WangDeLiangReview2018 - (5.1&5.2)语音增强&语音增强的泛化
【WangDeLiangOverview2018】
Supervised Speech Separation Based on Deep Learning: An Overview
DeLiang Wang / Jitong Chen @ Ohio
IEEE/ACM Trans. ASLP2018
【目录】
1. 引入
2. 学习机器(learning machines)
3. 训练目标(training target)
4. 特征
5. 单声道分离
5.1 语音增强(speech separation)
5.2 语音增强的泛化
5.3 语音去混响 & 去噪(speech dereverberation & denoising)
5.4 说话人分离(speaker separation)
6. 多声道分离(阵列分离)
7. 更多内容
【正文】
5.1 语音增强
据我们所知,Wang和Wang在2012年的两篇会议论文[179][180]中首次将深度学习引入到语音分离中,随后在2013年扩展到期刊版本[181]。他们使用DNN进行子带分类(subband classification)来估计IBM。在会议版本中,采用了有限玻尔兹曼机RBM预训练的前馈DNNs作为二分类器,以及用于结构感知机(structured perceptron)[179]和条件随随机场(conditional random fields)[180]的特征编码器(feature encoder)。他们报告说,在所有使用DNN的情况下都有很强的分离结果,由于结合了时间动力学,在结构化预测中DNN用于特征学习的结果更好。
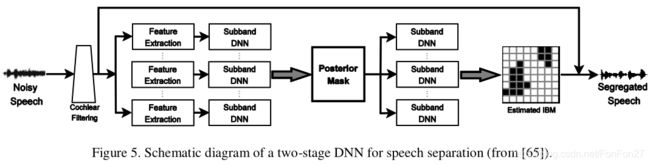
在期刊版[181]中,输入信号通过64通道的Gammatone滤波器组导出子带信号,从子带信号中提取每个T-F单元的声学特征。这些特征形成子带DNNs(共64个)的输入,学习更多的判别特征。图4说明了DNN在语音分离中的这种应用。经过DNN训练后,将最后一层隐藏层的输入特征和学习特征连接并馈给线性支持向量机,有效地估计子带IBM。该算法被进一步扩展为两阶段DNN[65],其中第一阶段训练为像往常一样估计子带IBM,第二阶段以以下方式明确地合并了T-F上下文。在第一阶段DNN训练后,二值化前的单元级输出可以解释为语音控制T-F单元的后验概率。因此,第一阶段DNN输出被认为是一个后掩膜。在第二阶段,T-F单元以单元中心的后掩模局部窗口作为输入。两阶段DNN如图5所示。第二阶段的结构让人想起CNN的卷积层,但没有权值共享。这种利用上下文信息的方式被证明可以显著提高分类的准确性。受试者测试表明,DNN对HI和NH听众都产生了很大的可理解度/清晰度(intelligibility)改善,其中HI听众受益更多[65]。这是第一个为背景噪音中的HI听众提供实质性语音清晰度改善的单通道算法,以至于有分离的HI受试者比没有分离的NH受试者表现得更好。

2013年,Lu等人[116]发表了一篇使用深度自编码器DAE(Deep AutoEncoder)进行语音增强的Interspeech论文。一个基本的自编码器AE(AutoEncoer)是一个无监督的学习机器,典型的有一个对称的架构与一个绑定权值的隐藏层,它学习将输入信号映射到自己。多个经过训练的AEs可以堆叠到DAE中,然后接受传统的监督微调,例如使用backpropagation算法。换句话说,自动编码是RBM预训练的替代方案。[116]的算法学习从有噪语音的mel频率功率谱映射到干净语音的mel-频率功率谱,可以看作是第一个基于映射的方法(作者还在Interspeech 2012上发表了一篇论文[115],在该论文中,一个DAE以无监督的方式进行训练,从干净语言的mel谱映射到自身。然后使用训练过的DAE从噪声输入中“召回”干净的信号,以实现鲁棒的ASR)。
