
loss.backward()
optimizer.step()
sum_loss += loss.item()
train_loss.append(loss.item())
print(["epoch:%d , batch:%d , loss:%.3f" %(epoch,batch_idx,1.0*sum_loss/(batch_idx+1))])
torch.save(net.state_dict(), '/home/lwf/code/pytorch学习/alexnet-cat-dag/model/cat_dog_model.pth')
plot_curve(train_loss)
使用交叉熵损失函数和SGD优化器来训练网络,训练后保存模型至本地。
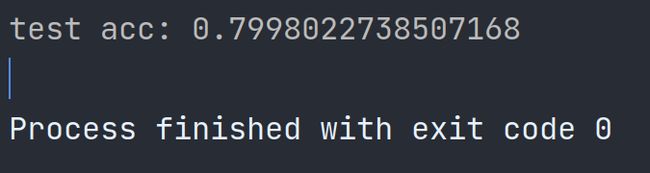
测试准确率
预测单张图片: