RabbitMQ 6种队列模式——Work queues工作队列
上一篇博文,详细模拟了简单队列模式, 简单队列有个缺点,简单队列是一一对应的关系,即点对点,一个生产者对应一个消费者,按照这个逻辑,如果我们有一些比较耗时的任务,也就意味着需要大量的时间才能处理完毕,显然简单队列模式并不能满足我们的工作需求。
工作队列模式概念
一个消息生产者,一个交换器,一个消息队列,多个消费者。同样也称为点对点模式

当消息生产速度远大于消费速度时,消息队列就会爆满,从而导致服务器不可用,那么我们就要设置多个消费者,共同进行消费。
但是不同的消费者处理消息的快慢也不一样,有的处理快,有的处理慢。那么RabbitMQ是怎么处理的呢?
消息的分发策略
MQ消息队列有如下几个角色
- 生产者
- 存储消息
- 消费者
☁ 生产者生成消息后,MQ进行存储,消费者是如何获取消息的呢?
答:一般获取数据的方式无外乎推(push)或者拉(pull)两种方式,典型的git 就有推拉机制,我们发送的http请求就是一种典型的拉去数据库数据返回的过程,而消息队列MQ是一种推送的过程,而这些推机制会适用到很多业务场景,也有很多对应推机制策略
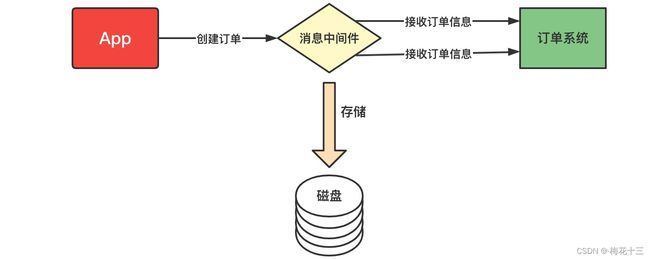
▎消息分发机制
| ActiveMQ | RabbitMQ | Kafka | RocketMQ | |
|---|---|---|---|---|
| 发布订阅 | 支持 | 支持 | 支持 | 支持 |
| 轮询分发 | 支持 | 支持 | 支持 | / |
| 公平分发 | / | 支持 | 支持 | / |
| 重发 | 支持 | 支持 | / | 支持 |
| 消息拉取 | / | 支持 | 支持 | 支持 |
比如队列中100条消息
1. 消费者A的服务器耗时 1000ms
2. 消费者B的服务器耗时 100ms
3. 消费者C的服务器耗时 300ms
1. 发布订阅
每个消费者都会收到100条消息
2. 轮询分发
公平模式,当有多个消费者接收消息时,消息的分配模式是一个消费者分配一条,直至消息消费完成,也就是说,不论消费者的服务器性能和消费能力如何,都会公平的按照一个一个轮询的分发(但无顺序)ABC三个消费者至少各自都消费33条,剩下一条会直接分配给其中一个消费者
缺点:不同消费者处理任务的时间是不一样的,会造成性能浪费
3. 公平分发
能者多劳模式,数据会倾斜,按照服务器性能来分发,消费者A服务器最慢,可能消费10条,消费者B最快,可能消费50条,而消费者C一般,可能消费40条
两者分发共同特点:数据一旦被一个消费者消费,其他消费者不会重复再消费这条数据
!! 前提:必须用到手动应答模式
4. 重发
出现问题和故障的情况下,消息不丢失还可进行重发
发送消息过程出现异常、或网络抖动、故障等原因造成消息的无法消费,比如用户在下订单,消费MQ接受,订单系统出现故障,导致用户支付失败,则此时需要消息中间件必须支持消息重试机制策略。也就是支持:出现问题和故障的情况下,消息不丢失还可以进行重发!
交换机如何路由消息到队列
队列是用来缓存存储消息的,生产者不会直接的向队列发送任何消息。实际上,生产者都不知道将消息交付给哪个队列。
生产者只将消息往exchange交换机中发送。交换机接收到消息之后,再把消息路由给具体队列,最终消费者从队列中获取消息进行消费。
也就是说,交换机一边从生产者中接收消息,一边将消息推到队列。需要注意的是:如果消息发送到了一个没有绑定队列的交换机时,消息就会丢失!
☁ 那么交换机是怎么将消息路由到具体队列的呢?
生产者发送消息给交换机,消息头上会携带一个routing key,通过routing key,交换机就知道该把消息分发到哪个队列,这些规则都通过exchange类型来定义。RabbitMQ 的交换机有四种类型:fanout、direct、topic、headers。
▸ fanout 广播方式
就跟广播一样,会将消息投递给所有绑定在此交换器的队列。