随后,Xu等人[196]在独立于[116]的基础上,发表了一项研究,使用带有RBM预训练的DNN从有噪语音的对数功率谱映射到干净语音的对数功率谱,如图6。与[116]不同的是,[196]中使用的DNN是带有RBM预训练的标准前馈MLP。训练后,DNN从一个有噪声的输入中估计干净语音的频谱。实验结果表明,训练后的DNN对无训练噪声的增益约为0.4 ~ 0.5 PESQ,高于传统的一种有代表性的增强方法。

许多随后的研究已经沿着T-F掩膜和谱映射(spectral mapping)的路线发表。在[186][185]中,采用LSTM的RNN用于语音增强及其在鲁棒ASR中的应用,其训练目标是信号近似(见3.1节)。在[41]中也使用RNNs来估计PSM。在[132][210]中,提出了用于IBM估计的深度叠加网络(deep stacking network),然后使用掩码估计进行基音(pitch)估计。经过几个周期的迭代,掩模估计和基音估计的精度都得到了提高。DNN被用来同时估计cIRM的实分量和虚分量,产生比IRM估计更好的语音质量[188]。音素水平上的语音增强最近被研究[183][18]。在[59]中,DNN用分段增益函数考虑了感知掩蔽。在[198]中,多目标学习被证明可以提高增强性能。研究表明,分层DNN进行子带谱映射比单个DNN进行全带谱映射[39]的增强效果更好。在[161]中,为了提高增强性能,DNN中增加了非连续层之间的skip connection。
研究发现,同时使用掩膜和映射目标的多目标训练优于单目标训练[205]。cnn也被用于IRM估计[83]和谱映射[46][136,138]。
除了掩膜和基于映射的方法,最近有兴趣使用深度学习来执行端到端分离,即不借助于T-F表示的时间映射。这种方法的一个潜在优势是避免了在重建增强语音时使用噪声语音相位的需要,这可能会影响语音质量,特别是在输入信噪比较低的情况下。最近,Fu等人[47]开发了一种全卷积网络(去除完全连接层的CNN)用于语音增强。他们观察到,完全连接使得很难映射出波形信号的高频和低频分量,而随着它们的消除,增强结果得到了改善。由于卷积算子与滤波器或特征提取器相同,CNN似乎是时间映射的自然选择。
最近的一项研究使用GAN进行时间映射(temporal mapping)[138]。在所谓的语音增强GAN:SEGAN(SpeecDh Enhancement GAN)中,生成器(Genarator)是一个全卷积网络,执行增强或去噪。鉴别器(Discriminator)遵循与G相同的卷积的结构,它传递生成的波形信号VS干净的信号的信息回到G,D可以看作是提供一种可训练的对G的损失函数 . SEGAN评估在未经训练的嘈杂的环境,但结果是不确定的,并不如掩蔽或映射方法。
在GAN的另一项研究[122]中,G试图增强嘈杂语音的声谱图,同时D试图区分增强的声谱图和干净的话语。[122]的比较表明,这种GAN的增强结果与DNN的增强结果相当。
并非所有基于深度学习的语音增强方法都基于DNNs。例如,Le Roux等人[105]提出了深度NMF,它展开了NMF操作,并包括反向传播中的乘法更新。Vu等人[167]提出了一个NMF框架,在该框架中,DNN经过训练,将有噪声语音的NMF激活系数映射到干净版本。
5.2 语音增强的泛化
对于任何监督学习任务,泛化(generalization)到未经训练的条件是一个关键的问题。在语音增强的情况下,数据驱动算法在泛化方面承担了举证责任,因为传统的语音增强和CASA算法很少使用监督训练,不存在这个问题。监督增强有三个方面的泛化:噪声、说话人和信噪比。在信噪比泛化方面,我们可以简单地在训练集中包含更多的信噪比水平,实践经验表明,监督增强对训练中使用的精确信噪比并不敏感。部分原因是,即使在训练中包含了少量的混合信噪比,但帧级和T-F单元级的局部信噪比通常变化幅度很大,为学习机很好地泛化提供了必要的品种。一种替代策略是采用递增隐层数的渐进训练来处理较低信噪比的情况[48]。
