(三)WGAN和WGAN-GP解读与项目实战
(三)Wasserstein-GAN
一、传统的GAN的缺陷
1.超参数敏感
超参数敏感是指网络的结构设定、学习率、初始化状态等超参数对网络的训练过程影响较大,微量的超参数调整将可能导致网络的训练结果截然不同。如图 13.15 所示,图(a)为 GAN 模型良好训练得到的生成样本,图(b)中的网络由于没有采用 Batch Normalization层等设置,导致 GAN 网络训练不稳定,无法收敛,生成的样本与真实样本差距非常大。 为了能较好地训练 GAN 网络,DCGAN 论文作者提出了不使用 Pooling 层、多使用Batch Normalization 层、不使用全连接层、生成网络中激活函数应使用 ReLU、最后一层使用tanh激活函数、判别网络激活函数应使用 LeakyLeLU 等一系列经验性的训练技巧。但是这些技巧仅能在一定程度上避免出现训练不稳定的现象,并没有从理论层面解释为什么会出现训练困难、以及如果解决训练不稳定的问题。

2. 模式崩塌
模式崩塌(Mode Collapse)是指模型生成的样本单一,多样性很差的现象。由于判别器只能鉴别单个样本是否采样自真实分布,并没有对样本多样性进行显式约束,导致生成模型可能倾向于生成真实分布的部分区间中的少量高质量样本,以此来在判别器中获得较高的概率值,而不会学习到全部的真实分布。模式崩塌现象在 GAN 中比较常见,如图 13.16所示,在训练过程中,通过可视化生成网络的样本可以观察到,生成的图片种类非常单一,生成网络总是倾向于生成某种单一风格的样本图片,以此骗过判别器。

另一个直观地理解模式崩塌的例子如图 13.17 所示,第一行为未出现模式崩塌现象的生成网络的训练过程,最后一列为真实分布,即 2D 高斯混合模型;第二行为出现模式崩塌现象的生成网络的训练过程,最后一列为真实分布。可以看到真实的分布由 8 个高斯模型混合而成,出现模式崩塌后,生成网络总是倾向于逼近真实分布的某个狭窄区间,如图 13.17 第 2 行前 6 列所示,从此区间采样的样本往往能够在判别器中较大概率判断为真实样本,从而骗过判别器。但是这种现象并不是我们希望看到的,我们希望生成网络能够逼近真实的分布,而不是真实分布中的某部分。

二、GAN理论(参考李宏毅老师深度学习视频)
一、 我们知道generator的目标就是:
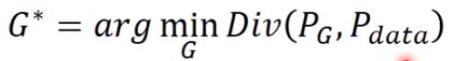
即最小化真实数据分布与Generator产生的数据的分布之间的某种距离
但是数据的分布我们并不知道,我们只能对其进行采样得到一些真实样本,然后通过极大似然估计来逼近真实分布。

二、然后我们可以证明求最大似然估计就是求最小KL散度

三、先训练Discriminator,再训练Generator
首先先fixed住Generator,再训练Discriminator,即最大化V(G, D)

MaxV(G,D)就等价于求Pg和Pdata之间的JS散度(但是JS散度存在缺陷):


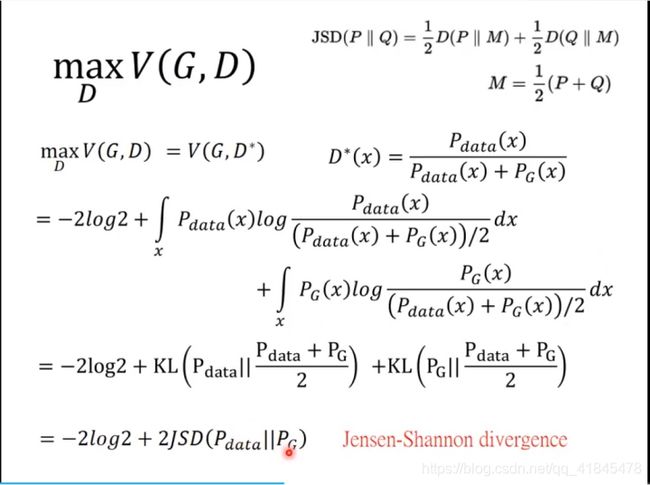
三、WGAN
-
当 P G P_G PG 和 P d a t a P_{data} Pdata 完全不重叠时,JS散度恒等于log2, 当完全重合后,JS散度等于0。只有当两个分布重叠时,JS散度才会平滑变动,但是刚开始训练时,是基本不重叠,梯度为0,参数长时间得不到更新,网络无法收敛。证明:两者分布不重合JS散度为log2的数学证明