▸ direct 路由方式
在 direct 模式里,交换机和队列之间绑定了一个 key(这个key就是Binding key),只有消息的 Routing key 与Binding key 相同时,交换机才会把消息发给该队列。
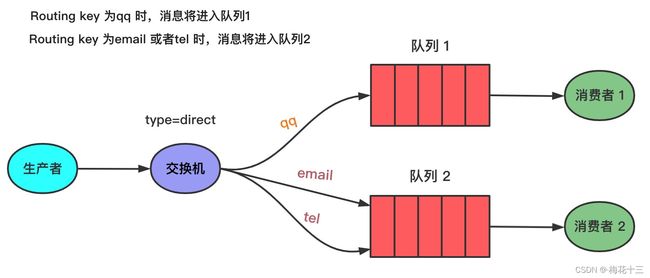
如上图,消息的Routing key 为 qq 时,消息将进入队列1,Routing key 为 email 或 时,消息将进入队列2。若消息的 key 是其他字符串,被交换机直接遗弃。
同时,交换机也支持多重绑定。不同的队列可以用相同的Binding key与同一交换机绑定。如下图,当消息的Routing key为black时,消息将进入 Q1 和 Q2。

▸ topic主题方式
通过模糊路由到队列。该方式的Routing key必须具有固定格式:以 . 间隔的一串单词,比如:quick.orange.rabbit,Routing key 最多不能超过255byte。
交换机和队列的Binding key用通配符来表示,有两种语法:
-
* 可以替代一个单词;
-
# 可以替代 0 或多个单词;

上图中,Q1与交换机的 绑定kye 为 " * .orange. *",当消息的Routing key为三个单词,且中间的单词为 orange 时,消息将进入 Q1。
Q2 与交换机的绑定key 为 "lazy.#",当消息的Routing key以 lazy 开头时,消息将进入 Q2 。
▸ headers参数方式
不常用,headers交换机是通过Headers头部来将消息映射到队列的,Headers头部携带一个Hash结构,Hash结构中要求携带一个键"x-match",这个键的Value可以是any或者all,这代表消息携带的Hash是需要全部匹配(all),还是仅匹配一个键(any)就可以了。相比直连交换机,首部交换机的优势是匹配的规则不被限定为字符串String类型。
▎扩展:默认交换机
default Exchange,默认交换机的名字是空字符串。
发送消息不指定交换机名称,会发到"默认交换机"上。默认的Exchange不进行Binding操作,任何发送到该Exchange的消息都会被转发到 "Queue名字和Routing key相同的队列"中,如果vhost中不存在和Routing key同名的队列,则该消息会被抛弃。
代码展示
接下来用代码展示2种消息分发策略:轮询分发、公平分发
准备条件
提醒:由于生产者和消费者的代码大同小异,为了方便,编写一个通用的连接工具类。
public class MQConnectionUtils {
// 获取连接
public static Connection getConnection(String connectionName,String vHost){
Connection connection = null;
// 1.建立连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("127.0.0.1");
factory.setPort(5672);
factory.setUsername("wpf2");
factory.setPassword("123");
factory.setVirtualHost(vHost);
try {
// 2.通过连接工厂建立连接
connection = factory.newConnection(connectionName);
} catch (IOException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
return connection;
}
// 释放资源
public static void close(Connection connection, Channel channel){
// 1.关闭通道
if(channel!=null && channel.isOpen()){
try {
channel.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// 2.关闭连接
if(connection!=null){
try {
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}▸ 轮询分发
在工作的使用中,经常会遇到多个消费者监听同一个队列的情况,那么此时消息应该如何分发给消费者呢?