为了解决训练和测试条件之间的不匹配,Kim和Smaragdis[98]提出了一种两阶段DNN,其中第一阶段是执行谱映射的标准DNN,第二阶段是在测试阶段进行无监督自适应的自编码器AE。就像[115]一样,AE被训练成将清晰话语的幅度谱映射到自身,因此它的训练不需要标记数据。然后将声发射叠加在DNN的顶部,作为纯度检查器,如图7所示。其原理是,增强良好的语音往往会在AE的输入和输出之间产生一个小的差异(错误),而增强较差的语音应该产生一个大的错误。给定一个测试混合,已经训练好的DNN将与AE的误差信号进行微调。AE模块的引入提供了一种无监督的适应测试条件的方法,这与训练条件有很大的不同,并被证明提高了语音增强的性能。
由于各种各样的平稳和非平稳噪声可能会干扰语音信号,因此噪声泛化从根本上具有挑战性。在训练噪声有限的情况下,一种方法是利用噪声扰动,特别是频率扰动[23]来扩展训练噪声;具体来说,对原始噪声样本的谱图进行扰动,以产生新的噪声样本。为了使Xu等人[196]的基于dnn的映射算法对新噪声的鲁棒性更好,Xu等人[195]采用了噪声感知训练,即输入特征向量包含了显式的噪声估计。通过二值掩蔽估计噪声,具有噪声感知训练的DNN对未训练噪声有较好的泛化能力。
[24]系统地解决了噪声泛化问题。本研究训练DNN在帧级估计IRM。此外,IRM同时在几个连续的帧中进行估计,并对同一帧的不同估计进行平均,以产生更平滑、更精确的蒙版(参见[178])。DNN有5个隐藏层,每个层有2048个ReLUs。每一帧的输入特征为cochlegram响应能量(表1和表2中的GF特征)。训练集包括640,000个混合物,由560个IEEE句子和10,000 (10K)噪声从声音效果库(www.sound-ideas.com)创建,固定信噪比为-2 dB。噪声的总持续时间约为125小时,混合训练的总持续时间约为380小时。为了评估训练噪声的数量对噪声泛化的影响,我们也按照[181]的方法,在100个噪声的条件下训练同一个DNN。测试集使用160个IEEE句子和不同信噪比下的非平稳噪声创建。训练过程中既不使用测试句子,也不使用测试噪声。STOI测量的分离结果如表3所示,采用10K-noise模型得到STOI较大的改进。此外,10k噪声模型的性能大大优于100噪声模型,其平均性能与前一半训练噪声训练和后一半测试噪声依赖模型相匹配。被试测试表明,大规模训练产生的噪声无关模型显著提高了NH和HI听者在看不见的噪声中的语音清晰度。本研究强烈地表明,大规模的训练与各种各样的噪声是解决噪声泛化的一种有前途的方法。
对于说话人泛化来说,训练特定说话人的分离系统对不同的说话人并不适用。对演讲者泛化的一种直接尝试是使用大量的演讲者进行训练。然而,实验结果[20][100]表明,前馈DNN似乎不能对大量的通话者进行建模。这种DNN通常采用一个声学特征窗口来进行掩码估计,而不使用长期上下文。由于无法跟踪目标说话者,前馈网络有将噪声片段误认为目标语音的倾向。RNNs自然建模时间依赖性,因此预期比前馈DNN更适合于说话人泛化。
我们最近使用了RNN和LSTM来解决噪声无关模型[20]的说话人泛化问题。图8所示的模型是在3,200,000个混合了6、10、20、40和77个扬声器的10,000个噪音的混合物上训练出来的。当使用训练过的扬声器进行测试时,如图9(a)所示,当更多的训练扬声器加入到训练集时,DNN的性能会下降,而LSTM则受益于额外的训练扬声器。对于未经训练的测试说话者,如图9(b)所示,LSTM在STOI方面显著优于DNN。LSTM在训练过程中接触到许多演讲者后,似乎能够跟踪目标演讲者。在多说话者和噪声大的大规模训练中,LSTM算法是一种有效的不依赖于说话者和噪声的语音增强方法。