-
EM距离:
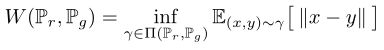
其中, ∏ ( P r , P g ) \prod (P_r,Pg) ∏(Pr,Pg) 表示所有联合分布 γ ( x , y ) \gamma(x, y) γ(x,y)的集合, 其边缘分布分别是 P r P_r Pr、 P g P_g Pg, 直观上讲, γ ( x , y ) \gamma(x, y) γ(x,y)表示 how much “mass” must be transported from x to y in order to transform the distributions P r P_r Pr into the distribution P g P_g Pg. The EM distance thex-yn is the “cost” of the optimal transport plan.也即是说,要穷举所有的联合分布 γ ( x , y ) \gamma(x, y) γ(x,y)去计算|| x - y || 的期望 E ( x , y ) γ E_{(x, y)~\gamma} E(x,y) γ[ ||x - y || ] , 但这是不现实的,因此,WGAN的作者introduce a practical approximation of optimizing the EM distance.
WGAN的作者基于Kantorovich-Rubinstein对偶性将直接求W( P r P_r Pr, P g P_g Pg)转换为求:
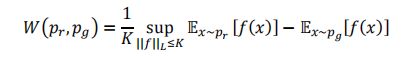
其中sup{ . }表示集合的上确界, ∣ ∣ f ∣ ∣ L || f ||_L ∣∣f∣∣L<=K表示函数f满足K阶Lipschitz连续性,即满足:
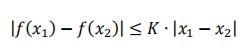
只要记住这个约束是为了保证D足够平滑

但是,求解一个带约束的优化问题是不容易的,在WGAN的论文中,也没有直接解决这个问题,而是采取添加限制的方式来让判别器目标函数尽量平滑,这种方式称为Weight Clipping, 其核心就是事先定义出判别器参数更新后的一个范围(-c, c),通过这种方式粗暴的将判别器参数更新后的值限制在(-c, c)。
WGAN的特点:
(1). 判别器最后一层去掉sigmoid
(2). 生成器和判别器的损失不再取 log \log log
(3). 训练判别器时, 每次参数更新后的值限制在一个范围(-c, c)
(4). 不使用基于动量的梯度优化算法,推荐使用RMSProp或者SGD算法