分发消息默认采用的轮询分发。轮询分发是指一个消费者一条,按均分配。即你一条我一条,直到队列里的消息全部消费完为止。
1. 生产者:定义生产者,生产消息到交换机中
public class Producer {
public static void main(String[] args) {
// 1.获取连接
Connection connection = MQConnectionUtils.getConnection("生产者","test_host");
Channel channel = null;
try {
// 2.通过连接建立通道
channel = connection.createChannel();
// 3.发送消息
// 注意:my-exchange2是交换机名称,在图形化界面已创建好,就不用代码声明创建了
for (int i = 1; i <= 10; i++) {
String message = "你好 "+i+" 梅花十三!";
channel.basicPublish("my-exchange2", "", null, message.getBytes());
Thread.sleep(i * 20);
}
System.out.println("消息已发送完毕");
} catch (Exception e) {
e.printStackTrace();
}finally {
MQConnectionUtils.close(connection,channel);
}
}
}2. 消费者1:定义消费者类
public class Consumer1 implements Runnable{
public void run() {
final String name = Thread.currentThread().getName();
// 1.获取连接
Connection connection = MQConnectionUtils.getConnection("消费者","test_host");
Channel channel = null;
try {
// 2.通过连接建立通道
channel = connection.createChannel();
// 3.创建一个消费者,消费消息
DefaultConsumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,byte[] body) throws IOException {
System.out.println(name+"接收成功!消息内容:" + new String(body, "UTF-8"));
try {
// 假设消费者1处理消息速度要1秒
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
// 注意:my-queue是队列名称,在图形化界面已创建好,并绑定了my-exchange2交换机
channel.basicConsume("my-queue", true, consumer);
} catch (Exception e) {
e.printStackTrace();
}finally {
//不关闭,为了展示多个消费者实时接收消息
// MQConnectionUtils.close(connection,channel);
}
}
}3. 消费者2:定义消费者2和消费者1的代码是一致的,只是处理消息速度不一样
// 3.创建一个消费者,消费消息
DefaultConsumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
System.out.println(name+"接收成功!消息内容:" + new String(body, "UTF-8"));
try {
// 假设消费者2的处理速度是200ms,比消费者1快800ms
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
channel.basicConsume("my-queue", true, consumer);4. 启动消费者:新建一个测试类,运行2个消费者线程,监听队列
public class test {
public static void main(String[] args) throws InterruptedException {
new Thread(new Consumer1(),"消费者1").start();
new Thread(new Consumer2(),"消费者2").start();
}
}5.启动生产者:如下图,生产者已将消息生产并投递到交换机
6. 查看消费者:切换至测试类控制面板,查看消费者消费情况
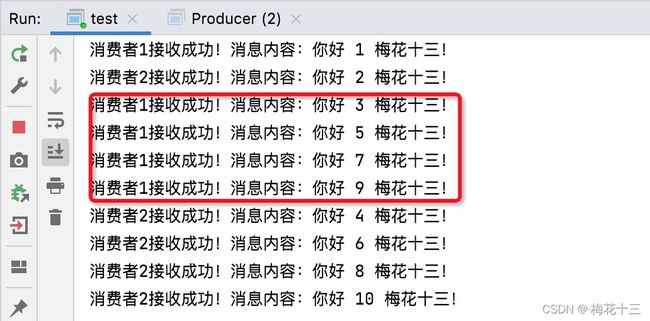
✦ 结论:如上图,消费者1处理的消息都是奇数,消费者2的是偶数。消费者1处理速度是1秒,消费者2处理速度是200毫秒。RabbitMQ不管消费者处理消息速度如何,分发消息都是按均分配,你一条,我一条!
▸ 公平分发
由于消费者处理消息的能力不同,存在处理快慢问题,就需要能者多劳,处理快的多处理。
公平分发不是按照字面理解的按均分配模式,而是多劳多得策略。比如:消费者1可能电脑性能更好,响应和处理速度快,而消费者2 是一台垃圾电脑,接收消息和处理速度慢,那么消费者2就可以多处理一点消息!

1. 生产者:同上述轮询分发中的代码一致,这里就不二次贴了
2. 消费者1:同上述轮询分发中的代码基本一致,不同点在于以下代码中的第3、5、6点处
public class Consumer1 {
public static void main(String[] args) throws IOException {
System.out.println("消费者1开始接收。。。。。。");
// 1.获取连接
Connection connection = MQConnectionUtils.getConnection("消费者","test_host");
// 2.通过连接建立通道
final Channel channel = connection.createChannel();
// 3.设置不公平分发:限制发送给同一个消费者 不得超过一条消息,处理完毕再分发
channel.basicQos(1);
// 4.创建一个消费者,消费消息
DefaultConsumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,byte[] body) throws IOException {
System.out.println("消费者1接收成功!消息内容:" + new String(body, "UTF-8"));
try {
// 假设消费者1处理消息速度要1秒
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 5.手动确认,消息已被消费
//(由于basicQos设置了1,这里手动确认已被消费后,下一条消息才会进来)
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
// 6.autoAck的值为false:表示开启手动应答模式,手动确认消息已被消费,消息才会被队列删除
channel.basicConsume("my-queue", false, consumer);
}
}!! 注意:设置参数channel.basicQos(1); 目的是告诉 RabbitMQ我每次只处理一条消息,你要等我处理完了再分给我下一个。这样RabbitMQ就不会轮流分发了,而是寻找空闲的工作者进行分发。
3. 消费者2:与消费者1代码基本一致,不同点在于,消费者2休眠时间为:Thread.sleep(200);
4. 启动消费者:分别启动运行2个消费者,开始监听队列

5.生产消息:启动producer类,生产消息
6. 查看消费能力:切换至Consumer1 和 Consumer2 查看两个消费者的消费能力


✦ 结论:由上俩图可知,消费者2处理一条消息200ms,消费者1处理需要1秒,因此,消费者2处理的消息明显比消费者1多的多,即所谓的能者多劳!