代码实现:
import argparse
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch
os.makedirs("images", exist_ok=True)
parser = argparse.ArgumentParser()
parser.add_argument('--root', default='../dataset', help = 'root path for dataset')
parser.add_argument("--n_epochs", type=int, default=200, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.00005, help="learning rate")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
opt = parser.parse_args(args = [])
print(opt)
np.random.seed(22)
torch.manual_seed(22)
img_shape = (opt.channels, opt.img_size, opt.img_size)
cuda = True if torch.cuda.is_available() else False
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(opt.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
# Initialize generator and discriminator
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
# create the dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
dataset = datasets.MNIST(root=opt.root, train=True, transform=transform, download=False)
dataloader = DataLoader(dataset = dataset, batch_size=opt.batch_size, shuffle=True, num_workers=4)
# Optimizers
optimizer_G = torch.optim.RMSprop(generator.parameters(), lr=opt.lr)
optimizer_D = torch.optim.RMSprop(discriminator.parameters(), lr=opt.lr)
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# ----------
# Training
# ----------
batches_done = 0
for epoch in range(opt.n_epochs):
for i, (imgs, _) in enumerate(dataloader):
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], opt.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z).detach()
# Adversarial loss
loss_D = -torch.mean(discriminator(real_imgs)) + torch.mean(discriminator(fake_imgs))
loss_D.backward()
optimizer_D.step()
# Clip weights of discriminator
for p in discriminator.parameters():
p.data.clamp_(-opt.clip_value, opt.clip_value)
# Train the generator every n_critic iterations
if i % opt.n_critic == 0:
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_imgs = generator(z)
# Adversarial loss
loss_G = -torch.mean(discriminator(gen_imgs))
loss_G.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, opt.n_epochs, batches_done % len(dataloader), len(dataloader), loss_D.item(), loss_G.item())
)
if batches_done % opt.sample_interval == 0:
save_image(gen_imgs.data, "Picture/WGAN/%d.png" % batches_done, nrow=8, normalize=True)
batches_done += 1
四、WGAN-GP
在WGAN-GP论文中,作者提出采用增加梯度惩罚项(Gradient Penalty)方法来迫使判别器网路满足1阶Lipschitz函数约束,同时作者发现将梯度值约束在1周围时效果更好,因此梯度惩罚项定义为:
![]()
因此WGAN的判别器D的训练目标为:

其中 x ^ \hat x x^来自于 x r x_r xr与 x f x_f xf的线性差值:
x ^ \hat x x^ = t x r x_r xr + ( 1 − t ) x f (1 - t ) x_f (1−t)xf, t ∈ \in ∈[0, 1]
判别器D的目标是最小化上述的误差 L ( G , D ) L(G, D) L(G,D), 迫使生成器G的分布 P g P_g Pg与真实分布 P r P_r Pr之间的EM距离项尽可能大,GP惩罚项接近于1。
WGAN生成器G的训练目标为:
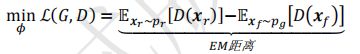
即使得生成器的分布 P g P_g Pg和真实分布 P r P_r Pr之间的EM距离越小越好,考虑到 E x r ∼ p r [ D ( x r ) ] E_{x_r\sim p_r}[D(x_r)] Exr∼pr[D(xr)]一项与生成器无关,因此生成器的训练目标简写为:
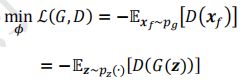




不同于之前,WGAN-GP的优化器还是选用了Adam
算法如下:

代码实现:
import torch
import argparse
import torchvision
import matplotlib.pyplot as plt
import numpy as np
import torchvision.transforms as transforms
from torchvision.utils import save_image
from torch.utils.data import DataLoader
from torchvision import datasets
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from torch.autograd import Variable
import torch.autograd as autograd
parser = argparse.ArgumentParser()
parser.add_argument('--root', default='../dataset', help = 'root path for dataset')
parser.add_argument("--n_epochs", type=int, default=50, help="number of epochs of training")
parser.add_argument("--batch_size", type=int, default=64, help="size of the batches")
parser.add_argument("--lr", type=float, default=0.0002, help="adam: learning rate")
parser.add_argument("--beta1", type=float, default=0.5, help="adam: decay of first order momentum of gradient")
parser.add_argument("--beta2", type=float, default=0.999, help="adam: decay of first order momentum of gradient")
parser.add_argument("--latent_dim", type=int, default=100, help="dimensionality of the latent space")
parser.add_argument("--img_size", type=int, default=28, help="size of each image dimension")
parser.add_argument("--channels", type=int, default=1, help="number of image channels")
parser.add_argument("--n_critic", type=int, default=5, help="number of training steps for discriminator per iter")
parser.add_argument("--clip_value", type=float, default=0.01, help="lower and upper clip value for disc. weights")
parser.add_argument("--sample_interval", type=int, default=400, help="interval betwen image samples")
args = parser.parse_args(args = [])
print(args)
img_shape = (args.channels, args.img_size, args.img_size)
np.random.seed(22)
torch.manual_seed(22)
cuda = True if torch.cuda.is_available() else False
# create the dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5), (0.5))
])
dataset = datasets.MNIST(root=args.root, train=True, transform=transform, download=False)
dataloader = DataLoader(dataset = dataset, batch_size=args.batch_size, shuffle=True, num_workers=4)
# ======================
# Generator
#=======================
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(args.latent_dim, 128, normalize=False),
*block(128, 256),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(img_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.shape[0], *img_shape)
return img
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(img_shape)), 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(256, 1),
)
def forward(self, img):
img_flat = img.view(img.shape[0], -1)
validity = self.model(img_flat)
return validity
generator = Generator()
discriminator = Discriminator()
if cuda:
generator.cuda()
discriminator.cuda()
Tensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# lambda for gradient penalty
lambda_gp = 10
# optimizers
optimizer_G = torch.optim.Adam(generator.parameters(), lr = args.lr, betas=(args.beta1, args.beta2))
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr = args.lr, betas=(args.beta1, args.beta2))
def compute_gradient_penalty(D, real_sample, fake_sample):
"""Calculates the gradient penalty loss for WGAN GP"""
# Random weight term for interpolation between real and fake samples
alpha = Tensor(np.random.random((real_sample.size(0), 1, 1, 1)))
# Get random interpolation between real and fake samples
interpolates = (alpha * real_sample + (1 - alpha) * fake_sample).requires_grad_(True)
d_interpolates = D(interpolates)
grad_tensor = Variable(Tensor(real_sample.size(0), 1).fill_(1.0), requires_grad = False)
gradients = autograd.grad(
outputs=d_interpolates,
inputs=interpolates,
grad_outputs = grad_tensor,
create_graph = True, # 设置为True可以计算更高阶的导数
retain_graph = True, # 设置为True可以重复调用backward
only_inputs = True, #默认为True,如果为True,则只会返回指定input的梯度值。 若为False,则会计算所有叶子节点的梯度,
#并且将计算得到的梯度累加到各自的.grad属性上去。
)[0] # 因为返回的是一个只有一个tensor元素的list,索引0可以取出梯度张量
gradients = gradients.view(real_sample.size(0), -1)
gradient_penalty = ((gradients.norm(2, dim = 1) - 1)**2).mean()
return gradient_penalty
# ----------
# Training
# ----------
for epoch in range(args.n_epochs):
for i ,(imgs, _) in enumerate(dataloader):
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
real_imgs = Variable(imgs.type(Tensor))
# Sample noise as generator input
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], args.latent_dim))))
# Generate a batch of images
fake_imgs = generator(z)
# Real images
real_score = discriminator(real_imgs)
# fake images
fake_score = discriminator(fake_imgs)
# Gradient penalty
gradient_penalty = compute_gradient_penalty(discriminator, real_imgs.data, fake_imgs.data)
d_loss = -torch.mean(real_score) + torch.mean(fake_score) + lambda_gp * gradient_penalty
d_loss.backward()
optimizer_D.step()
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Train the generator every n_critic steps
if i % args.n_critic == 0:
fake_imgs = generator(z)
fake_score = discriminator(fake_imgs)
g_loss = -torch.mean(fake_score)
g_loss.backward()
optimizer_G.step()
print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, args.n_epochs, i, len(dataloader), d_loss.item(), g_loss.item())
)
if epoch % 2 == 0:
with torch.no_grad():
z = Variable(Tensor(np.random.normal(0,1, (imgs.shape[0], args.latent_dim))))
gen_imgs = generator(z)
save_image(gen_imgs, 'Picture/WGAN-GP/generator_epoch{}.png'.format(epoch) ,normalize=True)
# do checkpointing 只保存参数
torch.save(generator.state_dict(), 'Model/WGAN-GP/generator_epoch_{}.pth'.format(epoch))